粒子群优化算法
一、概述
粒子群优化算法(Particle Swarm Optimization,PSO)的思想来源于对鸟捕食行为的模仿,最初,Reynolds.Heppner 等科学家研究的是鸟类飞行的美学和那些能使鸟群同时突然改变方向,分散,聚集的定律上,这些都依赖于鸟的努力来维持群体中个体间最佳距离来实现同步。而社会生物学家 E.O.Wilson 参考鱼群的社会行为认为从理论上说,在搜寻食物的过程中,尽管食物的分配不可知,群中的个体可以从群中其它个体的发现以及以往的经验中获益。
粒子群从这种模型中得到启发并用于解决优化问题。如果我们把一个优化问题看作是在空中觅食的鸟群,那么粒子群中每个优化问题的潜在解都是搜索空间的一只鸟,称之为“粒子”(Particle),“食物”就是优化问题的最优解。每个粒子都有一个由优化问题决定的适应度用来评价粒子的“好坏”程度,每个粒子还有一个速度决定它们飞翔的方向和距离,它根据自己的飞行经验和同伴的飞行经验来调整自己的飞行。粒子群初始化为一群随机粒子(随机解),然后通过迭代的方式寻找最优解,在每一次的迭代中,粒子通过跟踪两个“极值”来更新自己,第一个是粒子本身所经历过的最好位置,称为个体极值即 P b e s t Pbest Pbest;另一个是整个群体经历过的最好位置称为全局极值 G b e s t Gbest Gbest。每个粒子通过上述的两个极值不断更新自己,从而产生新一代的群体。
二、粒子群算法
算法的描述如下:
假设搜索空间是 L L L维,并且群体中有 N N N个粒子。那么群体中的第 i i i个粒子可以表示为一个 L L L维的向量, X i = ( x i 1 , x i 2 , ⋯ , x i L ) , i = 1 , 2 , ⋯ , N X_i=(x_{i1},x_{i2},\cdots,x_{iL}),i=1,2,\cdots,N Xi=(xi1,xi2,⋯,xiL),i=1,2,⋯,N,即第 i i i个粒子在 L L L维的搜索空间的位置是 X i X_i Xi,它所经历的“最好”位置记作 P b e s t i = ( p i 1 , p i 2 , ⋯ , p i L ) , i = 1 , 2 , ⋯ , N Pbest_i=(p_{i1},p_{i2},\cdots,p_{iL}),i=1,2,\cdots,N Pbesti=(pi1,pi2,⋯,piL),i=1,2,⋯,N。粒子的每个位置代表要求的一个潜在解,把它代入目标函数就可以得到它的适应度值,用来评判粒子的“好坏”程度。整个群体迄今为止搜索到的最优位置记作 G b e s t g = ( p g 1 , p g 2 , ⋯ , p g L ) Gbest_g=(p_{g1},p_{g2},\cdots,p_{gL}) Gbestg=(pg1,pg2,⋯,pgL), g g g是最优粒子位置的索引。
V i t + 1 = ω V i t + c 1 r 1 ( P b e s t i t − X i t ) + c 2 r 2 ( G b e s t g t − X i t ) (1) V_{i}^{t+1}=\omega V_{i}^{t} + c_1 r_1 (Pbest_i^{t}-X_i^{t}) + c_2 r_2 (Gbest_g^{t}-X_i^{t}) \tag{1} Vit+1=ωVit+c1r1(Pbestit−Xit)+c2r2(Gbestgt−Xit)(1)
