文章目录
- @[toc]
- XML概述
- 代码示例
- CSS格式化XML
- 为什么要用CSS样式表:
- 代码示例:
- 代码详解:
- XSLT转化XML
- XSLT简介:
- 代码示例
- 代码详解:
- 正确的样式表声明
- 从XML里提取数据
- 节点匹配
- DOM解析XML
- XML DOM简介
- 节点
- 代码示例
- 代码详解
- 节点
- XML DOM 节点树
- 加载函数
- 遍历XML文档数据
文章目录
- @[toc]
- XML概述
- 代码示例
- CSS格式化XML
- 为什么要用CSS样式表:
- 代码示例:
- 代码详解:
- XSLT转化XML
- XSLT简介:
- 代码示例
- 代码详解:
- 正确的样式表声明
- 从XML里提取数据
- 节点匹配
- DOM解析XML
- XML DOM简介
- 节点
- 代码示例
- 代码详解
- 节点
- XML DOM 节点树
- 加载函数
- 遍历XML文档数据
XML概述
- XML 被设计用来传输和存储数据。
- XML 仅仅是纯文本
- XML 允许创作者定义自己的标签和自己的文档结构。
- XML 不是对 HTML 的替代,而是对 HTML 的补充。
- XML 是独立于软件和硬件的信息传输工具。
- XML 是 W3C 的推荐标准
代码示例
<?xml version="1.0" encoding="utf-8"?>
<students><student><sn>201709000123</sn><name>张嘉佳</name><sex>女</sex> <nation>汉族</nation><address>湖北武汉</address><profession>英语</profession></student><student><sn>201709000124</sn><name>李文斌</name><sex>男</sex> <nation>傣族</nation><address>云南昆明</address><profession>建筑</profession></student><student><sn>201709000548</sn><name>王香凝</name><sex>女</sex> <nation>苗族</nation><address>四川成都</address><profession>音乐</profession></student><student><sn>201709000789</sn><name>张文煊</name><sex>女</sex> <nation>汉族</nation><address>广东广州</address><profession>语言</profession></student></students>
这个简单的XML文档类似于C语言中的结构体对象
CSS格式化XML
为什么要用CSS样式表:
在浏览器中打开XML文档时,如果没有为XML指定样式表,浏览器将会使用默认样式显示XML,
而且,XML没有预定义的<style>标记,也没有预定义的<style>和class属性
所以当我们需要自定义一种XML输出样式时,就需要自定义一个外部CSS样式表;
代码示例:
XML部分:Css-xml.xml
<?xml version="1.0" encoding="utf-8"?>
<?xml-stylesheet type="text/css" href="cssformat.css"?>
<students><h2>XSLT转化XML</h2><student><sn>201709000123</sn><name>张嘉佳</name><sex>女</sex> <nation>汉族</nation><address>湖北武汉</address><profession>英语</profession></student><student><sn>201709000124</sn><name>李文斌</name><sex>男</sex> <nation>傣族</nation><address>云南昆明</address><profession>建筑</profession></student><student><sn>201709000548</sn><name>王香凝</name><sex>女</sex> <nation>苗族</nation><address>四川成都</address><profession>音乐</profession></student><student><sn>201709000789</sn><name>张文煊</name><sex>女</sex> <nation>汉族</nation><address>广东广州</address><profession>语言</profession></student>
</students>CSS部分: cssformat.css
students{border-collapse: collapse;display: table; margin: auto;margin-top: 24px;
}
student{display:table-row;line-height: 24px;}
sn, name, sex, nation, address, profession{display:table-cell;border:1px solid;padding: 6px;
}
txt{font-style: normal;font-weight: bolder;font-size: x-large;line-height: 24px;text-align: left;margin-top: 20px;
}
运行结果:

代码详解:
-
在上面的 XML 中,根节点是 。文档中的所有其他节点都被包含在 中。
根节点 有四个 节点。
第一个 节点六个节点:
