前言
在linux操作系统的使用中,有的时候我们可能想对某个现有的文件做尾部的截取(比如为了保留头部关键信息),但同时又不想重新写一个新的文件出来,这个时候我们其实可以采用系统提供的truncate命令。单词truncate的本意是“截断”,在这里由于操作的对象是文件,所以此命令的作用就是文件的截断。那么同样作为一套成熟的文件系统,HDFS是否也能支持这样的API方法呢?可能它与linux文件系统的一个巨大差别在于它是分布式的,但是这不会影响到HDFS Truncate功能的实现,正如标题所显示的,HDFS同样支持了truncate的操作。
HDFS Truncate功能概述
首先第一点要让大家有一个大概的认识,HDFS Truncate不会是一个很大,很复杂的改动,它实质上是对现有HDFS读写文件操作方法的一个补充和完善。简单地说,就是在HDFS的客户端和服务端增加一个truncate(…)方法。个人认为其中唯一一点比较难的是truncate截断操作如何落实到HDFS的block文件块的操作中,这一点也是大家所要着重去理解的。
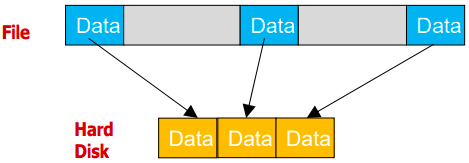
Truncate文件截断在HDFS上的表现其实是block的截断。传入目标文件,与目标保留的长度(此长度应小于文件原大小),如下图所示:
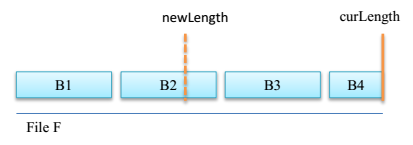
图 1-1 HDFS文件截断原理
上图表示的意思是说,一个文件有拥有4个block块,然后需要截取的长度刚好处在第二block快上,当真正截断操作发生后,B2的后半部,B3和B4就会被移除。
与原生的linux上的truncate命令略有不同的是,HDFS的truncate命令不支持截断超过当前文件大小的情况,如果是这种情况会抛出异常。而在linux中,这种情况下会在超出实际长度的部分返回空字节数据。
HDFS Truncate使用场景
这节我们聚焦的话题是HDFS Truncate到底有哪些适用场景呢?在其设计文档中,列举了如下几项:
- 第一点,允许用户移除意外写入的数据。
- 第二点,当写事务发生失败的时候,可以进行回滚,回到之前写入成功的事务状态。
- 第三点,有能力移除一次失败的写操作而写入的不完整的数据。
- 第四点,提升HDFS对于其它文件系统的支持度。
这里很有意思的一点是,truncate方法与append方法刚好是互逆的方法,在许多意外情况下我们append的出错数据可以通过truncate进行还原。
HDFS Truncate的实现原理
在本小节中,我们来看看HDFS的具体的实现原理,步骤不会太复杂,下面会同时给出具体的操作图帮助大家进行理解。
首先是一个初始的文件块,当前长度与目标截取的长度如下所示:
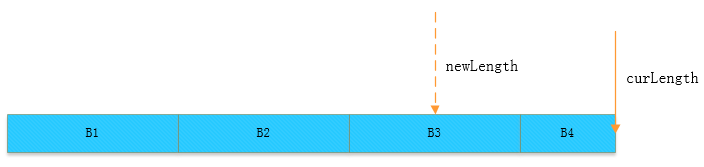
图 1-2 原始文件
要截取到newLength所指示的地方,我们需要做下面2个过程,
第一步,定位到新的截取长度所对应的块,然后把后面多余的块(这里就是B4)从此文件中进行移除,如下图所示:
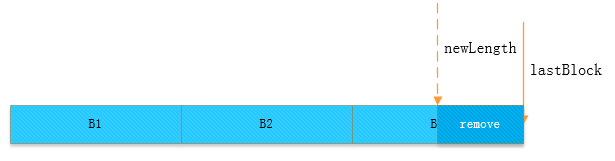
图 1-3 定位截取长度所在的block
第二步,找到新长度所对应的block块之后,计算此块内部需要移除的偏移量,然后进行删除,如下图:

图 1-4 截取最终效果图
上图就是最后的截取效果图,当然了,这里有一种特殊情况如果截取的位置恰好在block的分界处,比如刚好在B3的末尾处,则上面第二步block内部偏移量的截取操作则可以不用执行。
以上是对普通文件截取的操作,我们可以看到,它是直接在原文件上做的修改,我们可以称之为“in-place-truncate”,但是在有些情况下,我们为了保留原始的数据,需要重新拷贝一份出来做截取的动作,我们称这样的情况为“copy-on-truncate”,主要有以下2类情况:
- 当我们操作的文件为快照中的文件,需要保留当时快照维护的数据。
- 当前DataNode正处于升级过程。
上述2类情况是我们需要特殊对待的时候。
HDFS Truncate的实现
前面原理部分的内容大家如果理解了之后,将会非常有助于此小节的学习。本节我们将从源码层面去分析HDFS Truncate的实现。
首先我们从truncate方法的发起入口开始,就是DFSClient端的客户端方法,
// 文件截断方法public boolean truncate(String src, long newLength) throws IOException {checkOpen();// 如果截断长度为负数,则抛出异常if (newLength < 0) {throw new HadoopIllegalArgumentException("Cannot truncate to a negative file size: " + newLength + ".");}try (TraceScope ignored = newPathTraceScope("truncate", src)) {// 调用服务端的对应处理方法return namenode.truncate(src, newLength, clientName);} catch (RemoteException re) {throw re.unwrapRemoteException(AccessControlException.class,UnresolvedPathException.class);}}
这里我们省略中间的方法,直接跳到最终的处理方法,最终进入到了类FSDirTruncateOp中,此类的作用就是专门处理文件截断的,
在进行真正文件截断之前,服务端会做一些判断,如果不符合要求,则程序会直接退出,
// 截断一个文件到给定的大小static TruncateResult truncate(final FSNamesystem fsn, final String srcArg,final long newLength, final String clientName,final String clientMachine, final long mtime,final BlocksMapUpdateInfo toRemoveBlocks, final FSPermissionChecker pc)throws IOException, UnresolvedLinkException {...try {iip = fsd.resolvePathForWrite(pc, srcArg);src = iip.getPath();if (fsd.isPermissionEnabled()) {fsd.checkPathAccess(pc, iip, FsAction.WRITE);}// 获取输入路径对应的INodeFile对象INodeFile file = INodeFile.valueOf(iip.getLastINode(), src);// 不支持EC下的条带式的文件块if (file.isStriped()) {throw new UnsupportedOperationException("Cannot truncate file with striped block " + src);}final BlockStoragePolicy lpPolicy = fsd.getBlockManager().getStoragePolicy("LAZY_PERSIST");// 不支持内存方式存储的文件if (lpPolicy != null && lpPolicy.getId() == file.getStoragePolicyID()) {throw new UnsupportedOperationException("Cannot truncate lazy persist file " + src);}...然后再判断一下当前文件是否已经被截断为目标长度,
