Numpy基础教程:
- https://blog.csdn.net/qq_43328040/article/details/106601065
————————————————————————————————————
文章目录
- 一.ndarray对象内幕
- 1.1 Numpy dtype 层次结构
- 二.高阶数组操作
- 2.1重塑数组
- 2.2 C顺序和Fortran顺序
- 2.3 连接和分隔数组
- 2.31堆叠助手:r_和c_
- 2.4 重复元素: tile和repeat
- 2.5 神奇索引的等价方法:take和put
- 三.广播
- 3.1 在其他轴上广播
- 3.2通过广播设定数组的值
- 四. 高阶ufunc用法
- 4.1 ufunc实例方法
- 4.2使用python编写新的ufunc方法
- 五.结构化和记录数组
- 5.1 嵌套dtype和多维字段
- 5.2 为什么使用结构化数组
- 六.关于NumPy排序
- 6.1 间接排序:argsort和lexsort
- 6.2 其他的排序算法
- 6.3 数组的部分排序
- 6.4 numpy.searchsorted: 在已排序的数组寻找元素
- 七.使用Numba编写快速NumPy函数
- 7.1用Numba创建自定义numpy.ufunc对象
- 八.高阶数组输入和输出
- 8.1 内存映射文件
- 九.性能技巧
- 9.1连续内存的重要性
一.ndarray对象内幕

NumPy的ndarray提供了一种将同质数据块(可以是连续或跨越)解释为多维数组对象的方式。正如你之前所看到的那样,数据类型(dtype)决定了数据的解释方式,比如浮点数、整数、布尔值等。
ndarray如此强大的部分原因是所有数组对象都是数据块的一个跨度视图(strided view)。你可能想知道数组视图arr[::2,::-1]不复制任何数据的原因是什么。简单地说,ndarray不只是一块内存和一个dtype,它还有跨度信息,这使得数组能以各种步幅(step size)在内存中移动。更准确地讲,ndarray内部由以下内容组成:
* 一个指向数据(内存或内存映射文件中的一块数据)的指针。
* 数据类型或dtype,描述在数组中的固定大小值的格子。
* 一个表示数组形状(shape)的元组。
* 一个跨度元组(stride),其中的整数指的是为了前进到当前维度下一个元素需要“跨过”的字节数。
下图说明了ndarray的内部结构。

例如,一个10×5的数组,其形状为(10,5):
import numpy as np
np.ones((10, 5)).shape
(10, 5)
一个典型的(C顺序,稍后将详细讲解)3×4×5的float64(8个字节)数组,其跨度为(160,40,8) —— 知道跨度是非常有用的,通常,跨度在一个轴上越大,沿这个轴进行计算的开销就越大:
np.ones((3, 4, 5), dtype=np.float64).strides
(160, 40, 8)
虽然NumPy用户很少会对数组的跨度信息感兴趣,但它们却是构建非复制式数组视图的重要因素。跨度甚至可以是负数,这样会使数组在内存中后向移动,比如在切片obj[::-1]或obj[:,::-1]中就是这样的。
1.1 Numpy dtype 层次结构
你可能偶尔需要检查数组中所包含的是否是整数、浮点数、字符串或Python对象。因为浮点数的种类很多(从float16到float128),判断dtype是否属于某个大类的工作非常繁琐。幸运的是,dtype都有一个超类(比如np.integer和np.floating),它们可以跟np.issubdtype函数结合使用:
ints = np.ones(10, dtype=np.uint16)
floats = np.ones(10, dtype=np.float32)
np.issubdtype(ints.dtype, np.integer)
True
np.issubdtype(floats.dtype, np.floating)
True
调用dtype的mro方法即可查看其所有的父类:
np.float64.mro()[numpy.float64,numpy.floating,numpy.inexact,numpy.number,numpy.generic,float,object]
然后得到:
np.issubdtype(ints.dtype, np.number)True
大部分NumPy用户完全不需要了解这些知识,但是这些知识偶尔还是能派上用场的。下图说明了dtype体系以及父子类关系。

二.高阶数组操作

除花式索引、切片、布尔条件取子集等操作之外,数组的操作方式还有很多。虽然pandas中的高级函数可以处理数据分析工作中的许多重型任务,但有时你还是需要编写一些在现有库中找不到的数据算法。
2.1重塑数组
多数情况下,你可以无需复制任何数据,就将数组从一个形状转换为另一个形状。只需向数组的实例方法reshape传入一个表示新形状的元组即可实现该目的。例如,假设有一个一维数组,我们希望将其重新排列为一个矩阵
arr = np.arange(8)
arrarray([0, 1, 2, 3, 4, 5, 6, 7])
arr.reshape((4, 2))array([[0, 1],[2, 3],[4, 5],[6, 7]])

