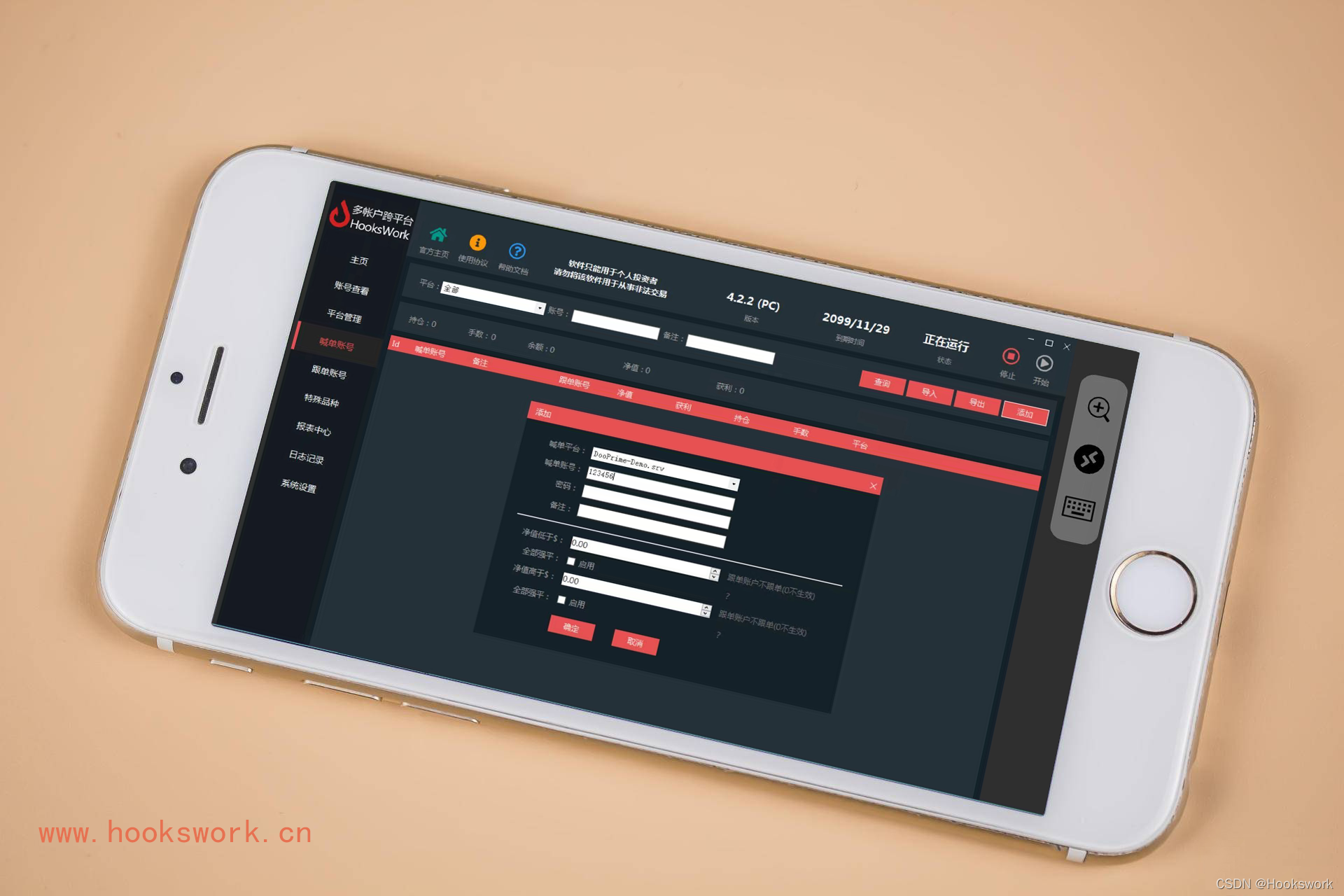
一种小型后台管理系统通用开发框架中的Cache缓存设计
本篇博客记录一下我在实习的公司的后台管理系统开发框架中学习到的一种关于网站的缓存(Cache)的实现方法,我会在弄懂的基础上,将该方法在.net core上进行实现。因为公司开发都是基于.net framework的,但是在.net 这一块,.net framework正在逐渐被.net core所取代,而目前公司的前辈们由于开发任务较重,并没有着手使用.net core的打算,所以,我自己打算为公司搭建一个基于.net core的后台开发框架,这对自己是一个挑战,但收获还是很大的,在这个过程中,我学到了很多。下面我记录一下我们公司关于网站设计中Cache的一种设计与实现方法(先说在.net mvc下的实现方法,后续会写另一篇.net core的实现方法):
-
总体设计:
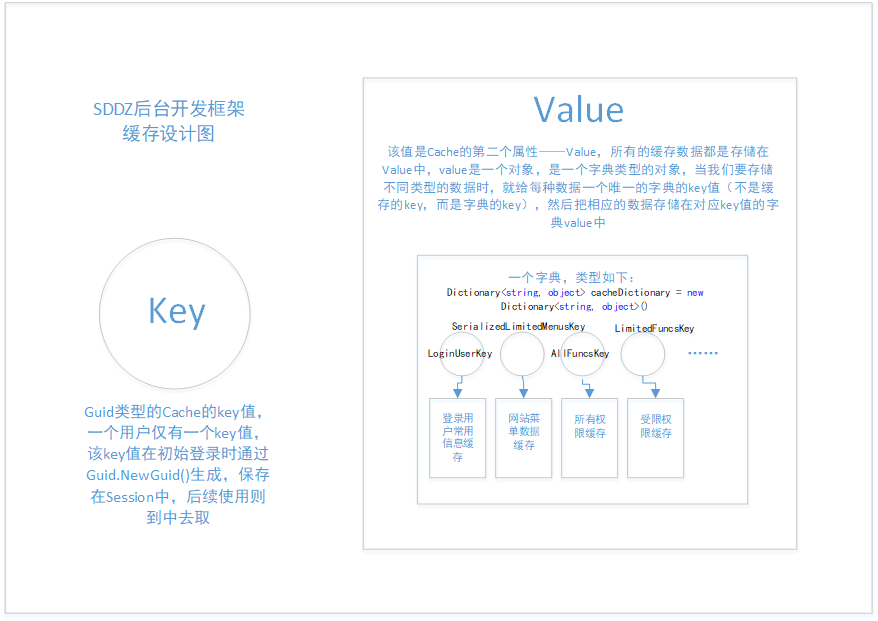
我们知道的缓存一般分为3种,分别是 Cookies,Session和Cache,这三种的区别和使用场景我在这里就不说了,网上有大神的博客说的很清楚。Cookies主要用于客户端,Session和Cache用于服务端,本篇主要讲Cahe的使用。Cache存储于服务器的内存中,允许自定义如何缓存数据项,以及缓存时间有多长。当系统内存缺乏时,缓存会自动移除很少使用或者使用优先级较低的缓存项以释放内存。Cache的使用可以提高整个系统的运行效率。
Cache在使用上也是(key,value)形式的,关于插入、获取、移除什么的,都可以在Cache类中去查看,这里贴出Cache这个类的内容:

#region 程序集 System.Web, Version=4.0.0.0, Culture=neutral, PublicKeyToken=b03f5f7f11d50a3a
// C:\Program Files (x86)\Reference Assemblies\Microsoft\Framework\.NETFramework\v4.5\System.Web.dll
#endregionusing System.Collections;
using System.Reflection;namespace System.Web.Caching
{//// 摘要:// Implements the cache for a Web application. This class cannot be inherited.[DefaultMember("Item")]public sealed class Cache : IEnumerable{public static readonly DateTime NoAbsoluteExpiration;public static readonly TimeSpan NoSlidingExpiration;public Cache();public object this[string key] { get; set; }public int Count { get; }public long EffectivePrivateBytesLimit { get; }public long EffectivePercentagePhysicalMemoryLimit { get; }public object Add(string key, object value, CacheDependency dependencies, DateTime absoluteExpiration, TimeSpan slidingExpiration, CacheItemPriority priority, CacheItemRemovedCallback onRemoveCallback);public object Get(string key);public IDictionaryEnumerator GetEnumerator();public void Insert(string key, object value);public void Insert(string key, object value, CacheDependency dependencies);public void Insert(string key, object value, CacheDependency dependencies, DateTime absoluteExpiration, TimeSpan slidingExpiration, CacheItemPriority priority, CacheItemRemovedCallback onRemoveCallback);public object Remove(string key);}
}
可以看到里面有Add,Get,Insert之类的东西,这些用法网上也有很清楚的讲述,我也不赘述,也说不清楚,哈哈。
下面,结合上面那张示意图,来说明一下我要讲的缓存设计,个人感觉还是比较好的。
<key,value>的形式,就是一个value对应一个key,通过key可以设置value的值,也可以获取value的值。在这里我们把 每个用户登录时生成的一个唯一的 id 做为 cache的key,然后把希望放到缓存中的数据作为value,进行缓存数据的处理。但是,我们放到value中的值,可能是有不同用途不同种类的一些值,比如,登录用户的基本信息,该系统存储的菜单数据,这两个就是用途完全不相干的两类数据,怎么存储呢?再另外使用一个key值不同的cache,这应该也是可以的。但是,我们这里讲的方法只使用一个Cache。
具体做法呢,就是把这个value定义为一个 Dictionary<key,value>类型的值,这样在value里面,我们就可以通过设置不同的key值,来存储不同用途的缓存数据了。
-
第一步
首先,先定义一个存储value数据的类,代码如下:
