主成分分析(Principal components analysis,以下简称PCA)是最重要的降维方法之一。在数据压缩消除冗余和数据噪音消除等领域都有广泛的应用。一般我们提到降维最容易想到的算法就是PCA,下面我们就对PCA的原理做一个总结。
目录
一、PCA的思想与原理
(一)什么是主成分分析法
(二)为什么做PCA
(三)PCA的思想
二、PCA的推导:基于最小投影距离
三、PCA的推导:基于最大投影方差
四、PCA算法流程
五、PCA实例
六、PCA的应用
(一)降噪
1、PCA为什么能降噪
2、手写数字降噪实例
(二)人脸识别
七、PCA算法总结
一、PCA的思想与原理
(一)什么是主成分分析法
-
一种数据数据降维算法(非监督)
- 通过析取主成分显出的最大的个体差异,发现更便于人们能够理解的特征,也可以用来削减回归分析和聚类分析中变量的数目。
(二)为什么做PCA
- 在很多场景中需要对多变量数据进行观测,在一定程度上增加了数据采集的工作量。并且多变量之间存在相关性,从而增加了问题分析的复杂性
- 对每个指标单独分析 ——> 分析结果是孤立的(不能完全利用数据的信息)
- 盲目减少指标 ——> 损失有用的信息,得出错误结论
- 在减少分析指标的同时,尽量减少原指标的信息的损失
- 可以考虑将关系紧密的变量变成尽可能少的新变量,使这些新变量是两两不相关的,那么就可以用较少的综合指标分别代表存在于各个变量中的各类信息
