查询删除MySQL重复数据
- 新建表
users
CREATE TABLE `users` (`user_id` int(11) NOT NULL AUTO_INCREMENT,`user_name` varchar(20) NOT NULL,`user_vip` int(11) DEFAULT '0',`user_vips` int(11) DEFAULT '0',`user_password` varchar(20) DEFAULT NULL,PRIMARY KEY (`user_id`)
) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8
- 插入数据
INSERT INTO users(user_name,user_vip,user_vips,user_password) VALUES('www',1,1,'111');
INSERT INTO users(user_name,user_vip,user_vips,user_password) VALUES('wxs',1,1,'222');
INSERT INTO users(user_name,user_vip,user_vips,user_password) VALUES('wxs',1,1,'111');
INSERT INTO users(user_name,user_vip,user_vips,user_password) VALUES('wxs',1,1,'111');
- 查询
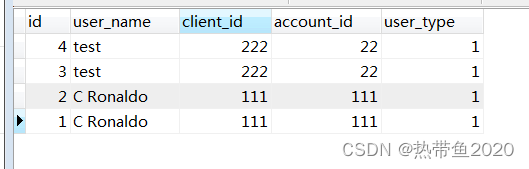
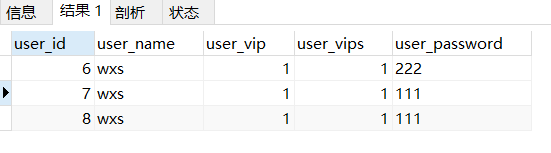
user_name重复的数据
SELECT * FROM users WHERE user_name IN (SELECT user_name FROM users GROUP BY user_name HAVING COUNT(user_name) > 1);
-
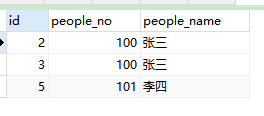
删除重复的数据,只保留一条
- 首先查询出,除了
user_id最小的一行之外的所有重复数据(上图除了user_id为 6 的其余行)
SELECT * FROM users WHERE user_name IN (SELECT user_name FROM users GROUP BY user_name HAVING COUNT(user_name) > 1) AND user_id NOT IN (SELECT MIN(user_id) from users GROUP BY user_name HAVING COUNT(user_name) > 1);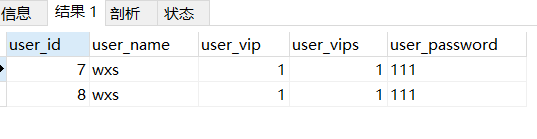
- 然后删除这些重复行 (如果你直接替换
SELECT *为 DELETE 你会看到如下报错)

大意为:不能在同一个sql语句中,先select同一个表的某些值,然后再update(更新)这个表
-
修改上面的sql 语句为:
DELETE FROM users WHERE user_name IN ( SELECT un FROM (SELECT user_name AS un FROM users GROUP BY user_name HAVING COUNT(user_name) > 1) as a) AND user_id NOT IN ( SELECT ui from (SELECT MIN(user_id) AS ui FROM users GROUP BY user_name HAVING COUNT(user_name) > 1) AS b);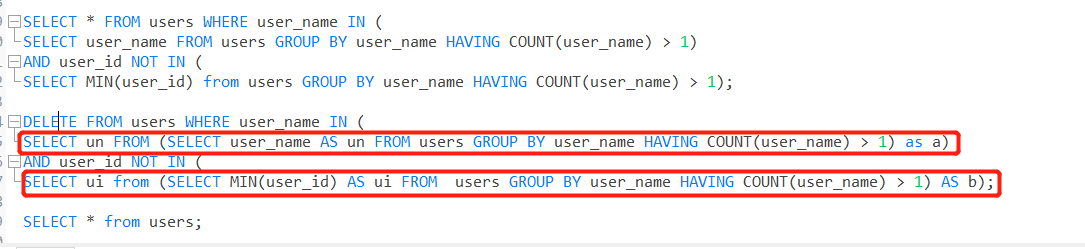
给作为条件查询的表起一个别名就可以解决了
- 首先查询出,除了