在ctf里reverse经常会有base64相关的题型,每次写到这类题型只能凭经验猜测考点来解题,特此出一个base64相关的博客,加深对base64的理解,下次再看到伪代码也不会觉得慌了,毕竟纵使实现形式不同,代码的核心逻辑还是大差不差的。
base64编码原理及代码实现
- 1. 简介
- 2. 原理
- 2.1 base64编码表
- 2.2 当待编码数据正好为3的倍数时
- 2.2.1 对abc进行base64编码
- 2.3 当待编码数据不为3的倍数时
- 2.3.1 对a进行base64编码
- 2.3.2 对ab进行base64编码
- 2.4 小结
- 3. 代码实现
- 3.1 其一
- 3.2 其二
1. 简介
base64编码是一种以64个可打印字符来表示和传输数据的编码,通常base64编码的数据是没有含义的,base64编码后的数据要通过base64解码才有意义。
2. 原理
base64编码是由64(2^6)个可打印字符来表示的,占用6位,这6位数据正好从0到63对应64个字符,而1 byte = 8 bit,如何用6bit来表示1byte(8bit) 的数据呢,如果每3byte为一组,对应每4个base64编码数据,3 * 8 bit = 4 * 6 bit,这样就解决了这个问题。
2.1 base64编码表
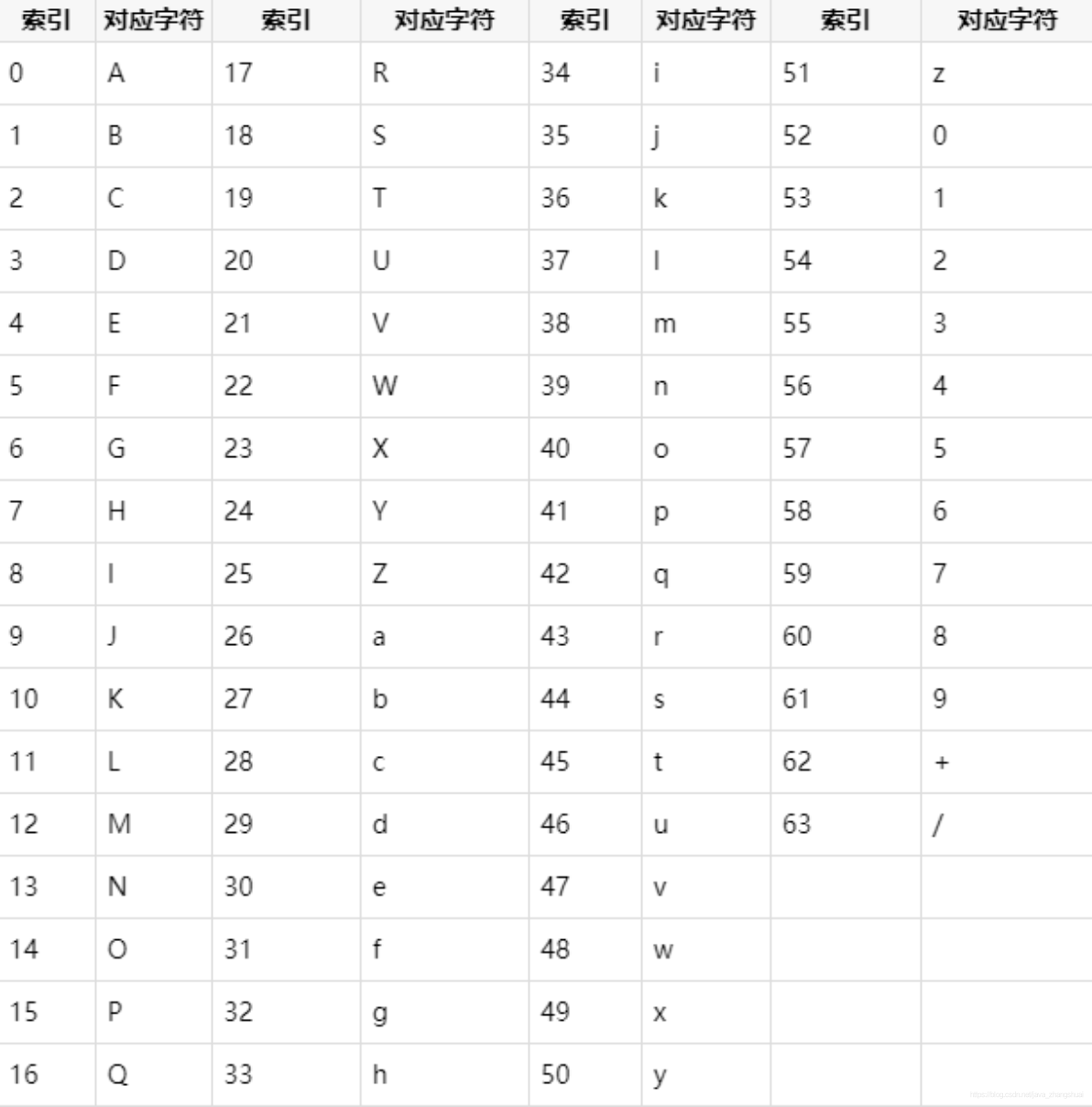
索引和字符的对应关系被叫做base64编码表,如下图所示
| base64编码表 | |
|---|---|
| 索引 | 字符 |
| 0 | A |
| 1 | B |
| 2 | C |
| 3 | D |
| 4 | E |
| 5 | F |
| 6 | G |
| 7 | H |
| 8 | I |
| 9 | J |
| 10 | K |
| 11 | L |
| 12 | M |
| 13 | N |
| 14 | O |
| 15 | P |
| 16 | Q |
| 17 | R |
| 18 | S |
| 19 | T |
| 20 | U |
| 21 | V |
| 22 | W |
| 23 | X |
| 24 | Y |
| 25 | Z |
| 26 | a |
| 27 | b |
| 28 | c |
| 29 | d |
| 30 | e |
| 31 | f |
| 32 | g |
| 33 | h |
| 34 | i |
| 35 | j |
| 36 | k |
| 37 | l |
| 38 | m |
| 39 | n |
| 40 | o |
| 41 | p |
| 42 | q |
| 43 | r |
| 44 | s |
| 45 | t |
| 46 | u |
| 47 | v |
| 48 | w |
| 49 | x |
| 50 | y |
| 51 | z |
| 52 | 0 |
| 53 | 1 |
| 54 | 2 |
| 55 | 3 |
| 56 | 4 |
| 57 | 5 |
| 58 | 6 |
| 59 | 7 |
| 60 | 8 |
| 61 | 9 |
| 62 | + |
| 63 | / |
2.2 当待编码数据正好为3的倍数时
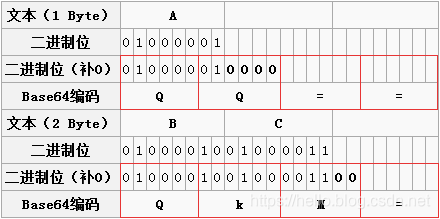
2.2.1 对abc进行base64编码
以abc这个数据为例,对其进行base64编码,如下图所示,abc——>YWNE
可以看到3字节的倍数的数据是可以完美适配base64编码的,但如果我想将非3字节倍数的数据进行base64编码呢?
2.3 当待编码数据不为3的倍数时
2.3.1 对a进行base64编码
a占一个字节(8 bit),而base64编码最少需要3 * 8 bit= 24 bit,因此需要在a后面再补2个空字符,这一组字符中,前6 bit的大小仍为24,对应的字符为Y,还剩下2 bit,则需要补0 直至补满6 bit,补满之后的数据大小为16,对应字符为Q,接下来的 2*6 bit = 12 bit 则填 2个 =,得到base64编码后的数据YQ
==,这样就解决了对一个字节进行base64编码的问题

2.3.2 对ab进行base64编码
ab共占二个字节(2 *8 bit = 16 bit),由上可知需要再补 1 byte达到 3 byte,对应的4个base64字符,其中,前两个分别为Y和Q,对于第三个,其前4bit是有数据的,而后2bit则需要补0,大小为8,对应字符为I,最后6 bit则用一个=来补齐。这样得到base64编码后的数据YWI=

2.4 小结