按C顺序(行方向)和按F顺序(列方向)的重塑
多维数组也能被重塑:
arr.reshape((4, 2)).reshape((2, 4))array([[0, 1, 2, 3],[4, 5, 6, 7]])
作为参数的形状的其中一维可以是-1,它表示该维度的大小由数据本身推断而来:
arr = np.arange(15)
arr.reshape((5, -1))array([[ 0, 1, 2],[ 3, 4, 5],[ 6, 7, 8],[ 9, 10, 11],[12, 13, 14]])
与reshape将一维数组转换为多维数组的运算过程相反的运算通常称为扁平化(flattening)或分散化(raveling):
arr = np.arange(15).reshape((5, 3))
arrarray([[ 0, 1, 2],[ 3, 4, 5],[ 6, 7, 8],[ 9, 10, 11],[12, 13, 14]])
arr.ravel()array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14])
如果结果中的值在原始数组中是连续的,则ravel不会产生源数据的副本。flatten方法的行为类似于ravel,只不过它总是返回数据的副本:
数组可以被重塑或散开为别的顺序。这对NumPy新手来说是一个比较微妙的问题,所以在下一小节中我们将专门讲解这个问题。
2.2 C顺序和Fortran顺序
NumPy允许你更为灵活地控制数据在内存中的布局。默认情况下,NumPy数组是按行优先顺序创建的。在空间方面,这就意味着,对于一个二维数组,每行中的数据项是被存放在相邻内存位置上的。另一种顺序是列优先顺序,它意味着每列中的数据项是被存放在相邻内存位置上的。
由于一些历史原因,行和列优先顺序又分别称为C和Fortran顺序。在FORTRAN 77中,矩阵全都是列优先的。
像reshape和reval这样的函数,都可以接受一个表示数组数据存放顺序的order参数。一般可以是’C’或’F’(还有’A’和’K’等不常用的选项,具体请参考NumPy的文档)。图A-3对此进行了说明:
arr = np.arange(12).reshape((3, 4))
arrarray([[ 0, 1, 2, 3],[ 4, 5, 6, 7],[ 8, 9, 10, 11]])
arr.ravel()array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])
arr.ravel('F')array([ 0, 4, 8, 1, 5, 9, 2, 6, 10, 3, 7, 11])
二维或更高维数组的重塑过程比较令人费解。C和Fortran顺序的关键区别就是维度的行进顺序:
C/行优先顺序:先经过更高的维度(例如,轴1会先于轴0被处理)。
Fortran/列优先顺序:后经过更高的维度(例如,轴0会先于轴1被处理)。
2.3 连接和分隔数组
numpy.concatenate可以按指定轴将一个由数组组成的序列(如元组、列表等)连接到一起:
arr1 = np.array([[1, 2, 3], [4, 5, 6]])
arr2 = np.array([[7, 8, 9], [10, 11, 12]])
np.concatenate([arr1, arr2], axis=0)array([[ 1, 2, 3],[ 4, 5, 6],[ 7, 8, 9],[10, 11, 12]])
np.concatenate([arr1, arr2], axis=1)array([[ 1, 2, 3, 7, 8, 9],[ 4, 5, 6, 10, 11, 12]])
对于常见的连接操作,NumPy提供了一些比较方便的方法(如vstack和hstack)。因此,上面的运算还可以表达为:
np.vstack((arr1, arr2))array([[ 1, 2, 3],[ 4, 5, 6],[ 7, 8, 9],[10, 11, 12]])
np.hstack((arr1, arr2))array([[ 1, 2, 3, 7, 8, 9],[ 4, 5, 6, 10, 11, 12]])
与此相反,split用于将一个数组沿指定轴拆分为多个数组:
arr = np.random.randn(5, 2)
arrarray([[-0.27526867, -0.67921962],[-0.92972287, -0.35201398],[-0.2558084 , -0.28675778],[-1.26047769, 1.43530095],[ 0.69262824, -0.57397718]])
first, second, third = np.split(arr, [1, 3])
firstarray([[-0.27526867, -0.67921962]])
secondarray([[-0.92972287, -0.35201398],[-0.2558084 , -0.28675778]])
thirdarray([[-1.26047769, 1.43530095],[ 0.69262824, -0.57397718]])
传入到np.split的值[1,3]指示在哪个索引处分割数组。
下表列出了所有关于数组连接和拆分的函数,其中有些是专门为了方便常见的连接运算而提供的。

2.31堆叠助手:r_和c_
NumPy命名空间中有两个特殊的对象——r_和c_,它们可以使数组的堆叠操作更为简洁:
arr = np.arange(6)
arr1 = arr.reshape((3, 2))
arr2 = np.random.randn(3, 2)
np.r_[arr1, arr2]array([[ 0.412107 , -0.23394682],[-0.01930548, -0.99743316],[-0.85863788, -0.40004808]])
np.r_[arr1, arr2]array([[ 0. , 1. ],[ 2. , 3. ],[ 4. , 5. ],[ 0.412107 , -0.23394682],[-0.01930548, -0.99743316],[-0.85863788, -0.40004808]])
np.c_[np.r_[arr1, arr2], arr]array([[ 0. , 1. , 0. ],[ 2. , 3. , 1. ],[ 4. , 5. , 2. ],[ 0.412107 , -0.23394682, 3. ],[-0.01930548, -0.99743316, 4. ],[-0.85863788, -0.40004808, 5. ]])
它还可以将切片转换成数组:
np.c_[1:6, -10:-5]array([[ 1, -10],[ 2, -9],[ 3, -8],[ 4, -7],[ 5, -6]])
2.4 重复元素: tile和repeat
对数组进行重复以产生更大数组的工具主要是repeat和tile这两个函数。repeat会将数组中的各个元素重复一定次数,从而产生一个更大的数组:
arr = np.arange(3)
arr.repeat(3)array([0, 0, 0, 1, 1, 1, 2, 2, 2])
默认情况下,如果传入的是一个整数,则各元素就都会重复那么多次。如果传入的是一组整数,则各元素就可以重复不同的次数:
arr.repeat([2, 3, 4])array([0, 0, 1, 1, 1, 2, 2, 2, 2])
对于多维数组,还可以让它们的元素沿指定轴重复:
arr = np.random.randn(2, 2)
arrarray([[ 0.88588819, -1.25990033],[ 1.62085848, 0.92912152]])
arr.repeat(2, axis=0)array([[ 0.88588819, -1.25990033],[ 0.88588819, -1.25990033],[ 1.62085848, 0.92912152],[ 1.62085848, 0.92912152]])
注意,如果没有设置轴向,则数组会被扁平化,这可能不会是你想要的结果。同样,在对多维进行重复时,也可以传入一组整数,这样就会使各切片重复不同的次数:
arr.repeat([2, 3], axis=0)array([[ 0.88588819, -1.25990033],[ 0.88588819, -1.25990033],[ 1.62085848, 0.92912152],[ 1.62085848, 0.92912152],[ 1.62085848, 0.92912152]])
arr.repeat([2, 3], axis=1)array([[ 0.88588819, 0.88588819, -1.25990033, -1.25990033, -1.25990033],[ 1.62085848, 1.62085848, 0.92912152, 0.92912152, 0.92912152]])
tile的功能是沿指定轴向堆叠数组的副本。你可以形象地将其想象成“铺瓷砖”:
arrarray([[ 0.88588819, -1.25990033],[ 1.62085848, 0.92912152]])
np.tile(arr, 2)array([[ 0.88588819, -1.25990033, 0.88588819, -1.25990033],[ 1.62085848, 0.92912152, 1.62085848, 0.92912152]])
第二个参数是瓷砖的数量。对于标量,瓷砖是水平铺设的,而不是垂直铺设。它可以是一个表示“铺设”布局的元组:
arrarray([[ 0.88588819, -1.25990033],[ 1.62085848, 0.92912152]])
np.tile(arr, (2, 1))array([[ 0.88588819, -1.25990033],[ 1.62085848, 0.92912152],[ 0.88588819, -1.25990033],[ 1.62085848, 0.92912152]])
np.tile(arr, (3, 2))array([[ 0.88588819, -1.25990033, 0.88588819, -1.25990033],[ 1.62085848, 0.92912152, 1.62085848, 0.92912152],[ 0.88588819, -1.25990033, 0.88588819, -1.25990033],[ 1.62085848, 0.92912152, 1.62085848, 0.92912152],[ 0.88588819, -1.25990033, 0.88588819, -1.25990033],[ 1.62085848, 0.92912152, 1.62085848, 0.92912152]])
2.5 神奇索引的等价方法:take和put
在之前我们讲过,获取和设置数组子集的一个办法是通过整数数组使用花式索引:
arr = np.arange(10) * 100
inds = [7, 1, 2, 6]
arr[inds]array([700, 100, 200, 600])
ndarray还有其它方法用于获取单个轴向上的选区:
arr.take(inds)array([700, 100, 200, 600])
put函数用于将指定的选区进行数值替换
arr.put(inds, 42)
arrarray([ 0, 42, 42, 300, 400, 500, 42, 42, 800, 900])
arr.put(inds, [40, 41, 42, 43])
arrarray([ 0, 41, 42, 300, 400, 500, 43, 40, 800, 900])
要在其它轴上使用take,只需传入axis关键字即可:
inds = [2, 0, 2, 1]
arr = np.random.randn(2, 4)
arrarray([[ 1.46902272, 0.01935251, -0.6950622 , 2.24996752],[ 1.03686395, -0.67560415, -0.83536367, -0.27154602]])
arr.take(inds, axis=1)array([[-0.6950622 , 1.46902272, -0.6950622 , 0.01935251],[-0.83536367, 1.03686395, -0.83536367, -0.67560415]])
put不接受axis参数,它只会在数组的扁平化版本(一维,C顺序)上进行索引。因此,在需要用其他轴向的索引设置元素时,最好还是使用花式索引。
三.广播