X i t + 1 = X i t + V i t + 1 (2) X_{i}^{t+1} = X_{i}^{t} + V_{i}^{t+1} \tag{2} Xit+1=Xit+Vit+1(2)
ω \omega ω为惯性权重(inertia weight), P b e s t i t Pbest_i^{t} Pbestit为第 i i i个粒子到第 t t t代为止搜索到的历史最优解, G b e s t g t Gbest_g^{t} Gbestgt为整个粒子群到目前为止搜索到的最优解, X i t X_i^{t} Xit, V i t V_i^{t} Vit分别是第 i i i个粒子当前的位置和飞行速度, c 1 , c 2 c_1,c_2 c1,c2为非负的常数,称为加速度因子, r 1 , r 2 r_1,r_2 r1,r2是 [ 0 , 1 ] [0,1] [0,1]之间的随机数。
公式由三部分组成,第一部分是粒子当前的速度,表明了粒子当前的状态;第二部分是认知部分(Cognition Modal),表示粒子本身的思考( c 1 c_1 c1也称为自身认知系数);第三部分是社会认知部分(Social Modal),表示粒子间的信息共享( c 2 c_2 c2为社会认知系数)。
参数的选择:
粒子数目一般取30~50,参数 c 1 , c 2 c_1,c_2 c1,c2一般取2。适应度函数、粒子的维数和取值范围要视具体问题而定。问题解的编码方式通常可以采用实数编码。
算法的主要步骤如下:
第一步:对粒子群的随机位置和速度进行初始设定,同时设定迭代次数。
第二步:计算每个粒子的适应度值。
第三步:对每个粒子,将其适应度值与所经历的最好位置 P b e s t i Pbest_i Pbesti的适应度值进行比较,若较好,则将其作为当前的个体最优位置。
第四步:对每个粒子,将其适应度值与全局所经历的最好位置 G b e s t g Gbest_g Gbestg的适应度值进行比较,若较好,则将其作为当前的全局最优位置。
第五步:根据公式(1),(2)对粒子的速度和位置进行优化,从而更新粒子位置。
第六步:如未达到结束条件(通常为最大循环数或最小误差要求),则返回第二步。
三、基于粒子群算法的非线性函数寻优
本案例寻优的非线性函数为
y = − c × exp ( − 0.2 1 n ∑ i = 1 n x i 2 ) − exp ( 1 n ∑ i = 1 n cos 2 π x i ) + c + e y=-c\times \exp(-0.2\sqrt{\frac{1}{n}\sum_{i=1}^{n}{x_i^2}}) - \exp(\frac{1}{n}\sum_{i=1}^{n}{\cos 2\pi x_i})+c+e y=−c×exp(−0.2n1i=1∑nxi2)−exp(n1i=1∑ncos2πxi)+c+e
当 c = 20 c=20 c=20, n = 2 n=2 n=2时,该函数为Ackley函数,函数图形如图1所示。
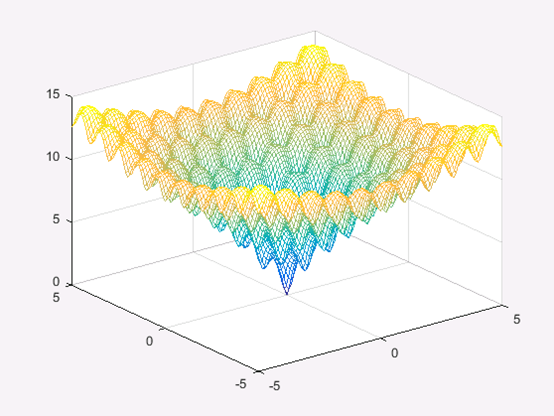
从函数图形可以看出,该函数有很多局部极小值,在 ( 0 , 0 ) (0,0) (0,0)处取到全局最小值0。
