引言
关于LiveData,在2022尾声的今天,从事 Android 开发的小伙伴一定不会陌生。相应的,关于 LiveData 解析与使用的文章更是数不胜数,其中不乏优秀的创作者,在众多的文章以及前辈面前,本篇也不敢妄谈能写的多么深入,易懂。
本篇主要想着重聊聊 LiveData 的实现思想,以及与之相关联的一些问题,试着从另一角度告诉你这些答案,或者说是个人的浅薄理解。
在我的认知里,如果你了解完这些,那么对于 LiveData ,我想就也就不会再有疑问:)
在阅读本文前,建议读者有以下前置知识储备:
- 熟悉并会使用
LiveData;- 理解
Lifecycle的设计;
导航
本篇将从以下几个方面解析 LiveData:
LiveData简要快析;LiveData源码简析;LiveData设计思想;LiveData与Lifecycle的关联;LiveData用作事件通知时的隐患;LiveData与EventBus的区别是什么;LiveData和Flow我该怎么选;
好了,让我们开始吧! 🐊
LiveData简要快析
在官方的描述中,LiveData 如下所示:
LiveData是一种可观察的数据存储器类。与常规的可观察类不同,LiveData具有生命周期感知能力,意指它遵循其他应用组件(如activity、fragment或service)的生命周期。这种感知能力可确保LiveData仅更新处于活跃生命周期状态的应用组件观察者。
说简单就是 LiveData 是一个可观察的数据存储类,内部借助了 Lifecycle,从而实现了生命周期感知,同时,这个可观察指的是,在其存储的数据更新时,它会去通知观察者。又因为生命周期感知的存在,所以可以做到 何时通知、何时解绑,从而做到安全无泄漏,就是如此:)
LiveData与Lifecycle的关联
说一句比较夸大的话,没有 Lifecycle,自然也不会存在 LiveData,或者说应该改名为 ObserveData 🤪。LiveData 作为作为生命感知型组件一部分,自诞生之初其,就离不开 Lifecycle 这个基石。
而 LiveData 规定了,当我们开发者订阅数据通知(调用observe())时,必须传递相应的 lifecycle 对象,其内部自然就是为了注册相应的观察者,从而做到生命周期感知,不然它怎么能自己解绑呢?
当我们的观察者生命周期处于 STARTD 或者 RESUMED 状态,LiveData 就会认为当前观察者处于活跃状态,此时就会触发相应的更新通知,而非活跃的观察者自然不会收到通知。也正是因为 Lifecycle 的原因,所以 LiveData 做到了自动解绑,从而避免内存泄漏。
关于 Lifecycle ,这里也顺便再提一下:
说到
Lifecycle,在sdk26以后,Lifecycle已经被写入了我们 Androidx 基础组件,默认会在ComponentActivity及Fragmeent中初始化,并且支持开发者自行调用lifecycle对象,从而添加相应的生命周期观察者,从而免除模版代码。相应的,Lifecycle将生命周期划分为了如下几个阶段:
DESTROYEDINITIALIZEDCREATEDSTARTEDRESUMED这几个阶段与我们开发者其实并不相关,开发者往往关注的是其对应的Event。即
Lifecycle将生命周期划分为多个状态,当生命周期改变时,就会触发生命周期事件通知(比如 onResume() 等),从而同步当前的状态,而状态相当于一个事件集,其代表了当前lifecycle的状态,从而不拘泥于现在Event到底处于什么。
LiveData设计思想
其实,要理解 LiveData 的设计思想,最简单的方式就是手动实现一遍,所以本小节将完整叙述一遍 LiveData 的整体设计流程。👨🏻💻
在开始之前,我们先看一段普通的示例代码,如下所示:
private val _livedata: MutableLiveData<String> = MutableLiveData()
val liveData: LiveData<String> = _livedatafun manager(){_livedata.postValue(x)_livedata.setValue(x)
}fun observeX(){liveData.observe(lifecycle,Observer)
}
LiveData 的使用一般如上所示,我们一般会先初始化一个 MutableLiveData 对象,然后对外暴漏 LiveData 对象,从而遵循开闭原则,外部调用者只允许订阅观察者,观察数据更新,而不允许主动通知数据更新,当然这也是 LiveData 的标准推荐用法。
如果我们自己要实现一个 LiveData ,其内部维护着一个数据,并且要保证这个数据在更新时,观察者可以收到通知,并且要在页面活跃状态才行。此时,就有如下几个问题🧐:
- 数据怎么维护?
- 数据什么时候通知? 通知时机呢?