...// 判断文件是否已经被截断为相同的目标长度final BlockInfo last = file.getLastBlock();if (last != null && last.getBlockUCState()== BlockUCState.UNDER_RECOVERY) {// 获取最后一个正在被操作的截断块final Block truncatedBlock = last.getUnderConstructionFeature().getTruncateBlock();if (truncatedBlock != null) {// 计算当前操作文件的总长度=不包含最后一个块的字节大小+最后一个截断块的字节大小final long truncateLength = file.computeFileSize(false, false)+ truncatedBlock.getNumBytes();// 如果当前的截断后的长度等于目标截断长度,则说明此文件已经被截断成功,返回截断结果if (newLength == truncateLength) {return new TruncateResult(false, fsd.getAuditFileInfo(iip));}}}...如果当前没有截断操作在进行,则进行文件的长度检查,判断是否满足当前要求,
...// Opening an existing file for truncate. May need lease recovery.fsn.recoverLeaseInternal(RecoverLeaseOp.TRUNCATE_FILE, iip, src,clientName, clientMachine, false);// 再次判断当前文件文件大小与目标大小的关系long oldLength = file.computeFileSize();// 如果大小一致,则无须截断,返回结果if (oldLength == newLength) {return new TruncateResult(true, fsd.getAuditFileInfo(iip));}// 如果目标文件大小大于原始文件大小,则抛异常退出if (oldLength < newLength) {throw new HadoopIllegalArgumentException("Cannot truncate to a larger file size. Current size: " + oldLength+ ", truncate size: " + newLength + ".");}...下面将要开始真正的截断操作了,
...// 下面准备开始真正的文件截断操作了,此过程对应上小节的图1-2到图1-3final QuotaCounts delta = new QuotaCounts.Builder().build();// 判断截断的位置是否刚好在block与block的分割处onBlockBoundary = unprotectedTruncate(fsn, iip, newLength,toRemoveBlocks, mtime, delta);...这里进入unprotectedTruncate方法,
private static boolean unprotectedTruncate(FSNamesystem fsn,INodesInPath iip, long newLength, BlocksMapUpdateInfo collectedBlocks,long mtime, QuotaCounts delta) throws IOException {assert fsn.hasWriteLock();...verifyQuotaForTruncate(fsn, iip, file, newLength, delta);// 获取此文件中需要保留的快照中的块Set<BlockInfo> toRetain = file.getSnapshotBlocksToRetain(latestSnapshot);// 累加block大小直到获取首次超出目标长度为止long remainingLength = file.collectBlocksBeyondMax(newLength,collectedBlocks, toRetain);file.setModificationTime(mtime);// 如果当前block累加的长度恰好等于目标截断长度,说明截断的位置刚好在block边界上return (remainingLength - newLength) == 0;}继续进入INodeFile的collectBlocksBeyondMax方法,看看里面到底是如何执行的,
public long collectBlocksBeyondMax(final long max,final BlocksMapUpdateInfo collectedBlocks, Set<BlockInfo> toRetain) {final BlockInfo[] oldBlocks = getBlocks();if (oldBlocks == null) {return 0;}int n = 0;long size = 0;// max为目标截断长度,进行size的累加直到累加大小第一次超出截断长度for(; n < oldBlocks.length && max > size; n++) {size += oldBlocks[n].getNumBytes();}if (n >= oldBlocks.length) {return size;}// 重新设置当前文件的inode,对原块做一个新的拷贝,原来的块要么后面被删除,要么被保留truncateBlocksTo(n);// 将超出截断位置后的block进行回收和删除if (collectedBlocks != null) {for(; n < oldBlocks.length; n++) {final BlockInfo del = oldBlocks[n];// 如果这些块不是快照中的块,则回收入待移除列表中if (toRetain == null || !toRetain.contains(del)) {collectedBlocks.addDeleteBlock(del);}}}return size;}最后是进行最后块的偏移截取,也就是上一节中图1-3到图1-4的过程,
