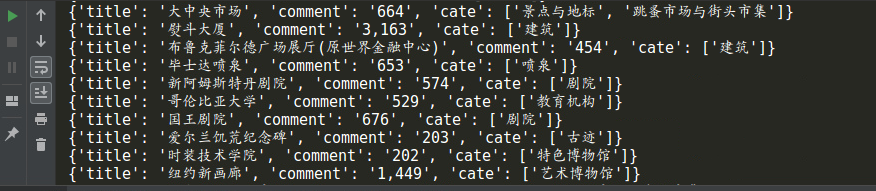
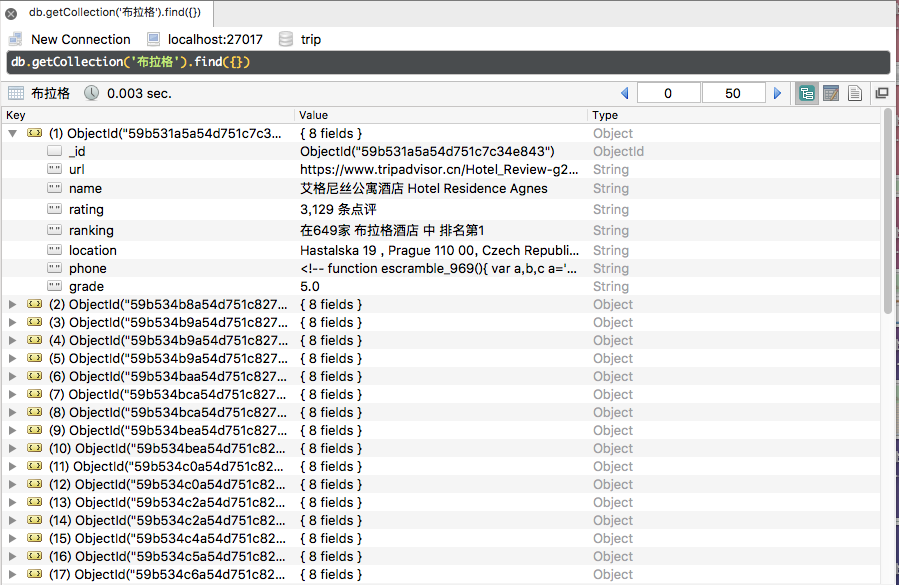
需求
网站入口:www.tripadvisor.com

网页下端,遍历点开进入所有城市链接:

点击后进入该城市的所有hotel

代码
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
# Created on 2018-09-06 11:16:59
# Project: trip_hotelfrom pyspider.libs.base_handler import *
import datetime
import re
import json
import copyfrom pymongo import MongoClient# 连接线下数据库
DB_IP = ''
DB_PORT = #DB_IP = '127.0.0.1'
#DB_PORT = 27017client = MongoClient(host=DB_IP, port=DB_PORT)# admin 数据库有帐号,连接-认证-切换
db_auth = client.admin
db_auth.authenticate("", "")DB_NAME = 'research'
db = client[DB_NAME]def get_today():return datetime.datetime.strptime(datetime.datetime.now().strftime('%Y-%m-%d'), '%Y-%m-%d')class Handler(BaseHandler):crawl_config = {'headers': {'user-agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36','cookie':'SetCurrency=USD'},'proxy': 'http://10.15.100.94:6666','retries': 5}url = 'https://www.tripadvisor.com/'@every(minutes=24 * 60)def on_start(self):self.crawl(self.url, callback=self.index_page)@config(age=60)def index_page(self, response):page = response.etreecity_list = page.xpath("//div[@class='customSelection']/div[@class='boxhp collapsibleLists']/div[@class='section']/div[@class='ui_columns' or @class='ui_columns no-collapse']/ul[@class='lst ui_column is-4']/li[@class='item']")print(len(city_list))base_url = 'https://www.tripadvisor.com'for each in city_list:city_name = each.xpath("./a/text()")[0]city_link = base_url + each.xpath("./a/@href")[0]print(city_name, '---', city_link)save = {"city": city_name}self.crawl(city_link, callback=self.parse_city, save=save)@config(age=60)def parse_city(self, response):page = response.etreebase_url = 'https://www.tripadvisor.com'## 国家country = page.xpath("//div[@id='taplc_trip_planner_breadcrumbs_0']/ul[@class='breadcrumbs']/li[1]/a/span/text()")[0]print(country)## 第一需求表## 翻页#page_list = [response.url]#page_list.extend([base_url+i for i in page.xpath("//div[@class='pageNumbers']/a/@href")])#print(len(page_list))save = {"country": country, "city": response.save["city"]}#for each in page_list:# self.crawl(each, callback=self.parse_page, save=save)tail_url = page.xpath("//div[@class='pageNumbers']/a[last()]/@href")[0]total_num = re.findall('oa(\d+)-',tail_url)[0]page_url = base_url + tail_url.replace(total_num,'{}')print(page_url)total_page = int(total_num)//30for i in range(total_page+1):if i == 0:self.crawl(response.url, callback=self.parse_page, save=save)else:self.crawl(page_url.format(30*i), callback=self.parse_page, save=save)## 第三个需求表new_url = response.url.replace('Hotels','Tourism').replace('Hotels', 'Vacations')print(new_url)self.crawl(new_url, callback=self.parse_detail, save=save)def