<sn>, <name>, <sex>,<natiion>,<address>以及 <profession>,其中每个节点都包含一个文本节点,“201709000123”, “张嘉佳”, “女” 以及 "汉族"等。
XMl文档中引用外部样式表的格式是:
<?xml-stylesheet type="text/css" href="cssformat.css"?>
注意:
- type=“text/css” 注意在引用外部CSS时,text/后应为css(它也可能为JavaScript、xsl等)
- href=“cssformat.css” 注意文件名
CSS文件中的书写格式与HTML中的<style>一样
更多CSS属性详解CSS 参考手册
XSLT转化XML
XSLT简介:
- XSLT 指 XSL 转换(XSL Transformations)。
- XSLT 是 XSL 中最重要的部分。
- XSLT 可将一种 XML文档转换为另外一种 XML 文档。
- XSLT 使用 XPath 在 XML 文档中进行导航。
- 所有主流的浏览器都支持 XML 和 XSLT。
- XPath 是一个 W3C 标准。
代码示例
`XML部分:xslt-xml.xml
<?xml version="1.0" encoding="utf-8"?>
<?xml-stylesheet type="text/xsl" href="xsltformat.xsl"?><students><student><sn>201709000123</sn><name>张嘉佳</name><sex>女</sex> <nation>汉族</nation><address>湖北武汉</address><profession>英语</profession></student><student><sn>201709000124</sn><name>李文斌</name><sex>男</sex> <nation>傣族</nation><address>云南昆明</address><profession>建筑</profession></student><student><sn>201709000548</sn><name>王香凝</name><sex>女</sex> <nation>苗族</nation><address>四川成都</address><profession>音乐</profession></student><student><sn>201709000789</sn><name>张文煊</name><sex>女</sex> <nation>汉族</nation><address>广东广州</address><profession>语言</profession></student>
</students>XSLT部分: xsltformat.xsl
<?xml version="1.0" encoding="utf-8"?>
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform" version="1.0">
<xsl:output method="html" version="1.0" encoding="UTF-8" indent="yes"/>
<xsl:template match="/"><html><head><meta charset="utf-8"/><title>XTSL转化XML</title></head><body><h2 align="center">XSLT转化XML</h2><table border="1" cellpadding="6" align="center"><caption>studentlist</caption><tr><th>学号</th><th>姓名</th><th>性别</th><th>民族</th><th>籍贯</th><th>专业</th></tr><xsl:for-each select="students/student"><tr><td align="center"><xsl:value-of select="sn"/></td><td align="center"><xsl:value-of select="name"/></td><td align="center"><xsl:value-of select="sex"/></td><td align="center"><xsl:value-of select="nation"/></td><td align="center"><xsl:value-of select="address"/></td><td align="center"><xsl:value-of select="profession"/></td></tr></xsl:for-each></table></body></html></xsl:template>
</xsl:stylesheet>
运行结果:

代码详解:
-
在上面的 XML 中,根节点是 。文档中的所有其他节点都被包含在 中。
根节点 有四个 节点。
第一个 节点六个节点:
<sn>, <name>, <sex>,<natiion>,<address>以及 <profession>,其中每个节点都包含一个文本节点,“201709000123”, “张嘉佳”, “女” 以及 "汉族"等。
XMl文档中引用外部样式表的格式是:
<?xml-stylesheet type="text/xsl" href="xsltformat.xsl"?>
注意:
- type=“text/xsl” ,text/后应为xsl
- href=“xsltformat.xsl” 注意文件名
正确的样式表声明
把文档声明为 XSL 样式表的根元素是 <xsl:stylesheet> 或 <xsl:transform>。
注释: <xsl:stylesheet> 和 <xsl:transform> 是完全同义的,均可被使用!