...// 如果不是在边界上,则对于最后一个块还需要进行偏移量的设置if (!onBlockBoundary) {// 获取最后一块还需要截去的偏移量long lastBlockDelta = file.computeFileSize() - newLength;assert lastBlockDelta > 0 : "delta is 0 only if on block bounday";// 进行最后一个块的截取truncateBlock = prepareFileForTruncate(fsn, iip, clientName,clientMachine, lastBlockDelta, null);}...这里进入prepareFileForTruncate方法,
static Block prepareFileForTruncate(FSNamesystem fsn, INodesInPath iip,String leaseHolder, String clientMachine, long lastBlockDelta,Block newBlock) throws IOException {assert fsn.hasWriteLock();...// 获取当前文件的最后一个块BlockInfo oldBlock = file.getLastBlock();// 此处判断是否要重新拷贝一个block进行截断操作boolean shouldCopyOnTruncate = shouldCopyOnTruncate(fsn, file, oldBlock);if (newBlock == null) {newBlock = (shouldCopyOnTruncate) ? fsn.createNewBlock(false): new Block(oldBlock.getBlockId(), oldBlock.getNumBytes(),fsn.nextGenerationStamp(fsn.getBlockManager().isLegacyBlock(oldBlock)));}...这里copyOnTruncate的条件就是上节提到的2大场景,
private static boolean shouldCopyOnTruncate(FSNamesystem fsn, INodeFile file,BlockInfo blk) {// 是否处于升级相关操作if (!fsn.isUpgradeFinalized()) {return true;}if (fsn.isRollingUpgrade()) {return true;}// 当前block是否为在当前最近一次的快照中return file.isBlockInLatestSnapshot(blk);}上述逻辑判断完毕,则进行对应条件下的截断操作,
...final BlockInfo truncatedBlockUC;BlockManager blockManager = fsn.getFSDirectory().getBlockManager();if (shouldCopyOnTruncate) {// 如果是copy-on-truncate的方式,则将会分配新的块进行截断truncatedBlockUC = new BlockInfoContiguous(newBlock,file.getPreferredBlockReplication());truncatedBlockUC.convertToBlockUnderConstruction(BlockUCState.UNDER_CONSTRUCTION, blockManager.getStorages(oldBlock));// 设置最后一个块的长度,oldBlock.getNumBytes() - lastBlockDelta得到的值对应的就是目标截断的长度truncatedBlockUC.setNumBytes(oldBlock.getNumBytes() - lastBlockDelta);truncatedBlockUC.getUnderConstructionFeature().setTruncateBlock(oldBlock);file.setLastBlock(truncatedBlockUC);blockManager.addBlockCollection(truncatedBlockUC, file);...} else {// 直接在原块上做修改blockManager.convertLastBlockToUnderConstruction(file, lastBlockDelta);oldBlock = file.getLastBlock();assert !oldBlock.isComplete() : "oldBlock should be under construction";BlockUnderConstructionFeature uc = oldBlock.getUnderConstructionFeature();uc.setTruncateBlock(new Block(oldBlock));// 设置最后一个块的长度,oldBlock.getNumBytes() - lastBlockDelta得到的值对应的就是目标截断的长度uc.getTruncateBlock().setNumBytes(oldBlock.getNumBytes() - lastBlockDelta);uc.getTruncateBlock().setGenerationStamp(newBlock.getGenerationStamp());truncatedBlockUC = oldBlock;...}OK,至此truncate操作正式结束。大家可以细致地与上节中所述的原理过程进行对照。
小结
HDFS Truncate截断功能目前发布在Hadoop 2.7.0以及以上的版本中,社区相关JIRA HDFS-3107(HDFS truncate),想更加详细了解此特性的同学可以阅读此JIRA.
参考资料
[1].https://issues.apache.org/jira/browse/HDFS-3107
[2].https://issues.apache.org/jira/secure/attachment/12697141/HDFS_truncate.pdf





![ins40401 oracle,安装orace grid infrastructure 提示[INS-40404]问题](http://www.2cto.com/uploadfile/Collfiles/20131204/20131203153602859.jpg)