广播(broadcasting)指的是不同形状的数组之间的算术运算的执行方式。它是一种非常强大的功能,但也容易令人误解,即使是经验丰富的老手也是如此。将标量值跟数组合并时就会发生最简单的广播:
arr = np.arange(5)
arrarray([0, 1, 2, 3, 4])
arr * 4array([ 0, 4, 8, 12, 16])
这里我们说:在这个乘法运算中,标量值4被广播到了其他所有的元素上。
看一个例子,我们可以通过减去列平均值的方式对数组的每一列进行距平化处理。这个问题解决起来非常简单:
arr = np.random.randn(4, 3)
arr.mean(0)array([-1.44187575, 0.13700902, -0.06376677])
demeaned = arr - arr.mean(0)
demeanedarray([[ 0.79875636, -1.16113748, -0.26786685],[-1.56813261, 2.14316652, 1.48499361],[ 0.32467283, -0.1763157 , 1.12517759],[ 0.44470342, -0.80571333, -2.34230434]])
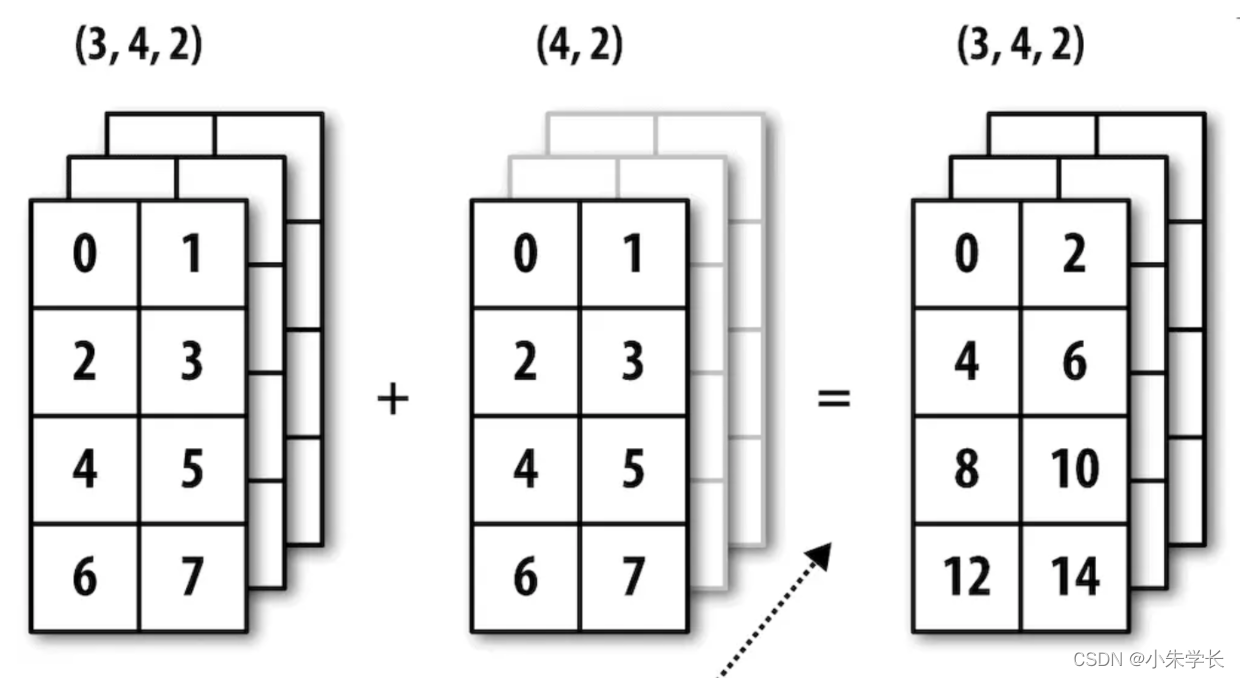
下图形象地展示了该过程。用广播的方式对行进行距平化处理会稍微麻烦一些。幸运的是,只要遵循一定的规则,低维度的值是可以被广播到数组的任意维度的(比如对二维数组各列减去行平均值)。

于是就得到了:

