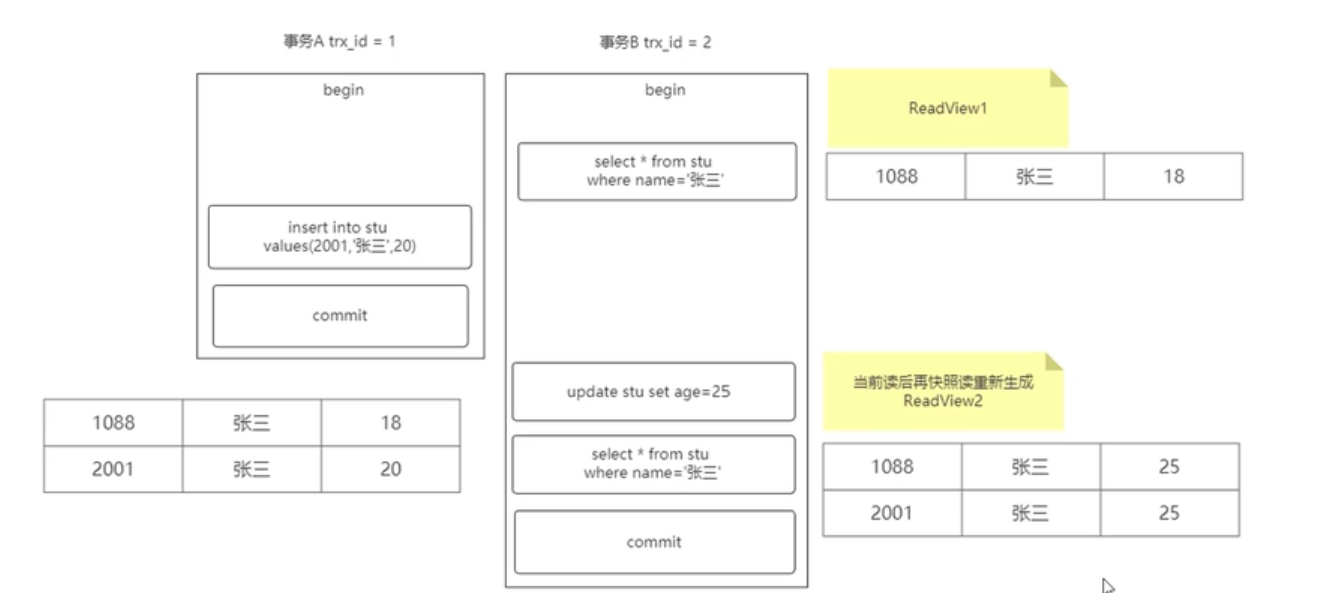
一. 为单元测试“正名”
我曾经认为,单元测试面向的是一个函数。任何走出一个函数的测试,都不是单元测试。
其实,对“单元”的定义取决于自己。如果你正在使用函数式编程,一个单元最有可能指的是一个函数。你的单元测试将使用不同的参数调用这个函数,并断言它返回了期待的结果;在面向对象语言里,下至一个方法,上至一个类都可以是一个单元(从一个单一的方法到一整个的类都可以是一个单元)。意图很重要(“意图”二字是本文中第一次提到,它很重要)
我们有单元测试、增量测试、集成测试、回归测试、冒烟测试等等,名字非常多。谷歌看到这种“百家争鸣”的现象,创立了自己的命名方式,只分为小型测试、中型测试和大型测试。
·小型测试,针对单个函数的测试,关注其内部逻辑,mock所有需要的服务。
小型测试带来优秀的代码质量、良好的异常处理、优雅的错误报告
·中型测试,验证两个或多个制定的模块应用之间的交互
·大型测试,也被称为“系统测试”或“端到端测试”。大型测试在一个较高层次上运行,验证系统作为一个整体是如何工作的。
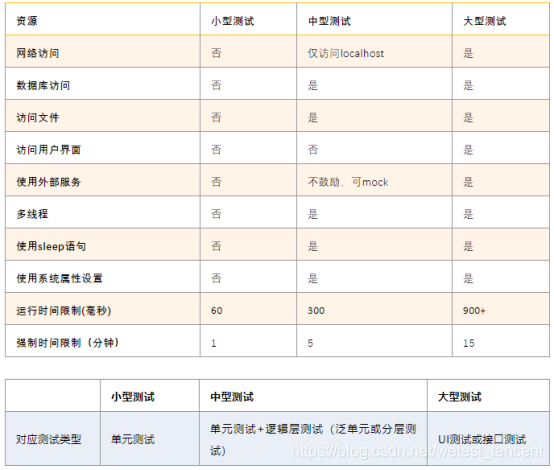
结论:我们的单元测试,既可以针对一个函数写case,也可以按照函数的调用关系串起来写case。
二. 金字塔模型
在金字塔模型之前,流行的是冰淇淋模型。包含了大量的手工测试、端到端的自动化测试及少量的单元测试。造成的后果是,随着产品壮大,手工回归测试时间越来越长,质量很难把控;自动化case频频失败,每一个失败对应着一个长长的函数调用,到底哪里出了问题?单元测试少的可怜,基本没作用。
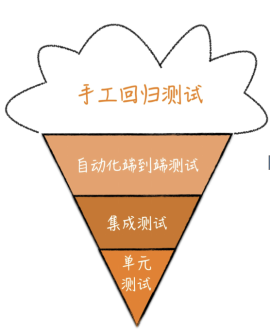
Mike Cohn 在他的着作《Succeeding with Agile》一书中提出了“测试金字塔”这个概念。这个比喻非常形象,它让你一眼就知道测试是需要分层的。它还告诉你每一层需要写多少测试。
测试金字塔本身是一条很好的经验法则,我们最好记住Cohn在金字塔模型中提到的两件事:
·编写不同粒度的测试
·层次越高,你写的测试应该越少
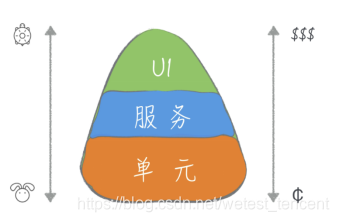
同时,我们对金字塔的理解绝不能止步于此,要进一步理解:
我把金字塔模型理解为——冰激凌融化了。就是指,最顶部的“手工测试”理论上全部要自动化,向下融化,优先全部考虑融化成单元测试,单元测试覆盖不了的 放在中间层(分层测试),再覆盖不了的才会放到UI层。因此,UI层的case,能没有就不要有,跑的慢还不稳定。按照乔帮主的说法,我不分单元测试还是分层测试,统一都叫自动化测试,那就应该把所有的自动化case看做一个整体,case不要冗余,单元测试能覆盖,就要把这个case从分层或ui中去掉。
