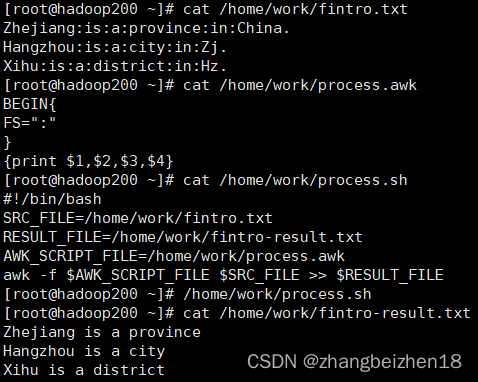
AWK倾向于一行一行的数据进行处理
awk 用法:awk ' pattern {action} '
变量名 含义
ARGC 命令行变元个数
ARGV 命令行变元数组
FILENAME 当前输入文件名
FNR 当前文件中的记录号
FS 输入域分隔符,默认为一个空格
RS 输入记录分隔符
NF 当前记录里域个数
NR 到目前为止记录数
OFS 输出域分隔符
ORS 输出记录分隔符
主要三个参数:FS、NR、NF
FS:定义分隔符的,没有的时候默认是空格符 格式:{FS=“:”}
也可以多域分割
awk -F"[: +]" '{print $1,$2}' ceshi
awk -F":| |+" '{print $1,$2}' ceshi
上述两种情况是一样的
NR:处理的是哪一行 比如:NR==1{printf 。。。。。。。} 第一行应该怎么输出
NF:每一行拥有的字段总数($0)
cat /etc/passwd | awk '{FS=":"} $3 < 10 {print $1 "\t " $3}' 定义分隔符和条件然后输出(默认第一行还是空格符)
AWK常与printf连用,所以对printf的语法也得熟悉
printf
%d 有符号十进制整数
%f 浮点数、十进制记数法
%s 字符串
#直接打印出log.txt 跟 $9一样
ls -ld log.txt |awk '{print $NF}'
[root@ansible logs]# ls -ld catalina.out|awk '{print $NF}'
catalina.out
![]()
#先判断条件筛选在分割,集成了grep的功能
awk -F":" '{if ($3>500) print $1}' /etc/passwd
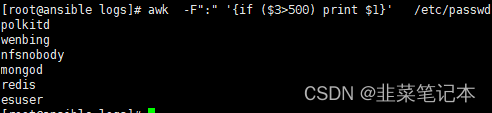
当有这种情况出现时得加扩展符号,比如
#就是直接以多个:或者多个空格为分隔符
awk -F"[: ]+" '{print $2,$3}' log.txt
awk -F":" '$3>500 {print $1}' /etc/passwd
#匹配第一个域已we打头的行,然后打印第一个域
awk -F":" '$1 ~ /^we/ {print $1}' /etc/passwd
#不是以l那个打头的
awk -F":" '$1 !~ /^l/ {print $1}' /etc/passwd
#先打印BEGIN的输出,然后读入内容$0 代表所有
awk -F":" 'BEGIN {print "wenbing,uid"} $3>500 {print $0}' /etc/passwd
---------------------------0508学到这里-----------------------------------
#先打印BEGIN,再读完所有输出,最后打印END的内容
awk -F":" 'BEGIN {print "zhangsan,gid"} $3 >500 {print $1,$3} END {print "ceshi,ceshi"}' /etc/passwd
#awk -F"分隔符" 'BEGIN {print "读取文件之前的初始打印值"} 模式匹配动作 {print action/执行动作} END {print "执行完成之后最后的打印动作"}' +filename
自带变量FILENAME 输入文件名
$0 匹配行的所有输出(按行读取)
$NF 结尾的域
$ 分隔符对应的域
#自定义变量,统计目录文件总字节
ls -l |awk 'BEGIN {size=0} {size+=$5} END {print size}'
![]()
#统计文件的大小
ls -l log.txt |awk 'BEGIN {size=0} {size+=$5} END {print size}'
ls -l catalina.out |awk '{print $5}'
![]()
#BEGIN后面接的第一个是首次读入的,余下的是没读取一个都会读入一次,END后面跟的是只有在所有输入完成之后才读入
#比如这个就是最后一个文件的大小,因为每次读入的时候,size清0了
ls -l |awk '{size=0} {size+=$5} END {print size}'
第一次BEGIN值0,无打印
第二次读入0,打印0
第三次读入8,打印8
第四次读入210,打印218
第五次读入1995,打印2213
最后结尾在打印一遍最终的值
//打印行号
awk '{print NR}' catalina.out
//打印整行
awk '{print $0}' catalina.out
#打印整行,然后做匹配,满足匹配的就打印出行号,
awk '$0~/^$/ {print NR}'catalina.out
#整行先替换成set,再打印行号,然后输出这行内容
awk '$0="SET "NR" "$0' catalina.out
#首先匹配本行是否为空,如果为空执行默认的1打印空行,如果没有的话就不输出,非空就打印匹配规则
awk 'NF{a++;print a,$0;next}1' catalina.out
###正向读取,先读取2.txt,a,b是随意取的别名,读取第一个文件,满足第一个条件,第一个和第二个赋值给a、b变量中的数据,当读取第二个文件时,满足第二个条件(满足读入总记录大于当前文件记录),跳过第一个动作,直接执行print(读入第二个文件时肯定是大于(NR>FNR),执行后面的模块);如果第一个文件想要输出多个,直接在第一个模块加变量即可
awk 'NR==FNR{a[FNR]=$1;b[FNR]=$2;next}NR>FNR{print a[FRN],b[FNR],$2,$3}' 2.txt 1.txt
# 默认分隔符(空格或者制表符)
# $1 $2 表示某列第一个,第二个字段,依次类推
awk '{print $1}' catalina.out
# 可以使用 -F 指定分隔符
awk -F ',' '{print $1,$2}' catalina.out
#输出日志文件的第一列前五行,和前面的 —F 功能相同
head -5 catalina.out | awk 'BEGIN{FS=" "}{print $1,$2}'