虽然我是一名经验丰富的NumPy老手,但经常还是得停下来画张图并想想广播的原则。再来看一下最后那个例子,假设你希望对各行减去那个平均值。由于arr.mean(0)的长度为3,所以它可以在0轴向上进行广播:因为arr的结尾维度是3,所以它们是兼容的。
根据该原则,要在1轴向上做减法(即各行减去行平均值),较小的那个数组的形状必须是(4,1):
arrarray([[-0.64311939, -1.02412846, -0.33163362],[-3.01000836, 2.28017554, 1.42122684],[-1.11720292, -0.03930668, 1.06141082],[-0.99717233, -0.66870431, -2.40607111]])
row_means = arr.mean(1)
row_means.shape(4,)
row_means.reshape((4, 1))array([[-0.66629382],[ 0.23046467],[-0.03169959],[-1.35731592]])
demeaned = arr - row_means.reshape((4, 1))
demeanedarray([[ 0.02317443, -0.35783463, 0.3346602 ],[-3.24047303, 2.04971087, 1.19076216],[-1.08550333, -0.00760708, 1.09311041],[ 0.36014359, 0.68861161, -1.0487552 ]])
下图说明了该运算的过程。

图A-6展示了另外一种情况,这次是在一个三维数组上沿0轴向加上一个二维数组。

3.1 在其他轴上广播
高维度数组的广播似乎更难以理解,而实际上它也是遵循广播原则的。如果不然,你就会得到下面这样一个错误:
arr - arr.mean(1)---------------------------------------------------------------------------ValueError Traceback (most recent call last)<ipython-input-73-8b8ada26fac0> in <module>
----> 1 arr - arr.mean(1)ValueError: operands could not be broadcast together with shapes (4,3) (4,)
人们经常需要通过算术运算过程将较低维度的数组在除0轴以外的其他轴向上广播。根据广播的原则,较小数组的“广播维”必须为1。在上面那个行减均值的例子中,这就意味着要将行平均值的形状变成(4,1)而不是(4,):
arr - arr.mean(1).reshape((4, 1))array([[ 0.02317443, -0.35783463, 0.3346602 ],[-3.24047303, 2.04971087, 1.19076216],[-1.08550333, -0.00760708, 1.09311041],[ 0.36014359, 0.68861161, -1.0487552 ]])
对于三维的情况,在三维中的任何一维上广播其实也就是将数据重塑为兼容的形状而已。图A-7说明了要在三维数组各维度上广播的形状需求。

于是就有了一个非常普遍的问题(尤其是在通用算法中),即专门为了广播而添加一个长度为1的新轴。虽然reshape是一个办法,但插入轴需要构造一个表示新形状的元组。这是一个很郁闷的过程。因此,NumPy数组提供了一种通过索引机制插入轴的特殊语法。下面这段代码通过特殊的np.newaxis属性以及“全”切片来插入新轴:
arr = np.zeros((4, 4))
arr_3d = arr[:, np.newaxis, :]
arr_3d.shape(4, 1, 4)
arr_1d = np.random.normal(size=3)
arr_1d[:, np.newaxis]array([[1.58331572],[0.20398254],[0.52159683]])
arr_1d[np.newaxis, :]array([[1.58331572, 0.20398254, 0.52159683]])
因此,如果我们有一个三维数组,并希望对轴2减去均值,那么只需要编写下面这样的代码就可以了:
arr = np.random.randn(3, 4, 5)
depth_means = arr.mean(2)
depth_meansarray([[-0.48697362, 0.60461413, -0.73433923, 0.12402652],[-0.54290158, -0.87327633, 0.96338243, 0.07150238],[ 0.64337069, -0.5125288 , -0.42618718, -0.36957221]])
depth_means.shape(3, 4)
demeaned = arr - depth_means[:, :, np.newaxis]
demeaned.mean(2).astype('int')array([[0, 0, 0, 0],[0, 0, 0, 0],[0, 0, 0, 0]])
有些读者可能会想,在对指定轴进行距平化时,有没有一种既通用又不牺牲性能的方法呢?实际上是有的,但需要一些索引方面的技巧:
def demean_axis(arr, axis=0):means = arr.mean(axis)# This generalizes things like [:, :, np.newaxis] to N dimensionsindexer = [slice(None)] * arr.ndimindexer[axis] = np.newaxisreturn arr - means[indexer]3.2通过广播设定数组的值
算术运算所遵循的广播原则同样也适用于通过索引机制设置数组值的操作。对于最简单的情况,我们可以这样做:
arr = np.zeros((4, 3))
arr[:] = 5
arrarray([[5., 5., 5.],[5., 5., 5.],[5., 5., 5.],[5., 5., 5.]])
但是,假设我们想要用一个一维数组来设置目标数组的各列,只要保证形状兼容就可以了:
col = np.array([1.28, -0.42, 0.44, 1.6])
arr[:] = col[:, np.newaxis]
arrarray([[ 1.28, 1.28, 1.28],[-0.42, -0.42, -0.42],[ 0.44, 0.44, 0.44],[ 1.6 , 1.6 , 1.6 ]])
arr[:2] = [[-1.37], [0.509]]四. 高阶ufunc用法