UserCache.cs
using System.Collections.Generic;namespace Common
{public class UserCache{private readonly Dictionary<string, object> cacheDictionary = new Dictionary<string, object>();private readonly object lockObj = new object();/// <summary>/// 索引器/// </summary>/// <param name="key">key</param>/// <returns>缓存对象</returns>public object this[string key]{get{lock (lockObj){return cacheDictionary.ContainsKey(key) ? cacheDictionary[key] : null;}}set{lock(lockObj){if (cacheDictionary.ContainsKey(key)){cacheDictionary[key] = value;}else{cacheDictionary.Add(key, value);}}}}public void Remove(string key){lock (lockObj){if(cacheDictionary.ContainsKey(key)){cacheDictionary.Remove(key);}}}public void Clear(){lock(lockObj){cacheDictionary.Clear();}}}
}
上面的代码,用到了一个索引器,这使得我们可以像数组那样用 XXX[index]这样的方法访问和设置数据,从代码中我们可以看到,这个类最终都实现对 cacheDictionary 这个字典的操作,因为我们的数据都存储在这个字典中。不管你想存储什么数据只需要定义一个key值,然后存储到字典中即可。
-
第二步
定义好UserCache.cs后,我们再来写关于缓存操作的类:
先定义缓存操作类,然后书写关于缓存操作的代码:
WebCache.cs(部分)
using System;
using System.Web;
using System.Web.Caching;
using Common;namespace Console
{/// <summary>/// 缓存操作类/// </summary>public class WebCache{#region 私有变量private const string UserIdentifyKey = "CacheUserIdentifyKey";#endregion#region 私有方法private static string GetUserIdentify(){if (HttpContext.Current.Session[UserIdentifyKey] != null)return HttpContext.Current.Session[UserIdentifyKey].ToString();var identify = Guid.NewGuid().ToString();HttpContext.Current.Session[UserIdentifyKey] = identify;return identify;}private static UserCache GetUserCache(){var identify = GetUserIdentify();if (HttpContext.Current.Cache.Get(identify) == null){HttpContext.Current.Cache.Insert(identify, new UserCache(), null, Cache.NoAbsoluteExpiration,new TimeSpan(0, 20, 0), CacheItemPriority.High, CacheRemovedCallback);}return HttpContext.Current.Cache.Get(identify) as UserCache;}/// <summary>/// 缓存被移除时触发/// </summary>/// <param name="key">被移除的缓存的key</param>/// <param name="value">被移除的缓存的值</param>/// <param name="reason">移除原因</param>private static void CacheRemovedCallback(string key, object value, CacheItemRemovedReason reason){// 缓存被移除时执行的操作// 如果是手动移除,则不处理//if (reason == CacheItemRemovedReason.Removed)// return;// 此处访问页面会报错,暂时注释掉// ShowNotification(MessageType.Warning, "警告", "由于您太久没操作页面已过期,请重新登录!", true);}#endregion}
}
首先看上面的代码:
上面三段代码中,核心的代码是第二段,需要注意的是,都是静态方法:
GetUserCache() 方法
当然,我们还是从第一段代码开始说起,
GetUserIdentify()
private static string GetUserIdentify(){if (HttpContext.Current.Session[UserIdentifyKey] != null)return HttpContext.Current.Session[UserIdentifyKey].ToString();var identify = Guid.NewGuid().ToString();HttpContext.Current.Session[UserIdentifyKey] = identify;return identify;}