本案例群体的粒子数为20,每个粒子的维数为2,算法迭代进化次数为100。加速度因子 c 1 = 1.4 c_1=1.4 c1=1.4, c 2 = 1.5 c_2=1.5 c2=1.5,惯性权重 ω = 0.1 \omega = 0.1 ω=0.1。
适应度函数代码如下:
function y = fun(x)
% 函数用于计算粒子适应度值
% x input 输入粒子
% y output 粒子适应度值 c=20;y=-c*exp(-0.2*sqrt((x(1)^2+x(2)^2)/2))-...exp((cos(2*pi*x(1))+cos(2*pi*x(2)))/2)+c+exp(1);
end
PSO算法代码如下:
%% 清空环境
clc
clear
%% 参数初始化
c1 = 1.4;c2 = 1.5; %加速度因子
maxgen = 100; %进化次数
sizepop = 20; %群体规模
w = 0.1; %惯性权重
Vmax = 1;Vmin = -1; %速度最大值,最小值
popmax = 5;popmin = -5; %个体最大值,最小值
pop = zeros(sizepop,2); %种群
V = zeros(sizepop,2); %速度
fitness = zeros(sizepop,1); %适应度
trace = zeros(maxgen,1); %结果
%% 随机产生一个群体,初始粒子和速度
for i=1:sizepoppop(i,:) = 5*rands(1,2); %初始种群V(i,:) = rands(1,2); %初始化速度 fitness(i)=fun(pop(i,:)); %计算染色体的适应度
end
%% 个体极值和群体极值
[bestfitness,bestindex] = min(fitness);
Gbest = pop(bestindex,:); %全局最佳
fitnessGbest = bestfitness; %全局最佳适应度值
Pbest = pop; %个体最佳
fitnessPbest = fitness; %个体最佳适应度值
%% 迭代寻优
for i=1:maxgen for j=1:sizepop V(j,:) = w*V(j,:) + c1*rand*(Pbest(j,:) - pop(j,:)) + ... %速度更新c2*rand*(Gbest - pop(j,:));V(j,V(j,:)>Vmax)=Vmax;V(j,V(j,:)<Vmin)=Vmin; pop(j,:)=pop(j,:)+V(j,:); %群体更新pop(j,pop(j,:)>popmax)=popmax;pop(j,pop(j,:)<popmin)=popmin;fitness(j)=fun(pop(j,:)); %适应度值 end for j=1:sizepop if fitness(j) < fitnessPbest(j) %个体最优更新Pbest(j,:) = pop(j,:);fitnessPbest(j) = fitness(j);end if fitness(j) < fitnessGbest %群体最优更新Gbest = pop(j,:);fitnessGbest = fitness(j);endend trace(i)=fitnessGbest; disp([Gbest,fitnessGbest]);
