时间:2019年
作者:Weiyue Wang ,University of Southern California etc.
Abstract:
1.DISN 通过预测基本符号距离场来从二维图像中生成高质量的细节丰富的三维网格;
2.DISN 在二维图像上预测每一个三维点的投影位置,以及从图像特征映射中提取局部特征。将全局特征与局部特征相结合,可以提高符号距离场的预测精度,尤其对于细节丰富的区域。
1.Introduction
1.体素与点云方法通常在分辨率上受到限制;
2.一些方法在神经网络中使用显式曲面表示,但假设了固定拓扑,限制了方法的灵活性;
3.基于点和网格的方法使用倒角距离(Chamfer Distance:CD)和 Earth-mover Distanc(EMD)作为训练损失,但这些距离只提供用于测量形状相似性的近似度量;
4.SDF 仅对三维中每个点采样距基础形状边界的有符号距离进行编码。给定一组有符号距离值,可以通过使用Marching Cubes等方法识别等值面来提取形状;
5.大致思路:首先可以通过 CNN 来提取输入图像的特征,得到一个特征向量;然后 DISN 通过使用该特征向量来预测给定三维点的 SDF 值;通过对不同三维点位置的采样, DISN 可以生成具有无限分辨率的基本表面隐式场。而且不需要固定的拓扑假设,回归得到的目标值与GT相同而不是其近似值;
6.使用从二维图像中学习到的形状嵌入可以捕捉到全局形状属性,但是容易忽略孔洞以及细薄结构这样的细节;
7.因此提出了一个局部特征提取模块,该模块使网络能够学习投影像素和三维空间之间的关系,并显著提高生成的三维形状中细粒度细节的重建质量。
2.Related Work
1.AtlasNet使用一组参数化曲面元素生成三维形状的曲面,基于图形的网络Pix2Mesh从输入图像重建三维流形并提出了通过变形给定源网格来重建3D形状的3DN。这些方法使用显式三维表示,通常会遇到分辨率有限和网格拓扑固定等问题。隐式表示为克服这些限制提供了另一种表示方式;
2.使用基于体素的SDF表示进行形状修复。然而,已知3D CNN存在高内存使用率和计算成本;
3.使用自动解码器结构引入DeepSDF以完成形状。然而,它们的网络不是前馈的,需要在测试阶段优化嵌入向量,这限制了方法的效率和能力;
4.在深度网络中使用SDF执行形状生成任务。虽然他们的方法在生成任务中取得了令人满意的结果,但无法恢复用于单视图重建的三维对象的细粒度细节。
3.Method
SDF: SDF 是一个将给出的三维空间坐标点映射为一个实数值
的连续函数:
,它所得到的结果的绝对值是该三维坐标点距离表面的距离,结果的符号代表该点所在表面的内侧还是外侧(s>0在表面外侧,s<0在表面内侧)。等值面
隐式地表示基础三维形状。与3D CNN方法不同,3D CNN方法生成具有固定分辨率的体积网格,DISN生成具有任意分辨率的连续场。

1.DISN:

DISN由两部分组成:相机位姿估计和 SDF预测;
DISN首先估计相机参数将三维世界坐标中的物体映射到二维图像平面的摄影机参数;给定预测得到的相机参数,我们将每一个三维 query 点投影到图像平面上,然后收集对应图像块的多尺度 CNN 特征,然后 DISN 使用多尺度的局部特征和全局特征将给出的三维点解码为 SDF 值。
(1)相机位姿估计:

与更常用的表示法(如四元数和欧拉角)相比,6D旋转表示法是连续的,神经网络更容易回归。
文中应用了一个六维旋转表示 ,给出 b ,旋转矩阵
:
,其中N(·)为归一化函数(the normalization function)。
损失函数:
为在世界空间的点云,N为点云中点的数量,
,
表示相机空间中相应的地面真值点位置。
(2)SDF 预测:我们的解决方案是使用多层感知器将给定的点位置映射到更高维的特征空间。然后将该高维特征分别与全局和局部图像特征连接,并用于回归SDF值。
特征提取:仅仅使用全局特征很难捕捉到类似于孔洞,细薄结构等形状细节,因此引入了局部图像特征集中于细粒度的细节重建:

通过估计的摄影机参数,三维点p∈ R3被投影到二维位置q∈ R2位于图像平面上。我们检索每个特征映射上对应于位置q的特征,并将它们连接起来以获得局部图像特征。由于后层中的特征图的尺寸小于原始图像,因此我们使用双线性插值将其调整为原始尺寸,并在位置q处提取调整后的特征。然后,两个解码器分别将全局和局部图像特征作为点特征的输入,并进行SDF预测。最终SDF是这两个预测的总和。
有无局部特征的效果对比:

损失函数: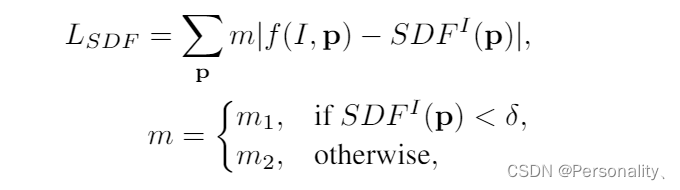
2.表面重建:为了生成网格曲面,我们首先定义一个密集的三维网格,并预测每个网格点的SDF值。一旦我们计算了密集网格中每个点的SDF值,我们就使用Marching Cubes来获得对应于等值曲面S0的3D网格。