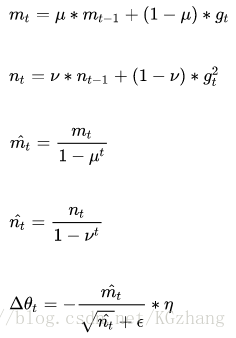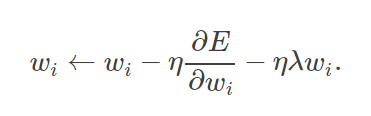class torch.optim.Adam(params, lr=0.001, betas=(0.9, 0.999), eps=1e-08, weight_decay=0)
它在Adam: A Method for Stochastic Optimization中被提出。(https://arxiv.org/abs/1412.6980)
参数:
params (iterable) – 待优化参数的iterable或者是定义了参数组的dict
lr (float, 可选) – 学习率(默认:1e-3)
betas (Tuple[float, float], 可选) – 用于计算梯度以及梯度平方的运行平均值的系数(默认:0.9,0.999)
eps (float, 可选) – 为了增加数值计算的稳定性而加到分母里的项(默认:1e-8)
weight_decay (float, 可选) – 权重衰减(L2惩罚)(默认: 0)
解释:
lr:同样也称为学习率或步长因子,它控制了权重的更新比率(如 0.001)。较大的值(如 0.3)在学习率更新前会有更快的初始学习,而较小的值(如 1.0E-5)会令训练收敛到更好的性能。
betas = (beta1,beta2)
beta1:一阶矩估计的指数衰减率(如 0.9)。
beta2:二阶矩估计的指数衰减率(如 0.999)。该超参数在稀疏梯度(如在 NLP 或计算机视觉任务中)中应该设置为接近 1 的数。
eps:epsilon:该参数是非常小的数,其为了防止在实现中除以零(如 10E-8)。
Adam(Adaptive Moment Estimation)本质上是带有动量项的RMSprop,它利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率。它的优点主要在于经过偏置校正后,每一次迭代学习率都有个确定范围,使得参数比较平稳。其公式如下:
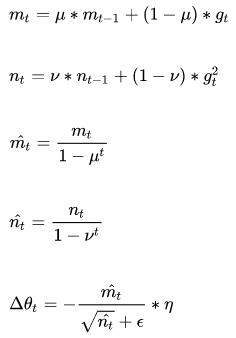
其中,前两个公式分别是对梯度的一阶矩估计和二阶矩估计,可以看作是对期望E|gt|,E|gt^2|的估计;
公式3,4是对一阶二阶矩估计的校正,这样可以近似为对期望的无偏估计。可以看出,直接对梯度的矩估计对内存没有额外的要求,而且可以根据梯度进行动态调整。最后一项前面部分是对学习率n形成的一个动态约束,而且有明确的范围。
用法:
step(closure=None)函数:执行单一的优化步骤
closure (callable, optional):用于重新评估模型并返回损失的一个闭包
Adam的特点有:
1、结合了Adagrad善于处理稀疏梯度和RMSprop善于处理非平稳目标的优点;
2、对内存需求较小;
3、为不同的参数计算不同的自适应学习率;
4、也适用于大多非凸优化-适用于大数据集和高维空间。
通过一个简单的例子看一下,PyTorch 中是如何使用优化器的
Example:
>>> optimizer = torch.optim.SGD(model.parameters(), lr=0.1, momentum=0.9)
>>> optimizer.zero_grad()
>>> loss_fn(model(input), target).backward()
>>> optimizer.step()
首先,在创建优化器对象的时候,要传入网络模型的参数,并设置学习率等优化方法的参数。然后使用函数zero_grad将梯度置为零。接着调用函数backward来进行反向传播计算梯度。最后使用优化器的step函数来更新参数。
接下来看一下函数zero_grad。优化器 SGD 中的 zero_grad 函数如下所示。 可以看到,操作很简单,就是将所有参数的梯度置为零p.grad.zero_()。