end
%% 结果分析
plot(trace)
title('最优个体适应度');
xlabel('进化代数');
ylabel('适应度');
算法结果如下:
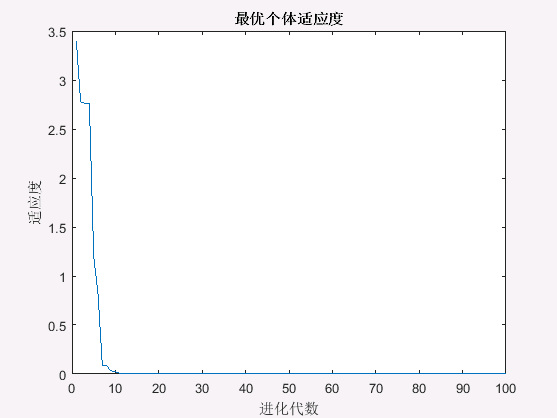
最终得到的个体适应度值为 0.4441 × 1 0 − 14 0.4441\times 10^{-14} 0.4441×10−14,对应的粒子位置为 ( 0.0125 × 1 0 − 14 , 0.1310 × 1 0 − 14 ) (0.0125\times 10^{-14}, 0.1310\times 10^{-14}) (0.0125×10−14,0.1310×10−14),PSO算法寻优得到最优值接近函数实际最优值,说明PSO算法具有较强的函数极值寻优能力。
四、基于自适应变异粒子群算法的非线性函数寻优
本案例寻优的非线性函数(Shubert函数)为
f ( x 1 , x 2 ) = ∑ i = 1 5 i cos [ ( i + 1 ) x 1 + i ] × ∑ i = 1 5 i c o s [ ( i + 1 ) x 2 + i ] , − 10 ≤ x 1 , x 2 ≤ 10 f(x_1,x_2 )=\sum_{i=1}^{5}{i\cos[(i+1) x_1+i]}\times\sum_{i=1}^{5}{icos[(i+1) x_2+i]},-10\leq x_1,x_2 \leq 10 f(x1,x2)=i=1∑5icos[(i+1)x1+i]×i=1∑5icos[(i+1)x2+i],−10≤x1,x2≤10
该函数图形如图3所示:
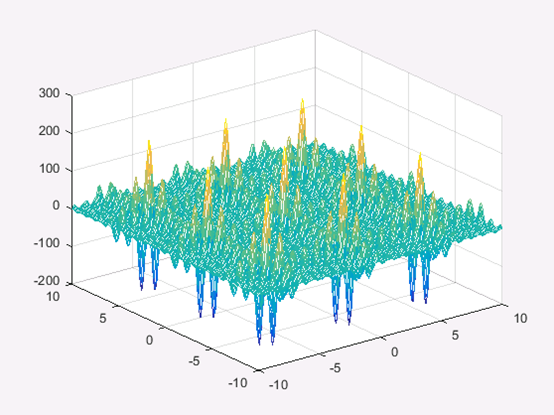
从函数图形可以看出,该函数有很多局部极小值,很难用传统的梯度下降方法进行全局寻优。
自适应变异是借鉴遗传算法中的变异思想,在PSO算法中引入变异操作,即对某些变量以一定的概率重新初始化。变异操作拓展了在迭代中不断缩小的种群搜索空间,使粒子能够跳出先前搜索到的最优值位置,在更大的空间中开展搜索,同时保持了种群多样性,提高算法寻找更优值的可能性。因此,在普通粒子群算法的基础上引入简单变异算子,在粒子每次更新之后,以一定概率重新初始化粒子。
本案例群体的粒子数为50,每个粒子的维数为2,算法迭代进化次数为500。加速度因子 c 1 = 1.4 c_1=1.4 c1=1.4, c 2 = 1.5 c_2=1.5 c2=1.5,惯性权重 ω = 0.8 \omega = 0.8 ω=0.8。
适应度函数代码如下:
function y = funShubert(x)
% 函数用于计算粒子适应度值
% x input 输入粒子
% y output 粒子适应度值 h1=0;h2=0;for i=1:5h1 = h1+i*cos((i+1)*x(1)+i);h2 = h2+i*cos((i+1)*x(2)+i);endy = h1*h2;
end
自适应变异PSO算法代码如下:
%% 清空环境
clc
clear
%% 参数初始化
c1 = 1.4;c2 = 1.5; %加速度因子
maxgen = 500; %进化次数
sizepop = 50; %种群规模
w = 0.8; %惯性权重
Vmax = 5;Vmin = -5; %速度最大值,最小值