虽然许多NumPy用户只会用到通用函数所提供的快速的元素级运算,但通用函数实际上还有一些高级用法能使我们丢开循环而编写出更为简洁的代码。
4.1 ufunc实例方法
NumPy的各个二元ufunc都有一些用于执行特定矢量化运算的特殊方法。下面我将通过几个具体的例子对它们进行说明。
reduce接受一个数组参数,并通过一系列的二元运算对其值进行聚合(可指明轴向)。例如,我们可以用np.add.reduce对数组中各个元素进行求和:
arr = np.arange(10)
np.add.reduce(arr)45
arr.sum()45
起始值取决于ufunc(对于add的情况,就是0)。如果设置了轴号,约简运算就会沿该轴向执行。这就使你能用一种比较简洁的方式得到某些问题的答案。在下面这个例子中,我们用np.logical_and检查数组各行中的值是否是有序的:
np.random.seed(12346)
arr = np.random.randn(5, 5)
arr[::2].sort(1)
arr[:, :-1] < arr[:, 1:]array([[ True, True, True, True],[False, True, False, False],[ True, True, True, True],[ True, False, True, True],[ True, True, True, True]])
np.logical_and.reduce(arr[:, :-1] < arr[:, 1:], axis=1)array([ True, False, True, False, True])
注意,logical_and.reduce跟all方法是等价的。
accumulate跟reduce的关系就像cumsum跟sum的关系那样。它产生一个跟原数组大小相同的中间“累计”值数组:
arr = np.arange(15).reshape((3, 5))
np.add.accumulate(arr, axis=1)array([[ 0, 1, 3, 6, 10],[ 5, 11, 18, 26, 35],[10, 21, 33, 46, 60]], dtype=int32)
outer用于计算两个数组的叉积:
arr = np.arange(3).repeat([1, 2, 2])
arrarray([0, 1, 1, 2, 2])
np.multiply.outer(arr, np.arange(5))array([[0, 0, 0, 0, 0],[0, 1, 2, 3, 4],[0, 1, 2, 3, 4],[0, 2, 4, 6, 8],[0, 2, 4, 6, 8]])
outer输出结果的维度是两个输入数据的维度之和:
x, y = np.random.randn(3, 4), np.random.randn(5)
result = np.subtract.outer(x, y)
result.shape(3, 4, 5)
最后一个方法reduceat用于计算“局部约简”,其实就是一个对数据各切片进行聚合的groupby运算。它接受一组用于指示如何对值进行拆分和聚合的“箱体边缘”:
arr = np.arange(10)
np.add.reduceat(arr, [0, 5, 8])array([10, 18, 17], dtype=int32)
最终结果是在arr[0:5]、arr[5:8]以及arr[8:]上执行的缩聚(此处是加和)。跟其他方法一样,这里也可以传入一个axis参数:
arr = np.multiply.outer(np.arange(4), np.arange(5))
arrarray([[ 0, 0, 0, 0, 0],[ 0, 1, 2, 3, 4],[ 0, 2, 4, 6, 8],[ 0, 3, 6, 9, 12]])
np.add.reduceat(arr, [0, 2, 4], axis=1)array([[ 0, 0, 0],[ 1, 5, 4],[ 2, 10, 8],[ 3, 15, 12]], dtype=int32)
下图总结了部分的ufunc方法。

4.2使用python编写新的ufunc方法
有多种方法可以让你编写自己的NumPy ufuncs。最常见的是使用NumPy C API,但它超越了本书的范围。在本节,我们讲纯粹的Python ufunc。
numpy.frompyfunc接受一个Python函数以及两个分别表示输入输出参数数量的参数。例如,下面是一个能够实现元素级加法的简单函数:
def add_elements(x, y):return x + y
add_them = np.frompyfunc(add_elements, 2, 1)
add_them(np.arange(8), np.arange(8))array([0, 2, 4, 6, 8, 10, 12, 14], dtype=object)
用frompyfunc创建的函数总是返回Python对象数组,这一点很不方便。幸运的是,还有另一个办法,即numpy.vectorize。虽然没有frompyfunc那么强大,但可以让你指定输出类型:
add_them = np.vectorize(add_elements, otypes=[np.float64])
add_them(np.arange(8), np.arange(8))array([ 0., 2., 4., 6., 8., 10., 12., 14.])
虽然这两个函数提供了一种创建ufunc型函数的手段,但它们非常慢,因为它们在计算每个元素时都要执行一次Python函数调用,这就会比NumPy自带的基于C的ufunc慢很多:
arr = np.random.randn(10000)
%timeit add_them(arr, arr)1.84 ms ± 17.9 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
%timeit np.add(arr, arr)5.04 µs ± 53.4 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each)
五.结构化和记录数组

你可能已经注意到了,到目前为止我们所讨论的ndarray都是一种同质数据容器,也就是说,在它所表示的内存块中,各元素占用的字节数相同(具体根据dtype而定)。从表面上看,它似乎不能用于表示异质或表格型的数据。结构化数组是一种特殊的ndarray,其中的各个元素可以被看做C语言中的结构体(struct,这就是“结构化”的由来)或SQL表中带有多个命名字段的行:
dtype = [('x', np.float64), ('y', np.int32)]
sarr = np.array([(1.5, 6), (np.pi, -2)], dtype=dtype)
sarrarray([(1.5 , 6), (3.14159265, -2)],dtype=[('x', '<f8'), ('y', '<i4')])
定义结构化dtype(请参考NumPy的在线文档)的方式有很多。最典型的办法是元组列表,各元组的格式为(field_name,field_data_type)。这样,数组的元素就成了元组式的对象,该对象中各个元素可以像字典那样进行访问:
sarr[0](1.5, 6)
sarr[0]['y']6
字段名保存在dtype.names属性中。在访问结构化数组的某个字段时,返回的是该数据的视图,所以不会发生数据复制:
sarr['x']array([1.5 , 3.14159265])
5.1 嵌套dtype和多维字段
在定义结构化dtype时,你可以再设置一个形状(可以是一个整数,也可以是一个元组):
dtype = [('x', np.int64, 3), ('y', np.int32)]
arr = np.zeros(4, dtype=dtype)
arrarray([([0, 0, 0], 0), ([0, 0, 0], 0), ([0, 0, 0], 0), ([0, 0, 0], 0)],dtype=[('x', '<i8', (3,)), ('y', '<i4')])
在这种情况下,各个记录的x字段所表示的是一个长度为3的数组:
arr[0]['x']array([0, 0, 0], dtype=int64)
这样,访问arr[‘x’]即可得到一个二维数组,而不是前面那个例子中的一维数组:
arr['x']array([[0, 0, 0],[0, 0, 0],[0, 0, 0],[0, 0, 0]], dtype=int64)
这就使你能用单个数组的内存块存放复杂的嵌套结构。你还可以嵌套dtype,作出更复杂的结构。下面是一个简单的例子:
dtype = [('x', [('a', 'f8'), ('b', 'f4')]), ('y', np.int32)]
data = np.array([((1, 2), 5), ((3, 4), 6)], dtype=dtype)
dataarray([((1., 2.), 5), ((3., 4.), 6)],dtype=[('x', [('a', '<f8'), ('b', '<f4')]), ('y', '<i4')])
data['x']array([(1., 2.), (3., 4.)], dtype=[('a', '<f8'), ('b', '<f4')])
data['y']array([5, 6])
data['x']['a']array([1., 3.])
pandas的DataFrame并不直接支持该功能,但它的分层索引机制跟这个差不多。
5.2 为什么使用结构化数组
跟pandas的DataFrame相比,NumPy的结构化数组是一种相对较低级的工具。它可以将单个内存块解释为带有任意复杂嵌套列的表格型结构。由于数组中的每个元素在内存中都被表示为固定的字节数,所以结构化数组能够提供非常快速高效的磁盘数据读写(包括内存映像)、网络传输等功能。
结构化数组的另一个常见用法是,将数据文件写成定长记录字节流,这是C和C++代码中常见的数据序列化手段(业界许多历史系统中都能找得到)。只要知道文件的格式(记录的大小、元素的顺序、字节数以及数据类型等),就可以用np.fromfile将数据读入内存。这种用法超出了本书的范围,知道这点就可以了。
六.关于NumPy排序