在一个用户登录之初,我们首先给这个用户生成一个唯一的用户 id ,然后把这个id保存到 Session中 (Session也是<key,value>形式的)。在第二段代码中,通过 GetUserIdentify()方法获取用户的唯一 id,然后把这个唯一 id作为 Cache的key值。
然后,我们来看第二段代码:
GetUserCache():
private static UserCache GetUserCache(){var identify = GetUserIdentify();if (HttpContext.Current.Cache.Get(identify) == null){HttpContext.Current.Cache.Insert(identify, new UserCache(), null, Cache.NoAbsoluteExpiration,new TimeSpan(0, 20, 0), CacheItemPriority.High, CacheRemovedCallback);}return HttpContext.Current.Cache.Get(identify) as UserCache;}
这段代码,首先判断Cache中是否有值(是否存在这个key的Cache),若不存在,则创建一个(代码中的 new UserCache())。.net framework中Cache操作使用 HttpContext.Current.Cache,Insert后有若干个参数,意思分别是:
identify:key值;
new UserCache():value值;
第三个参数是:缓存依赖项 CacheDependency ,这里是 null;
Cache.NoAbsoluteExpiration:绝对过期时间 ,这里设置为无绝对过期时间;
new TimeSpan(0, 20, 0):这是滑动过期时间,此处设置为 20 minite;
CacheItemPriority.High:缓存优先级,此处为 high;
CacheRemovedCallback: 缓存移除时的回调函数,这个回调函数的参数是固定写法,必须按照规定写,三个参数以及参数类型 不可缺少也不可写错,否则会报错;(具体可见上面的第三段代码)
上面说到,若不存在,则创建一个 ,若存在,那么就直接返回即可。
接下来,在WebCache.cs中定义一些公共方法,用来供外界的方法调用,以实现对缓存的操作,代码如下:
WebCache.cs(全):
using System;
using System.Web;
using System.Web.Caching;
using Common;namespace Console
{/// <summary>/// 缓存操作类/// </summary>public class WebCache{#region 私有变量private const string UserIdentifyKey = "CacheUserIdentifyKey";#endregion#region 公共方法/// <summary>/// 获取缓存/// </summary>/// <param name="key">键</param>/// <returns></returns>public static object GetCache(string key){return GetUserCache()[key];}/// <summary>/// 设置缓存/// </summary>/// <param name="key">键</param>/// <param name="value">值</param>/// <returns></returns>public static bool SetCache(string key, object value){try{var userCache = GetUserCache();userCache[key] = value;return true;}catch{return false;}}/// <summary>/// 清空缓存/// </summary>/// <returns></returns>public static bool ClearCache(){try{// 只清除缓存内容// GetUserCache().Clear();// 直接从Cache里移除var identify = GetUserIdentify();HttpContext.Current.Cache.Remove(identify);return true;}catch{return false;}}/// <summary>/// 移除缓存/// </summary>/// <param name="key">键</param>/// <returns></returns>public static bool RemoveCache(string key){try{GetUserCache().Remove(key);return true;}catch{return false;}}#endregion#region 私有方法private static string GetUserIdentify(){if (HttpContext.Current.Session[UserIdentifyKey] != null)return HttpContext.Current.Session[UserIdentifyKey].ToString();var identify = Guid.NewGuid().ToString();HttpContext.Current.Session[UserIdentifyKey] = identify;return identify;}private