popmax = 10;popmin = -10; %个体最大值,最小值
pop = zeros(sizepop,2); %种群
V = zeros(sizepop,2); %速度
fitness = zeros(sizepop,1); %适应度
trace = zeros(maxgen,1); %结果
%% 随机产生一个群体,初始粒子和速度
for i=1:sizepoppop(i,:) = 10*rands(1,2); %初始种群V(i,:) = 5*rands(1,2); %初始化速度fitness(i) = funShubert(pop(i,:)); %计算染色体的适应度
end
%% 个体极值和群体极值
[bestfitness, bestindex] = min(fitness);
Gbest = pop(bestindex,:); %全局最佳
fitnessGbest = bestfitness; %全局最佳适应度值
Pbest = pop; %个体最佳
fitnessPbest = fitness; %个体最佳适应度值
%% 迭代寻优
for i=1:maxgen for j=1:sizepop V(j,:) = w*V(j,:) + c1*rand*(Pbest(j,:) - pop(j,:)) +...%速度更新c2*rand*(Gbest - pop(j,:));V(j,V(j,:)>Vmax) = Vmax;V(j,V(j,:)<Vmin) = Vmin; pop(j,:) = pop(j,:)+V(j,:); %群体更新pop(j,pop(j,:)>popmax) = popmax;pop(j,pop(j,:)<popmin) = popmin; if rand>0.9 %自适应变异 pop(j,:) = rands(1,2);end fitness(j) = funShubert(pop(j,:)); %适应度值 endfor j=1:sizepop if fitness(j) < fitnessPbest(j) %个体最优更新Pbest(j,:) = pop(j,:);fitnessPbest(j) = fitness(j);end if fitness(j) < fitnessGbest %群体最优更新Gbest = pop(j,:);fitnessGbest = fitness(j);endend trace(i)=fitnessGbest; disp([Gbest,fitnessGbest]);
end
%% 结果分析
plot(trace)
title('最优个体适应度');
xlabel('进化代数');
ylabel('适应度');
算法结果如下:
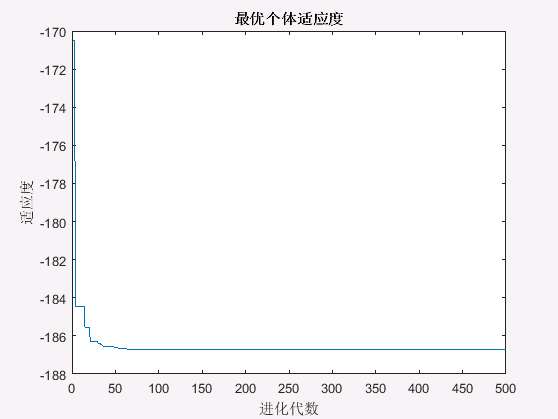
最终得到的个体适应度值为-186.7309,对应的例子位置为 ( − 1.4252 , − 0.8003 ) (-1.4252,-0.8003) (−1.4252,−0.8003),自适应变异PSO算法寻优得到最优值接近函数实际最优值,说明该算法具有较强的函数极值寻优能力。
五、补充
