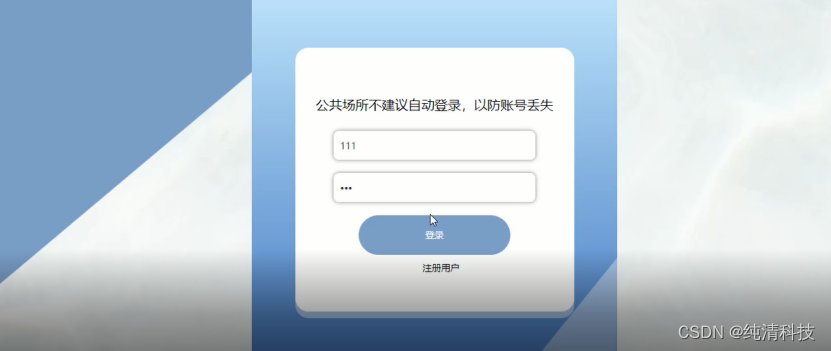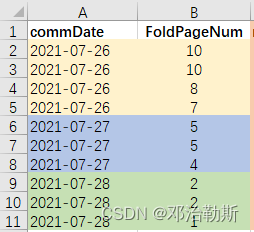
需求场景:对上面的数据进行排名计算,4种情况:
①不考虑commDate,单独对FoldPageNum进行排名,不连续排名;
②不考虑commDate,单独对FoldPageNum进行排名,连续排名;
③按commDate分组,对FoldPageNum进行组内排名,不连续排名;
④按commDate分组,对FoldPageNum进行组内排名,连续排名。
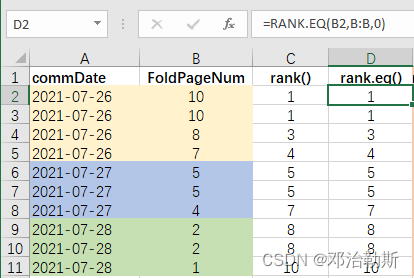
①不考虑commDate,单独对FoldPageNum进行排名,不连续排名:
= RANK(B2, B:B, 0)
或者
= RANK.EQ(B2, B:B, 0)
这两个函数是一样的,输出的结果如下:
②不考虑commDate,单独对FoldPageNum进行排名,连续排名:
第一种方法:
= IF( N(D2) = N(D1), N(E1), N(E1) + 1
)
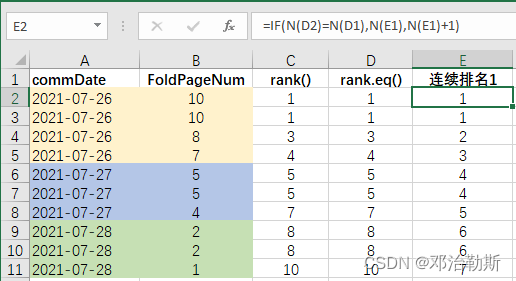
这种方法有2个前提:1. 先算不连续排名;2. 将表格按计算出来的不连续排名进行升序排序。
函数N()用于将单元格里的值转为数值,文本转成数据等于0,再加1就是排名1了。
第二种方法:
= SUMPRODUCT( (B$2:B$11 >= B2) / COUNTIF(B$2:B$11, B$2:B$11) )
即
= SUMPRODUCT( (B$2:B$11 >= B2) * (1 / COUNTIF(B$2:B$11, B$2:B$11) ) )
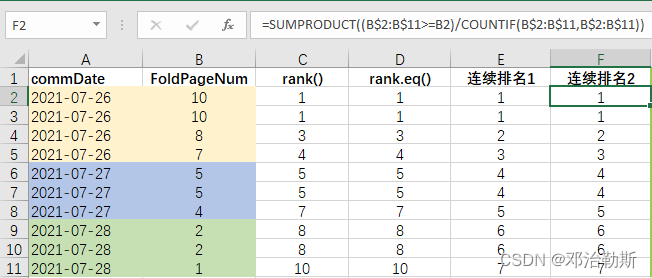
分为2块计算,
(B$2:B$11 >= B2)输出一个由True和False组成的数组;
COUNTIF(B$2:B$11, B$2:B$11)输出每个值在选定的数据区域里面的重复次数,然后被1除,得到1/n;
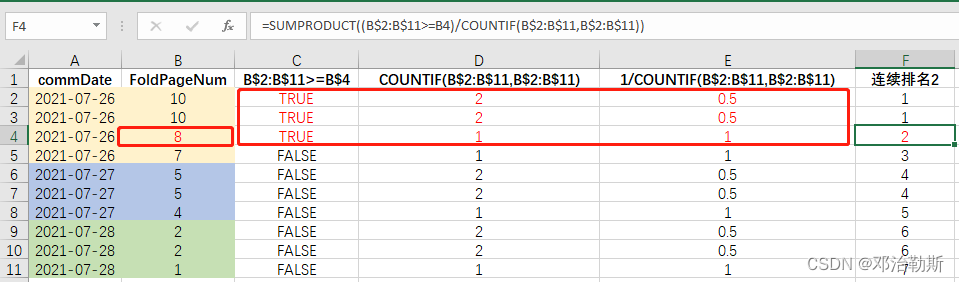
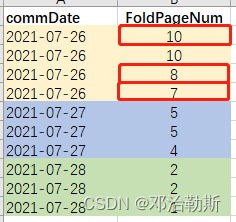