static UserCache GetUserCache(){var identify = GetUserIdentify();if (HttpContext.Current.Cache.Get(identify) == null){HttpContext.Current.Cache.Insert(identify, new UserCache(), null, Cache.NoAbsoluteExpiration,new TimeSpan(0, 20, 0), CacheItemPriority.High, CacheRemovedCallback);}return HttpContext.Current.Cache.Get(identify) as UserCache; // as是一种强制类型转化的方式}/// <summary>/// 缓存被移除时触发/// </summary>/// <param name="key">被移除的缓存的key</param>/// <param name="value">被移除的缓存的值</param>/// <param name="reason">移除原因</param>private static void CacheRemovedCallback(string key, object value, CacheItemRemovedReason reason){// 缓存被移除时执行的操作// 如果是手动移除,则不处理//if (reason == CacheItemRemovedReason.Removed)// return;// 此处访问页面会报错,暂时注释掉// ShowNotification(MessageType.Warning, "警告", "由于您太久没操作页面已过期,请重新登录!", true);}#endregion}
}
依次定义了GetCache(),SetCache(),RemoveCache(),ClearCache()四个方法,供外界调用,来实现对缓存的操作。
到这里,基本上关于这个Cache的实现就已经讲完了,下面,给出一段代码,做一个使用的示例。
private const string LoginUserKey = "CacheKey-LoginUserCacheKey";
/// <summary>/// 获取或设置当前登录用户/// </summary>public static User LoginUser{get { return WebCache.GetCache(LoginUserKey) as User; }set { WebCache.SetCache(LoginUserKey, value); }}
SetCache():
WebCache.SetCache(key, value);
RemoveCache():
RemoveCache(key); //移除字典中某个缓存值
ClearCache();
ClearCache(); //清空缓存的字典
关于这个缓存设计,就记录到这里了,关于.net core下的实现,因为.net core下并没有System.Web这个类,所以它的Cache实现方式,与.net 下的实现方式有些区别,这个,我会另起一篇博客去记录。
说明:本片博客并没有完整的demo,所有的代码都已贴出。
ES6学习笔记
ES6的标准发布很久了,ES7和ES8已经出来了,直到现在才开始学习,已经有点晚了,希望可以赶得上吧。
(以下内容根据阮一峰老师的ES6标准入门进行整理,若要深入学习,请点击:http://es6.ruanyifeng.com/)
-
1.简介
ES是ECMAScript的简称,ECMA是国际化标准化组织的简称,所以ECMAScript其实就是JavaScript的国际标准。写Js代码时,尽量遵从标准。
-
2.let 和 const命令
(1)let
let用来声明变量。它的用法类似于 var ,但是所声明的变量,只在 let 命令所在的 代码块 (一个大括号包裹的区域,称为代码块{ 代码块内 })内有效;如:
var a = [];
for(var i = 0;i < 10 ;i++){a[i] = function(){console.log(i);}
}
a[6]();
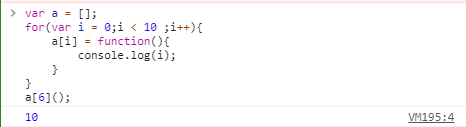
(该代码为在谷歌浏览器控制台编写)
上面代码中,变量 i 是 var 命令声明的,在全局范围内都有效,所以全局只有一个变量 i 。每一次循环,变量 i 的值都会发生改变,而循环内被赋给数组 a的函数内部的 console.log(i) ,里面的 i 指向的就是全局的 i 。也就是说,所有数组 a 的成员里面的 i ,指向的都是同一个 i ,导致运行时输出的是最后一轮的 i 的值,也就是 10。
使用let时:
var a = [];
for(let i = 0;i < 10 ;i++){a[i] = function(){console.log(i);}
}
a[6]();
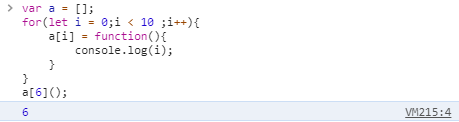
上面代码中,变量 i 是 let 声明的,当前的 i 只在本轮循环有效,所以每一次循环的 i 其实都是一个新的变量,所以最后输出的是 6 。你可能会问,如果每一轮循环的变量 i 都是重新声明的,那它怎么知道上一轮循环的值,从而计算出本轮循环的值?这是因为 JavaScript 引擎内部会记住上一轮循环的值,初始化本轮的变量 i 时,就在上一轮循环的基础上进行计算。
let与var的区别:
(1)let 声明的变量必须严格遵守 先定义 后使用 的的原则,如果在定义一个变量之前,就已经使用它了,则会报错;
var可以在声明一个变量之前使用一个变量,但这个变量的值会是 undefined; (这被称为 var 的 变量提升 现象 ,这一现象是非常奇怪的 ,let的出现就是为了改变这一现象);
console.log(a); var a = 10;