(三)PCA的思想
假如我们的数据集是n维的,共有m个数据(x,x
,...,x
)。我们希望将这m个数据的维度从n维降到k维,希望这m个k维的数据集尽可能的代表原始数据集。我们知道数据从n维降到k维肯定会有损失,但是我们希望损失尽可能的小。那么如何让这k维的数据尽可能表示原来的数据呢?
我们先看看最简单的情况,也就是n=2,K=1,也就是将数据从二维降维到一维。数据如下图。我们希望找到某一个维度方向,它可以代表这两个维度的数据。图中列了两个向量方向,u1和u2,那么哪个向量可以更好的代表原始数据集呢?从直观上也可以看出,u1比u2好。
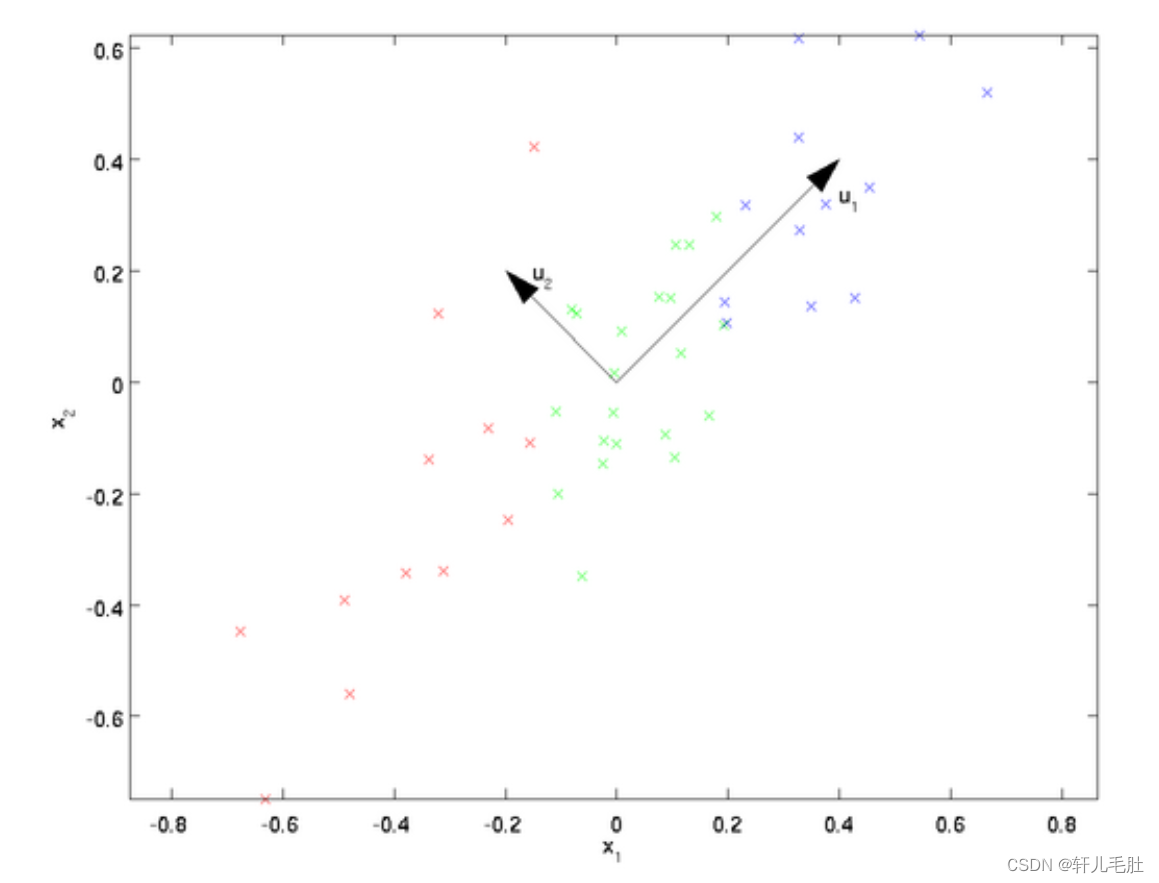
为什么u1比u2好呢?
可以有两种解释,第一种解释是样本点到这个直线的距离足够近,第二种解释是样本点在这个直线上的投影能尽可能的分开。
假如我们把K从1维推广到任意维,我们希望降维的标准为:样本点到这个超平面的距离足够近,或者说样本点在这个超平面上的投影能尽可能的分开。
基于上面的两种标准,我们可以得到PCA的两种等价推导。
二、PCA的推导:基于最小投影距离
我们首先看第一种解释的推导,即样本点到这个超平面的距离足够近。
设m个n维数据(x,x
,...,x
)都已经进行了中心化,即
。经过投影变换后得到的新坐标系为{
},其中w是标准正交基,即
。

