1. torch模块
torch模块包含了一些pytorch的常用激活函数,如Sigmoid(torch.sigmoid)、ReLu(torch.relu)和Tanh(torch.tanh);同时也包含了pytorch张量的一些计算操作,如矩阵的乘法(torch.mm)、张量元素的选择(torch.select)。注意,该模块中计算的对象大多数是pytorch张量。
例:
a = torch.randn(1,2,3,4,5)
torch.numel(a)

2. torch.Tensor模块
torch.Tensor模块定义了torch中的张量类型,如张量中的数值类型有单精度、双精度浮点和整型等,并且张量有一定的维数和形状。如果张量方法后缀带下划线,则该方法会修改张量本身的数据,反之则会返回新的张量。例如,Tenor.add方法会让当前张量和输入参数张量做加法,返回新的张量,而Tensor。add_方法会改变当前张量的值。
例:
a = torch.tensor(1)
b = torch.tensor(2)
print(torch.Tensor.add(a, b))
print(torch.Tensor.add_(a, b))

3. torch.sparse模块
torch.sparse模块定义了稀疏张量,其中构造的稀疏张量采用的是COO格式(Coordinate),主要方法是用一个长整型定义非零元素的位置,用浮点数张量定义对应非零元素的值。稀疏张量之间可以做元素加减乘除运算和矩阵乘法。
例:
i = [[0, 1, 1],[2, 0, 2]]
v = [3, 4, 5]
torch.sparse_coo_tensor(i, v, (2, 3))

4. torch.cuda模块
torch.cuda模块定义了与CUDA运算相关的一系列函数,包含但不限于检查系统的CUDA是否可用,当前进程对应的GPU序号(在多GPU情况下),清除GPU上的缓存,设置GPU的计算流(Stream),同步GPU上执行的所有核函数(Kernel)等。
例:
torch.cuda.is_available()

5. torch.nn模块
torch.nn是pytorch神经网络模块化的核心。该模块定义了一系列模块,包括卷积层nn.ConvNd(N=1,2,3)和线性层(全连接层)nn.Linear等。当我们构建深度学习模型的时候,可以通过继承nn.Module类并重写forward方法来实现一个新的神经网络。此外,torch.nn也定义了平方损失函数(torch.nn.MSELoss)、交叉熵损失函数(torch.nn.CrossEntropyLoss)等损失函数。可以直接对torch.nn中定义的神经网络参数使用优化器进行训练。
例:
import torch.nn as nn
import torch.nn.functional as Fclass Model(nn.Module):def __init__(self):super(Model, self).__init__()self.conv1 = nn.Conv2d(1, 20, 5)self.conv2 = nn.Conv2d(20, 20, 5)def forward(self, x):x = F.relu(self.conv1(x))return F.relu(self.conv2(x))
6. torch.functional函数模块
torch.nn.functional函数模块定义了一些神经网络相关的函数,包括卷积函数和池化函数等,这些函数也是深度学习模型构建的基础。
例:
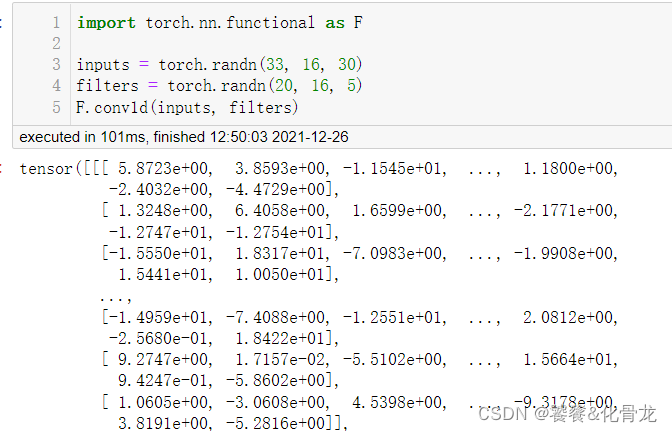
import torch.nn.functional as Finputs = torch.randn(33, 16, 30)
filters = torch.randn(20, 16, 5)
F.conv1d(inputs, filters)
7. torch.nn.init模块
torch.nn.init模块定义了神经网络权重的初始化,包含了很多初始化方法,如均匀初始化torch.nn.init.uniform_和正太分布归一化torch.nn.init.normal_等。
例:
w = torch.empty(3, 5)
nn.init.uniform_(w)