 (一个在线运行的代码工具)
(一个在线运行的代码工具)
console.log(b); let b = 10;
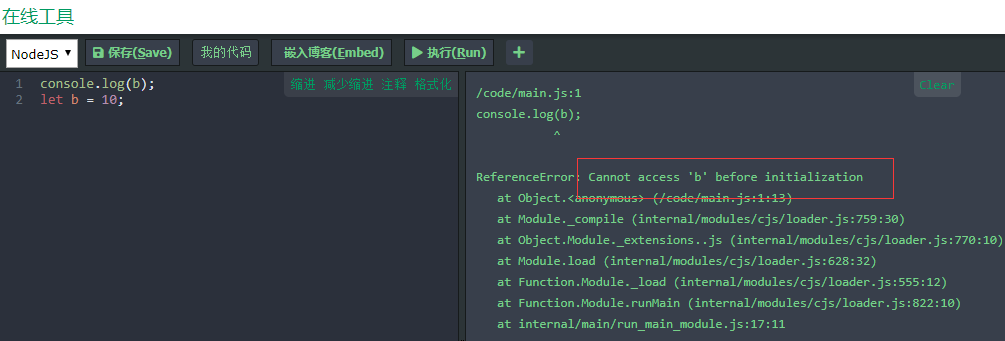
(2)暂时性死区:
前面说了,let只在其所在的 代码块 内有效,所以一旦一个代码块声明了一个let变量,那这个变量就和这个代码块绑定在一起了,在代码块声明这个变量之前使用这个变量就会报错;
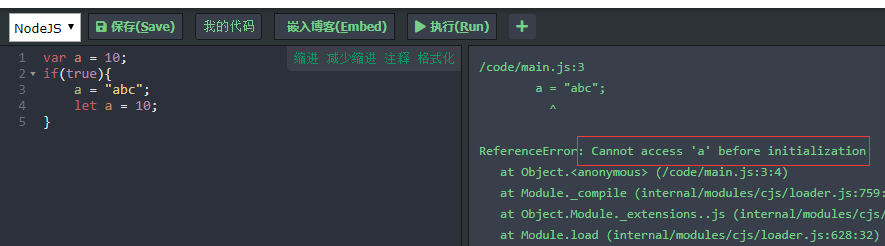
(3)不允许重复声明
function func() {let a = 10;var a = 1;
} 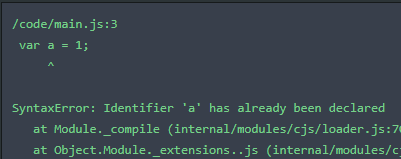
function func() {var a = 10;var a = 1;
}

(不报错)
ES6的 块级作用域:
let为ES6新增了块级作用域:每一个块级里的let变量互不干扰:
function func(){let a = 10;if(true){let a = 5;console.log(a);} console.log(a);
} 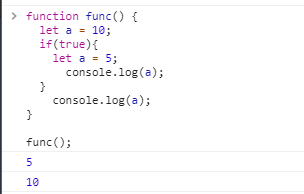
(在两个不同块里的内容互不干扰)
ES6中 块级作用域中可以声明方法:
如下代码,在ES5中是非法的,但在ES6中是合法的,只不过,块级作用域中 声明的方法 只能在块级作用域中调用。
// 情况一
if (true) {function f() {}
}// 情况二
try {function f() {}
} catch(e) {// ...
} 考虑到环境导致的行为差异太大,应该避免 在块级作用域内声明函数。如果确实需要,也应该写成函数表达式,而不是函数声明语句。
// 块级作用域内部的函数声明语句,建议不要使用
{let a = 'secret';function f() {return a;}
}// 块级作用域内部,优先使用函数表达式
{let a = 'secret';let f = function () {return a;};
}
注意:ES6的块级作用域必须有 大括号 ,否则JavaScript引擎就会认为没有 块级作用域。
(2)const
1>const声明一个只读变量,一旦声明,常量的值就不能改变;
2>const声明的变量不得改变值,这意味着,const一旦声明变量,就必须立即初始化,不能留到以后赋值;
3>const 的作用域和let 一样,只在其所在的块级作用域有效;
4>const 只能在声明后才能使用;
5>const 变量也不能重复声明;
const 的本质:
const保证的并不是变量的值不能改动,而是变量指向的那个内存地址所保存的数据不得改动。对于一些简单类型的数据(数值、字符串、布尔值),就相当于是保存的常量了,但是,对于复合类型的数据,如对象,数组,变量指向的内存地址,保存的只是一个指向实际数据的指针,const只能保证这个指针是固定的(即总是指向另一个固定的地址),至于它指向的数据结构是不是可变的,就完全不能控制了。因此,将一个对象声明为常量必须非常小心。
(3)ES6声明变量的6中方法
ES5 > 两种方法:var 和 funcion;
ES6 > 六种方法: (1) var (2) function (3)let (4) const (5) import (6) class;
3.变量的解构赋值
(1)数组的结构赋值
ES5赋值方法:
let a = 5; let b = 6; let c = 7;
ES6赋值方法:
let [a,b,c] = [5,6,7];
现象:
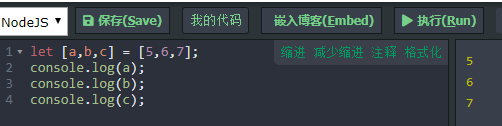
说明:ES6 允许按照一定模式,从数组和对象中提取值,对变量进行赋值,这被称为解构(Destructuring)。本质上,这种写法属于“模式匹配”,只要等号两边的模式相同,左边的变量就会被赋予对应的值。
下面是一些例子:
let [foo, [[bar], baz]] = [1, [[2], 3]]; foo // 1 bar // 2 baz // 3let [ , , third] = ["foo", "bar", "baz"]; third // "baz"let [x, , y] = [1, 2, 3]; x // 1 y // 3let [head, ...tail] = [1, 2, 3, 4]; head // 1 tail // [2, 3, 4]let [x, y, ...z] = ['a']; x // "a" y // undefined z // []
解析不成功,变量的值就是undefined.
注意:上述方式定义变量,必须要求等式右边是数组(或可遍历的结构),以下写法出错:
// 报错
let [foo] = 1;
let [foo] = false;
let [foo] = NaN;
let [foo] = undefined;
let [foo] = null;
let [foo] = {};
默认值:
解构赋值允许指定默认值,如下:
let [foo = true] = []; foo // truelet [x, y = 'b'] = ['a']; // x='a', y='b' let [x, y = 'b'] = ['a', undefined]; // x='a', y='b'
当所要赋的值是 undefined 时,则会给变量赋默认值。
(2)对象的解构赋值
对象也可以进行解构赋值,具体方法为:
let { foo, bar } = { foo: 'aaa', bar: 'bbb' };
foo // "aaa"
bar // "bbb"
对象与数组结构赋值的区别:
数组的元素是按次序排列的,变量的取值由它的位置决定;而对象的属性没有次序,变量必须与属性同名,才能取到正确的值;
对象的结构赋值也可以指定默认值,默认值生效的条件是,对象的属性值严格等于undefined.