# OFS 设置输出分隔符
head -5 catalina.out | awk 'BEGIN{FS=" ";OFS="-"}{print $1,$2}'

#RS 标记行的分隔符(记录分隔符)
# 指定行分隔符进行分割,指定为 \n
head -5 catalina.out | awk 'BEGIN{RS="\n"}{print $1,$2,$3}'
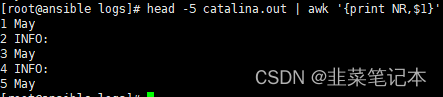
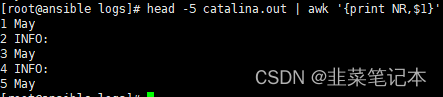
# 指定行序列号输出
head -5 catalina.out | awk '{print NR,$1}'
# 输出文件行数
cat catalina.out | awk 'END{print(NR)}'
#NF 字段数量,$NF 最后一个字段的内容
# 指定分隔符空格,计算每一行字段数量
tail -5 catalina.out | awk 'BEGIN{FS=" "}{print NF}'


# if 判断语句
cat catalina.out | awk '{if($3>300) print($1,$11)}'
# 从第二列开始,依次输出到结尾
tail -5 catalina.out | awk '{for(c=2;c<NF;c++) print $c}'
#删除catalina.out文件的重复行
awk '!($0 in array) { array[$0]; print }' catalina.out
#查看机器的ip列表
ifconfig -a |grep inet|grep netmask|awk '{print $2}'
#查看本机的ip
ifconfig ens33 | grep "netmask" | awk '$1=$1'| cut -d " " -f 2
ifconfig ens33 | grep "netmask" | awk -F" " '{print $2}'
#查看机器的每个远程链接机器的连接数
netstat -antu | awk '$5 ~ /[0-9]:/{split($5, a, ":"); ips[a[1]]++} END {for (ip in ips) print ips[ip], ip | "sort -k1 -nr"}'
#查看java进程打开的socket数量
ps aux | grep tomcat | awk '{print $2}' | xargs -I % ls /proc/%/fd | wc -l
#批量重命名文件
find . -name '*.jpg' | awk 'BEGIN{ a=0 }{ printf "mv %s name%01d.jpg\n", $0, a++ }' | bash

#查看esuer用户打开的文件句柄列表
for x in `ps -u esuser u | grep java | awk '{ print $2 }'`;do ls /proc/$x/fd|wc -l;done

#计算文件temp的第一列的值的和
awk '{s+=$1}END{print s}' catalina.out
![]()
#查看最常用的命令和使用次数
history | awk '{if ($2 == "sudo") a[$3]++; else a[$2]++}END{for(i in a){print a[i] " " i}}' | sort -rn | head
#查看最长使用的10个unix命令
awk '{print $1}' ~/.bash_history | sort | uniq -c | sort -rn | head -n 10
#查找某个时间戳的文件列表
cp -p `ls -l | awk '/Apr 14/ {print $NF}'` /usr/users/backup_dir
#格式化输出当前的进程信息
ps -ef | awk -v OFS="\n" '{ for (i=8;i<=NF;i++) line = (line ? line FS : "") $i; print NR ":", $1, $2, $7, line, ""; line = "" }'
#查看输入数据的特定位置的单个字符
echo "abcdefg"|awk 'BEGIN {FS="''"} {print $2}'
#打印行号
ls | awk '{print NR "\t" $0}'
#打印当前的ssh 客户端
netstat -tn | awk '($4 ~ /:22\s*/) && ($6 ~ /^EST/) {print substr($5, 0, index($5,":"))}'

