数据分析SQL面试题目9套汇总
- 题目来源:
https://www.jianshu.com/p/0f165dcf9525

关于这套题的笔记
一、

解题思路:
-
1、用concat实现连接 2、还需要按照“用户号”分组,将每组中的前两个“场景”号间接,这时需要用到 GROUP_CONCAT
函数(注意必须和GROUP BY 语句合用),即 GROUP_CONCAT(changjing SEPARATOR’-’) …
GROPY BY userid3、对相同“用户号”、相同“场景”取最小的访问时间
4、整体思路:首先按照“用户号”和“场景”分组,取最小访问时间,然后,以”用户号“为组,按照“用户号”、“场景”和“访问时间”排序,序号为新的一列;将以上查询命名为新表;用concat和GROUP_CONCAT 实现连接,注意要求新的序号列小于2.
注意:排序的过程可以用窗口函数来做,mysql8.0以上版本才支持窗口函数
##利用窗口函数(mysql8以上版本)
SELECT CONCAT(t.userid,'-',GROUP_CONCAT(t.changjing SEPARATOR'-')) AS result
FROM(
SELECT userid,changjing,inttime,row_number() over(PARTITION BY userid ORDER BY userid,changjing,inttime) AS new_rank
FROM(SELECT userid,changjing, MIN(inttime) inttime FROM datafrog_test1 GROUP BY userid,changjing
) tem) t
WHERE t.new_rank<=2
GROUP BY t.userid;
##不利用窗口函数
SELECT CONCAT(t.userid,'-',GROUP_CONCAT(t.changjing SEPARATOR'-')) AS result
FROM(SELECT userid,changjing,inttime,IF(@tmp=userid,@rank:=@rank+1,@rank:=1) AS new_rank,@tmp:=userid AS tmpFROM (SELECT userid,changjing, MIN(inttime) inttime FROM datafrog_test1 GROUP BY userid,changjing)tempORDER BY userid,changjing)t
WHERE t.new_rank<=2
GROUP BY t.userid;
三个排序窗口函数:
- RANK():计算排序(如果存在相同位次的记录,则会跳过之后的位次,比如:1,2,2,4)
- DENSE_RANK():计算排序(即使存在相同位次的记录,也不会跳过之后的位次,比如:1,2,2,3)
- ROW_NUMBER():赋予连续且唯一的位次,比如:1,2,3,4
二、

- mysql 导入中文数据乱码
导入语句:
LOAD DATA INFILE 'D:/camera.csv'
INTO TABLE userinfo
FIELDS TERMINATED BY ','
IGNORE 1 LINES;
这里要把原来的默认路径改为空;
先用
show variables like '%secure%';
找到my文件的路径,然乎按记事本打开my,ini文件,把原路径改为空
 即,secure-file-priv=""
即,secure-file-priv=""
首先:
set names gbk;
然后导入还是会报错,百度一下,说是,需要建立gbk编码的库,和gbk编码的表
重新建库建表的语句:
CREATE DATABASE xiangji CHARACTER SET GBK COLLATE gbk_chinese_ci;
USE xiangji;
CREATE TABLE userinfo(
uid VARCHAR(10),
app_name VARCHAR(20) CHARACTER SET GBK COLLATE gbk_chinese_ci,
duration INT(10),
times INT(10),
dayno VARCHAR(30)
);
现在导入不报错了,但是中文字体是乱码,然后就继续百度:
又一次找到my.ini这个文件,打开它,改两个地方;
 图源:https://jingyan.baidu.com/article /4ae03de3ebb0d83eff9e6b16.html
图源:https://jingyan.baidu.com/article /4ae03de3ebb0d83eff9e6b16.html
改完了重启mysql(计算机管理),汉字就不是乱码了。
以上,over。回归正题,原文解释很清晰,这里就不介绍了。
SELECT day1,COUNT(DISTINCT a.uid) AS 活跃用户数,
COUNT(DISTINCT CASE WHEN day2-day1=1 THEN a.uid END) AS 次日留存用户数,
COUNT(DISTINCT CASE WHEN day2-day1=3 THEN a.uid END) AS 三日留存用户数,
COUNT(DISTINCT CASE WHEN day2-day1=7 THEN a.uid END) AS 七日留存用户数,
CONCAT(ROUND(COUNT(DISTINCT CASE WHEN day2-day1=1 THEN a.uid END)/COUNT(DISTINCT a.uid)*100,2),'%') AS 次日留存率,
