内容:V8引擎、JS内存管理、V8引擎如何回收垃圾、如何查看V8内存使用情况、内存优化实例
目录
一、V8引擎是什么?
二、内存
2.1、内存生命周期:(这个不同的程序语言基本一样)
2.2、JavaScript的内存管理
2.3、为什么要关注内存?
2.4、V8引擎的内存分配
三、垃圾回收机制
3.1、垃圾回收算法
3.2、详解垃圾回收
一、V8引擎是什么?
V8引擎是驱动 Google Chrome 的 JavaScript 引擎的名称。是 Chrome浏览器和edge浏览器获取我们的 JavaScript 代码并执行代码的东西。
V8 提供了 JavaScript 执行的运行时环境。 DOM 和其他 Web 平台 API 由浏览器提供。
JavaScript 引擎独立于它所在的浏览器。 这个关键特性促成了 Node.js 的兴起。 早在 2009 年,V8 就被选为驱动 Node.js 的引擎,随着 Node.js 的流行,V8 成为现在为大量使用 JavaScript 编写的服务器端代码提供驱动的引擎。
Node.js 底层代码主要是为C++,这个跟后续内容有关。Node.js生态系统非常庞大,这要归功于 V8,它还支持桌面应用程序,例如 Electron 等项目。
其它JS引擎:
Firefox 使用 SpiderMonkey
Safari 使用 JavaScriptCore(也称为 Nitro)
Edge 最初基于 Chakra,但现在已经使用 Chromium 和 V8 引擎重建。
等等其它引擎
所有引擎都采用ECMA ES-262 标准,即 ECMAScript(JavaScript 使用的标准)。
二、内存
2.1、内存生命周期:(这个不同的程序语言基本一样)
1、分配你所需要的内存
2、使用分配到的内存(读、写)
3、不需要时将其释放归还
2.2、JavaScript的内存管理
与其他需要手动管理内存的语言不同,在JavaScript中,当我们创建变量(对象,字符串等)的时候,系统会自动给对象分配对应的内存。
系统发现这些变量不再被使用的时候,会自动释放(垃圾回收)这些变量的内存,开发者不用过多的关心内存问题。
在JavaScript中,数据类型分为两类,简单类型和引用类型,对于简单类型,内存是保存在栈(stack)空间中,复杂数据类型,内存是保存在堆(heap)空间中。
基本类型:这些类型在内存中分别占有固定大小的空间,他们的值保存在栈空间,我们通过按值来访问的
引用类型:引用类型,值大小不固定,栈内存中存放地址指向堆内存中的对象。是按引用访问的。
而对于栈的内存空间,只保存简单数据类型的内存,由操作系统自动分配和自动释放。而堆空间中的内存,由于大小不固定,系统无法无法进行自动释放,这个时候就需要JS引擎来手动的释放这些内存。
2.3、为什么要关注内存?
1、防止页面占用内存过大, 引起客户端卡顿,甚至无响应。
2、Node使用的也是V8,内存对于后端服务的性能非常重要。因为服务的持久性,后端更容易造成内存溢出。
2.4、V8引擎的内存分配
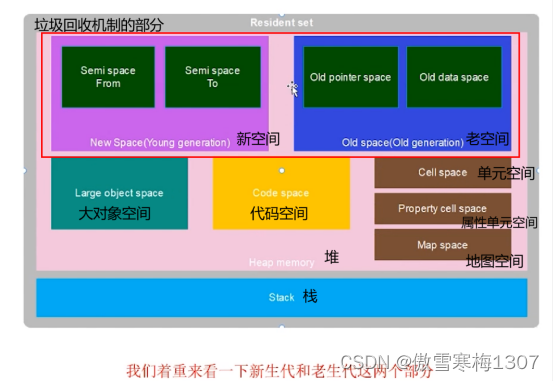
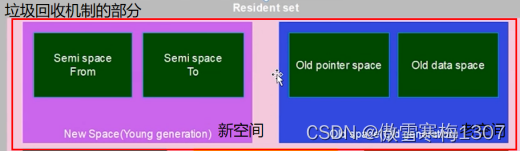
新生代(新空间):分为Semi space From和Semi space To,且两个区域的空间严格对半分。
老生代(老空间):分为Old pointer space和Old data space,是连续的区域,如果一个对象有指针引用或者指向其它对象,大多数会保存在Old pointer space里面;如果一个对象是原始对象,没有指针引用,会保存在Old data space里面,而且所有老生代的对象全部会由新生代晋升而来。
V8引擎的新生代和老生代的内存空间是多大?
这个和操作系统有关。
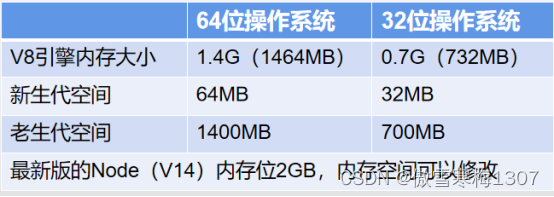
为什么限制在1.4G空间?