而要说清上述问题,即正是对LiveData的设计思想做一个阐述。
- 要满足上述条件,我们需要设计一个类,假设名字叫做
ObserveData,并且内部持有一个数据T,因为要支持多种数据类型,所以泛型也必不可少; - 为了支持数据监听,我们需要新增一个具体的监听数据更新方法,假设名字叫做 observe() ,当然也需要传入具体的观察者
IObserve接口对象; - 为了支持数据更改,我们需要新增一个具体的设置数据的方法,假设名字叫做 setValue();
- 为了在用户调用 setValue() 更新数据时,通知用户变更,我们需要新增一个观察者列表map,从而将用户 observe() 传递进来的观察者保存起来;
- 为了符合Android的生命周期,保证页面活跃状态才能收到通知,从而避免非活跃观察者被通知到,节省性能;以及能不能将解绑逻辑让框架自行执行,从而免除调用者手动调用模版代码;自然而然,我们就会想到
Lifecycle,所以我们可以在 observe() 这里做改动: -
- 我们更改了 observe() 方法,调用者必须传递
lifecycle对象进来; - 我们新增了一个新的包装类假设名字叫做
ObserverLifecycleWrapper,其需要实现LifecycleEvent接口,以及内部保存着我们的观察者; - 最后,当用户在调用 observe() 订阅数据更新时,我们就将用户传递的观察者使用包装类包装起来,并缓存到我们的观察者map中,接着再将其 add() 到
lifecycle的生命周期观察数组里,从而便于收到生命周期更新通知;
- 我们更改了 observe() 方法,调用者必须传递
- 上述的实现看似简单,但仔细思考就有个问题,如果观察者此时处于不活跃状态呢?此时用户更改了数据,那这个数据更改就没法通知给用户;那如果观察者又转为活跃状态了,本次更改岂不是跳过了?相应的,我们又怎么确保同一个数据更新不会触达用户两次呢?
-
- 为了解决上述问题,我们增加了 [版本号] 的概念,我们的
ObserveData中持有一个最新版本号,每一个观察者包装类ObserverLifecycleWrapper也维护着这个的版本号。即当用户每次手动更新数据时,我们对 版本号进行++ ,然后再去通知相应的观察者,如果这个 观察者的版本号<小于当前ObserveData最新的版本号,我们就认为这个观察者依然持有着旧的数据,就对其进行更新,并将新的版本号赋值给这个观察者; - 相应的,因为我们的观察者订阅了
lifecycle生命周期更新,所以当生命周期由非活跃转为活跃状态时,我们就再去对比一下当前观察者的最新数据版本号与我们当前最新的版本号是否一致,如果不一致,则主动更新;否则跳过。
- 为了解决上述问题,我们增加了 [版本号] 的概念,我们的
上述思路看着很繁琐,但其实比较简单,也即是 LiveData 的整个设计思路,但如果你理解 Lifecycle ,上述的理解我想对你来说,就是 so easy🤌。
但仔细观察,不难发现上述的思路中,似乎隐藏着一些问题,而这些问题,似乎也是充满一些争议,比如每次 observe() 时,因为lifecycle + version 的问题,会导致新的观察者重新订阅后数据被回推,而关于这个问题我们也会在后面进行补充。
LiveData源码简析
在上面我们阐述了 LiveData 的设计思想,有了上面的基础,那么再看源码就非常简单了🏃🏻。
而要探究 LiveData 的源码,我们只需要去看看相应的 observe() 和 postValue() 即可,为什么这么说呢?
