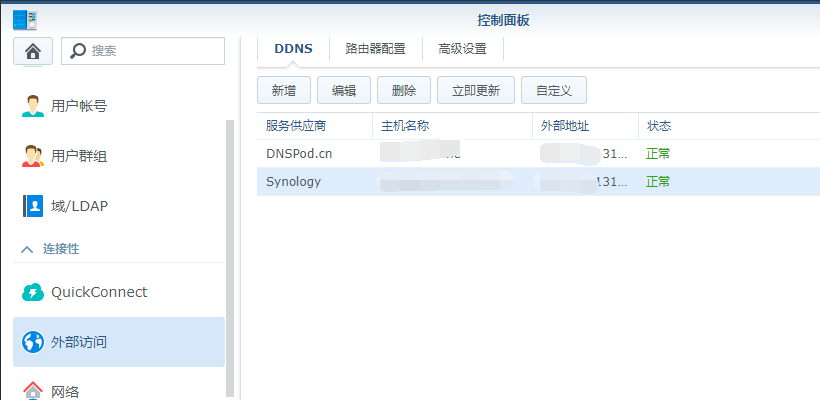
在考虑重编译T-SQL(或者存储过程)的时候,有两种方式可以实现强制重编译(前提是忽略导致重编译的其他因素的情况下,比如重建索引,更新统计信息等等),
一是基于WITH RECOMPILE的存储过程级别重编译,另外一种是基于OPTION(RECOMPILE)的语句级重编译。
之前了解的比较浅,仅仅认为是前者就是编译整个存储过程中的所有的语句,后者是重编译存储过程中的某一个语句,也没有追究到底是不是仅仅只有这么一点区别。
事实上在某些特定情况下,两者的区别并非仅仅是存储过程级重编译和语句级重编译的区别,
从编译生成的执行计划来看,这两种强制编译的方式内在机制差异还是比较大的。
这里同时引申出来另外一个问题:The Parameter Embedding Optimization(怎么翻译?也没有中文资料中提到The Parameter Embedding Optimization,勉强翻译为“参数植入优化”)
本文通过一个简单的示例来说明这两者的区别(测试环境为SQL Server2014)。这里首先感谢UEST同学提供的参考资料和指导建议。
WITH RECOMPILE 和 OPTION(RECOMPILE)使用上的区别
关于存储过程级别的重编译,典型用法如下,在存储过程参数之后指定“WITH RECOMPILE”