8. torch.optim模块
torch.optim模块定义了一系列的优化器,如torch.optim.SGD(随机梯度下降算法)、torch.optim.AdaGrad(adaGrad算法)、torch.optim.RMSprop(RMSProp算法)和torch.optim.Adam(Adam算法)等。当然,这个模块还包含学习率衰减的算法子模块,即torch.optim.lr_scheduler。该模块还包含了学习率阶梯下降算法torch.optim.lr_scheduler.StepLR和余弦退火算法torch.optim.lr_scheduler.CosineAnnealingLR等学习率衰减算法。
9. torch.autograd模块
torch.autograd模块就是pytoch的自动微分算法模块,包括torch.autograd.backward函数,主要作用是求得损失函数之后进行反向梯度传播,torch.autograd.grad函数用于一个标量张量(即只有一个分量的张量)对另一个张量求导,以及在代码中设置不参与求导的部分。
例:
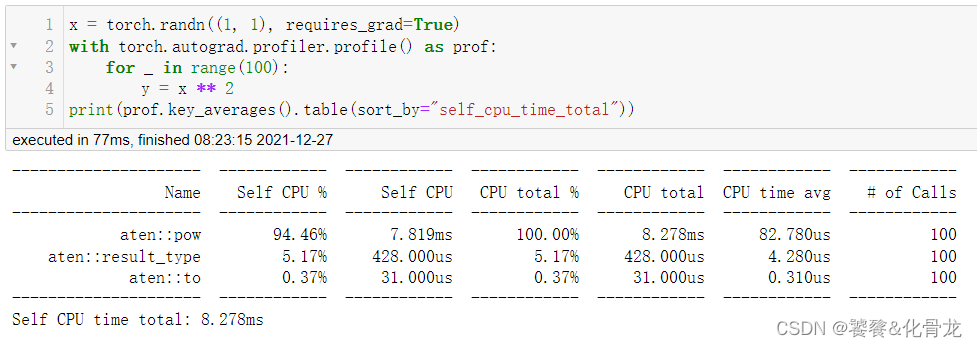
x = torch.randn((1, 1), requires_grad=True)
with torch.autograd.profiler.profile() as prof:for _ in range(100):y = x ** 2
print(prof.key_averages().table(sort_by="self_cpu_time_total"))
10. torch.distributed模块
torch.distributed是pytorch的分布式计算模块,主要是提供pytorch并行运算环境,其主要支持的后端有MPI、Gloo和NCCL三种。pytorch的分布式工作原理是启动多个并行的进程,每个进程拥有一个模型的备份,然后输入不同训练函数到多个并行的进程,计算损失函数,每个进程独立地做反向传播,最后所有进程权重张量的梯度做归约(Reduce)。用到后端的部分主要是数据的广播(Broadcast)和数据的收集(Gather),其中,前者是把数据从一个节点(进程)传播到另一个节点(进程),比如把梯度张量从其他节点转移到某个特定的节点,然后对所有的张量求平均。
11. torch.distributions模块
torch.distributons提供了使得pytorch能够对不同的分布进行采样,并且生成概率采样过程的计算图的相关类。比如在强化学习(Reinforcement Learing)中,经常会使用一个深度学习模型来模拟在不同环境条件下采取的策略(Policy),其最后的输出时不同动作的概率。当深度学习模型输出概率之后,需要根据概率对策略进行采样来模拟当前的策略概率分布,最后用梯度下降方法来让最优策略的概率最大(也称为策略梯度下降,Policy Gradient)。因为采样的输出结果是离散的,无法直接求导,所以不能使用反向传播的方法来优化网络。我们可以使用torch.distributions.Categorical进行采样,然后使用对数求导技巧来规避这个问题。
例:
params = policy_network(state)
m = Normal(*params)
action = m.rsample()