原因很简单,一个好的框架库,会遵循 开闭与最少原则,即暴漏给开发者往往只有几个主要方法。而在
LiveData的设计中,observe() 和 postValue() 两个方法是离我们开发者最接近的,而了解完这两个方法,也就不难理解LiveData的底层实现,以及为其他问题解析做出铺垫。虽然也有 observeForever(), removeObserve(),但这些都比较简单,不影响我们阅读主流程。
observe()
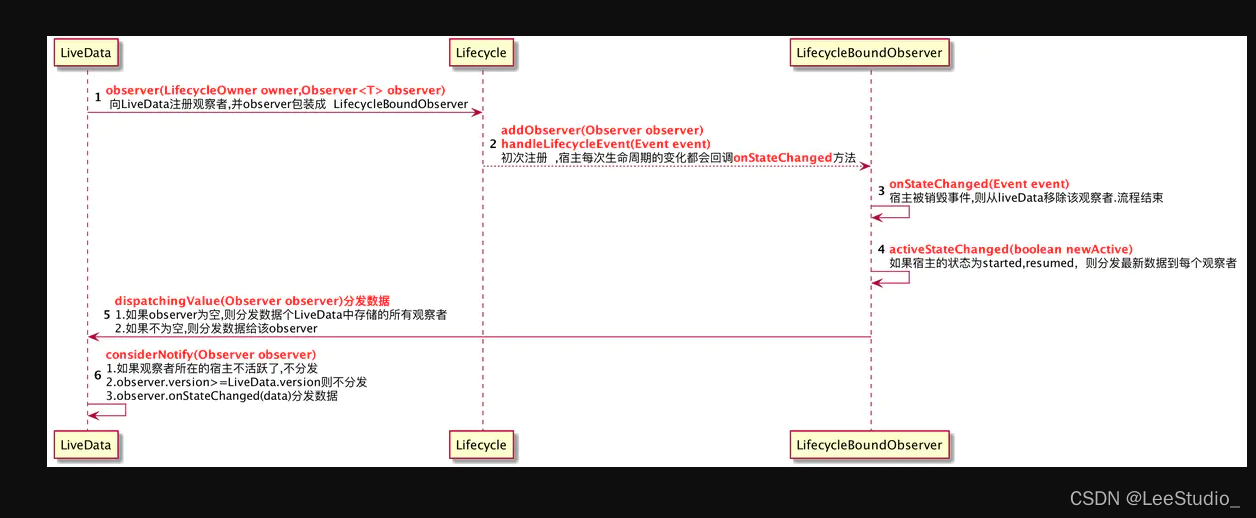
用于订阅LiveData的数据更新,源码如下:
@MainThread
public void observe(@NonNull LifecycleOwner owner, @NonNull Observer<? super T> observer) {// 创建生命周期绑定观察者,这里相当于是对我们观察者的一个包装LifecycleBoundObserver wrapper = new LifecycleBoundObserver(owner, observer)// 将观察者添加到缓存中,如果存在,则跳过ObserverWrapper existing = mObservers.putIfAbsent(observer, wrapper)...// 将观察者添加到Lifecycle订阅列表中,即赋予生命周期订阅owner.getLifecycle().addObserver(wrapper)
}
在调用 observe() 订阅 Livedata 数据更新时,这里相当于添加了一个观察者,方法内部会将我们传递的 LifecycleOwner 与 观察者 包装为一个具体的生命周期观察者 wrapper(LifecycleEventObserver),接着将这个 wrapper 添加到当前的观察者列表中,如果存在则停止本次订阅操作,否则将这个观察者添加到 lifecycle 生命周期订阅列表。
因为 LifecycleEventObserver 实现了 LifecycleEventObserver 接口,故这个 wrapper 实则具备了生命感知,所以不难猜测,LiveData 为什么能做到自动解绑,页面活跃时接收消息,也是因为 lifecycle 的原因。
postValue()
用于在非主线程更新 LiveData 中持有的数据,内部最终会调用 setValue() ,具体如下:
protected void postValue(T value) {boolean postTask;// 进入对象锁synchronized (mDataLock) {// 数据是否set过postTask = mPendingData == NOT_SET;// 待同步的数据mPendingData = value;}// 当前正在postValue,忽略本次操作if (!postTask) {return;}// 将任务发送到主线程执行ArchTaskExecutor.getInstance().postToMainThread(mPostValueRunnable);
}private final Runnable mPostValueRunnable = new Runnable() {public void run() {Object newValue;synchronized (mDataLock) {// 获取最新待设置的数据newValue = mPendingData;// 重置待同步的数据为默认mPendingData = NOT_SET;}// 设置数据setValue((T) newValue);}};
上述方法的实现很巧妙,内部会先判断当前是否正在更新数据(即数据是否为默认),然后将我们要设置的数据保存起来,如果正在更新,则跳过本次任务发送,否则将本次更新任务发送到主线程去执行(不难猜测内部也是handler执行),在具体的 runable 中,会直接去取最新待同步的值,然后将其置为默认值,最后执行真正的数据更新,即 setValue();
不过需要注意的,多线程下调用,可能会丢失某次的通知。
setValue()
用于在主线程更新 LiveData 持有的数据,其内部实则分为了三个步骤,如下所示:
-1. 设置数据:
protected void setValue(T value) {// 版本号++mVersion++;// 同步数据mData = value;// 分发数据dispatchingValue(null);
}
-2. 分发数据:
void dispatchingValue(@Nullable ObserverWrapper initiator) {...// 不为null时证明是lifecycle状态变为活跃if (initiator != null) {considerNotify(initiator);initiator = null;} else {//setValue时触发, 轮训观察者列表去更新for (Iterator<Map.Entry<Observer<? super T>, ObserverWrapper>> iterator =mObservers.iteratorWithAdditions(); iterator.hasNext(); ) {considerNotify(iterator.next().getValue());// 如果分发失效,直接跳出(非关键点)if (mDispatchInvalidated) {break;}}}...