惯性权重 ω \omega ω体现的是粒子当前速度多大程度上继承先前的速度,Shi.Y最先将惯性权重 ω \omega ω引入到PSO算法中,并分析指出一个较大的惯性权值有利于全局搜索,而一个较小的惯性权值则更有利于局部搜索。为了更好地平衡算法的全局搜索与局部搜索能力,其提出了线性递减惯性权重(Linear Decreasing Inertia Weight,LDIW),即
ω ( t ) = ω s t a r t − ( ω s t a r t − ω e n d ) × t T m a x \omega(t)=\omega_{start}-(\omega_{start}-\omega_{end})\times\frac{t}{T_{max}} ω(t)=ωstart−(ωstart−ωend)×Tmaxt
式中, ω s t a r t \omega_{start} ωstart为初始惯性权重, ω e n d \omega_{end} ωend为迭代至最大次数时的惯性权重, t t t为当前迭代次数, T m a x T_max Tmax为最大迭代次数。
一般来说,惯性权重取值为 ω s t a r t = 0.9 \omega_{start}=0.9 ωstart=0.9, ω e n d = 0.4 \omega_{end}=0.4 ωend=0.4时算法性能最好。这样,随着迭代的进行,惯性权重由0.9线性递减至0.4,迭代初期较大的惯性权重使算法保持了较强的全局搜索能力,而迭代后期较小的惯性权值有利于算法进行更精确的局部搜索。
线性惯性权重只是一种经验做法,常用的惯性权重的选择还包括以下几种:
ω ( t ) = ω s t a r t − ( ω s t a r t − ω e n d ) × ( t T m a x ) 2 \omega(t)=\omega_{start}-(\omega_{start}-\omega_{end})\times(\frac{t}{T_{max}})^2 ω(t)=ωstart−(ωstart−ωend)×(Tmaxt)2
ω ( t ) = ω s t a r t − ( ω s t a r t − ω e n d ) × ( 2 t T m a x − ( t T m a x ) 2 ) \omega(t)=\omega_{start}-(\omega_{start}-\omega_{end})\times(\frac{2t}{T_{max}}-(\frac{t}{T_{max}})^2) ω(t)=ωstart−(ωstart−ωend)×(Tmax2t−(Tmaxt)2)
六、练习
求测试函数的最小值,以及最小值点。
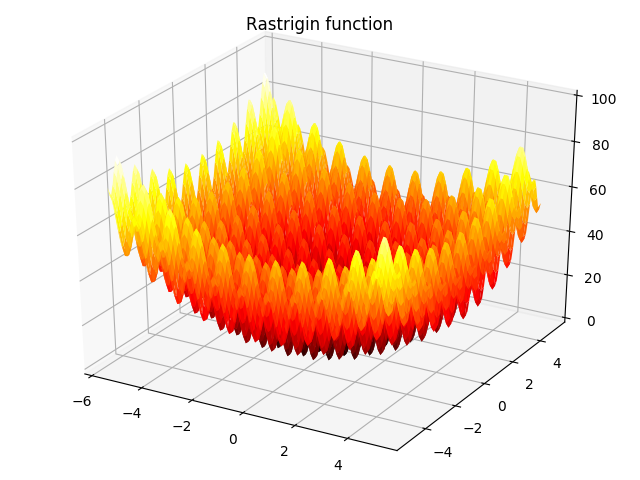
1. Rastrigin function:
f ( x ) = A n + ∑ i = 1 n [ x i 2 − A cos ( 2 π x i ) ] , − 5.12 ≤ x i ≤ 5.12 f(\bm x)=A_n+\sum_{i=1}^{n}{[x_i^2-A\cos (2\pi x_i)]},-5.12\leq x_i\leq 5.12 f(x)=An+i=1∑n[xi2−Acos(2πxi)],−5.12≤xi≤5.12
当 A = 10 , n = 2 A=10,n=2 A=10,n=2时,如下图所示:
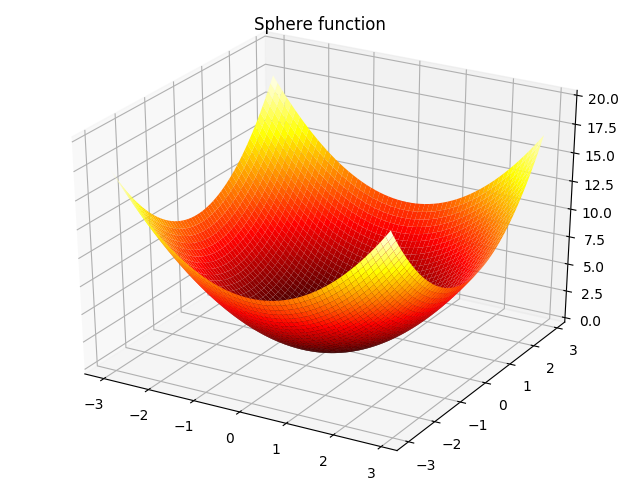
2. Sphere function:
f ( x ) = ∑ i = 1 n x i 2 , − ∞ ≤ x i ≤ ∞ f(\bm x) = \sum_{i=1}^{n}{x_i^2},-\infty\leq x_i \leq \infty f(x)=i=1∑nxi2,−∞≤xi≤∞
当 n = 2 n=2 n=2时,如下图所示:
3. Beale function:
f ( x , y ) = ( 1.5 − x + x y ) 2 + ( 2.25 − x + x y 2 ) 2 + ( 2.625 − x + x y 3 ) 2 , − 4.5 ≤ x , y ≤ 4.5 f(x,y)=(1.5-x+xy)^2+(2.25-x+xy^2)^2+(2.625-x+xy^3)^2,-4.5\leq x,y\leq 4.5 f(x,y)=(1.5−x+xy)2+(2.25−x+xy2)2+(2.625−x+xy3)2,−4.5≤x,y≤4.5
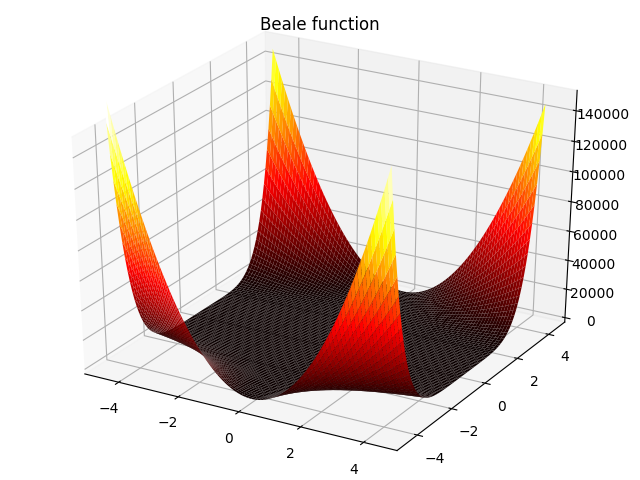
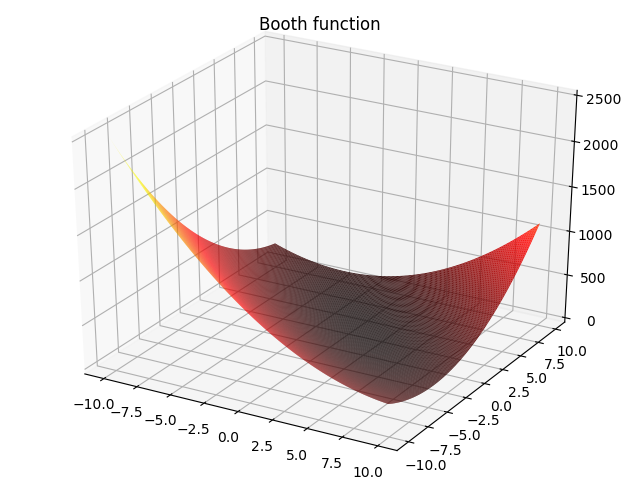
4. Booth function:
f ( x , y ) = ( x + 2 y − 7 ) 2 + ( 2 x + y − 5 ) 2 , − 10 ≤ x , y ≤ 10 f(x,y)=(x+2y-7)^2+(2x+y-5)^2,-10\leq x,y\leq 10 f(x,y)=(x+2y−7)2+(2x+y−5)2,−10≤x,y≤10
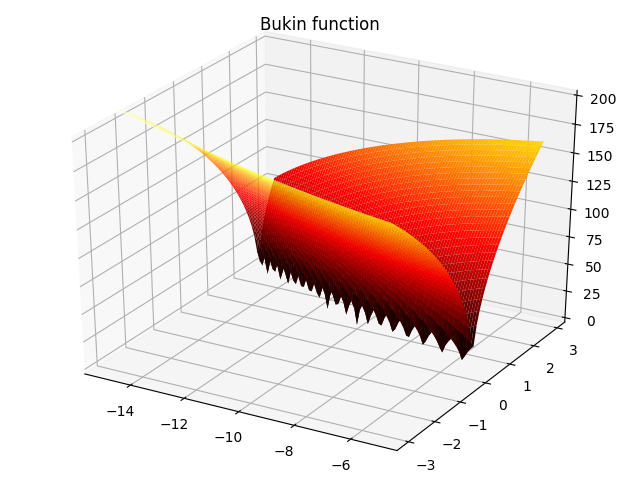
5. Bukin function:
f ( x , y ) = 100 ∣ y − 0.01 x 2 ∣ + 0.01 ∣ x + 10 ∣ , − 15 ≤ x ≤ − 5 , − 3 ≤ y ≤ 3 f(x,y)=100\sqrt{|y-0.01x^2|}+0.01|x+10|,-15\leq x\leq -5,-3\leq y\leq 3 f(x,y)=100∣y−0.01x2∣+0.01∣x+10∣,−15≤x≤−5,−3≤y≤3
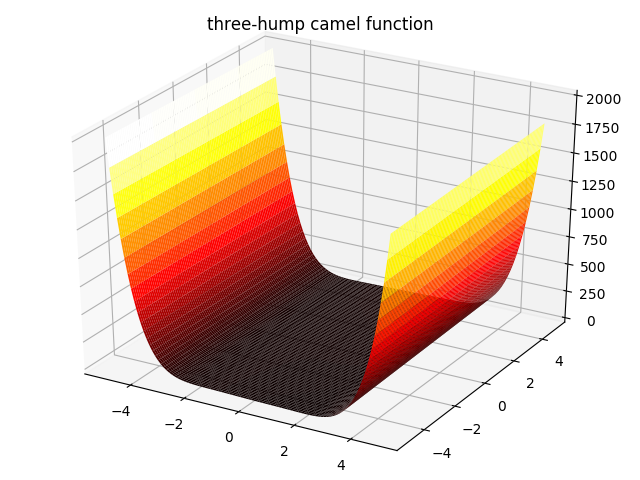
6. three-hump camel function:
f ( x , y ) = 2 x 2 − 1.05 x 4 + x 6 6 + x y + y 2 , − 5 ≤ x , y ≤ 5 f(x,y)=2x^2-1.05x^4+\frac{x^6}{6}+xy+y^2,-5\leq x,y\leq 5 f(x,y)=2x2−1.05x4+6x6+xy+y2,−5≤x,y≤5
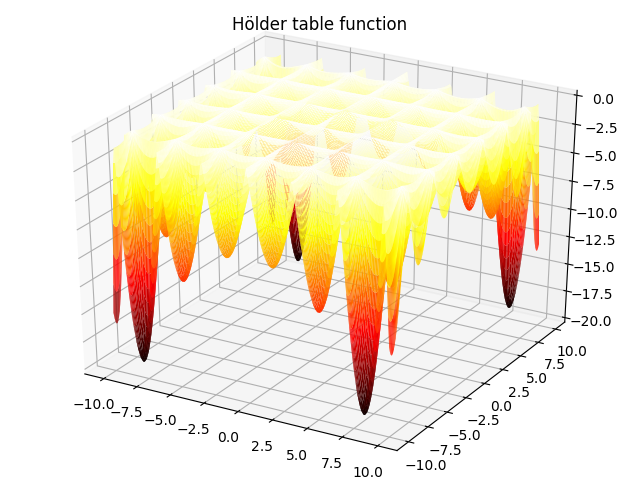
7. Hölder table function:
f ( x , y ) = − ∣ sin x cos y exp ( ∣ 1 − x 2 + y 2 π ∣ ) ∣ , − 10 ≤ x , y ≤ 10 f(x,y)=-|\sin x \cos y \exp(|1-\frac{\sqrt{x^2+y^2}}{\pi}|)|,-10\leq x,y\leq 10 f(x,y)=−∣sinxcosyexp(∣1−πx2+y2∣)∣,−10≤x,y≤10