next_state, reward = env.step(action)
loss = -reward
loss.backward()
12. torch.hub模块
torch.hub提供了一系列预训练的模型供用户使用。比如,可以通过torch.hub.list函数来获取某个模型镜像站点的模型信息。通过torch.hub.load来载入预训练的模型,载入后的模型也可以保存到本地。
例:
entrypoints = torch.hub.list('pytorch/vision', force_reload=True)
13. torch.jit模块
torch.jit是pytorch的实时编辑器(Just-In-Time Compiler,JIT)模块。该模块就是把pytorch的动态图转换成可以优化和序列化的静态图,其主要工作原理是通过预先定义好的张量,追踪整个动态图的构建过程,得到最终构建出来的动态图,然后转换为静态图(通过中间表示,即Intermediate Representation,来描述最后得到的图)。
14. torch.multiprocessing模块
torch.multiprocessing是pytorch中的多进程API。通过使用这个模块,可以启动不同的进程,每个进程运行不同的深度学习模型,并且能够在进程间共享张量(通过共享内存的方式)。共享的张量可以在CPU上,也可以在GPU上,多进程API还提供了与Python原生的多进程API(即multiprocessing库)相同的一系列函数,包括锁(Lock)和队列(Queue)等。
15. torch.random模块
torch.random提供了一系列的方法来保存和设置随机生成器的状态,包括使用get_mg_state函数获取当前随机数生成器状态,set_rng_state函数设置当前随机数生成器状态,并且可以使用manual_seed函数来设置随机种子,也可以使用initial_seed函数来得到程序初始化的随机种子。神经网络的训练是一个随机过程,包括数据的输入、权重的初始化都有一定的随机性。设置一个统一的随机种子可以有效地帮助我们测试不同结构神经网络的表现,有助于调试神经网络的结构。
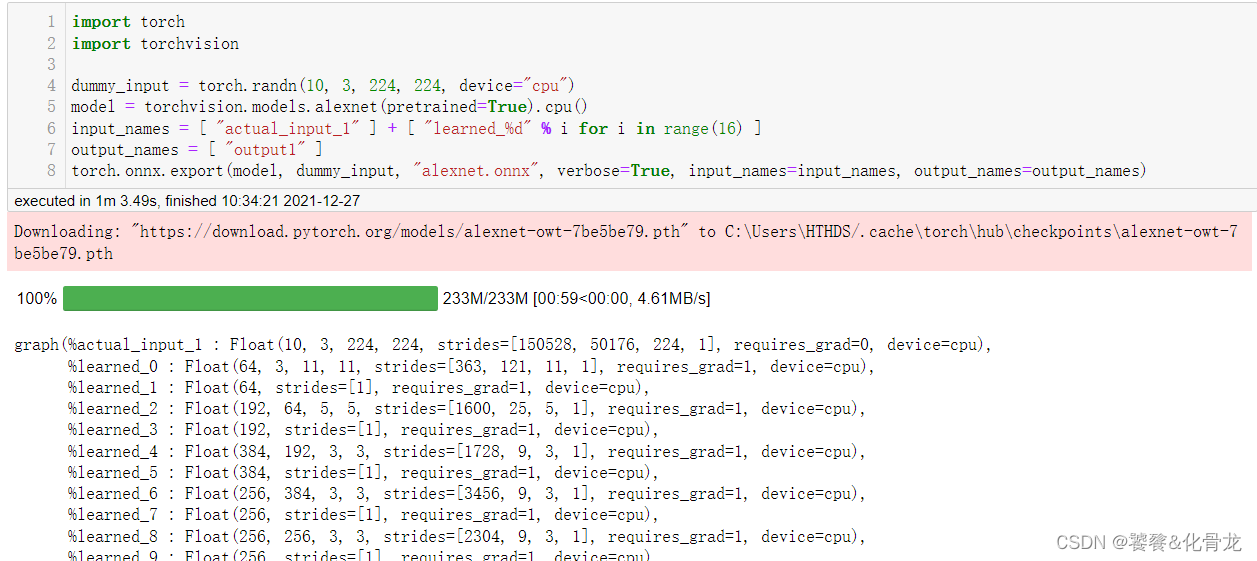
16. torch.onnx模块
torch.onnx定义了pytorch导出和载入ONNX格式的深度学习模型描述文件。该模块可以方便pytorch导出模型给其他深度学习框架使用,或者让pytorch可以载入其他深度学习框架构建的深度学习模型。
例:
import torch
import torchvisiondummy_input = torch.randn(10, 3, 224, 224, device="cpu")
model = torchvision.models.alexnet(pretrained=True).cpu()
input_names = [ "actual_input_1" ] + [ "learned_%d" % i for i in range(16) ]
output_names = [ "output1" ]
torch.onnx.export(model, dummy_input, "alexnet.onnx", verbose=True, input_names=input_names, output_names=output_names)