根据上面的个例,我们可以往数据量更大的情况考虑,假设一个数据有n byte(n > 3),如果 n % 3 = 0 ,则其base64编码后不存在=,因为它正好是 24 byte的倍数;如果n % 3 = 1,由于n = 3 * m + 1,3 * m 正好是24 byte的倍数,这部分不存在=,剩下最后 1 byte ,则按照上面2.3.1的步骤对其进行操作,后补 = =;如果n % 3 = 2,由于n = 3 * m + 2,3 * m 正好是24 byte的倍数,这部分不存在=,剩下最后 2 byte ,则按照上面2.3.2的步骤对其进行操作,后补 = 。
3. 代码实现
对于base64编码的代码,我这里学了两个版本,其中一个是在写ctf的reverse题时看到的,由于赛题是伪代码且逻辑不完整,所以我对其进行了完善,还有一个是我在学base64编码的时候看到的,其中第一个的代码量较小且更加利于理解,如果第一个的代码无法接受的也可以看看第二个,因人而异。
贴一下那道ctf的wp:
[WUSTCTF2020]level3
3.1 其一
#include<string.h>
#include<stdio.h>
#include<stdlib.h>
int main()
{char base64_table[] = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/";//data是代编码数据char data[] = "abcdefsdadasdsad2131324rfa2615";//data_len表示代编码数据能分成几组(3 * 8bit = 4 * 6 bit = 24bit)int data_len= strlen(data) / 3;//data_add表示分组后剩下几个int data_add = strlen(data) % 3;//开辟空间给src数组char *src = (char*)malloc(data_len * 4 + 4 + 1);//+4是为了给可能多的1或2个数据及后边要添的=留位置,+1是为了给'\0'留位置来表示字符串结尾int temp = 0;int tmp = 0;int n =0;//以4 * 6bit为单位将编码后的值传入srcwhile (temp < data_len){src[n++] = base64_table[data[tmp] >> 2];src[n++] = base64_table[16 * (data[tmp] & 0x3) | data[tmp + 1] >> 4];src[n++] = base64_table[4 * (data[tmp + 1] & 0xF) | data[tmp+ 2] >> 6];src[n++] = base64_table[data[tmp + 2] & 0x3F];tmp += 3;temp++;}//多出一个数据需要补2个=if(data_add == 1){src[n++] = base64_table[data[tmp] >> 2];src[n++] = base64_table[16 * (data[tmp] & 0x3)];src[n++] = '=';src[n++] = '=';src[n] = '\0';}//多出两个数据需要补1个=else if(data_add == 2){src[n++] = base64_table[data[tmp] >> 2];src[n++] = base64_table[(16 * (data[tmp] & 0x3)) | data[tmp + 1] >> 4];src[n++] = base64_table[4 * (data[tmp+1] & 0xF)];src[n++] = '=';src[n] = '\0';}else{src[n] = '\0';}printf("%s\n", src);
}
3.2 其二
#include<stdio.h>
#include<string.h>
#include<stdlib.h>const char base[] = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/=";
static char find_pos(char ch);
char *base64_encode(const char* data, int data_len, int *len);
char *base_64decode(const char* data, int data_len, int *len);/***找到ch在base中的位置*/
static char find_pos(char ch)
{//the last position (the only) in base[]char *ptr = (char*)strrchr(base, ch);return (ptr - base);