越是底层的测试,牵扯到相关内容越少,而高层测试则涉及面更广。比如单元测试,它的关注点只有一个单元,而没有其它任何东西。所以,只要一个单元写好了,测试就是可以通过的;而集成测试则要把好几个单元组装到一起才能测试,测试通过的前提条件是,所有这些单元都写好了,这个周期就明显比单元测试要长;系统测试则要把整个系统的各个模块都连在一起,各种数据都准备好,才可能通过。
另外,因为涉及到的模块过多,任何一个模块做了调整,都有可能破坏高层测试,所以,高层测试通常是相对比较脆弱的,在实际的工作中,有些高层测试会牵扯到外部系统,这样一来,复杂度又在不断地提升。
三. 为什么做单测
这个问题我们规避不掉。新闻是这次研发模式改革的主力军之一,所以自上而下的推动让这个问题不那么棘手:做了就是做了。不做,却又有那么多的理由:
(搜集到的吐槽真实声音)
· 单元测试浪费了太多的时间
· 单元测试仅仅是证明这些代码做了什么
· 我是很棒的程序员,我是不是可以不进行单元测试?
· 后面的集成测试将会抓住所有的bug
· 单元测试的成本效率不高我把测试都写了,那么测试人员做什么呢?
· 公司请我来是写代码,而不是写测试
· 测试代码的正确性,并不是我的工作
单元测试的意义
·单元测试对我们的产品质量是非常重要的。
·单元测试是所有测试中最底层的一类测试,是第一个环节,也是最重要的一个环节,是唯一一次有保证能够代码覆盖率达到100%的测试,是整个软件测试过程的基础和前提,单元测试防止了开发的后期因bug过多而失控,单元测试的性价比是最好的。
·据统计,大约有80%的错误是在软件设计阶段引入的,并且修正一个软件错误所需的费用将随着软件生命期的进展而上升。错误发现的越晚,修复它的费用就越高,而且呈指数增长的趋势。作为编码人员,也是单元测试的主要执行者,是唯一能够做到生产出无缺陷程序这一点的人,其他任何人都无法做到这一点
·代码规范、优化,可测试性的代码
·放心重构
·自动化执行three-thousand times
下面这张图,来自微软的统计数据:bug在单元测试阶段被发现,平均耗时3.25小时,如果漏到系统测试阶段,要花费11.5小时。

下面这张图,旨在说明两个问题:85%的缺陷都在代码设计阶段产生,而发现bug的阶段越靠后,耗费成本就越高,指数级别的增高。所以,在早期的单元测试就能发现bug,省时省力,一劳永逸,何乐而不为呢。

单元测试特别耗时?