CONCAT(ROUND(COUNT(DISTINCT CASE WHEN day2-day1=3 THEN a.uid END)/COUNT(DISTINCT a.uid)*100,2),'%') AS 三日留存率,
CONCAT(ROUND(COUNT(DISTINCT CASE WHEN day2-day1=7 THEN a.uid END)/COUNT(DISTINCT a.uid)*100,2),'%') AS 七日留存率
FROM
(SELECT uid,DATE_FORMAT(dayno,'%Y%m%d') day1 FROM userinfo WHERE app_name='相机')a
LEFT JOIN
(SELECT uid,DATE_FORMAT(dayno,'%Y%m%d') day2 FROM userinfo WHERE app_name='相机')b
ON a.uid=b.uid
GROUP BY day1;
三、行转列(图中左变右)
 方法一:
方法一:
我的第一反应是很像数据透视,之前做过按照数据透视表格式输出的sql语句,用到case
SELECT teacher_id,
(CASE week_day WHEN 1 THEN 'YES' ELSE '' END) mon,
(CASE week_day WHEN 2 THEN 'YES' ELSE '' END) tus,
(CASE week_day WHEN 3 THEN 'YES' ELSE '' END) thi,
(CASE week_day WHEN 4 THEN 'YES' ELSE '' END) thu,
(CASE week_day WHEN 5 THEN 'YES' ELSE '' END) fri
FROM course;
case语句也可以这样写:
SELECT teacher_id,
(CASE WHEN week_day=1 THEN 'YES' ELSE '' END) mon,
(CASE WHEN week_day=2 THEN 'YES' ELSE '' END) tus,
(CASE WHEN week_day=3 THEN 'YES' ELSE '' END) thi,
(CASE WHEN week_day=4 THEN 'YES' ELSE '' END) thu,
(CASE WHEN week_day=5 THEN 'YES' ELSE '' END) fri
FROM course;
**方法二:**用if语句也可以
SELECT teacher_id,
(IF(week_day=1,'YES','')) mon,
(IF(week_day=2,'YES','')) tus,
(IF(week_day=3,'YES','')) thi,
(IF(week_day=4,'YES','')) thu,
(IF(week_day=5,'YES','')) fri
FROM course;
四、
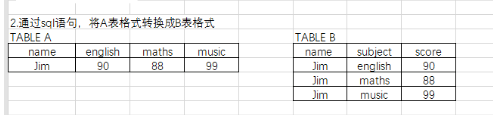
这里想不到更好的方法了:(
SELECT `name`,'english' AS `subject`, english AS score FROM a1
UNION
SELECT `name`,'maths' AS `subject`, maths AS score FROM a1
UNION
SELECT `name`,'music' AS `subject`, music AS score FROM a1;
五、

第一问:
create index id_FDATE on a2(FDATE);
第二问:
我只会用窗口函数(mysql 8.0)做,原文的做法太复杂惹。
SELECT YEAR(FDATE) FYEAR,MONTH(FDATE) FMONTH,SUM(`VALUE`) `VALUE`,SUM(SUM(`value`)) over(PARTITION BY YEAR(FDATE) ORDER BY MONTH(FDATE)) AS YSUM,SUM(SUM(`value`)) over(ORDER BY YEAR(FDATE),MONTH(FDATE)) AS SUM
FROM a2
GROUP BY YEAR(FDATE),MONTH(FDATE);
注意:要按照年和月分组,同一年月的值要加起来。灵活运用,partition by和order by。
六、

第一问:
SELECT NAME,EmailAddress,MAX(lastlogond) lastlogon,COUNT(DISTINCT YE,M,D) num
FROM(SELECT *,YEAR(lastlogon) YE,MONTH(lastlogon) M,DAY(lastlogon) D,DATE_FORMAT(lastlogon,'%Y-%m-%d %H:%i:%s') lastlogondFROM userlog
) a
GROUP BY NAME;
这道题卡了一会,因为没注意到lastlogon是以varchar的格式录入的,选最大日期选错了,需要提前吧varchar 转换成日期格式**‘%Y-%m-%d %H:%i:s’** ,注意转换格式Ymd His
第二问:
DROP TABLE IF EXISTS tmp_table;
CREATE TEMPORARY TABLE tmp_table