}/***BASE64编码*/
char *base64_encode(const char* data, int data_len, int *len)
{int prepare = 0;int ret_len;*len = 0;int temp = 0;char *ret = NULL;char *f = NULL;int tmp = 0;char changed[4];int i =0;ret_len = data_len / 3;temp = data_len % 3;if(temp > 0){ret_len += 1;}//最后一位以'\0'结束ret_len = ret_len*4 + 1;ret = (char *)malloc(ret_len);if (ret == NULL){printf("No enough memory\n");exit(0);}memset(ret, 0, ret_len);f = ret;//tmp记录data中移动位置while (tmp < data_len){temp = 0;prepare = 0;memset(changed, 0, 4);while (temp < 3){if (tmp >= data_len){break;}//将data前8*3位移入prepare的低24位prepare = ((prepare << 8) | (data[tmp] & 0xFF));tmp ++;temp ++;}//将有效数据移到以prepare的第24位起始位置prepare = (prepare << ((3-temp) * 8));for (i = 0; i < 4; i++){//最后一位或两位if (temp < i){changed[i] = 0x40;}else{//24位数据changed[i] = (prepare >> ((3-i) * 6)) & 0x3F;}*f = base[changed[i]];f++;(*len)++;}}*f = '\0';return ret;
}//base64解码
char *base64_decode(const char *data, int data_len, int *len)
{int ret_len = (data_len / 4) * 3 + 1;int equal_count = 0;char *ret = NULL;char *f = NULL;*len = 0;int tmp = 0;int temp = 0;char need[3];int prepare = 0;int i =0;if (*(data + data_len - 1) == '='){equal_count += 1;}if (*(data + data_len -2) == '='){equal_count += 1;}ret = (char *)malloc(ret_len);if (ret == NULL){printf("No enough memory\n");exit(0);}memset(ret, 0, ret_len);f = ret;while (tmp < (data_len - equal_count)){temp = 0;prepare = 0;memset(need, 0, 4);while(temp < 4){if (tmp >= (data_len - equal_count)){break;}prepare = (prepare << 6) | (find_pos(data[tmp]));temp++;tmp++;}prepare = prepare << ((4-temp) * 6);for (i = 0; i< 3; i++){if (i == temp){break;}*f = (char)((prepare >> ((2-i) * 8)) & 0xFF);f++;(*len) ++;}}*f = ' ';if (data[data_len - 1] == '='){(*len)--;}return ret;
}
int main()
{
//在former里填入要编码的数据char *former ="a";int len1, len2;printf("%s\n", former);
//在第二个参数中填入要编码的数据的长度char *after = base64_encode(former, 1, &len1);printf("%d %s\n", len1, after);former = base64_decode(after, len1, &len2);printf("%d %s\n", len2, former);
}