跟Python内置的列表一样,ndarray的sort实例方法也是就地排序。也就是说,数组内容的重新排列是不会产生新数组的:|
arr = np.random.randn(6)
arr.sort()
arrarray([-1.47108206, -1.13286962, -1.01114869, -0.33176812, -0.08468875,0.87050269])
在对数组进行就地排序时要注意一点,如果目标数组只是一个视图,则原始数组将会被修改:
arr = np.random.randn(3, 5)
arrarray([[-0.34357617, 2.17140268, 0.12337075, -0.01893118, 0.17731791],[ 0.7423957 , 0.85475634, 1.03797268, -0.32899594, -1.11807759],[-0.24152521, -2.0051193 , 0.73788753, -1.06137462, 0.59545348]])
arr[:, 0].sort()
arrarray([[-0.34357617, 2.17140268, 0.12337075, -0.01893118, 0.17731791],[-0.24152521, 0.85475634, 1.03797268, -0.32899594, -1.11807759],[ 0.7423957 , -2.0051193 , 0.73788753, -1.06137462, 0.59545348]])
相反,numpy.sort会为原数组创建一个已排序副本。另外,它所接受的参数(比如kind)跟ndarray.sort一样:
arr = np.random.randn(5)
arrarray([-0.26822958, 1.33885804, -0.18715572, 0.91108374, -0.32150045])
np.sort(arr)array([-0.32150045, -0.26822958, -0.18715572, 0.91108374, 1.33885804])
arrarray([-0.26822958, 1.33885804, -0.18715572, 0.91108374, -0.32150045])
这两个排序方法都可以接受一个axis参数,以便沿指定轴向对各块数据进行单独排序:
arr = np.random.randn(3, 5)
arrarray([[ 1.00543901, -0.51683937, 1.19251887, -0.19893404, 0.39691349],[-1.76381537, 0.60709023, -0.22215536, -0.21707838, -1.21357483],[-0.87044607, -0.2305542 , 1.04376344, -1.14410284, -0.36360302]])
arr.sort(axis=1)
arrarray([[-0.51683937, -0.19893404, 0.39691349, 1.00543901, 1.19251887],[-1.76381537, -1.21357483, -0.22215536, -0.21707838, 0.60709023],[-1.14410284, -0.87044607, -0.36360302, -0.2305542 , 1.04376344]])
你可能注意到了,这两个排序方法都不可以被设置为降序。其实这也无所谓,因为数组切片会产生视图(也就是说,不会产生副本,也不需要任何其他的计算工作)。许多Python用户都很熟悉一个有关列表的小技巧:values[::-1]可以返回一个反序的列表。对ndarray也是如此:
arr[:, ::-1]array([[ 1.19251887, 1.00543901, 0.39691349, -0.19893404, -0.51683937],[ 0.60709023, -0.21707838, -0.22215536, -1.21357483, -1.76381537],[ 1.04376344, -0.2305542 , -0.36360302, -0.87044607, -1.14410284]])
6.1 间接排序:argsort和lexsort
在数据分析工作中,常常需要根据一个或多个键对数据集进行排序。例如,一个有关学生信息的数据表可能需要以姓和名进行排序(先姓后名)。这就是间接排序的一个例子,如果你阅读过有关pandas的章节,那就已经见过不少高级例子了。给定一个或多个键,你就可以得到一个由整数组成的索引数组(我亲切地称之为索引器),其中的索引值说明了数据在新顺序下的位置。argsort和numpy.lexsort就是实现该功能的两个主要方法。下面是一个简单的例子:
values = np.array([5, 0, 1, 3, 2])
indexer = values.argsort()
indexer # 得到排完序之后的索引数组array([1, 2, 4, 3, 0], dtype=int64)
values[indexer]array([0, 1, 2, 3, 5])
一个更复杂的例子,下面这段代码根据数组的第一行对其进行排序:
arr = np.random.randn(3, 5)
arr[0] = values
arrarray([[ 5. , 0. , 1. , 3. , 2. ],[ 0.23159352, 0.72798172, -1.3918432 , 1.99558262, -0.29812485],[ 1.20366758, -0.01576758, 0.74394881, 0.86879898, -0.42864822]])
arr[:, arr[0].argsort()]array([[ 0. , 1. , 2. , 3. , 5. ],[ 0.72798172, -1.3918432 , -0.29812485, 1.99558262, 0.23159352],[-0.01576758, 0.74394881, -0.42864822, 0.86879898, 1.20366758]])
lexsort跟argsort差不多,只不过它可以一次性对多个键数组执行间接排序(字典序)。假设我们想对一些以姓和名标识的数据进行排序:
first_name = np.array(['Bob', 'Jane', 'Steve', 'Bill', 'Barbara'])
last_name = np.array(['Jones', 'Arnold', 'Arnold', 'Jones', 'Walters'])
sorter = np.lexsort((first_name, last_name))
sorterarray([1, 2, 3, 0, 4], dtype=int64)
arr = zip(last_name[sorter], first_name[sorter])
for i,j in arr:print(i, j)Arnold Jane
Arnold Steve
Jones Bill
Jones Bob
Walters Barbara
刚开始使用lexsort的时候可能会比较容易头晕,这是因为键的应用顺序是从最后一个传入的算起的。不难看出,last_name是先于first_name被应用的。
6.2 其他的排序算法
稳定的(stable)排序算法会保持等价元素的相对位置。对于相对位置具有实际意义的那些间接排序而言,这一点非常重要:
values = np.array(['2:first', '2:second', '1:first', '1:second','1:third'])
key = np.array([2, 2, 1, 1, 1])
indexer = key.argsort(kind='mergesort')
indexerarray([2, 3, 4, 0, 1], dtype=int64)
values.take(indexer)array(['1:first', '1:second', '1:third', '2:first', '2:second'],dtype='<U8')
mergesort(合并排序)是唯一的稳定排序,它保证有O(n log n)的性能(空间复杂度),但是其平均性能比默认的quicksort(快速排序)要差。表A-3列出了可用的排序算法及其相关的性能指标。大部分用户完全不需要知道这些东西,但了解一下总是好的。