SELECT NAME,lastlogon,COUNT(lastlogon) over(PARTITION BY `name` ORDER BY lastlogond) Num_logontime #这里用count和rank都可以,DENSE_RANK() over(PARTITION BY `name` ORDER BY YE,M,D) Num_logondayFROM(SELECT *,YEAR(lastlogon) YE,MONTH(lastlogon) M,DAY(lastlogon) D,DATE_FORMAT(lastlogon,'%Y-%m-%d %H:%i:%s') lastlogondFROM userlog
) a;SELECT * FROM tmp_table;
不得不说,窗口函数真的太好用了。
- 注意创建临时表的语法:
- create temporary table 表名 查询语句;
七、

**第一问:**考察group_concat
SELECT qq,GROUP_CONCAT(game SEPARATOR'_')
FROM tableA
GROUP BY qq;
第二问:
我大概可以理解原文给出的答案的思路,也觉得没什么错,但是放在mysql中的运行结果不对,也不知道为啥。其实基本思想就是借助一个自然数序列与table进行连接,这里我自己创建了一个0,1,2的表,然后进行连接。
CREATE TABLE fz(num INT);
INSERT INTO fz VALUES(0),(1),(2);
SELECT a.qq,SUBSTR(game,2*b.num+1,1) AS game
FROM(
SELECT qq,game,LENGTH(game)-LENGTH(REPLACE(game,'_',''))+1 num
FROM tableB
) a,fz b
WHERE a.num>b.num
ORDER BY qq;
八、
表结构介绍:
用户活跃模型表:tmp_liujg_dau_based
以imp_date,qimei为主键,一个用户1天只出现一次,出现即表示当日登录
字段:
(1)imp_date,日期,string格式,格式例如20190601
(2)qimei,用户唯一标识,string格式,无空值
(3)is_new,新用户表示,string格式,1表示新用户,0表示老用户
红包活动参与领取模型表:tmp_liujg_packet_based
日志流水表,每一行为领取一次红包,无特殊说明,一般不考虑领取红包但当日未登录的情况
字段:
(1)imp_date,日期,string格式,格式例如20190601
(2)report_time,领取时间戳,string
(3)qimei,用户唯一标识,string格式,无空值
(4)add_money,领取金额,string格式,表示领取金额,单位为分,无空值或0值
1、计算2019年6月1日至今,每日DAU(活跃用户量,即有登录的用户量)
输出数据格式:imp_date(日期)
输出数据指标:dau
SELECT imp_date,COUNT(DISTINCT qimei) AS dau
FROM tmp_liujg_dau_based
WHERE imp_date>='20190601'
GROUP BY imp_date;
2、计算2019年6月1日至今,每日领取红包的新用户数、老用户数(近1个月),及其人均领取额、人均领取次数,要考虑领取红包但当日未登录的情况
输出数据维度:imp_date(日期)、is_new(新用户1,老用户0,未知2)
输出数据指标:mean_money(人均领取金额)、mean_get_count(人均领取次数)
以tmp_liujg_packed_based为主表左连接tmp_liujg_dau_based标记号新用户还是老用户。然后from这个子查询,进行计算即可。
SELECT imp_date,is_new,SUM(add_money)/COUNT(DISTINCT qimei) '人均领取金额',COUNT(*)/COUNT(DISTINCT qimei) '人均领取次数'
FROM
(SELECT p.*,
CASE WHEN d.is_new = 1 THEN '新用户' WHEN d.is_new = 0 THEN '老用户' ELSE '领取红包但未登陆'END is_new
FROM tmp_liujg_packed_based p
LEFT JOIN tmp_liujg_dau_based d
ON p.qimei=d.qimei AND p.imp_date = d.imp_date
WHERE p.imp_date>='20190601') ne
GROUP BY imp_date,is_new;
3、计算2019年3月至今,每个月按领取红包天数为1、2、…、30、31天区分,计算出每个月领取红包的用户数、人均领取金额、人均领取次数
输出数据维度:month(月份)、get_money_days(领取天数)
SELECT LEFT(imp_date,6) 月份,
COUNT(DISTINCT imp_date) 每月领取天数,
COUNT(DISTINCT qimei) 每月用户数,
SUM(add_money)/COUNT(DISTINCT qimei) 每月人均领取金额,
COUNT(report_time)/COUNT(DISTINCT qimei) 每月人均领取次数
FROM tmp_liujg_packed_based
WHERE LEFT(imp_date,6)>='201903'
GROUP BY LEFT(imp_date,6);