}
-3. 通知观察者:
private void considerNotify(ObserverWrapper observer) {// check当前观察者持有的生命周期状态,即非onsStart-onPause时直接returnif (!observer.mActive) return;// 再次check观察者最新状态,即检查lifecycle对应的状态if (!observer.shouldBeActive()) {// 如果非活跃状态,通知观察者当前非活跃状态observer.activeStateChanged(false);return;}// 版本检测,如果当前观察者持有的版本>=当前的版本,即证明已经更新过了if (observer.mLastVersion >= mVersion) {return;}// 更新观察者当前的版本observer.mLastVersion = mVersion;// 执行数据通知observer.mObserver.onChanged((T) mData);
}
让我们总结一下上述的整体思路,当我们调用 setValue() 时,内部会对当前 LiveData 持有的版本号 version 进行自增,然后调用dispatchingValue() 去分发本次数据,然后会去轮训当前的观察者列表,然后判断观察者是否是活跃状态,即是否是 onStrat() - onPause() 之间,如果是并且当前观察者的版本号小于 LiveData 维护的版本号,由此证明当前观察者尚未通知过,从而触发通知。
LiveData用作事件通知时的隐患
关于这个问题,经常会被开发者提起,或者叫做数据倒灌,数据回推更为合适,但这些问题其实都是在 [不正确] 的背景下使用LiveData导致。
比如常见于共享的 LiveData ,使用 LiveData 作为事件通知,大家会发现为什么刚刚 observe() 的观察者,马上就响应了数据更新,并且还是旧数据,那这是为什么呢?
问题很简单,在上面我们已经说过了,当我们调用 observe() 添加数据观察者时,内部实际会被包装为
LifecycleBoundObserver,从而添加到lifecycle的生命周期观察者列表。而熟悉lifecycle的小伙伴,肯定明白了,当我们添加lifecycle生命周期观察者时,其观察者的生命周期状态会被相应的执行到当前的lifecycle状态,所以自然会调用LifecycleBoundObserver中的状态更新方法,从而触发了数据分发。而又因为这个观察者是新添加进去的,观察者持有的数据版本号是默认的,即-1,但是LiveData内部的数据版本号可不是啊!,所以自然触发了数据更新通知。
那这个问题属于LiveData的设计问题吗?
并不属于,相反这个设计,是非常符合生命周期组件的定义。
LiveData 往往是为了界面数据的状态同步而作准备,所以当添加观察者后,被再次通知,也不难理解。因为对于页面而言,这个观察者的确是新添加的,如果 LiveData 中存在数据,肯定需要第一时间同步到页面更新。
具体我们看一眼官方对其的描述:

但既然 LiveData 这么安全好用,所以就会有开发者想着使用 LiveData 用于事件通知,此时它的设计在某种程度上就成了问题,虽然在官方的建议里,非常不建议直接这么用。
常见有如下几个解决思路:
-
反射解决version
在调用 observe() 方法里,反射相应的包装类
ObserverWrapper,把其的版本号更改为LiveData现有的版本号; -
SingleLiveEvent
计算机科学领域一直流传着一句格言:任何问题都可以通过增加一个间接的中间层来解决。
我们手动维护一个标记,并在 observe() 方法里,并再次包装观察者
Observer,这样当数据每次通知时,我们就可以拦截,从而用这个标记做判断,如果符合要求,则调用真实观察者的通知方法,并更新标记值。在我们每次 setValue() 时,再重置这个标记即可。具体可参见 Android-architecture-simple-SingleLiveEvent
-
手动维护version
这个方式可以说是对
SingleLiveEvent的一个完善与补充。既然
version我们无法避免,那么不如我们自己维护一个version,即继承LiveData,自己维护version,同时添加一个新的观察者包装类,内部持有一个版本号,对传递进来的观察者进行包装,并重写相应的 onChanged() 方法,内部会去判断观察者当前版本号,如果当前版持有的版本号<我们自己维护,则触发更新,并且更新观察者版本号;当我们每次 setValue() 时,并对version进行自增;在 observe() 时,再将当前持有的version赋值给我们的包装类,从而完成了整个套娃流程。具体可参见 KunMinx的UnPeek-LiveData-ProtectedUnPeekLiveData