注意:
(1)如果要将一个已经声明的变量用于解构赋值,必须非常小心;下面写法出错:
let x ;
{x} = {x:1}; JavaScript引擎会把{x}解析成一个代码块,从而发生语法错误,只有不把{x}放在行首,才能解决这个问题;以下写法正确:
let x;
({x} = {x:1});
(2)解构赋值允许等号左边的模式之中,不放置任何变量名。因此,可以写出非常古怪的赋值表达式;
({} = [true, false]);
({} = 'abc');
({} = []); 上面的表达式虽然毫无意义,但是语法是合法的,可以执行。
(3)字符串解构赋值
字符串也可以解构赋值。这是因为此时,字符串被转换成了一个类似数组的对象;
const [a, b, c, d, e] = 'hello'; a // "h" b // "e" c // "l" d // "l" e // "o"
(4)函数参数的解构赋值
函数的参数也可以使用解构赋值。如下:
function add([x, y]){return x + y;
}add([1, 2]); // 3 上面代码中,函数add的参数表面上是一个数组,但在传入参数的那一刻,数组参数就被解构成变量x和y。对于函数内部的代码来说,它们能感受到的参数就是x和y。
(5)解构过程中的圆括号的问题
只要有可能导致解构的歧义,就不得使用圆括号。
不能使用的情况:
1> 变量声明语句
// 全部报错
let [(a)] = [1];let {x: (c)} = {};
let ({x: c}) = {};
let {(x: c)} = {};
let {(x): c} = {};let { o: ({ p: p }) } = { o: { p: 2 } }; 上面 6 个语句都会报错,因为它们都是变量声明语句,模式不能使用圆括号。
2>函数参数
函数参数也属于变量声明,因此不能带有圆括号。
// 报错
function f([(z)]) { return z; }
// 报错
function f([z,(x)]) { return x; }
3>赋值语句的模式
// 全部报错
({ p: a }) = { p: 42 };
([a]) = [5];
可以使用的情况:
可以使用圆括号的情况只有一种:赋值语句的非模式部分,可以使用圆括号
[(b)] = [3]; // 正确
({ p: (d) } = {}); // 正确
[(parseInt.prop)] = [3]; // 正确
(6)解构赋值的作用
1>交换变量的值:
let x = 5; let y = 10; [x,y] = [y,x]
2>从函数返回多个值
函数只能返回一个值,如果要返回多个值,只能将它们放在数组或对象里返回。有了解构赋值,取出这些值就非常方便。
// 返回一个数组function example() {return [1, 2, 3];
}
let [a, b, c] = example();// 返回一个对象function example() {return {foo: 1,bar: 2};
}
let { foo, bar } = example();
3>函数参数的定义
解构赋值可以方便地将一组参数与变量名对应起来。
// 参数是一组有次序的值
function f([x, y, z]) { ... }
f([1, 2, 3]);// 参数是一组无次序的值
function f({x, y, z}) { ... }
f({z: 3, y: 2, x: 1});
4>提取Json数据
解构赋值对提取 JSON 对象中的数据,尤其有用。
let jsonData = {id: 42,status: "OK",data: [867, 5309]
};let { id, status, data: number } = jsonData;console.log(id, status, number);
// 42, "OK", [867, 5309]
5>函数参数的默认值
jQuery.ajax = function (url, {async = true,beforeSend = function () {},cache = true,complete = function () {},crossDomain = false,global = true,// ... more config
} = {}) {// ... do stuff
}; 指定参数的默认值,就避免了在函数体内部再写var foo = config.foo || 'default foo';这样的语句。
6>遍历Map解构
const map = new Map();
map.set('first', 'hello');
map.set('second', 'world');for (let [key, value] of map) {console.log(key + " is " + value);
}
// first is hello
// second is world 4.字符串的新增方法
(1)String.fromCodePoint()
ES5 提供String.fromCharCode()方法,用于从 Unicode 码点返回对应字符,但是这个方法不能识别码点大于0xFFFF的字符。
ES6 提供了String.fromCodePoint()方法,可以识别大于0xFFFF的字符,弥补了String.fromCharCode()方法的不足。
(2)String.Raw()
ES6 还为原生的 String 对象,提供了一个raw()方法。该方法返回一个斜杠都被转义(即斜杠前面再加一个斜杠)的字符串,往往用于模板字符串的处理方法。
(3)实例方法:includes(),startWith(),endWith()
传统方法,JavaScript只有一种方法 indexOf 可以用来确定一个字符串是否包含在另一个字符串中,ES6新增了3个方法:
includes():返回布尔值,表示是否找到了 参数字符串;
startWith(): 返回布尔值,表示参数字符串是否在 原字符串的头部;
endWith(): 返回布尔值,表示参数字符串是否在 原字符串的尾部;
这三个方法都支持 第二个参数,表示开始搜索的位置:
let s = 'Hello world!';s.startsWith('world', 6) // true
s.endsWith('Hello', 5) // true
s.includes('Hello', 6) // false 上面代码表示,使用第二个参数n时,endsWith的行为与其他两个方法有所不同。它针对前n个字符,而其他两个方法针对从第n个位置直到字符串结束。
(4)实例方法repeat()
repeat()方法返回一个新字符串,表示将原字符串重复n次;
'x'.repeat(3) // "xxx" 'hello'.repeat(2) // "hellohello" 'na'.repeat(0) // "
(5)实例方法 padStart(),padEnd()
ES2017 引入了字符串补全长度的功能。如果某个字符串不够指定长度,会在头部或尾部补全。
padStart用于头部补全,endStart用于尾部补全。
'x'.padStart(5, 'ab') // 'ababx' 'x'.padStart(4, 'ab') // 'abax''x'.padEnd(5, 'ab') // 'xabab' 'x'.padEnd(4, 'ab') // 'xaba'
1>如果原字符串的长度,等于或大于最大长度,则字符串补全不生效,返回原字符串;
2>如果用来补全的字符串与原字符串,两者的长度之和超过了最大长度,则会截去超出位数的补全字符串;
3>如果省略第二个参数,默认使用空格补全长度;
'x'.padStart(4) // ' x' 'x'.padEnd(4) // 'x '
(6)实例方法:trimStart(),trimEnd()
它们的行为与trim()一致,trimStart()消除字符串头部的空格,trimEnd()消除尾部的空格。它们返回的都是新字符串,不会修改原始字符串。
(7)实例方法:matchAll()
matchAll()方法返回一个正则表达式在当前字符串的所有匹配;
探秘 flex 上下文中神奇的自动 margin
探秘 flex 上下文中神奇的自动 margin
为了引出本文的主题,先看看这个问题,最快水平垂直居中一个元素的方法是什么?