6.3 数组的部分排序
排序的目的之一可能是确定数组中最大或最小的元素。NumPy有两个优化方法,numpy.partition和np.argpartition,可以在第k个最小元素划分的数组:
np.random.seed(12345)
arr = np.random.randn(20)
arrarray([-0.20470766, 0.47894334, -0.51943872, -0.5557303 , 1.96578057,1.39340583, 0.09290788, 0.28174615, 0.76902257, 1.24643474,1.00718936, -1.29622111, 0.27499163, 0.22891288, 1.35291684,0.88642934, -2.00163731, -0.37184254, 1.66902531, -0.43856974])
np.partition(arr, 3)array([-2.00163731, -1.29622111, -0.5557303 , -0.51943872, -0.37184254,-0.43856974, -0.20470766, 0.28174615, 0.76902257, 0.47894334,1.00718936, 0.09290788, 0.27499163, 0.22891288, 1.35291684,0.88642934, 1.39340583, 1.96578057, 1.66902531, 1.24643474])
当你调用partition(arr, 3),结果中的头三个元素是最小的三个,没有特定的顺序。numpy.argpartition与numpy.argsort相似,会返回索引,重排数据为等价的顺序:
indices = np.argpartition(arr, 3)
indicesarray([16, 11, 3, 2, 17, 19, 0, 7, 8, 1, 10, 6, 12, 13, 14, 15, 5,4, 18, 9], dtype=int64)
arr[indices]array([-2.00163731, -1.29622111, -0.5557303 , -0.51943872, -0.37184254,-0.43856974, -0.20470766, 0.28174615, 0.76902257, 0.47894334,1.00718936, 0.09290788, 0.27499163, 0.22891288, 1.35291684,0.88642934, 1.39340583, 1.96578057, 1.66902531, 1.24643474])
6.4 numpy.searchsorted: 在已排序的数组寻找元素
searchsorted是一个在有序数组上执行二分查找的数组方法,只要将值插入到它返回的那个位置就能维持数组的有序性:
arr = np.array([0, 1, 7, 12, 15])
arr.searchsorted(9)3
你可以传入一组值就能得到一组索引:
arr.searchsorted([0, 8, 11, 16])array([0, 3, 3, 5], dtype=int64)
从上面的结果中可以看出,对于元素0,searchsorted会返回0。这是因为其默认行为是返回相等值组的左侧索引:
arr = np.array([0, 0, 0, 1, 1, 1, 1])
arr.searchsorted([0, 1])array([0, 3], dtype=int64)
arr.searchsorted([0, 1], side='right')array([3, 7], dtype=int64)
再来看searchsorted的另一个用法,假设我们有一个数据数组(其中的值在0到10000之间),还有一个表示“面元边界”的数组,我们希望用它将数据数组拆分开:
data = np.floor(np.random.uniform(0, 10000, size=50))
bins = np.array([0, 100, 1000, 5000, 10000])
dataarray([2449., 7928., 4951., 9150., 9453., 5332., 2524., 7208., 3674.,4986., 2265., 3535., 6508., 3129., 7687., 7818., 8524., 9499.,1073., 9107., 3360., 8263., 8981., 427., 1957., 2945., 6269.,862., 1429., 5158., 6893., 8566., 6473., 5816., 7111., 2524.,9001., 4422., 205., 9596., 6522., 5132., 6823., 4895., 9264.,5158., 721., 5675., 6152., 9415.])
然后,为了得到各数据点所属区间的编号(其中1表示面元[0,100)),我们可以直接使用searchsorted:
labels = bins.searchsorted(data)
labelsarray([3, 4, 3, 4, 4, 4, 3, 4, 3, 3, 3, 3, 4, 3, 4, 4, 4, 4, 3, 4, 3, 4,4, 2, 3, 3, 4, 2, 3, 4, 4, 4, 4, 4, 4, 3, 4, 3, 2, 4, 4, 4, 4, 3,4, 4, 2, 4, 4, 4], dtype=int64)
通过pandas的groupby使用该结果即可非常轻松地对原数据集进行拆分:
import pandas as pd
pd.Series(data).groupby(labels).mean()2 553.750000
3 3132.375000
4 7482.733333
dtype: float64
七.使用Numba编写快速NumPy函数
Numba是一个开源项目,它可以利用CPUs、GPUs或其它硬件为类似NumPy的数据创建快速函数。它使用了LLVM项目将Python代码转换为机器代码。
为了介绍Numba,来考虑一个纯粹的Python函数,它使用for循环计算表达式(x - y).mean():
import numpy as np
def mean_distance(x, y):nx = len(x)result = 0.0count = 0for i in range(nx):result += x[i] - y[i]count += 1return result / count这个函数很慢:
x = np.random.randn(10000000)
y = np.random.randn(10000000)
%timeit mean_distance(x, y)6.64 s ± 81.2 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
%timeit (x - y).mean()47.6 ms ± 1.11 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
NumPy的版本要比它快过100倍。我们可以转换这个函数为编译的Numba函数,使用numba.jit函数:
import numba as nb
numba_mean_distance = nb.jit(mean_distance)也可以写成装饰器:
@nb.jit
def mean_distance(x, y):nx = len(x)result = 0.0count = 0for i in range(nx):result += x[i] - y[i]count += 1return result / count它要比矢量化的NumPy快:
%timeit numba_mean_distance(x, y)17.7 ms ± 2.7 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
Numba不能编译Python代码,但它支持纯Python写的一个部分,可以编写数值算法。
Numba不能编译Python代码,但它支持纯Python写的一个部分,可以编写数值算法。
Numba是一个深厚的库,支持多种硬件、编译模式和用户插件。它还可以编译NumPy Python API的一部分,而不用for循环。Numba也可以识别可以便以为机器编码的结构体,但是若调用CPython API,它就不知道如何编译。Numba的jit函数有一个选项,nopython=True,它限制了可以被转换为Python代码的代码,这些代码可以编译为LLVM,但没有任何Python C API调用。jit(nopython=True)有一个简短的别名numba.njit。