不能一刀切,不能只盯着单测阶段的耗时。
我采访了新闻客户端、后台的开发,首先肯定的是,单测会增加开发量、增加开发时长;
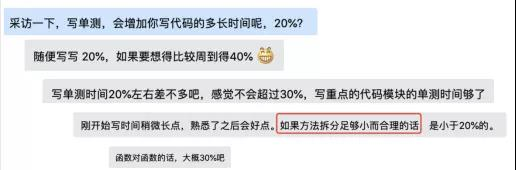
在《单元测试的艺术》这本书提到一个案例:找了开发能力相近的两个团队,同时开发相近的需求。进行单测的团队在编码阶段时长增长了一倍,从7天到14天,但是,这个团队在集成测试阶段的表现非常顺畅,bug量小,定位bug迅速等。最终的效果,整体交付时间和缺陷数,均是单测团队最少。

单测,存在即合理。一方面,需要把单测放在整个迭代周期来观测其效果;一方面,写单测也是技术活,写得好的同学,时间少代码质量高(也即,不是说写了单测,就能写好单测)
谁来写单测呢?
·开发同学写单测
·测试同学具有写单测的能力。重点在于开发脚手架、分层测试/端到端测试
增量还是存量
·单测case针对增量代码
·当存量代码出现大规模重构,后者质量暴露出极大风险时,都是推动补全单测的好时机
四. 单元测试的阶段
一. 广义的单元测试,我们指这三部分的有机组合:
·code review
·静态代码扫描
·单元测试用例编写
二. 结合新闻的实践,我把单测成长的过程分为4个目标,分别为:
·会写,全员可写
·写的好,同时关注可测性问题,试点解决
·识别可测性问题,熟练使用重构方法进行重构;识别代码架构设计问题;case与业务代码同步编写
·TDD。但这个目标是期望,不能作为必须实现的目标。
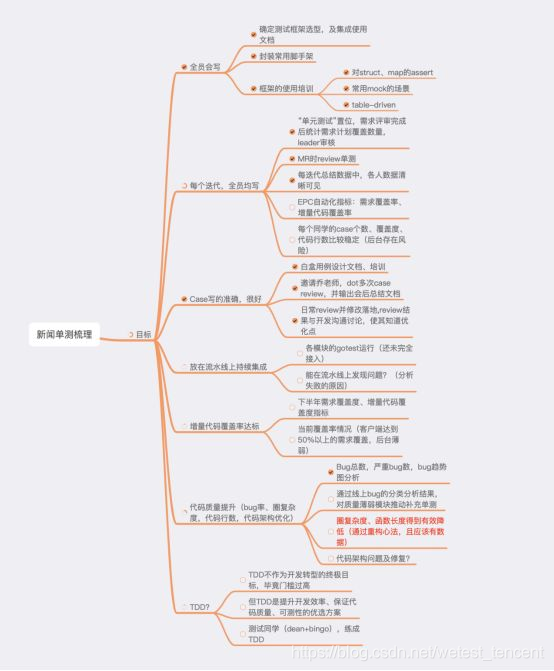
截至发稿当天,新闻处于第三阶段,即,每个迭代均能产出高质量的case,人数覆盖和需求覆盖均较高;关注重点在于可测性,时刻注重重构。
五. 单元测试的指标
还挺尴尬的,不太有直接的指标去衡量单测的效果。我们也经常被问到,“怎么证明你们新闻单测的作用呀?”