根据 W3C 的 XSLT 标准,声明 XSL 样式表的正确方法是:
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
或者:
<xsl:transform version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
如需访问 XSLT 的元素、属性以及特性,我们必须在文档顶端声明 XSLT 命名空间
从XML里提取数据
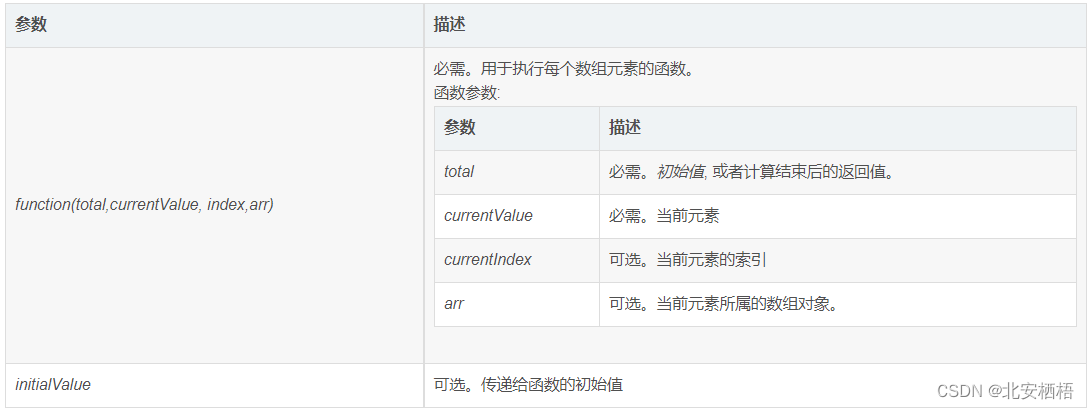
在XSLT中通常需要将XML中的内容复制到文档中,XSLT提供了value-of元素可实现该功能,格式:
<xsl:value-of select="name"/>
select后面为指定的XML中的节点 **“.”**表示选取钙元素下的所有元素(当前节点无嵌套元素除外)
XSLT xsl:template 元素
XSLT xsl:value-of 元素
XSLT xsl:for-each 元素
节点匹配
- 匹配根节点
<xsl:template match="/"> - 匹配元素名
<xsl:value-of select="name1"/><xsl:for-each select="name1/name2"/> - 匹配后代节点
<xsl:value-of select="//name1"/> - 通过ID匹配节点
<xsl:value-of select="ID(09000532)"/> - 通过I匹配属性@
<xsl:value-of select="name1/@atter"/> - 通过多个节点
<xsl:value-of select="name1|name2"/>(用“|”分隔) - 扩展匹配[]
<xsl:value-of select="name1[@atter='value]"/>
DOM解析XML
XML DOM简介
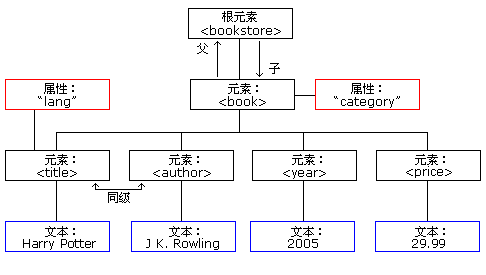
- XML DOM这种结构层次是根据XML文档生成的一颗节点树。
- XML 文档中的每个成分都是一个节点。
- XML DOM 是用于获取、更改、添加或删除 XML 元素的标准。
节点
根据 DOM,XML 文档中的每个成分都是一个节点。
DOM 是这样规定的:
- 整个文档是一个文档节点
- 每个 XML 标签是一个元素节点
- 包含在 XML 元素中的文本是文本节点
- 每一个 XML 属性是一个属性节点
- 注释属于注释节点
代码示例
XML部分:Dom-xml.xml
<?xml version="1.0" encoding="utf-8"?>
<students><student><sn>201709000123</sn><name>张嘉佳</name><sex>女</sex> <nation>汉族</nation><address>湖北武汉</address><profession>英语</profession></student><student><sn>201709000124</sn><name>李文斌</name><sex>男</sex> <nation>傣族</nation><address>云南昆明</address><profession>建筑</profession></student><student><sn>201709000548</sn><name>王香凝</name><sex>女</sex> <nation>苗族</nation><address>四川成都</address><profession>音乐</profession></student><student><sn>201709000789</sn><name>张文煊</name><sex>女</sex> <nation>汉族</nation><address>广东广州</address><profession>语言</profession></student></students>
Dom部分:Domformat.html(Dom为HTML文件)
<!doctype html>
<html>
<head>
<meta charset="utf-8">
<title>XML DOM应用</title>
</head>
<body>