parse_detail(self, response):page = response.etreehotel_num = page.xpath("//div[@class='navLinks']/ul/li[@class='hotels twoLines']//span[@class='typeQty']/text()")hotel_num = hotel_num[0] if hotel_num else ''print(hotel_num)hotel_reviews = page.xpath("//div[@class='navLinks']/ul/li[@class='hotels twoLines']//span[@class='contentCount']/text()")hotel_reviews = hotel_reviews[0] if hotel_reviews else ''print(hotel_reviews)rentals_num = page.xpath("//div[@class='navLinks']/ul/li[@class='vacationRentals twoLines']//span[@class='typeQty']/text()")rentals_num = rentals_num[0] if rentals_num else ''print(rentals_num) rentals_reviews = page.xpath("//div[@class='navLinks']/ul/li[@class='vacationRentals twoLines']//span[@class='contentCount']/text()")rentals_reviews = rentals_reviews[0] if rentals_reviews else ''print(rentals_reviews)thingstodo_num = page.xpath("//div[@class='navLinks']/ul/li[@class='attractions twoLines']//span[@class='typeQty']/text()")thingstodo_num = thingstodo_num[0] if thingstodo_num else ''print(thingstodo_num)thingstodo_reviews = page.xpath("//div[@class='navLinks']/ul/li[@class='attractions twoLines']//span[@class='contentCount']/text()")thingstodo_reviews = thingstodo_reviews[0] if thingstodo_reviews else ''print(thingstodo_reviews)restaurant_num = page.xpath("//div[@class='navLinks']/ul/li[@class='restaurants twoLines']//span[@class='typeQty']/text()")restaurant_num = restaurant_num[0] if restaurant_num else ''print(restaurant_num)restaurant_reviews = page.xpath("//div[@class='navLinks']/ul/li[@class='restaurants twoLines']//span[@class='contentCount']/text()")restaurant_reviews = restaurant_reviews[0] if restaurant_reviews else ''print(restaurant_reviews) forum_post = page.xpath("//div[@class='navLinks']/ul/li[@class='forum twoLines']//span[@class='contentCount']/text()")forum_post = forum_post[0] if forum_post else ''print(forum_post) result = {"country": response.save["country"],"city": response.save["city"],"hotel_num": hotel_num,"hotel_reviews": hotel_reviews,"rentals_num": rentals_num,"rentals_reviews": rentals_reviews,"thingstodo_num": thingstodo_num,"thingstodo_reviews": thingstodo_reviews,"restaurant_num": restaurant_num,"restaurant_reviews": restaurant_reviews,"forum_post": forum_post,"date": get_today(),"collection": 'trip_total_daily_data'}yield result@config(age=60)def parse_page(self, response):page = response.etree## 酒店列表#content_list = page.xpath("//div[@id='taplc_hsx_hotel_list_lite_dusty_hotels_combined_sponsored_0']/div[@class='prw_rup prw_meta_hsx_responsive_listing ui_section listItem ']")content_list = page.xpath("//div[@id='taplc_hsx_hotel_list_lite_dusty_hotels_combined_sponsored_0']/div/div[@class!