水平垂直居中也算是 CSS 领域最为常见的一个问题了,不同场景下的方法也各不相同,各有优劣。嗯,下面这种应该算是最便捷的了:
| 1 2 3 4 5 6 7 8 9 10 | <div class= "g-container" > <div class= "g-box" ></div> </div> .g-container { display : flex; } .g-box { margin : auto ; } |
上面的
display: flex替换成display: inline-flex | grid | inline-grid也是可以的。
CodePen Demo -- 使用 margin auto 水平垂直居中元素
如何让 margin: auto 在垂直方向上居中元素
嗯。这里其实就涉及了一个问题,如何让 margin: auto 在垂直方向上生效?
换句话说,传统的 display: block BFC(块格式化上下文)下,为什么 margin: auto 在水平方向可以居中元素在垂直方向却不行?
通常我们会使用这段代码:
| 1 2 3 4 5 | div { width : 200px ; height : 200px ; margin : 0 auto ; } |
让元素相对父元素水平居中。但是如果我们想让元素相对父元素垂直居中的话,使用 margin: auto 0是不生效的。
BFC 下 margin: auto 垂直方向无法居中元素的原因
查看 CSS 文档,原因如下,在 BFC 下:
If both margin-left and margin-right are auto, their used values are equal, causing horizontal centring.
—CSS2 Visual formatting model details: 10.3.3
If margin-top, or margin-bottom are auto, their used value is 0.
—CSS2 Visual formatting model details: 10.6.3
简单翻译下,在块格式化上下文中,如果 margin-left 和 margin-right 都是 auto,则它们的表达值相等,从而导致元素的水平居中。( 这里的计算值为元素剩余可用剩余空间的一半)
而如果 margin-top 和 margin-bottom 都是 auto,则他们的值都为 0,当然也就无法造成垂直方向上的居中。
使用 FFC/GFC 使 margin: auto 在垂直方向上居中元素
OK,这里要使单个元素使用 margin: auto 在垂直方向上能够居中元素,需要让该元素处于 FFC(flex formatting context),或者 GFC(grid formatting context) 上下文中,也就是这些取值中:
| 1 2 3 4 5 6 | { display : flex; display : inline-flex; display : grid; display : inline-grid; } |
FFC 下 margin: auto 垂直方向可以居中元素的原因
本文暂且不谈 grid 布局,我们业务中需求中更多的可能是使用 flex 布局,下文将着重围绕 flex 上下文中自动 margin 的一些表现。
嗯,也有很多前端被戏称为 flex 工程师,什么布局都 flex 一把梭。
查看 CSS 文档,原因如下,在 dispaly: flex 下:
- Prior to alignment via justify-content and align-self, any positive free space is distributed to auto margins in that dimension.
CSS Flexible Box Layout Module Level 1 -- 8.1. Aligning with auto margins
简单翻译一下,大意是在 flex 格式化上下文中,设置了 margin: auto 的元素,在通过 justify-content和 align-self 进行对齐之前,任何正处于空闲的空间都会分配到该方向的自动 margin 中去
这里,很重要的一点是,margin auto 的生效不仅是水平方向,垂直方向也会自动去分配这个剩余空间。
使用自动 margin 实现 flex 布局下的 space-between | space-around
了解了上面最核心的这一句 :
- 在通过
justify-content和align-self进行对齐之前,任何正处于空闲的空间都会分配到该维度中的自动 margin 中去
之后,我们就可以在 flex 布局下使用自动 margin 模拟实现 flex 布局下的 space-between 以及 space-around 了。
自动 margin 实现 space-around
对于这样一个 flex 布局:
| 1 2 3 4 5 6 7 | < ul class="g-flex"> < li >liA</ li > < li >liB</ li > < li >liC</ li > < li >liD</ li > < li >liE</ li > </ ul > |
如果它的 CSS 代码是:
| 1 2 3 4 5 6 | .g-flex { display : flex; justify- content : space-around; } li { ... } |
效果如下:

那么下面的 CSS 代码与上面的效果是完全等同的:
| 1 2 3 4 5 6 7 8 | .g-flex { display : flex; // justify- content : space-around; } li { margin : auto ; } |
CodePen Demo -- margin auto 实现 flex 下的 space-around
自动 margin 实现 space-between
同理,使用自动 margin,也很容易实现 flex 下的 space-between,下面两份 CSS 代码的效果的一样的:
| 1 2 3 4 5 6 | .g-flex { display : flex; justify- content : space-between; } li {...} |
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | .g-flex { display : flex; // justify- content : space-between; } li { margin : auto ; } li:first-child { margin-left : 0 ; } li:last-child { margin-right : 0 ; } |
CodePen Demo -- margin auto 实现 flex 下的 space-between
当然,值得注意的是,很重要的一点:
Note: If free space is distributed to auto margins, the alignment properties will have no effect in that dimension because the margins will have stolen all the free space left over after flexing.
