前言
2016年,Hadoop迎来了自己十周岁生日。过去的十年,Hadoop雄霸武林盟主之位,号令天下,引领大数据技术生态不断发展壮大,一时间百家争鸣,百花齐放。然而,兄弟多了不好管,为了抢占企业级市场,各家都迭代出自己的一套访问控制体系,不管是老牌系统(比如HDFS、HBase),还是生态新贵(比如Kafka、Alluxio),ACL(Access Control List)支持都是Roadmap里被关注最高的issue之一。
历史证明跳出混沌状态的最好方式就是——出台标准。于是,Hadoop两大厂Cloudera和Hortonworks先后发起标准化运动,分别开源了Sentry和Ranger,在centralized访问控制领域展开新一轮的角逐。
Ranger在0.4版本的时候被Hortonworks加入到其Hadoop发行版HDP里,目前作为Apache incubator项目,最新版本是0.6。它主要提供如下特性:
基于策略(Policy-based)的访问权限模型
通用的策略同步与决策逻辑,方便控制插件的扩展接入
内置常见系统(如HDFS、YARN、HBase)的控制插件,且可扩展
内置基于LDAP、文件的用户同步机制,且可扩展
统一的管理界面,包括策略管理、审计查看、插件管理等
本文将从权限模型、总体架构、系统插件三个角度来展开,剖析Ranger如何实现centralized访问控制。
权限模型
访问权限无非是定义了”用户-资源-权限“这三者间的关系,Ranger基于策略来抽象这种关系,进而延伸出自己的权限模型。为了简化模型,便于理解,我用以下表达式来描述它:
Policy = Service + List<Resource> + AllowACL + DenyACL
AllowACL = List<AccessItem> allow + List<AccssItem> allowException
DenyACL = List<AccessItem> deny + List<AccssItem> denyException
AccessItem = List<User/Group> + List<AccessType>
接下来从”用户-资源-权限”的角度来详解上述表达:
用户:由User或Group来表达;User代表访问资源的用户,Group代表用户所属的用户组。
资源:由(Service, Resource)二元组来表达;一条Policy唯一对应一个Service,但可以对应多个Resource。
权限:由(AllowACL, DenyACL)二元组来表达,两者都包含两组AccessItem。而AccessItem则描述一组用户与一组访问之间的关系——在AllowACL中表示允许执行,而DenyACL中表示拒绝执行。
下表列出了几种常见系统的模型实体枚举值:

关于权限这个部分,还有一点没有解释清楚:为什么AllowACL和DenyACL需要分别对应两组AccessItem?这是由具体使用场景引出的设计:
以AllowACL为例,假定我们要将资源授权给一个用户组G1,但是用户组里某个用户U1除外,这时只要增加一条包含G1的AccessItem到AllowACL_allow,同时增加一条包含U1的AccessItem到AllowACL_allowException即可。类似的原因可反推到DenyACL。
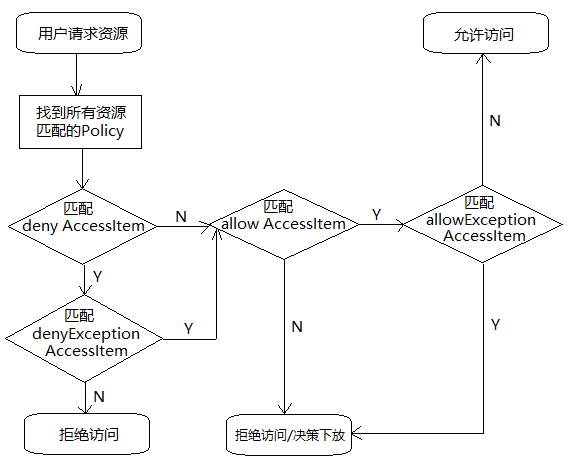
既然现在一条Policy有(allow, allowException, deny, denyException)这么四组AccessItem,那么判断用户最终权限的决策过程是怎样的?
总体来说,这四组AccessItem的作用优先级由高到低依次是:
denyException > deny > allowException > allow
访问决策树可以用以下流程图来描述:
这里要对决策下放做一个解释:如果没有policy能决策访问,Ranger可以选择将决策下放给系统自身的访问控制层,比如HDFS的ACL。
总体架构
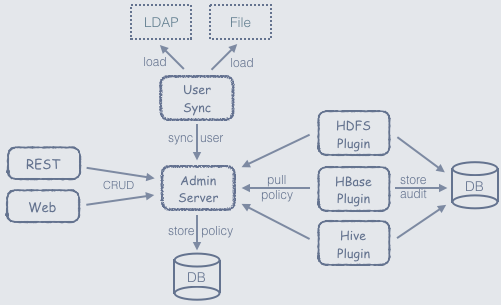
Ranger的总体架构如下图所示,主要由以下三个组件构成:
AdminServer: 以RESTFUL形式提供策略的增删改查接口,同时内置一个Web管理页面。
AgentPlugin: 嵌入到各系统执行流程中,定期从AdminServer拉取策略,根据策略执行访问决策树,并且定期记录访问审计。插件的实现原理将在后文详细介绍。
UserSync: 定期从LDAP/File中加载用户,上报给AdminServer。
系统插件
前文已经提到,系统插件主要负责三件事:
定期从AdminServer拉取策略
根据策略执行访问决策树
定期记录访问审计
以上执行逻辑是通用的,可由所有系统插件引用,因此剩下的问题是如何把这些逻辑嵌入到各个系统的访问决策流程中去。目前Ranger里有两种做法:
- 实现可扩展接口:多数的系统在实现时都有考虑功能扩展性的问题,一般会为核心的模块暴露出可扩展的接口,访问控制模块也不例外。Ranger通过实现访问控制接口,将自己的逻辑嵌入各个系统。下表列出了Ranger插件对几个常见系统的扩展接口:

- 代码注入:不排除有少数系统没有将访问控制模块暴露出扩展点,这个时候Ranger依赖Java代码注入机制(java.lang.instrument)来实现逻辑嵌入。以HDFS插件为例,Ranger利用ClassFileTransformer,直接修改HDFS访问控制类FSPermissionChecker的ClassFile,将checkPermission方法替换成Ranger的自定义实现。
后话
随着Hadoop生态圈进军企业级市场,数据安全逐渐成为关注焦点。Ranger作为标准化的访问控制层,引入统一的权限模型与管理界面,极大地简化了数据权限的管理。不过,Ranger目前处于孵化项目,在功能性与稳定性上仍然有较大的提升空间,其能否覆盖更多的系统,一统江湖成为标准,让我们拭目以待。