面试官过程中UI自动化必问的几个问题总结:
一、有做过UI自动化吗?怎么做的?这个问题在面试中问UI自动化相关技能的时候常常被问到,那该如何去回答呢?
接下来我就UI自动化相关的一些面试的问题做一个解答:
1、你做过UI自动化吗?用什么做的?
可以回答说做过,用的是python+selenium+unittest单元测试框架来做的,如果又问这个框架是你自己搭建的吗?还是公司原来就有的你只是使用?可以说自己参与过搭建(搭建过程其实不难,难在这个框架的设计,一个项目涉及到很多模块,这些模块又是不同的人在负责,而且涉及到很多业务上依赖性的东西以及一些最终产出的关注点的不一样,框架搭建好后是整个自动化团队一起使用,所以大家也都是聚在一起商量这个框架改如何设计是否满足每个模块的最终产出要求)
这个框架改如何搭建呢?在这里我讲一下UI自动化的一个基本的操作流程和几大最基本的分层;(当然每家公司的业务不一样,也可以多一些分层以满足自家的业务需求,但最基本的核心分层以及作用还是一样的)
首先我来讲一下做UI自动化的一个操作流程:
首先的话就是我需要打开pycharm然后新建一个py模块,然后导入selenium模块,time模块等等,然后通过from selenium import webdriver语句导入webdriver模块,然后创建一个driver对象:driver=webdriver.Chrome(),再通过driver.get方法来打开我们测试环境的地址,再使用 driver.maximize_window()最大化浏览器窗口,然后会使用driver.implicitly_wait()设置一个隐式等待,我可以通过driver.find_element_by_id,或者xpath,name,class,css等元素定位方法来进行定位到用户名和密码输入框,并且通过调用send_keys进行输入用户名和密码,最后通过调用click方法进行登录,登录之后,有一些表单的填写页面(比如主要有姓名、证件信息、手机号码、常住地址、邮箱、紧急联系人等等,如果是输入框我依旧用send_keys,如果有一些下拉框我会导入Select类,通过select_by_value方法进行定位,如果有滑动的地方我也会用window.scrollTo()方法,设置变量为js,然后通过driver.execute_script()来调用js变量来达到滑动滚动条的目的,包括如果是有iframe弹框的话,我首先会通过switch_to.frame()进入到iframe弹框,然后再进行其他的操作,如果要退出iframe框的话,直接用switch_to.default_content()方法就可以了,最后写完整个一个流程之后,我还会通过调用text方法拿到某个元素的文本值赋值给到一个变量,然后通过assert方法把预期结果和实际结果进行一个断言,以上就是我做ui自动化的一个大致流程,但是这是我们最开始做ui自动化的方法,后面因为做的时间也比较久,用例也比较多,所以后续用了一些PO设计模式和分层对用例进行了一些封装
面试官如果问:那你们后面是怎么封装的呢?
我们大概分了6层,来对我们的UI自动化进行了封装,要和您讲一下具体的代码吗?
1)如果面试官回答讲一下吧,那就需要讲详细一点
2)如果面试官说不用,大概讲一下分层架构就可以了,那就讲讲简单一点
当然,如果你代码能力不怎么样,就别给自己挖坑,万一真的要你讲代码,现场气氛一下子就会变的很尴尬,你可以主动说之前这个框架参与过搭建,要不要给介绍一下,接着你把框架分层简单的介绍一下就行了,当然你代码能力还可以,你可以详细的讲讲也行