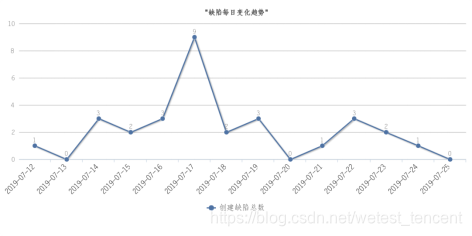
·bug类指标(间接指标):连续迭代的bug总数趋势、迭代内新建bug的趋势、千行bug率
·单测的需求覆盖度(50%以上),参与人员覆盖度(80%以上)
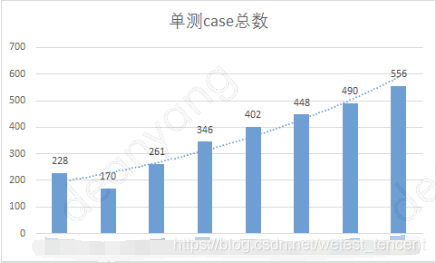
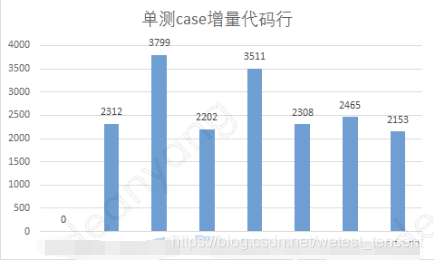
·单测case总数趋势,代码行增量趋势
·增量代码的行覆盖率(接入层80%,客户端30%)
·单函数圈复杂度(低于40),单函数代码行数(低于80),扫描告警数
在迭代需求持续高吞吐量的前提下,以新闻iOS的数据为例:

六. go单元测试框架选型
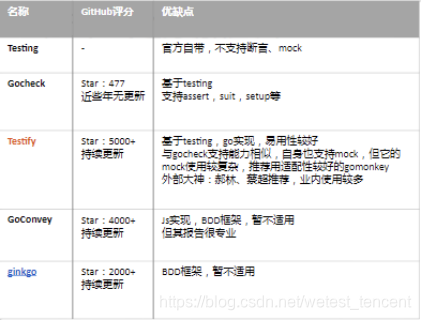
基本选型:testify + gomonkey
附加:httptest + sqlmock

前提
·测试文件,以_test.go结尾,与被测文件放于相同目录
·测试函数,函数名以Test开头,并且随后的第一个字符必须为大写字母或下划线,如:TestParseReq_CorrectNum_TableDriven
·测试函数,参数为t *testing.T;对于bench测试,参数为b *testing.B
·运行命令行,我的文章有深入讲解:go test命令行
testify常规用法
https://github.com/stretchr/testify
testify基于gotesting编写,所以语法上、执行命令行与go test完全兼容
支持大量高效的api,比如:
assert.Equal:常规对比,是把两者分别换成[]byte去严格比对
assert.Nil:判断对象为nil时,有时对err判空时也用
assert.Error:判断err的具体类型和内容
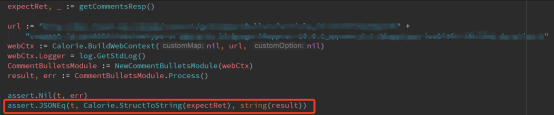
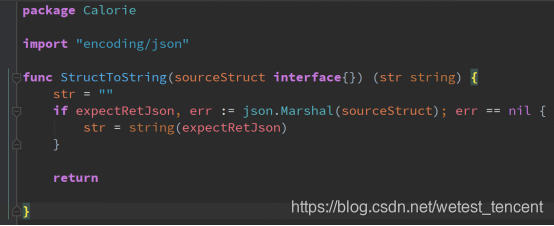
assert.JSONEq:这个比较有用,对比map时;或者对比struct的时候,也会先转为map,在用这个api去做对比,如下面这个例子,我封装了建议的方法去将struct转换为string(json):
·支持suite,用例集管理
·运行时,可以指定用例集执行
·自带mock工具,但只支持接口方法的mock,而且用法相对复杂
·table-driven

gomonkey用法(蓝色字体表示常用)
https://github.com/agiledragon/gomonkey
https://studygolang.com/articles/15034
·支持为一个函数打一个桩
·支持为一个成员方法打一个桩
·支持为一个全局变量打一个桩
·支持为一个函数变量打一个桩
·支持为一个函数打一个特定的桩序列
·支持为一个成员方法打一个特定的桩序列
·支持为一个函数变量打一个特定的桩序列
·table-driven的方式定义一系列stub
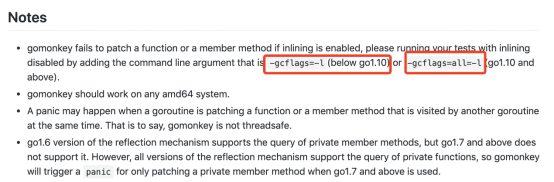
注意,对内联函数的Stub,go test命令行一定要加上参数才可生效。见官方文档。所以,我的命令行默认加上-gcflags=all=-l就行了。
我设置了一些goland的代码模板,放在附件中。
ApplyFunc是对外部函数Stub(非类方法)
/* 用法:gomonkey.ApplyFunc(被stub函数名, 被stub函数签名) 函数返回值
*例子:
patches := gomonkey.ApplyFunc(fake.Exec, func(_ string, _ ...string) (string, error) {
return outputExpect, nil
})
*/
patches := gomonkey.ApplyFunc(lcache.GetCache, func(_ string) (interface{}, bool) {
return getCommentsResp()
})
defer patches.Reset()
ApplyMethod是对类函数Stub。但这里注意,要被stub的方式是私有方法,gomonkey通过反射是找不到的,有两种解决方法:1)使用增强版的gomonkey;2)不Stub它,而是选择走进这个函数,这个话题在后面专题谈mock的时候说。
/* 用法:gomonkey.ApplyMethod(反射类名, 被stub函数签名) 函数返回值