然后与上面的True和False数组求乘积和,便得到排名。比如下图以FoldPageNum = 8为例,计算它的排名,C列计算出True和False数组,>= 8的都为True;然后countif()计算每个值重复的次数,被1除得到1/n;然后用sumproduct对两部分算乘积和,得到FoldPageNum = 8的排名 = True * 0.5 + True * 0.5 + True * 1 = 2
不过这种方法有一个麻烦的地方就是,当新增数据后,整列的公式都要改,因为用美分号锁定了计算区域。
③按commDate分组,对FoldPageNum进行组内排名,不连续排名:
第一种方法:
= COUNTIFS(A:A, A2, B:B, ">" & B2) + 1
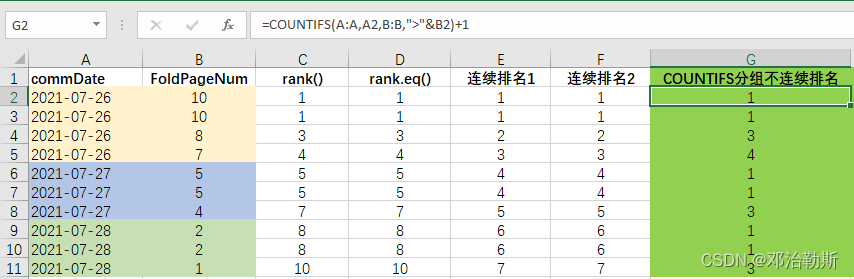
逻辑:用countifs先对A列进行分组识别,然后计算组内大于当前值的个数再加1就是该数值的组内排名。
第二种方法:
= SUMPRODUCT((A:A = A2) * (B:B > B2)) + 1
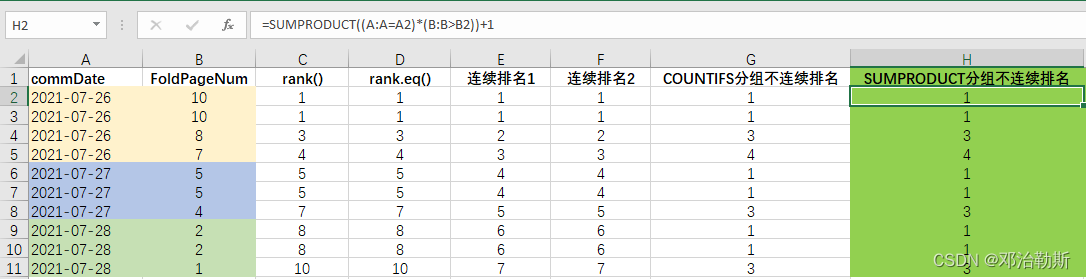
逻辑:先对A列进行逻辑判断,得到True和False组成的数组,再对B列进行大于该值的逻辑判断,同样得到True和False组成的数组,2个数组求乘积和再加1,就是该值的组内排名了。如果看了上面的Sumproduct函数的解析,这里应该就能直接看懂了。
④按commDate分组,对FoldPageNum进行组内排名,连续排名:
第一种方法:
= IF(N(H2) = N(H1),N(I1),IF(N(H2) = 1,1,N(I1) + 1)
)
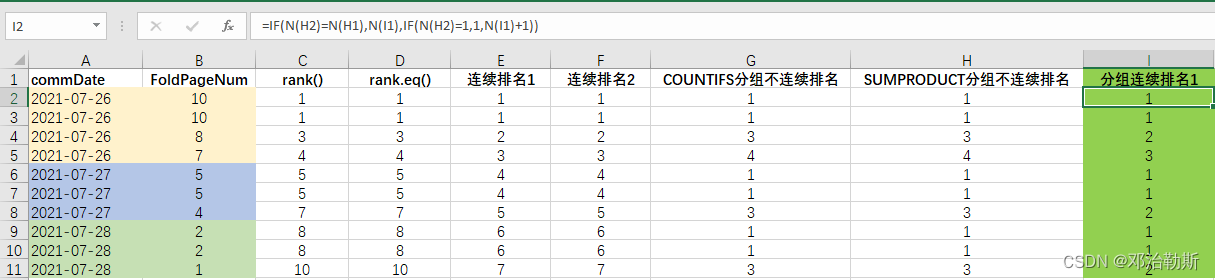
跟上面的不分组连续排名方法一样,这里有2个前提:1. 先算不连续排名;2. 将表格按计算出来的不连续排名进行升序排序。
这里对不连续排名加多了一层判断,如果相邻2个值不相等时,如果下面的值为1,则重新从1开始排。
第二种方法:
= COUNT( 0 / (B2 <= (MATCH(A2&B$2:B$11, A$2:A$11&B$2:B$11, 0) = ROW($1:$10) ) * B$2:B$11) )