-
改用其他方式
解决不了问题,就把提出问题的解决了:)
人生苦短,我选
Flow(SharedFlow)。
LiveData与EventBus怎么选
先说结论,这两者并不冲突,主要因为其各自负责的事情不一样。
LiveData用于处理[界面]的数据的状态,即常用于界面的数据状态同步;EventBus是用于事件总线,即是分发App中所有事件的一个中转站;
前者常用于于处理界面数据状态,并且遵循 Android 生命周期模式。而后者是作用于事件通知,即可以确保本次发出的事件一定会被可观察的接收者收到,虽然后者也支持 Sticky ,这点似乎和LiveData相似,但这两者在思想上本来就是大不相同。
对于开发者而言,因为两者使用起来的共性何其的相似,特别是作用于共享的页面时,开发者很容易会想到二选一问题,但事实上,仔细分析的话,就会发现:
- 对于
LiveData,这属于共享页面的数据状态同步;- 对于
EventBus而言,这属于共享页面[事件]的通知;两者完全不在一个领域,即
EvenBus不会关心你的数据后续,它只关心事件通知了吗? 我要不要在你订阅时再告诉你这个事件?而LiveData会帮你持有这个数据状态,同时需要关心我必须在合适的生命周期内再告诉你,以及在你重新订阅时再次告诉你(如果存在数据)。
因为LiveData其本身的设计驱使,由此也很容易诞生LiveDataBus,在具体的功能上,其做的事情和 EventBus 相似,在某些特性上,甚至优于后者。具体可以参见美团的 LiveEventBus
LiveData和Flow怎么选
这里的
Flow通常其实指StateFlow与SharedFlow。
这个问题,也常被开发者提起。诸如,官方推荐在 MVVM 及 MVI 中使用 Flow ,就是要革了 LiveData 的命?但其实,这两者也没什么直接冲突。
搞点小彩头,对于 非Kotlin 项目,你怎么用 Flow ? 😅
Flow: 那我走?
Rx: 我来我来。
先说说 Flow ,其指的是 Kotlin 中的数据流,虽然功能上不如Rx强大,但在 Kotlin 的背景下,其无疑是最佳搭档,毕竟有协程这个好兄弟在,因此,Android团队建议使用 Flow 替换 LiveData 。
再说说 LiveData ,其本设计简单轻巧,但功能不强,仅仅只能用于数据状态的同步。在多线程下 postValue ,甚至会丢掉某次的数据更改(其本身也不推荐用于通知事件的作用),不过也没什么问题,因为其本身就不是用来帮你做频繁数据处理的。
说的更详细点:
在2017年,
Kotlin的占有率可没那么高,所以LiveData作为 AAC 的重要组件自然承担了大部分责任。而在2022的今天,Kotlin在Android开发中的占有率早已经超过63%(这只是2021年统计),随着日益增加的业务与架构挑战,LiveData显然不能满足更多需求,架构也需要更先进的组件支持。相比
LiveData,Flow就显得更加强大,不仅独立于具体的视图层,而且其可以单独的集成到业务模块。在功能上,支持数据的各种处理,搭配协程,是Kotlin背景下不可获取的利刃。相应的,在Android上 面,Flow也可以通过 asLiveData() 从而转为LiveData,由此兼容使用。
如果你的项目是 Java 编写,那 LiveData 仍然是你维护页面数据状态的最好搭档。
如果你的项目是 Kotlin 编写,那么 LiveData 依然可以满足你的需求。但如果你想做更多事,比如想在发送数据时顺便处理一下,从而更自动的完成数据状态的处理,Flow 也许更加符合你的要求,当然你也可以随时将 Flow 转为传统的 LiveData 使用(对外部调用者而言)。当然需要注意的是,Flow 并不能感知 Android 的生命周期,你可能需要再增加一些模版代码,但好在Android团队做了各种扩展方法,这个成本在今天也是非常小。
总结
本篇,我们通过问题解答的方式,由浅入深,回顾了 LiveData 的设计思想,以及其相关的一些疑问,从而从根源上解释了这些问题。
到了这里,我们也无需再拘泥于人云亦云的数据是否倒灌、设计是否合理、到底和其他组件该怎么选、项目中到底该用什么,这些问题我相信都不是问题。因为在不谈的背景的情况下,没有绝对的标准与统一的准则,那就更别提对与错。但至少对于 LiveData 而言,了解完本篇的你,我相信再也不会再有相关疑问。
参阅
- 官方文档-LiveData概述
- 如何优雅的使用LiveData实现一套EventBus(事件总线)
- [Android]/architecture-samples/SingleLiveEvent
- [KunMinx]/UnPeek-LiveData/ProtectedUnPeekLiveData
关于我
我是 Petterp ,一个 Android工程师 ,如果本文对你有所帮助,欢迎点赞支持,你的支持是我持续创作的最大鼓励!