CSS Flexible Box Layout Module Level 1 -- 8.1. Aligning with auto margins
意思是,如果任意方向上的可用空间分配给了该方向的自动 margin ,则对齐属性(justify-content/align-self)在该维度中不起作用,因为 margin 将在排布后窃取该纬度方向剩余的所有可用空间。
也就是使用了自动 margin 的 flex 子项目,它们父元素设置的 justify-content 已经它们本身的 align-self 将不再生效,也就是这里存在一个优先级的关系。
使用自动 margin 实现 flex 下的 align-self: flex-start | flex-end | center
自动 margin 能实现水平方向的控制,也能实现垂直方向的控制,原理是一样的。
用 margin: auto 模拟 flex 下的 align-self: flex-start | flex-end | center,可以看看下面几个 Demo:
-
CodePen Demo -- margin auto 实现 flex 下的 align-self: center
-
CodePen Demo -- margin auto 实现 flex 下的 align-self: flex-end
不同方向上的自动 margin
OK,看完上面的一大段铺垫之后,大概已经初步了解了 FFC 下,自动 margin 的神奇。
无论是多个方向的自动 margin,抑或是单方向的自动 margin,都是非常有用的。
再来看几个有意思的例子:
使用 margin-left: auto 实现不规则两端对齐布局
假设我们需要有如下布局:

DOM 结构如下:
| 1 2 3 4 5 6 7 | < ul class="g-nav"> < li >导航A</ li > < li >导航B</ li > < li >导航C</ li > < li >导航D</ li > < li class="g-login">登陆</ li > </ ul > |
对最后一个元素使用 margin-left: auto,可以很容易实现这个布局:
| 1 2 3 4 5 6 7 | .g-nav { display : flex; } .g-login { margin-left : auto ; } |
此时, auto 的计算值就是水平方向上容器排列所有 li 之后的剩余空间。
当然,不一定是要运用在第一个或者最后一个元素之上,例如这样的布局,也是完全一样的实现:

| 1 2 3 4 5 6 7 8 | < ul class="g-nav"> < li >导航A</ li > < li >导航B</ li > < li >导航C</ li > < li >导航D</ li > < li class="g-login">登陆</ li > < li >注册</ li > </ ul > |
| 1 2 3 4 5 6 7 | .g-nav { display : flex; } .g-login { margin-left : auto ; } |

Codepen Demo -- nav list by margin left auto
垂直方向上的多行居中
OK,又或者,我们经常会有这样的需求,一大段复杂的布局中的某一块,高度或者宽度不固定,需要相对于它所在的剩余空间居中:

这里有 5 行文案,我们需要其中的第三、第四行相对于剩余空间进行垂直居中。
这里如果使用 flex 布局,简单的 align-self 或者 align-items 好像都没法快速解决问题。
而使用自动 margin,我们只需要在需要垂直居中的第一个元素上进行 margin-top: auto,最后一个元素上进行 margin-bottom: auto 即可,看看代码示意:
| 1 2 3 4 5 6 7 | < div class="g-container"> < p >这是第一行文案</ p > < p >这是第二行文案</ p > < p class="s-thirf">1、剩余多行文案需要垂直居中剩余空间</ p > < p class="s-forth">2、剩余多行文案需要垂直居中剩余空间</ p > < p >这是最后一行文案</ p > </ div > |
| 1 2 3 4 5 6 7 8 9 10 11 12 13 | .g-container { display : flex; flex-wrap: wrap; flex- direction : column; } .s-thirf { margin-top : auto ; } .s-forth { margin-bottom : auto ; } |
当然,这里将任意需要垂直居中剩余空间的元素用一个 div 包裹起来,对该 div 进行
margin: auto 0也是可以的。
嗯,非常的好用且方便:CodePen Demo -- 自动margin快速垂直居中任意段落
使用 margin-top: auto 实现粘性 footer 布局
OK,最后再来看这样一个例子。
要求:页面存在一个 footer 页脚部分,如果整个页面的内容高度小于视窗的高度,则 footer 固定在视窗底部,如果整个页面的内容高度大于视窗的高度,则 footer 正常流排布(也就是需要滚动到底部才能看到 footer),算是粘性布局的一种。
看看效果:

嗯,这个需求如果能够使用 flex 的话,使用 justify-content: space-between 可以很好的解决,同理使用 margin-top: auto 也非常容易完成:
| 1 2 3 4 5 6 | < div class="g-container"> < div class="g-real-box"> ... </ div > < div class="g-footer"></ div > </ div > |
| 1 2 3 4 5 6 7 8 9 10 11 12 | .g-container { height : 100 vh; display : flex; flex- direction : column; } .g-footer { margin-top : auto ; flex-shrink: 0 ; height : 30px ; background : deeppink; } |
Codepen Demo -- sticky footer by flex margin auto
上面的例子旨在介绍更多自动 margin 的使用场景。当然,这里不使用 flex 布局也是可以实现的,下面再给出一种不借助 flex 布局的实现方式:
CodePen Demo -- sticky footer by margin/paddig
值得注意的点
自动 margin 还是很实用的,可以使用的场景也很多,有一些上面提到的点还需要再强调下:
-
块格式化上下文中
margin-top和margin-bottom的值如果是 auto,则他们的值都为 0 -
flex 格式化上下文中,在通过
justify-content和align-self进行对齐之前,任何正处于空闲的空间都会分配到该方向的自动 margin 中去 -
单个方向上的自动 margin 也非常有用,它的计算值为该方向上的剩余空间
-
使用了自动 margin 的 flex 子项目,它们父元素设置的
justify-content以及它们本身的align-self将不再生效