4、计算2019年3月至今,每个月领过红包用户和未领红包用户的数量,平均月活跃天数(即本月平均活跃多少天)
感觉理解题意都要理解一会,可能我还是不熟练。
SELECT LEFT(imp_date,6) 月份,is_packet_user,COUNT(DISTINCT qimei) 用户数量,
COUNT(is_packet_user)/COUNT(DISTINCT qimei) 月活跃天数
FROM
(SELECT d.imp_date,d.qimei,p.qimei pqimei,
CASE WHEN p.qimei IS NULL THEN '非红包用户' ELSE '红包用户' END is_packet_user
FROM tmp_liujg_dau_based d
LEFT JOIN
(SELECT DISTINCT LEFT(imp_date,6) imp_date,qimei FROM tmp_liujg_packed_based WHERE imp_date>='20190301') p
ON LEFT(d.imp_date,6)=LEFT(p.imp_date,6) AND d.qimei=p.qimei) pd
GROUP BY LEFT(imp_date,6),is_packet_user;
5、计算2019年3月至今,每个月活跃用户的注册日期,2019年3月1日前注册的用户日期填空即可。
原链接给的答案没去重,查询出来的有重复值。另外我觉得题目给出的不是特别清晰。
思路:先找出2019年3月的新用户的第一次登录日期,作为注册日期,然后让tmp_liujg_dau_based与之左连接(注意去重)。
SELECT DISTINCT LEFT(d.imp_date,6) 月份,d.qimei, dd.用户注册日期
FROM tmp_liujg_dau_based d
LEFT JOIN
(
SELECT qimei,MIN(imp_date) 用户注册日期
FROM tmp_liujg_dau_based
WHERE is_new=1 AND imp_date>='2019-03-01'
GROUP BY qimei) dd
ON d.qimei=dd.qimei
WHERE d.imp_date>='20190301';
6、计算2019年3月至今,每日的用户次日留存率,领取红包用户的次日留存,未领取红包用户的次日留存率。
SELECT cc.imp_date 日期,
COUNT(DISTINCT cc.qimei) 当日用户数,
COUNT(DISTINCT cc.hb_qimei)/COUNT(DISTINCT cc.qimei) 当日领取红包用户占比,
COUNT(DISTINCT cc.qimei_lc)/COUNT(DISTINCT cc.qimei) 次日留存率,
COUNT(DISTINCT cc.hb_qimei_lc)/COUNT(DISTINCT cc.qimei_lc) 次日领取红包用户留存率
FROM
(SELECT aa.imp_date,
aa.qimei,#当日登录用户
aa.hb_qimei, #当日领取红包用户
bb.qimei qimei_lc, #次日登录用户
CASE WHEN aa.hb_qimei=bb.qimei AND aa.imp_date=bb.imp_date-1 THEN aa.hb_qimei ELSE NULL END hb_qimei_lc
#次日领取红包并登录的用户
FROM
(SELECT a.imp_date,a.qimei,b.qimei AS hb_qimei
FROM tmp_liujg_dau_based a
LEFT JOIN tmp_liujg_packed_based b
ON a.imp_date=b.imp_date AND a.qimei=b.qimei
WHERE a.imp_date>='2019-03-01') aa
LEFT JOIN
(SELECT a.imp_date,a.qimei,b.qimei AS hb_qimei
FROM tmp_liujg_dau_based a
LEFT JOIN tmp_liujg_packed_based b
ON a.imp_date=b.imp_date AND a.qimei=b.qimei
WHERE a.imp_date>='2019-03-01') bb
ON aa.imp_date=bb.imp_date-1 AND aa.qimei=bb.qimei
) cc
GROUP BY cc.imp_date;
这个答案不符合题意,我改了一下,还是觉得有点奇怪
SELECT cc.imp_date 日期,
COUNT(DISTINCT cc.qimei) 当日用户数,
COUNT(DISTINCT cc.hb_qimei)/COUNT(DISTINCT cc.qimei) 当日领取红包用户占比,
COUNT(DISTINCT cc.qimei_lc)/COUNT(DISTINCT cc.qimei) 次日留存率,
COUNT(DISTINCT cc.hb_qimei_lc)/COUNT(DISTINCT cc.hb_qimei) 当日领取红包用户留存率,
COUNT(DISTINCT cc.whb_qimei_lc)/(COUNT(DISTINCT cc.qimei)-COUNT(DISTINCT cc.hb_qimei)) 当日未领取红包用户留存率
FROM
(SELECT aa.imp_date,
aa.qimei,#当日登录用户
aa.hb_qimei, #当日领取红包用户
bb.qimei qimei_lc, #次日登录用户