代码方面大家可以参考这篇:UI自动化框架设计(含代码)
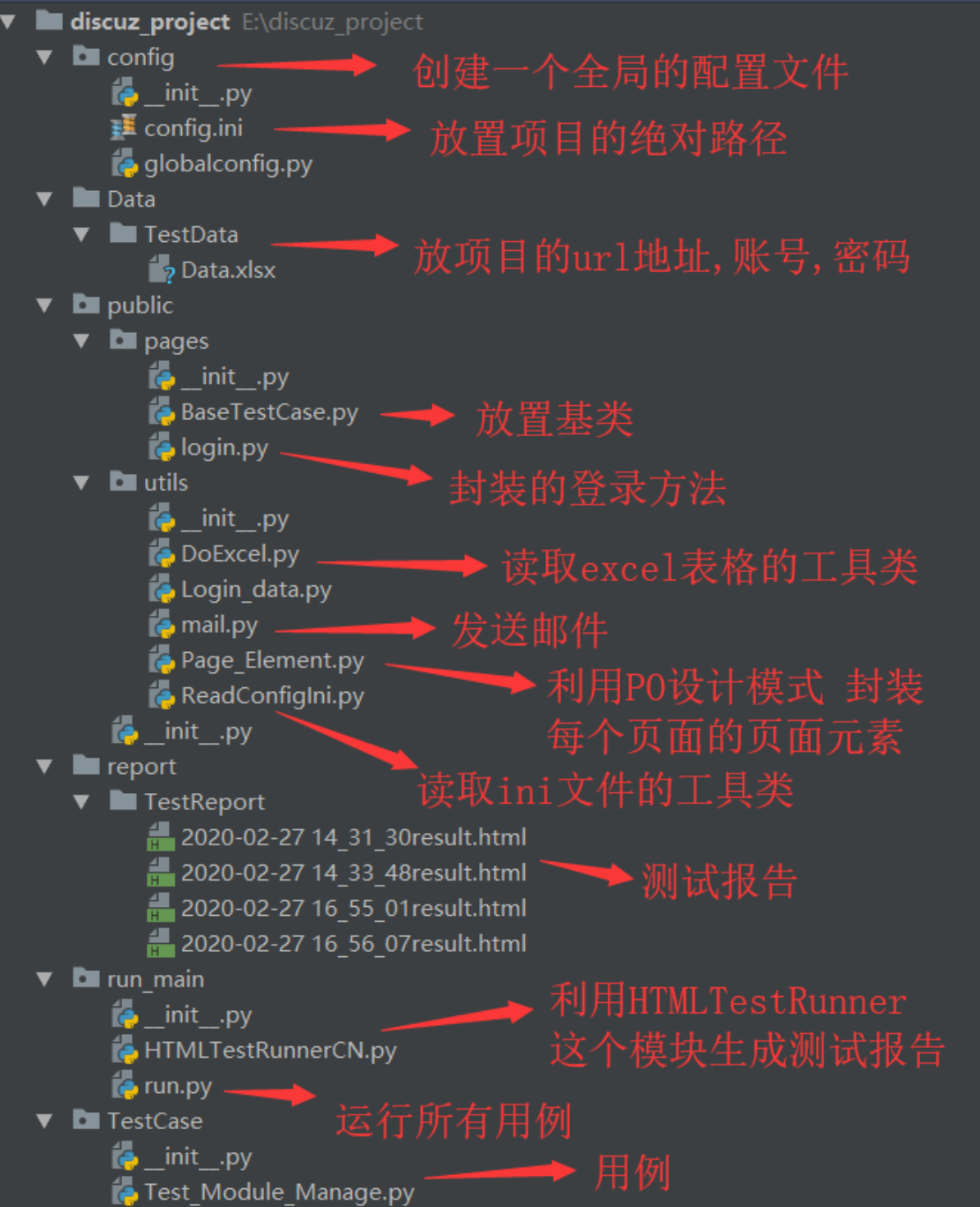
接下来我来讲一下这个框架是怎么分层的
这个框架我设计了六层,大家可以做个参考
第一层:的话是config配置层,这个里面主要是封装了一些我们测试环境的url地址和一些连接数据库的IP地址,用户名密码等等
第二层:是utils工具类层,这个里面主要封装了一些读取Excel表格的工具类,还有发邮件的工具类,还有一些读取配置文件的工具类
第三层:是一个public基类,这个里面主要封装了元素定位的方法比如把id,name,class,xpath,css等等都封装在一个类方法里面了,还把一些send_keys和隐式等待和其他其他公共方法都进行了二次的封装
第四层:就是testcase用例层了,这个里面主要就是通过定义一个类然后继承unittest.TestCase这个类,通过unittest单元测试框架来管理用例,在setupclass里面去创建driver对象,然后通过设置和取值的方法,拿到driver对象,先编写登录的用例,然后这个里面也用到了PO设计模式,把我们的元素定位和流程层,代码层进行了分离,最后用例写完再通过self.assertEquals进行一个断言
第五层:就是run运行层,首先会通过把所有的用例加载到一个suite套件里面,然后再通过调用run方法运行这个套件
第六层:就是通过HTMLtestrunner模块生成测试报告,然后最后通过Jenkins做可持续集成,在回归测试阶段,每天晚上都会运行一下我们的ui自动化用例,大致的一个框架结构就是这样的
下面截图是这个框架的大致样子
接下来我讲讲UI自动化面试中其它的一些问题:
二、自动化中遇到了什么问题?如何解决?
1、有的时候动态元素定位不到 —> 我会采用xpath相对路径自己写xpath语法来进行定位
2、有的时候自动化脚本执行速度较慢 —> 我会尽量少用xpath绝对路径,因为xpath绝对路径执行速度很慢,并且我会少用sleep方法,涉及到一些if elif条件判断时,尽量把可能发生的条件放在前面写,这样可以减少程序判断的次数,提高效率
3、弹框内有按钮点击不到 —> 弹框里面有设置滚动条,首先进入弹框里面,将滚动条滑动到最底部才可以点击确定或者取消按钮
4、有的时候元素没有加载出来 —> 我会通过设置隐性等待和显性等待来解决
5、有的时候还会碰到iframe框 —> 我会通过driver.switch_to.frame先进入到iframe框里面,再去定位到里面的元素
6、有的时候还会有alert弹框 —> 我会先点击确认弹框活取消弹框之后再定位其他的元素
三、UI自动化中的PO设计模式是什么意思?
PO设计模式英文全称就是Page Object,中文的意思就是页面对象设计模式,指的是所有当前页面的控件和元素都为类或者对象的属性,我们平时用PO设计模式,主要分了三层,最底层是元素定位层,就是把元素定位方法id,xpath,name,css等等和元素通过元组来接受,并且放在一个类当中,第二层是流程层只写我们的流程,第三层就是我们的用例也就是我们的代码层了,代码层会调用流程层,并且在需要元素定位的时候都是把底层已经封装好的元组也传进来就可以了,相当于就是不会把代码写死,起到了一个分离和解耦的作用,这个就是我理解的PO设计模式。
PO设计模式优势如下:
1. 让元素定位,流程,案例进行了分离
2. 前端代码关于元素定位有改动可以随时进行处理,修改非常方便
3. 让代码间的耦合性降低
4. 降低代码的维护成本,代码的复用性高
先写到这里,其它的问题我后续想到了我再继续补充。。。