1、表层原因:V8最初为浏览器而设计,设计者觉得Js代码只是暂时性的,代码存在时间不持久,同时也不太可能遇到用大量内存的场景
2、深层原因:V8的垃圾回收机制的限制(如果清理大量的内存垃圾是很耗时间,这样回引起JavaScript线程暂停执行的时间,那么性能和应用直线下降)
三、垃圾回收机制
3.1、垃圾回收算法
V8当前垃圾回收机制
2011年,V8应用了增量标记机制。直至2018年,Chrome64和Node.js V10启动并发标记(Concurrent),同时在并发的基础上添加并行(Parallel)技术,使得垃圾回收时间大幅度缩短。
变量的存储路径:
变量 --> 新生代 --> 老生代
新生代简单来说就是copy(复制),使用Scavenge算法(新生代互换);
老生代就是标记整理清除:早期用Mark-Sweep(标记清除),现在用Mark-Compact(标记整理)。
3.2、详解垃圾回收
新生代垃圾回收:
Scavange算法:将新生代堆分为两部分,分别叫from-space和to-space,工作方式也很简单,就是将from-space中存活的活动对象复制到to-space中,并将这些对象的内存有序的排列起来,然后将from-space中的非活动对象的内存进行释放,完成之后,将from space 和to space进行互换,这样可以使得新生代中的这两块区域可以重复利用。
简单描述就是:
标记活动对象和非活动对象
复制 from space 的活动对象到 to space 并对其进行排序
释放 from space 中的非活动对象的内存
将 from space 和 to space 角色互换
垃圾回收器是怎么知道哪些对象是活动对象和非活动对象的呢?
有一个概念叫对象的可达性,表示从初始的根对象(window,global)的指针开始,这个根指针对象被称为根集(root set),从这个根集向下搜索其子节点,被搜索到的子节点说明该节点的引用对象可达,并为其留下标记,然后递归这个搜索的过程,直到所有子节点都被遍历结束,那么没有被标记的对象节点,说明该对象没有被任何地方引用,可以证明这是一个需要被释放内存的对象,可以被垃圾回收器回收。
新生代中的对象什么时候变成老生代的对象呢?
在新生代中,还进一步进行了细分,分为nursery子代和intermediate子代两个区域,一个对象第一次分配内存时会被分配到新生代中的nursery子代,如果进过下一次垃圾回收这个对象还存在新生代中,这时候我们移动到 intermediate 子代,再经过下一次垃圾回收,如果这个对象还在新生代中,副垃圾回收器会将该对象移动到老生代中,这个移动的过程被称为晋升。
老生代垃圾回收(标记整理清除):
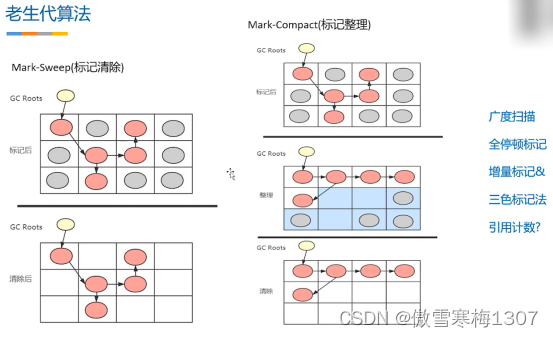
早期用Mark-Sweep(标记清除),现在用Mark-Compact(标记整理)
Mark-Sweep
Mark-Sweep处理时分为两阶段,标记阶段和清理阶段,看起来与Scavenge类似,不同的是,Scavenge算法是复制活动对象,而由于在老生代中活动对象占大多数,所以Mark-Sweep在标记了活动对象和非活动对象之后,直接把非活动对象清除。
标记阶段:对老生代进行第一次扫描,标记活动对象
清理阶段:对老生代进行第二次扫描,清除未被标记的对象,即清理非活动对象
这里存在一个问题,被清除的对象遍布于各内存地址,产生很多内存碎片,所以后面改进 了机制,采用标记整理方法(Mark-Sweep)。
Mark-Compact
由于Mark-Sweep完成之后,老生代的内存中产生了很多内存碎片,若不清理这些内存碎片,如果出现需要分配一个大对象的时候,这时所有的碎片空间都完全无法完成分配,就会提前触发垃圾回收,而这次回收其实不是必要的。
为了解决内存碎片问题,Mark-Compact被提出,它是在是在 Mark-Sweep的基础上演进而来的,相比Mark-Sweep,Mark-Compact添加了活动对象整理阶段,将所有的活动对象往一端移动,移动完成后,直接清理掉边界外的内存(先整理,再清除)。
还没整理完,后续会继续把内容整理好,编辑在此文里。