写完不是按Enter,而是Ctrl + Shift + Enter
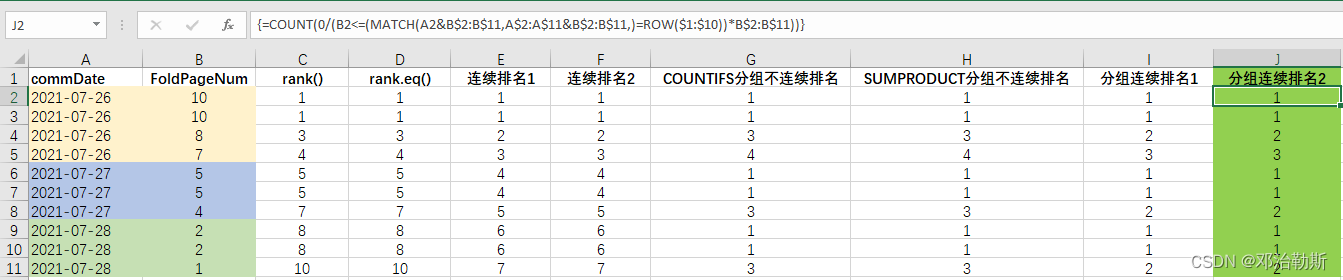
这个公式的逻辑有点意思,思路就是,比如说第4行的“2021-07-26 8”,就是先把维度“2021-07-26”所在的行区域找出来,然后再拿值“8”在这个区域里面算排名。然后最精髓的就是通过行号与固定行号的匹配判断进行去重过滤,拿到不重复的值列表。
具体就是:
- 先用"2021-07-26"和B列拼起来,然后在A列和B列对应拼起来的列表里面用match查找第一个匹配到的位置,得到的结果就是{1,1,3,4,#N/A,#N/A,#N/A,#N/A,#N/A,#N/A}这样一个列表,除了"2021-07-26"所在的行,其他的都变成错误值,以此来锁定这个区域。
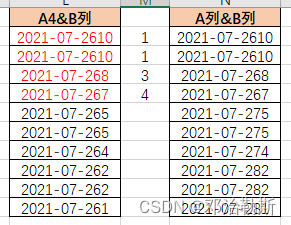
(这里会有一个漏洞,就是2021-07-26和8拼起来是2021-07-268,2021-07-2和68拼起来也是2021-07-268,会造成识别的区域包含了非目标区域。解决方案就是在拼接中间加入一个分隔符,比如:MATCH(A2&“|”&B$2:B$11, A$2:A$11&“|”&B$2:B$11, 0)
- 然后ROW($1:$10)这里是提供数据的行数序列,有新增数据的时候要手动改这里。用第一步得到的列表,跟这个序列做一个匹配判断,如下 ,只有1和3和4匹配出来。通过match的特性和这个连续不重复序列的匹配,达到了去重的效果,比如这里面2个10,就只会取到第1个。由此得到一个{TRUE,FALSE,TRUE,TRUE,#N/A,#N/A,#N/A,#N/A,#N/A,#N/A}的列表。
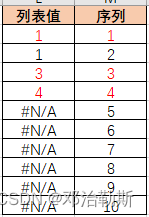
- 然后再跟B列相乘,得到了10,8,7三个值,然后再跟B4的8进行比较,B4<={10,8,7},得到2个TRUE,1个FALSE。0除之后得到2个0,1个错误值。最后用Count统计,就得到2。
不过这种方法也有一个麻烦的地方就是,当新增数据后,整列的公式都要改,因为用美分号锁定了计算区域。