Optimizer 更新参数主要是靠 step 函数,在父类 Optimizer 的 step 函数中只有一行代码raise NotImplementedError 。正如前边介绍的,网络模型参数和优化器的参数都保存在列表 self.param_groups 的元素中,该元素以字典形式存储和访问具体的网络模型参数和优化器的参数。所以,可以通过两层循环访问网络模型的每一个参数 p 。获取到梯度d_p = p.grad.data之后,根据优化器参数设置是否使用 momentum或者nesterov再对参数进行调整。最后一行 p.data.add_(-group[‘lr’], d_p)的作用是对参数进行更新。
PyTorch 中的 Adam Optimizer 和 SGD Optimizer 的主要区别也是 step 函数不同。Adam Optimizer 中的 step 函数。其中,对于每个网络模型参数都使用state[‘exp_avg’]和state[‘exp_avg_sq’]来保存 梯度 和 梯度的平方 的移动平均值。第一次更新的时候没有state,即len(state) == 0,所以两个数值都需要使用torch.zeros_like(p.data)来初始化为0 ,之后每次都只需要从state中取出该值使用和更新即可。state[‘step’]用于保存本次更新是优化器第几轮迭代更新参数。最后使用p.data.addcdiv_(-step_size, exp_avg, denom)来更新网络模型参数 p 。
值得注意的是,Adam Optimizer 只能处理 dense gradient,要想处理 sparse gradient 需要使用 SparseAdam Optimizer 。
关于学习率的调整
首先在一开始的时候我们可以给我们的神经网络附一个“经验性”的学习率:
lr=1e-3 #SGDlr=1e-3 #Adam一般要求学习率比较小
假设对于不同层想给予不同的学习率怎么办呢
参考:https://www.cnblogs.com/hellcat/p/8496727.html
直接对不同的网络模块制定不同学习率 classifiter的学习率设置为1e-2,所有的momentum=0.9
optimizer = optim.SGD([{‘params’: net.features.parameters()}, # 默认lr是1e-5
{‘params’: net.classifiter.parameters(), ‘lr’: 1e-2}], lr=1e-5,momentum=0.9)
以层为单位,为不同层指定不同的学习率
1、提取指定层对象为classifiter模块的第0个和第3个
special_layers = t.nn.ModuleList([net.classifiter[0], net.classifiter[3]])
2、获取指定层参数id
special_layers_params = list(map(id, special_layers.parameters()))
print(special_layers_params)
3、获取非指定层的参数id
base_params = filter(lambda p: id§ not in special_layers_params, net.parameters())
optimizer = t.optim.SGD([{‘params’: base_params},
{‘params’: special_layers.parameters(), ‘lr’: 0.01}], lr=0.001)
当你发现你的loss在训练过程中居然还上升了,那么一般来讲,是你此时的学习率设置过大了。这时候我们需要动态调整我们的学习率:
def adjust_learning_rate(optimizer, epoch, t=10):
“”“Sets the learning rate to the initial LR decayed by 10 every t epochs,default=10"”"
new_lr = lr * (0.1 ** (epoch // t))
for param_group in optimizer.param_groups:
param_group[‘lr’] = new_lr
官方文档中还给出用
torch.optim.lr_scheduler 基于循环的次数提供了一些方法来调节学习率.
torch.optim.lr_scheduler.ReduceLROnPlateau 基于验证测量结果来设置不同的学习率.