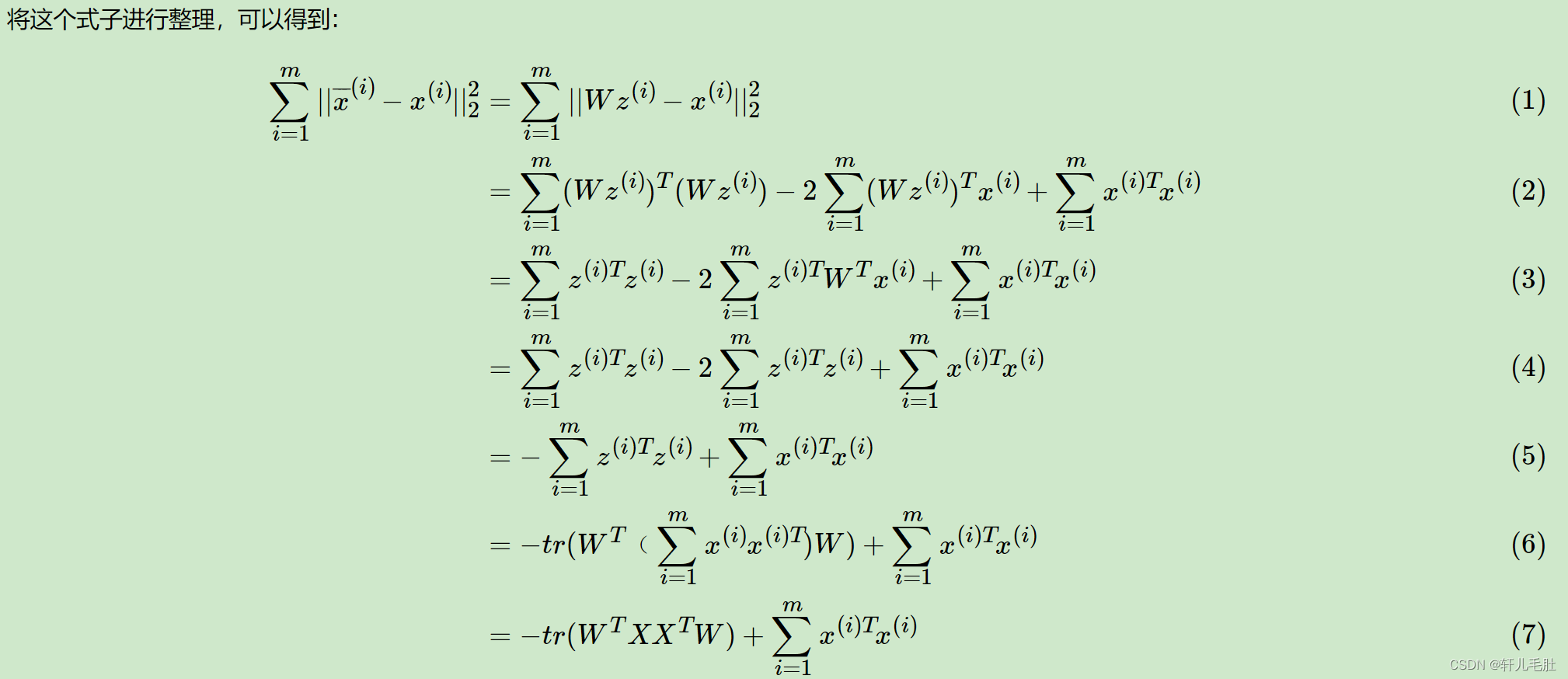

三、PCA的推导:基于最大投影方差
现在我们再来看看基于最大投影方差的推导。
设m个n维数据(x,x
,...,x
)都已经进行了中心化,即
。经过投影变换后得到的新坐标系为{
},其中w是标准正交基,即
。

四、PCA算法流程
 五、PCA实例
五、PCA实例
下面举一个简单的例子,说明PCA的过程。
假设我们的数据集有10个二维数据(2.5,2.4), (0.5,0.7), (2.2,2.9), (1.9,2.2), (3.1,3.0), (2.3, 2.7), (2, 1.6), (1, 1.1), (1.5, 1.6), (1.1, 0.9),需要用PCA降到1维特征。
首先我们对样本中心化,这里样本的均值为(1.81, 1.91),所有的样本减去这个均值向量后,即中心化后的数据集为(0.69, 0.49), (-1.31, -1.21), (0.39, 0.99), (0.09, 0.29), (1.29, 1.09), (0.49, 0.79), (0.19, -0.31), (-0.81, -0.81), (-0.31, -0.31), (-0.71, -1.01)。
现在我们开始求样本的协方差矩阵,由于我们是二维的,则协方差矩阵为:

对于我们的数据,求出协方差矩阵为:

求出特征值为(0.0490833989, 1.28402771),对应的特征向量分别为:,
,由于最大的k=1个特征值为1.28402771,对于的k=1个特征向量为
。则我们的W=
我们对所有的数据集进行投影,得到PCA降维后的10个一维数据集为:(-0.827970186,1.77758033,-0.992197494, -0.274210416,-1.67580142,-0.912949103,0.0991094375,1.14457216, 0.438046137,1.22382056)
六、PCA的应用
(一)降噪
1、PCA为什么能降噪
在实际的数据中不可避免地出现各种噪音,这些噪音的出现可能会对数据的准确性造成一定的影响。而主成分分析法还有一个用途就是降噪。PCA通过选取主成分将原有数据映射到低维数据再映射回高维数据的方式进行一定程度的降噪。
例如,我们构造一组数据:
import numpy as np
import matplotlib.pyplot as plt
X = np.empty((100, 2))
X[:,0] = np.random.uniform(0., 100., size=100)
X[:,1] = 0.75 * X[:,0] + 3. + np.random.normal(0, 5, size=100)
plt.scatter(X[:,0], X[:,1])
plt.show()
其中np.random.normal(0, 5, size=100)就是我们认为添加的噪声,在线性方程上下抖动。