CREATE PROCEDURE TestRecompile_WithRecompile (@p_parameter int )WITH RECOMPILE AS BEGINSET NOCOUNT ON;SELECT * FROM TestRecompile WHERE Id = @p_parameter OR @p_parameter IS NULL END GO
关于语句级重编译,典型用法如下,在某一条SQL语句的末尾指定OPTION(RECOMPILE)
CREATE PROCEDURE TestRecompile_OptionRecompile (@p_parameter VARCHAR(50) ) AS BEGINSET NOCOUNT ON;SELECT * FROM TestRecompile WHERE Id = @p_parameter OR @p_parameter IS NULL OPTION(RECOMPILE) END GO
按照惯例,先搭建一个测试环境
创建一张TestRecompile的表,也即上面存储过程中用到的表,插入100W行数据,Id字段上建立一个名字为idx_id的索引
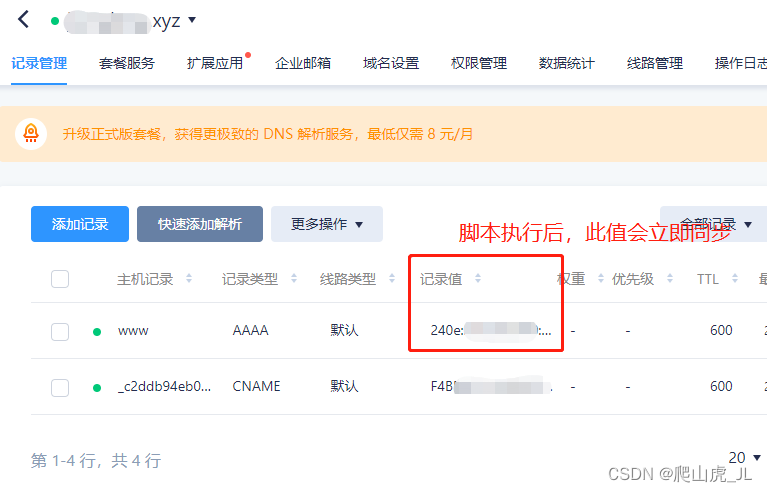
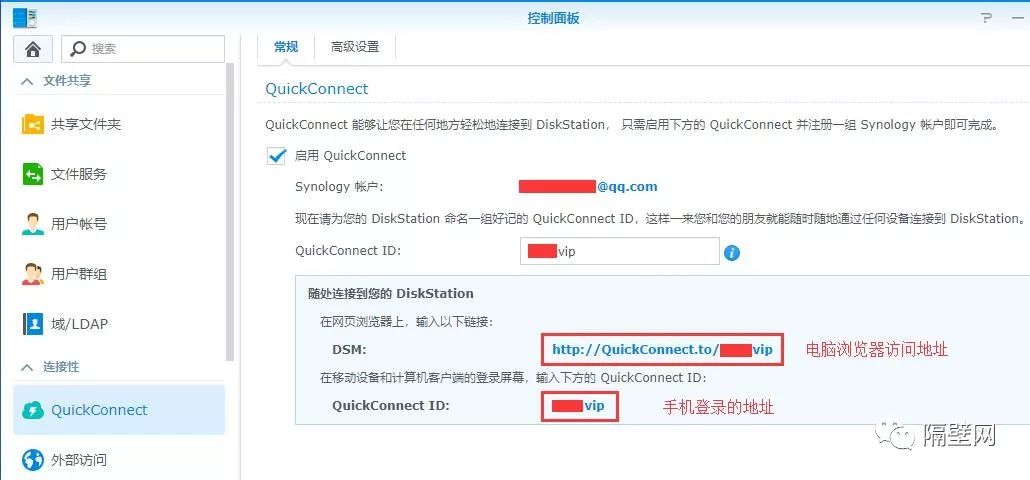
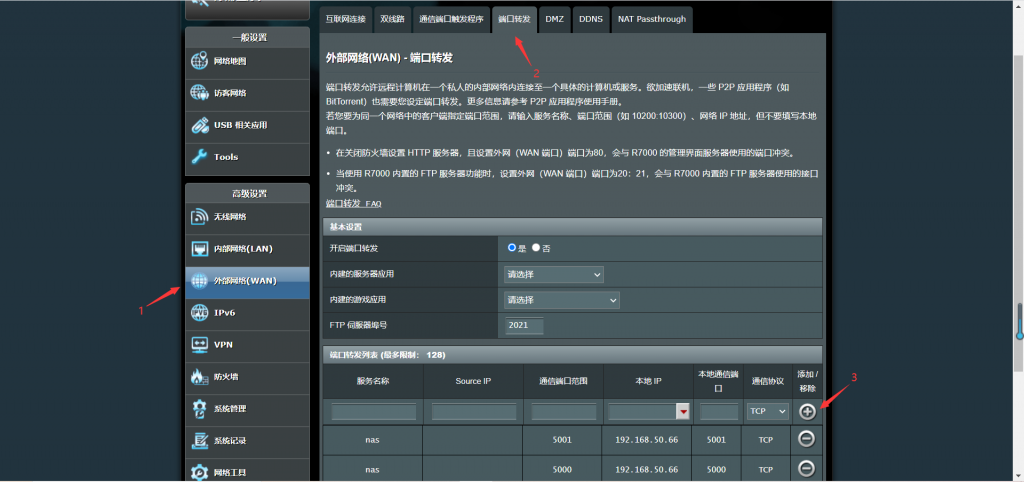



![[NAS] Synology (群晖) DSM7.0 使用自定义供应商DDNS](https://img-blog.csdnimg.cn/fc142b28f9424621bb59deb5e42fb4d5.png)