其他调参的策略
1.L2-正则化防止过拟合
weight decay(权值衰减),其最终目的是防止过拟合。在机器学习或者模式识别中,会出现overfitting,而当网络逐渐overfitting时网络权值逐渐变大,因此,为了避免出现overfitting,会给误差函数添加一个惩罚项,常用的惩罚项是所有权重的平方乘以一个衰减常量之和。其用来惩罚大的权值。在损失函数中,weight decay是放在正则项(regularization)前面的一个系数,正则项一般指示模型的复杂度,所以weight decay的作用是调节模型复杂度对损失函数的影响,若weight decay很大,则复杂的模型损失函数的值也就大。
这个在定义优化器的时候可以通过参数 【weight_decay,一般建议0.0005】来设置:
opt_Adam = torch.optim.Adam(net_Adam.parameters(), lr=LR, betas=(0.9, 0.99), eps=1e-06, weight_decay=0.0005)
2、batch normalization。batch normalization的是指在神经网络中激活函数的前面,将按照特征进行normalization,这样做的好处有三点:
提高梯度在网络中的流动。Normalization能够使特征全部缩放到[0,1],这样在反向传播时候的梯度都是在1左右,避免了梯度消失现象。
提升学习速率。归一化后的数据能够快速的达到收敛。
减少模型训练对初始化的依赖。
减少参数选择的依赖
一些通常的解释:https://blog.csdn.net/hjimce/article/details/50866313
3、加入dropout层:dropout一般设置为0.5
4、集成方法
集成学习是一种机器学习范式。在集成学习中,我们会训练多个模型(通常称为「弱学习器」)解决相同的问题,并将它们结合起来以获得更好的结果。最重要的假设是:当弱模型被正确组合时,我们可以得到更精确和/或更鲁棒的模型。
在集成学习理论中,我们将弱学习器(或基础模型)称为「模型」,这些模型可用作设计更复杂模型的构件。在大多数情况下,这些基本模型本身的性能并不是非常好,这要么是因为它们具有较高的偏置(例如,低自由度模型),要么是因为他们的方差太大导致鲁棒性不强(例如,高自由度模型)。
集成方法的思想是通过将这些弱学习器的偏置和/或方差结合起来,从而创建一个「强学习器」(或「集成模型」),从而获得更好的性能。
组合弱学习器
为了建立一个集成学习方法,我们首先要选择待聚合的基础模型。在大多数情况下(包括在众所周知的 bagging 和 boosting 方法中),我们会使用单一的基础学习算法,这样一来我们就有了以不同方式训练的同质弱学习器。
这样得到的集成模型被称为「同质的」。然而,也有一些方法使用不同种类的基础学习算法:将一些异质的弱学习器组合成「异质集成模型」。
很重要的一点是:我们对弱学习器的选择应该和我们聚合这些模型的方式相一致。如果我们选择具有低偏置高方差的基础模型,我们应该使用一种倾向于减小方差的聚合方法;而如果我们选择具有低方差高偏置的基础模型,我们应该使用一种倾向于减小偏置的聚合方法。
这就引出了如何组合这些模型的问题。我们可以用三种主要的旨在组合弱学习器的「元算法」:
bagging,该方法通常考虑的是同质弱学习器,相互独立地并行学习这些弱学习器,并按照某种确定性的平均过程将它们组合起来。boosting,该方法通常考虑的也是同质弱学习器。它以一种高度自适应的方法顺序地学习这些弱学习器(每个基础模型都依赖于前面的模型),并按照某种确定性的策略将它们组合起来。stacking,该方法通常考虑的是异质弱学习器,并行地学习它们,并通过训练一个「元模型」将它们组合起来,根据不同弱模型的预测结果输出一个最终的预测结果。
非常粗略地说,我们可以说 bagging 的重点在于获得一个方差比其组成部分更小的集成模型,而 boosting 和 stacking 则将主要生成偏置比其组成部分更低的强模型(即使方差也可以被减小)。
https://www.jiqizhixin.com/articles/2019-05-15-15
https://blog.csdn.net/google19890102/article/details/46507387
在训练过程中关于loss的一些说明:
参考:https://blog.csdn.net/LIYUAN123ZHOUHUI/article/details/74453980
1 train loss 不断下降,test loss 不断下降,说明网络正在学习
2 train loss 不断下降,test loss 趋于不变,说明网络过拟合
3 train loss 趋于不变,test loss 趋于不变,说明学习遇到瓶颈,需要减小学习率或者批处理大小
4 train loss 趋于不变,test loss 不断下降,说明数据集100%有问题
5 train loss 不断上升,test loss 不断上升(最终变为NaN),可能是网络结构设计不当,训练超参数设置不当,程序bug等某个问题引起
参考:
https://blog.csdn.net/Ibelievesunshine/article/details/99624645
https://blog.csdn.net/KGzhang/article/details/77479737
https://zhuanlan.zhihu.com/p/87209990
git 库
https://github.com/201419/Optimizer-PyTorch