#打印文件第一列不同值的行
awk '!array[$1]++' catalina.out
#打印第二列唯一值
awk '{ a[$2]++ } END { for (b in a) { print b } }' catalina.out
#查看系统所有分区
awk '{if ($NF ~ "^[a-zA-Z].*[0-9]$" && $NF !~ "c[0-9]+d[0-9]+$" && $NF !~ "^loop.*") print "/dev/"$NF}' /proc/partitions
#查看2到100所有质数
for num in `seq 2 100`;do if [ `factor $num|awk '{print $2}'` == $num ];then echo -n "$num ";fi done;echo

#查看第3到第6行
awk 'NR >=3 && NR <= 6' catalina.out
#逆序查看文件
awk '{a[i++]=$0} END {for (j=i-1; j>=0;) print a[j--] }' catalina.out
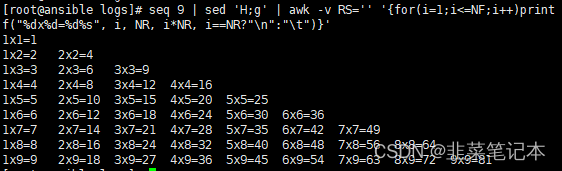
#打印99乘法表
seq 9 | sed 'H;g' | awk -v RS='' '{for(i=1;i<=NF;i++)printf("%dx%d=%d%s", i, NR, i*NR, i==NR?"\n":"\t")}'
#从文件中找出长度大于 80 的行:
awk 'length>80' catalina.out
# 求和
cat catalina.out|awk '{sum+=$1} END {print "Sum = ", sum}'
# 求平均
cat catalina.out|awk '{sum+=$1} END {print "Average = ", sum/NR}'
# 求最大值
cat catalina.out|awk 'BEGIN {max = 0} {if ($1>max) max=$1 fi} END {print "Max=", max}'
# 求最小值(min的初始值设置一个超大数即可)
awk 'BEGIN {min = 1999999} {if ($1<min) min=$1 fi} END {print "Min=", min}' catalina.out
# 计算状态码分布,sort 正序排列
cat catalina.out | awk '{print $11}' | sort -n | uniq -c
# 查找特定IP的日志
cat catalina.out | awk -F '\t' '($1~/192.168.1.150/){print $0}'
# 查找符合条件的数量
head catalina.out | awk 'BEGIN{count=0} {if($1!=0) count++ fi} END {print count}'