='prw_rup prw_common_ad_resp ui_section is-ad ']")print(len(content_list))for each in content_list:price_1 = each.xpath(".//div[@class='priceBlock ui_column is-12-tablet']//div[@class='price autoResize']/text()")price_1 = (price_1[0] if price_1 else '')price_origin = each.xpath(".//div[@class='priceBlock ui_column is-12-tablet']//div[@class='xthrough autoResize']/div/text()")if price_origin:price_origin = price_origin[0]else:price_origin = ''hotel_name = each.xpath(".//div[@data-prwidget-name='meta_hsx_listing_name']//a/text()")[0]hotel_id = each.xpath(".//div[@data-prwidget-name='meta_hsx_listing_name']//a/@id")[0]print(hotel_name, hotel_id)print(price_1, price_origin)reviews = each.xpath(".//a[@class='review_count']/text()")[0]print(reviews)web_1 = each.xpath(".//div[@class='priceBlock ui_column is-12-tablet']//div[@class='provider autoResize']/text()")[0]print(web_1)web_2 = each.xpath(".//div[@class='text-links is-shown-at-tablet has_commerce']/div[1]/div[@class='vendor']/span/text()")web_2 = (web_2[0] if web_2 else '')price_2 = each.xpath(".//div[@class='text-links is-shown-at-tablet has_commerce']/div[1]/div[@class='price autoResize']/text()")price_2 = (price_2[0] if price_2 else '')print(web_2, price_2)web_3 = each.xpath(".//div[@class='text-links is-shown-at-tablet has_commerce']/div[2]/div[@class='vendor']/span/text()")web_3 = (web_3[0] if web_3 else '')price_3 = each.xpath(".//div[@class='text-links is-shown-at-tablet has_commerce']/div[2]/div[@class='price autoResize']/text()")price_3 = (price_3[0] if price_3 else '')print(web_3, price_3)web_4 = each.xpath(".//div[@class='text-links is-shown-at-tablet has_commerce']/div[3]/div[@class='vendor']/span/text()")web_4 = (web_4[0] if web_4 else '')price_4 = each.xpath(".//div[@class='text-links is-shown-at-tablet has_commerce']/div[3]/div[@class='price autoResize']/text()")price_4 = (price_4[0] if price_4 else '')print(web_4, price_4)result = {"date": get_today(),"country": response.save["country"],"city": response.save["city"],"hotel_name": hotel_name,"hotel_id": hotel_id,"reviews": reviews,"price_origin": price_origin,"1_web": web_1,"1_price": price_1,"2_web": web_2,"2_price": price_2,"3_web": web_3,"3_price": price_3,"4_web": web_4,"4_price": price_4,"update_time": datetime.datetime.now(),"collection": "trip_hotel_daily_data"}yield resultdef on_result(self, result):super(Handler, self).on_result(result)if not result:returncol_name = result.pop("collection")col = db[col_name]if col_name == 'trip_hotel_daily_data': update_key = {'date': result["date"],'hotel_id': result["hotel_id"]}elif col_name == 'trip_total_daily_data':update_key = {'date': result["date"],'city': result["city"]}col.update(update_key, {'$set': result}, upsert=True)