<table border="1" align="center"><caption>使用DOM显示XML文挡</caption><tr><td>学号</td><td>姓名</td><td>性别</td><td>民族</td><td>籍贯</td><td>专业</td></tr><script type="text/javascript">var isie=true;var xmlDoc;try {xmlDoc=new ActiveXObject("Microsoft.XMLDOM");}catch(e) {isie=false;xmlDoc=document.implementation.createDocument("","",null);//}xmlDoc.async=false;xmlDoc.load("Dom-xml.xml");var stuList=xmlDoc.getElementsByTagName("student");for(var i=0; i<stuList.length; i++) {document.write("<tr>");var subList=stuList[i].childNodes;for(var j=0; j<subList.length; j++) {if(isie) {document.write("<td>" + subList[j].text + "</td>");}else {if(subList[j].nodeType==1) {document.write("<td>" + subList[j].textContent + "</td>");//}}}document.write("</tr>");}
</script>
</table>
</body>
</html>运行结果

注意:上述Dom案例代码只能在IE9+打开,否则只会出现表头(Dom无法解析XML文档中的内容)
如果出现这种情况,直接点击允许即可

代码详解
节点
-
在上面的 XML 中,根节点是 。文档中的所有其他节点都被包含在 中。
根节点 有四个 节点。
第一个 节点六个节点:
<sn>, <name>, <sex>,<natiion>,<address>以及 <profession>,其中每个节点都包含一个文本节点,“201709000123”, “张嘉佳”, “女” 以及 "汉族"等。
XML DOM 节点树
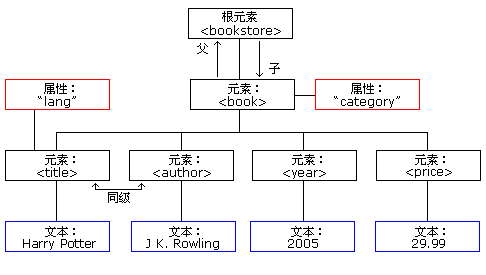
XML DOM 把 XML 文档视为一种树结构。这种树结构被称为节点树。
可通过这棵树访问所有节点。可以修改或删除它们的内容,也可以创建新的元素。
这颗节点树展示了节点的集合,以及它们之间的联系。这棵树从根节点开始,然后在树的最低层级向文本节点长出枝条:
(借用W3School的图)
加载函数
XML DOM 含有遍历 XML 树以及访问、插入、删除节点的方法(函数)。
然后,在访问并处理 XML 文档之前,必须把它载入 XML DOM 对象。
xmlDoc.load("Dom-xml.xml");:加载XML
下面代码为了兼容浏览器
try {xmlDoc=new ActiveXObject("Microsoft.XMLDOM");}catch(e) {isie=false;xmlDoc=document.implementation.createDocument("","",null);//}加载函数整体:
try {xmlDoc=new ActiveXObject("Microsoft.XMLDOM");}catch(e) {isie=false;xmlDoc=document.implementation.createDocument("","",null);//}xmlDoc.async=false;xmlDoc.load("Dom-xml.xml");
遍历XML文档数据
var stuList=xmlDoc.getElementsByTagName("student");for(var i=0; i<stuList.length; i++) {document.write("<tr>");var subList=stuList[i].childNodes;for(var j=0; j<subList.length; j++) {if(isie) {document.write("<td>" + subList[j].text + "</td>");}else {if(subList[j].nodeType==1) {document.write("<td>" + subList[j].textContent + "</td>");//}}}document.write("</tr>");}
XML DOM Document 对象