# 取出第一列 覆盖输出到1.txt中 (>>追加输出)
cat catalina.out |awk '{print $1}' > 1.txt
#算术函数
awk 'BEGIN{pi=3.14;print int(pi)}'
#随机数
awk 'BEGIN{srand();print rand()}'
![]()
# 第一个$1表示把第二列的内容放在第二个$1的位置
cat catalina.out | awk '$1=$1 "test.test"'
#合并两个单列的文本
awk 'FNR==NR{d[NR]=$0}FNR!=NR{print d[FNR],$0}' log1.txt log2.txt
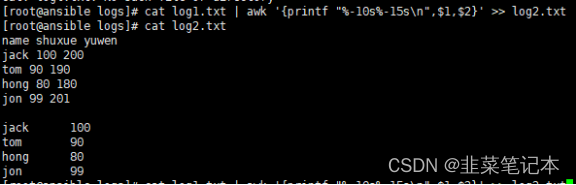
#格式化结果后输出
# %-45s表示输出字符串,宽度45位,左对齐.%-15s用来指定第二列的,左对齐,宽度15
# 两个百分号之间可以没有空格.使用\n对每一行的输出加上换行符
cat log1.txt | awk '{printf "%-10s%-15s\n",$1,$2}' >> log2.txt
#匹配$1出现的次数,key就是$1,value就是出现的次数,这种方式是无序的
awk '{array[$1]++}{for (i in array) print i,array[i]}' log1.txt
#awk 数组引用,按照顺序读取
awk -F ':' 'BEGIN {count=0;} {name[count] = $1;count++;}; END{for (i = 0; i < NR; i++) print i, name[i]}' /etc/passwd
#awk if循环运用
awk -F":" 'BEGIN{count=0;print "[start] privileges count is",count}{if($3==0){print $0}else if($3>1000){print $1,"test user";count+=2*$3} else {print $1,$3;count+=$3}}END{print "[end] privileges count is",count}' /etc/passwd
#打印第二列唯一值
awk '{ a[$2]++ } END { for (b in a) { print b } }' log1.txt
##按第六列 重复的删除,并保留一行
awk '!arr[$6]++' ca talina.out
##按第2列和第3列重复的删除,并保留一行
awk '!arr[$2$3]++' catalina.out
awk '!arr[$2_$3]++' catalina.out
##提取两个文件第一列相同的行
awk -F',' 'NR==FNR{a[$1]=$0;next}NR>FNR{if($1 in a)print $0"\n"a[$1]}' 1.log 2.log
##awk 按某个位置的字符分隔的方法
awk -F ":" '{ for(i=1;i<=3;i++) printf("%s:",$i)}' catalina.out
awk -F':' '{print $1 ":" $2 ":" $3; print $4}' catalina.out
awk -F':' '{print $1 ":" $2 ":" $3; for(i=1;i<=3;i++)$i=""; print}' catalina.out
##排序显示重复项目
cat catalina.out |awk -F '[ ]+' '{print $1}'| sort | uniq -c | sort -nr
#awk -F '\t'来表示分隔符,比如
awk -F '\t' '{print $1}' catalina.out
##多个空格分隔的方法
awk -F '[ ]+' '{print $9}'catalina.out
ls -lh /etc/sysconfig/network-scripts/ifcfg-* | awk -F '[ ]+' '{print $9}'
##指定分隔符既可以为空格,又可以为冒号,那么处理将会变得简单。可以使用正则表达式来指定多个分隔符,格式为 -F'[空格:]+' 如下
tail -5 catalina.out| awk -F'[ :]+' '{print $1"\t"$2}'