前面的例子,我们还可以这样写:
from numba import float64, njit
@njit(float64(float64[:], float64[:]))
def mean_distance(x, y):return (x - y).mean()7.1用Numba创建自定义numpy.ufunc对象
numba.vectorize创建了一个编译的NumPy ufunc,它与内置的ufunc很像。考虑一个numpy.add的Python例子:
from numba import vectorize@vectorize
def nb_add(x, y):return x + y现在有:
x = np.arange(10)
nb_add(x, x)array([ 0, 2, 4, 6, 8, 10, 12, 14, 16, 18], dtype=int64)
八.高阶数组输入和输出
np.save和np.load可用于读写磁盘上以二进制格式存储的数组。其实还有一些工具可用于更为复杂的场景。尤其是内存映像(memory map),它使你能处理在内存中放不下的数据集。
8.1 内存映射文件
内存映像文件是一种将磁盘上的非常大的二进制数据文件当做内存中的数组进行处理的方式。NumPy实现了一个类似于ndarray的memmap对象,它允许将大文件分成小段进行读写,而不是一次性将整个数组读入内存。另外,memmap也拥有跟普通数组一样的方法,因此,基本上只要是能用于ndarray的算法就也能用于memmap。
要创建一个内存映像,可以使用函数np.memmap并传入一个文件路径、数据类型、形状以及文件模式:
mmap = np.memmap('mymmap.txt', dtype='float64', mode='w+',shape=(10000, 10000))
mmapmemmap([[0., 0., 0., ..., 0., 0., 0.],[0., 0., 0., ..., 0., 0., 0.],[0., 0., 0., ..., 0., 0., 0.],...,[0., 0., 0., ..., 0., 0., 0.],[0., 0., 0., ..., 0., 0., 0.],[0., 0., 0., ..., 0., 0., 0.]])
对memmap切片将会返回磁盘上的数据的视图:
section = mmap[:5]如果将数据赋值给这些视图:数据会先被缓存在内存中(就像是Python的文件对象),调用flush即可将其写入磁盘:
section[:] = np.random.randn(5, 10000)
mmap.flush()
mmapmemmap([[ 0.56711132, -0.12717231, 0.52758445, ..., -0.51964959,-0.55576608, -0.62599963],[-0.60118962, -0.2320138 , 1.78400269, ..., 0.5460359 ,-0.81396878, -0.46026551],[ 0.14608177, -1.1583803 , -1.28189275, ..., 0.53420363,0.09238763, -1.28271782],...,[ 0. , 0. , 0. , ..., 0. ,0. , 0. ],[ 0. , 0. , 0. , ..., 0. ,0. , 0. ],[ 0. , 0. , 0. , ..., 0. ,0. , 0. ]])
del mmap只要某个内存映像超出了作用域,它就会被垃圾回收器回收,之前对其所做的任何修改都会被写入磁盘。当打开一个已经存在的内存映像时,仍然需要指明数据类型和形状,因为磁盘上的那个文件只是一块二进制数据而已,没有任何元数据:
mmap = np.memmap('mymmap.txt', dtype='float64', shape=(10000, 10000))
mmapmemmap([[ 0.56711132, -0.12717231, 0.52758445, ..., -0.51964959,-0.55576608, -0.62599963],[-0.60118962, -0.2320138 , 1.78400269, ..., 0.5460359 ,-0.81396878, -0.46026551],[ 0.14608177, -1.1583803 , -1.28189275, ..., 0.53420363,0.09238763, -1.28271782],...,[ 0. , 0. , 0. , ..., 0. ,0. , 0. ],[ 0. , 0. , 0. , ..., 0. ,0. , 0. ],[ 0. , 0. , 0. , ..., 0. ,0. , 0. ]])
内存映像可以使用前面介绍的结构化或嵌套dtype。
九.性能技巧
使用NumPy的代码的性能一般都很不错,因为数组运算一般都比纯Python循环快得多。下面大致列出了一些需要注意的事项:
1.将Python循环和条件逻辑转换为数组运算和布尔数组运算。
2.尽量使用广播。
3.避免复制数据,尽量使用数组视图(即切片)。
4.利用ufunc及其各种方法。
9.1连续内存的重要性
在某些应用场景中,数组的内存布局可以对计算速度造成极大的影响。这是因为性能差别在一定程度上跟CPU的高速缓存(cache)体系有关。运算过程中访问连续内存块(例如,对以C顺序存储的数组的行求和)一般是最快的,因为内存子系统会将适当的内存块缓存到超高速的L1或L2CPU Cache中。此外,NumPy的C语言基础代码(某些)对连续存储的情况进行了优化处理,这样就能避免一些跨越式的内存访问。
一个数组的内存布局是连续的,就是说元素是以它们在数组中出现的顺序(即Fortran型(列优先)或C型(行优先))存储在内存中的。默认情况下,NumPy数组是以C型连续的方式创建的。列优先的数组(比如C型连续数组的转置)也被称为Fortran型连续。通过ndarray的flags属性即可查看这些信息:
arr_c = np.ones((1000, 1000), order='C')
arr_f = np.ones((1000, 1000), order='F')
arr_c.flags C_CONTIGUOUS : TrueF_CONTIGUOUS : FalseOWNDATA : TrueWRITEABLE : TrueALIGNED : TrueWRITEBACKIFCOPY : FalseUPDATEIFCOPY : False
arr_f.flags C_CONTIGUOUS : FalseF_CONTIGUOUS : TrueOWNDATA : TrueWRITEABLE : TrueALIGNED : TrueWRITEBACKIFCOPY : FalseUPDATEIFCOPY : False
arr_f.flags.f_contiguousTrue
在这个例子中,对两个数组的行进行求和计算,理论上说,arr_c会比arr_f快,因为arr_c的行在内存中是连续的。我们可以在IPython中用%timeit来确认一下:
%timeit arr_f.sum(0)918 µs ± 15.4 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
%timeit arr_c.sum(0)814 µs ± 4.84 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
如果想从NumPy中提升性能,这里就应该是下手的地方。如果数组的内存顺序不符合你的要求,使用copy并传入’C’或’F’即可解决该问题:
arr_f.copy('C').flags C_CONTIGUOUS : TrueF_CONTIGUOUS : FalseOWNDATA : TrueWRITEABLE : TrueALIGNED : TrueWRITEBACKIFCOPY : FalseUPDATEIFCOPY : False
注意,在构造数组的视图时,其结果不一定是连续的:
arr_c[:50].flags.contiguous
True
arr_c[:, :50].flags
C_CONTIGUOUS : FalseF_CONTIGUOUS : FalseOWNDATA : FalseWRITEABLE : TrueALIGNED : TrueWRITEBACKIFCOPY : FalseUPDATEIFCOPY : False