*例子:
var s *fake.Slice
patches := ApplyMethod(reflect.TypeOf(s), "Add", func(_ *fake.Slice, _ int) error {
return nil
})
*/
var ac *auth.AuthCheck
patches := gomonkey.ApplyMethod(reflect.TypeOf(ac), "PrepareWithHttp", func(_ *auth.AuthCheck, _ *http.Request, _ ...auth.AuthOption) error {
return fmt.Errorf("prepare with nil object")
})
defer patches.Reset()
ApplyMethodSeq是对同一个Stub的函数返回不同的结果
/* 用法:gomonkey.ApplyMethodSeq(类的反射,"被stub函数名", 返回结构体);
Params{info1},中括号内为被stub函数的返回值列表;
Times为生效次数
*例子:
e := &fake.Etcd{}
info1 := "hello cpp"
info2 := "hello golang"
info3 := "hello gomonkey"
outputs := []OutputCell{
{Values: Params{info1, nil}},
{Values: Params{info2, nil}},
{Values: Params{info3, nil}},
}
patches := ApplyMethodSeq(reflect.TypeOf(e), "Retrieve", outputs)
defer patches.Reset()
*/
conn := &redis.RedisConn{}
patch1 := gomonkey.ApplyFunc(redis.NewRedisHTTP, func(serviceName string, _ string) *redis.RedisConn {
conn := &redis.RedisConn{
redis.RedisConfig{},
&redis.RedisHelper{},
}
return conn
})
defer patch1.Reset()
// mock redis data. 返回空和不为空的情况
outputCell := []gomonkey.OutputCell{
{Values: gomonkey.Params{"12", nil}, Times: 1},
{Values: gomonkey.Params{"", nil}, Times: 1},
}
patchs := gomonkey.ApplyMethodSeq(reflect.TypeOf(conn.RedisHelper), "Get", outputCell)
defer patchs.Reset()
先举这几个例子,详细的可以在上面的链接文章中全面得到。
这里补充一点,对类方法进行stub,必须要找到该方法对应的真实的类(结构体),举个例子:
//被测函数中有如下一段,其中的Get方法我们想stub掉,只要找到Get方法对应的类就好了
readCountStr, _ := conn.Get(redisKey)
if len(readCountStr) == 0 {
return 0, nil
}
定位conn,是RedisConn类型的struct
type RedisConn struct {
RedisConfig
*RedisHelper
}
所以第一次,我用gomonkey.AppleyMethod时这么写:
patches := gomonkey.ApplyMethod(reflect.TypeOf(*RedisConn),"Get", func(_ *redis.RedisHelper,_ string, _ []string) ([]string, error){
return info,err_notNil
})
defer patches.Reset()
WeTest小编提醒:上篇的内容就到这里,相信大家肯定还没看够吧~在下篇会说到关于mock、和如何不要滥用mock等等更多精彩的内容,让我们赶紧一起来看下吧~《从头到脚说单测——谈有效的单元测试(下篇)》
关注腾讯WeTest,了解更多热门测试产品:WeTest腾讯质量开放平台 - 专注游戏,提升品质