#显示文件中包含101的匹配行。
awk '/101/' catalina.out
awk '/101/,/105/' catalina.out
awk '$1 == 5' catalina.out
awk '$1 == "CT"' catalina.out 注意必须带双引号
awk '$1 * $2 >100 ' catalina.out
awk '$2 >5 && $2<=15' catalina.out
#显示文件file的当前记录号、域数和每一行的第一个和最后一个域。
awk '{print NR,NF,$1,$NF}' file
#显示文件file的匹配行的第一、二个域加10。
awk '/101/ {print $1,$2 + 10}' catalina.out
awk '/101/ {print $1$2}' catalina.out
显示文件file的匹配行的第一、二个域,但显示时域中间没有分隔符。
awk '/101/ {print $1 $2}' catalina.out
通过管道符获得输入,如:显示第4个域满足条件的行
df -h | awk '$4>1000000 '
#按照新的分隔符“|”进行操作。
awk -F "|" '{print $1}' catalina.out
#通过设置输入分隔符(FS="[: \t|]")修改输入分隔符。
awk 'BEGIN { FS="[: \t|]" } {print $1,$2,$3}' file
awk 'BEGIN { max=100 ;print "max=" max} #BEGIN 表示在处理任意行之前进行的操作。
{max=($1 >max ?$1:max); print $1,"Now max is "max}' file #取得文件第一个域的最大值。
(表达式1?表达式2:表达式3 相当于:
if (表达式1)
表达式2
else
表达式3
awk '{print ($1>4 ? "high "$1: "low "$1)}' file
#找到匹配行后先将第3个域替换后再显示该行(记录)。
awk '{$1 == 'Chi' {$3 = 'China'; print}' 1.log
#将第7域被3除,并将余数赋给第7域再打印。
awk '{$7 %= 3; print $7}' 1.log
#找到匹配行后为变量wage赋值并打印该变量。
awk '/tom/ {wage=$2+$3; printf wage}' 1.log
#END表示在所有输入行处理完后进行处理。
awk '/tom/ {count++;} END {print "tom was found "count" times"}' file
![]()
#gsub函数用空串替换$和,再将结果输出到filename中。
awk 'gsub(/\$/,"");gsub(/,/,""); cost+=$4; END {print "The total is $" cost>"filename"}' file
1 2 3 $1,200.00
1 2 3 $2,300.00
1 2 3 $4,000.00
awk '{gsub(/\$/,"");gsub(/,/,"");
if ($4>1000&&$4<2000) c1+=$4;
else if ($4>2000&&$4<3000) c2+=$4;
else if ($4>3000&&$4<4000) c3+=$4;
else c4+=$4; }
END {printf "c1=[%d];c2=[%d];c3=[%d];c4=[%d]\n",c1,c2,c3,c4}"' file
通过if和else if完成条件语句
awk '{gsub(/\$/,"");gsub(/,/,"");
if ($4>3000&&$4<4000) exit;
else c4+=$4; }
END {printf "c1=[%d];c2=[%d];c3=[%d];c4=[%d]\n",c1,c2,c3,c4}"' file
通过exit在某条件时退出,但是仍执行END操作。
awk '{gsub(/\$/,"");gsub(/,/,"");
if ($4>3000) next;
else c4+=$4; }
END {printf "c4=[%d]\n",c4}"' file
通过next在某条件时跳过该行,对下一行执行操作。
#把log1、log2的文件内容全部写到log3中,格式为打印文件并前置文件名。
awk '{ print FILENAME,$0 }' log1.txt log2.txt > log3.txt
#把合并后的文件重新分拆为3个文件。并与原文件一致。
awk ' $1!=previous { close(previous); previous=$1 } {print substr($0,index($0," ") +1)>$1}' log3.txt
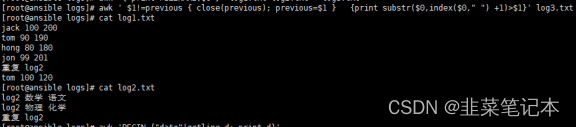
#通过管道把date的执行结果送给getline,并赋给变量d,然后打印。
awk 'BEGIN {"date"|getline d; print d}'
![]()
#通过getline命令交互输入name,并显示出来。
awk 'BEGIN {system("echo \"Input your name:\\c\""); getline d;print "\nYour name is",d,"\b!\n"}'
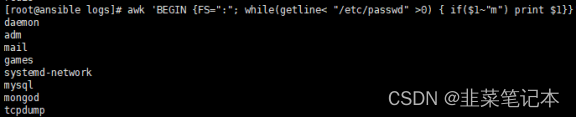
#打印/etc/passwd文件中用户名包含m的用户名。
awk 'BEGIN {FS=":"; while(getline< "/etc/passwd" >0) { if($1~"m") print $1}}'
18、awk '{ i=1;while(i<NF) {print NF,$i;i++}}' file 通过while语句实现循环。
awk '{ for(i=1;i<NF;i++) {print NF,$i}}' file 通过for语句实现循环。
type file|awk -F "/" '
{ for(i=1;i<NF;i++)
{ if(i==NF-1) { printf "%s",$i }
else { printf "%s/",$i } }}' 显示一个文件的全路径。
用for和if显示日期
awk 'BEGIN {
for(j=1;j<=12;j++)
{ flag=0;
printf "\n%d月份\n",j;
for(i=1;i<=31;i++)
{
if (j==2&&i>28) flag=1;
if ((j==4||j==6||j==9||j==11)&&i>30) flag=1;
if (flag==0) {printf "%02d%02d ",j,i}
}
}
}'
du -sk /home/ |gawk '$1>1024*1024 {print $1/1024/1024"G"} {print $1/1024"M"}'
![]()
精确到M和G 小数点....
du -sk /home/ |gawk '{print $1/1024}' 统计显示精确到M
du -sk /home/ |gawk '{print $1/1024/1024}' 统计显示精确到G
#在awk中调用系统变量必须用单引号,如果是双引号,则表示字符串
Flag=abcd
awk '{print '$Flag'}' 结果为abcd
awk '{print "$Flag"}' 结果为$Flag
#打印所有以模式no或so开头的行。
awk '/^(error|ERROR)/' catalina.out
#如果记录以n或s开头,就打印这个记录。
awk '/^[error]/{print $1}' catalina.out
#如果第一个域以两个数字结束就打印这个记录。
awk '$1 ~/[0-9][0-9]$/(print $1}' catalina.out
#如果第一个或等于100或者第二个域小于50,则打印该行。
awk '$1 == 100 || $2 < 50' catalina.out
#如果第一个域不等于10就打印该行。
awk '$1 != 10' catalina.out
#如果记录包含正则表达式test,则第一个域加10并打印出来。
awk '/test/{print $1 + 10}' catalina.out
如果第一个域大于5则打印问号后面的表达式值,否则打印冒号后面的表达式值。
awk '{print ($1 > 5 ? "ok "$1: "error"$1)}' catalina.out
#打印以正则表达式root开头的记录到以正则表达式mysql开头的记录范围内的所有记录。如果找到一个新的正则表达式root开头的记 录,则继续打印直到下一个以正则表达式mysql开头的记录为止,或到文件末尾。
awk '/^root/,/^mysql/' catalina.out