CASE WHEN aa.hb_qimei=bb.qimei AND aa.imp_date=bb.imp_date-1 AND aa.hb_qimei IS NOT NULL THEN aa.hb_qimei ELSE NULL END hb_qimei_lc,
#当日领取红包次日登录的用户
CASE WHEN aa.qimei=bb.qimei AND aa.imp_date=bb.imp_date-1 AND aa.hb_qimei IS NULL THEN aa.qimei ELSE NULL END whb_qimei_lc
#当日未领取红包次日登录的用户FROM
(SELECT a.imp_date,a.qimei,b.qimei AS hb_qimei
FROM tmp_liujg_dau_based a
LEFT JOIN tmp_liujg_packed_based b
ON a.imp_date=b.imp_date AND a.qimei=b.qimei
WHERE a.imp_date>='2019-03-01') aa
LEFT JOIN
(SELECT a.imp_date,a.qimei,b.qimei AS hb_qimei
FROM tmp_liujg_dau_based a
LEFT JOIN tmp_liujg_packed_based b
ON a.imp_date=b.imp_date AND a.qimei=b.qimei
WHERE a.imp_date>='2019-03-01') bb
ON aa.imp_date=bb.imp_date-1 AND aa.qimei=bb.qimei
) cc
GROUP BY cc.imp_date;
7、计算2019年6月1日至今,每日新用户领取得第一个红包的金额
思路:先用tmp_liujg_dau_based找到每天的新用户,然后左连接tmp_liujg_packed_based
备注:由于数据较少这里选择的时3月1号之后的数据
SELECT a.imp_date,a.qimei,MIN(DATE_FORMAT(report_time,'%Y%m%d %H%i%s')),add_money
FROM(
SELECT imp_date,qimei FROM tmp_liujg_dau_based WHERE is_new=1 AND imp_date>='20190301'
) a
LEFT JOIN tmp_liujg_packed_based b
ON
a.imp_date=b.imp_date AND a.qimei=b.qimei
GROUP BY imp_date,qimei;
8.计算2019年3月1日至今,每个新用户领取的第一个红包和第二个红包的时间差(只计算注册当日有领取红包的用户,注册当日及以后的DAU表中新用户为1的用户)
SELECT aa.imp_date,aa.qimei,report_time1,report_time2,
TIMESTAMPDIFF(MINUTE,report_time1,report_time2) '间隔时间(分钟)'
FROM(
SELECT a.imp_date,a.qimei,report_time1
FROM(
SELECT imp_date,qimei FROM tmp_liujg_dau_based WHERE is_new=1 AND imp_date>='20190301') a
INNER JOIN
(SELECT imp_date,qimei,MIN(report_time) report_time1 FROM tmp_liujg_packed_based GROUP BY imp_date,qimei) b
ON a.imp_date=b.imp_date AND a.qimei=b.qimei) aa
INNER JOIN (
SELECT a.imp_date,a.qimei,report_time2
FROM(
SELECT imp_date,qimei FROM tmp_liujg_dau_based WHERE is_new=1 AND imp_date>='20190301') a
INNER JOIN
(SELECT imp_date,qimei,MIN(report_time) report_time2
FROM tmp_liujg_packed_based
WHERE CONCAT_WS('_',imp_date,qimei,report_time) NOT IN
(SELECT CONCAT_WS('_',imp_date,qimei,MIN(report_time)) FROM tmp_liujg_packed_based GROUP BY imp_date,qimei)
GROUP BY imp_date,qimei
) b
ON a.imp_date=b.imp_date AND a.qimei=b.qimei) bb
ON aa.imp_date=bb.imp_date AND aa.qimei=bb.qimei;
写完这个还是有成就感的,最后一道题8问也是有点恶心到了,但是学到了concat_ws,timestampdiff的用法,对用户留存率有了更深的理解,完全掌握还需要二刷。







![[Mac OS X] 如何在终端查看 Mac OS 版本信息](https://s0.cyberciti.org/uploads/faq/2015/12/find-out-Mac-OS-X-version-from-Terminal.jpg)