我们降噪,这就需要使用PCA中的一个方法:X_ori=pca.inverse_transform(X_pca),将降维后的数据转换成与维度相同数据。要注意,还原后的数据,不等同于原数据!
这是因为在使用PCA降维时,已经丢失了部分的信息(忽略了解释方差比例)。因此在还原时,只能保证维度相同。会尽最大可能返回原始空间,但不会跟原来的数据一样。这样一来一回之间,丢失掉的信息,就相当于降噪了。
Stack Overflow中有两个不错的解释:
- you can only expect this if the number of components you specify is the same as the dimensionality of the input data. For any n_components less than this, you will get different numbers than the original dataset after applying the inverse PCA transformation: the following diagrams give an illustration in two dimensions.
- It can not do that, since by reducing the dimensions with PCA, you’ve
lost information (check pca.explained_variance_ratio_ for the % of
information you still have). However, it tries its best to go back to
the original space as well as it can, see the picture below
对制造的数据先降维,后还原,就可以去除噪音了:
from sklearn.decomposition import PCApca = PCA(n_components=1)
pca.fit(X)
X_reduction = pca.transform(X)
X_restore = pca.inverse_transform(X_reduction)
plt.scatter(X_restore[:,0], X_restore[:,1])
plt.show()

transform降维成一维数据,再inverse_transform返回成二维数据。此时数据成为了一条直线。这个过程可以理解为将原有的噪音去除了。当然,我们丢失的信息也不全都是噪音。我们可以将PCA的过程定义为:降低了维度,丢失了信息,也去除了一部分噪音。
2、手写数字降噪实例
重新创建一个有噪音的数据集,以digits数据为例:
from sklearn import datasetsdigits = datasets.load_digits()
X = digits.data
y = digits.target
# 添加一个正态分布的噪音矩阵
noisy_digits = X + np.random.normal(0, 4, size=X.shape)# 绘制噪音数据:从y==0数字中取10个,进行10次循环;
# 依次从y==num再取出10个,将其与原来的样本拼在一起
example_digits = noisy_digits[y==0,:][:10]
for num in range(1,10):example_digits = np.vstack([example_digits, noisy_digits[y==num,:][:10]])
example_digits.shape
# 输出:
(100, 64) # 即含有100个数字(0~9各10个),每个数字有64维
下面将这100个数字绘制出来,得到有噪音的数字:
def plot_digits(data):fig, axes = plt.subplots(10, 10, figsize=(10, 10),subplot_kw={'xticks':[], 'yticks':[]},gridspec_kw=dict(hspace=0.1, wspace=0.1)) for i, ax in enumerate(axes.flat):ax.imshow(data[i].reshape(8, 8),cmap='binary', interpolation='nearest',clim=(0, 16))plt.show()
plot_digits(example_digits)
 下面使用PCA进行降噪:
下面使用PCA进行降噪:

我们可以看到,图片清晰了不少。
(二)人脸识别
PCA将样本X从n维空间映射到k维空间,求出前k个主成分。 一个m ∗ n的矩阵,在经过主成分分析之后,一个k ∗ n的主成分矩阵。如果将主成分矩阵也看成是由k个样本组成的矩阵,那么可以理解为第一个样本是最重要的样本,以此类推。
在人脸识别领域中,原始数据矩阵可以视为有m个人脸样本的集合,如果将主成分矩阵每一行也看做是一个样本的话,每一行相当于是一个由原始人脸数据矩阵经过主成分分析得到的“特征脸”(Eigenface)矩阵,这个矩阵含有k个“特征脸”。每个“特征脸”表达了原有样本中人脸的部分特征。
七、PCA算法总结
这里对PCA算法做一个总结。作为一个非监督学习的降维方法,它只需要特征值分解,就可以对数据进行压缩,去噪。因此在实际场景应用很广泛。为了克服PCA的一些缺点,出现了很多PCA的变种,比如为解决非线性降维的KPCA,还有解决内存限制的增量PCA方法Incremental PCA,以及解决稀疏数据降维的PCA方法Sparse PCA等。
PCA算法的主要优点有:
1)仅仅需要以方差衡量信息量,不受数据集以外的因素影响。
2)各主成分之间正交,可消除原始数据成分间的相互影响的因素。
3)计算方法简单,主要运算是特征值分解,易于实现。
PCA算法的主要缺点有:
1)主成分各个特征维度的含义具有一定的模糊性,不如原始样本特征的解释性强。
2)方差小的非主成分也可能含有对样本差异的重要信息,因降维丢弃可能对后续数据处理有影响。