linux
常见linux高级命令?
- top、iotop
- netstat
- df -h
- jmap -heap
- tar
- rpm
- ps -ef
shell
用过的shell工具?
- awk Awk 命令详解 - 简书
awk是行处理器: 相比较屏幕处理的优点,在处理庞大文件时不会出现内存溢出或是处理缓慢的问题,通常用来格式化文本信息
- sort sort 命令详解 - 简书
- cut Linux cut 命令详解 - 简书
- sed 【现学现忘&Shell编程】— 35.sed命令(一) - 简书
写过哪些脚本
1.启停脚本

2. 单引号、双引号区别 单引号不解析里面变量的值,双引号解析里面变量值
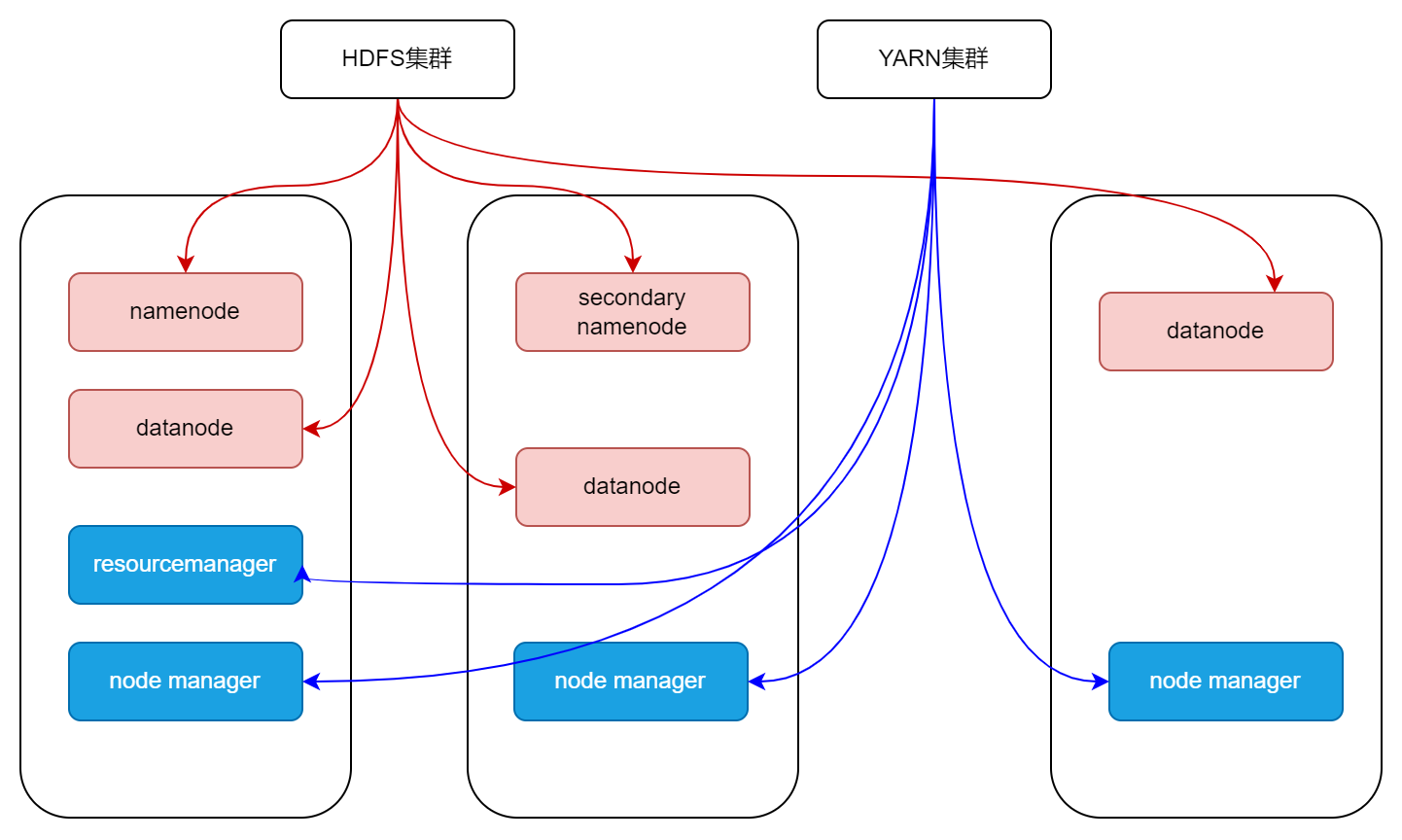
hadoop
入门问题:常用端口号、常用配置
9870 hdfs访问端口;8088 yarn访问端口;19888JobHistory访问;剩下的是内部通信端口

HDFS
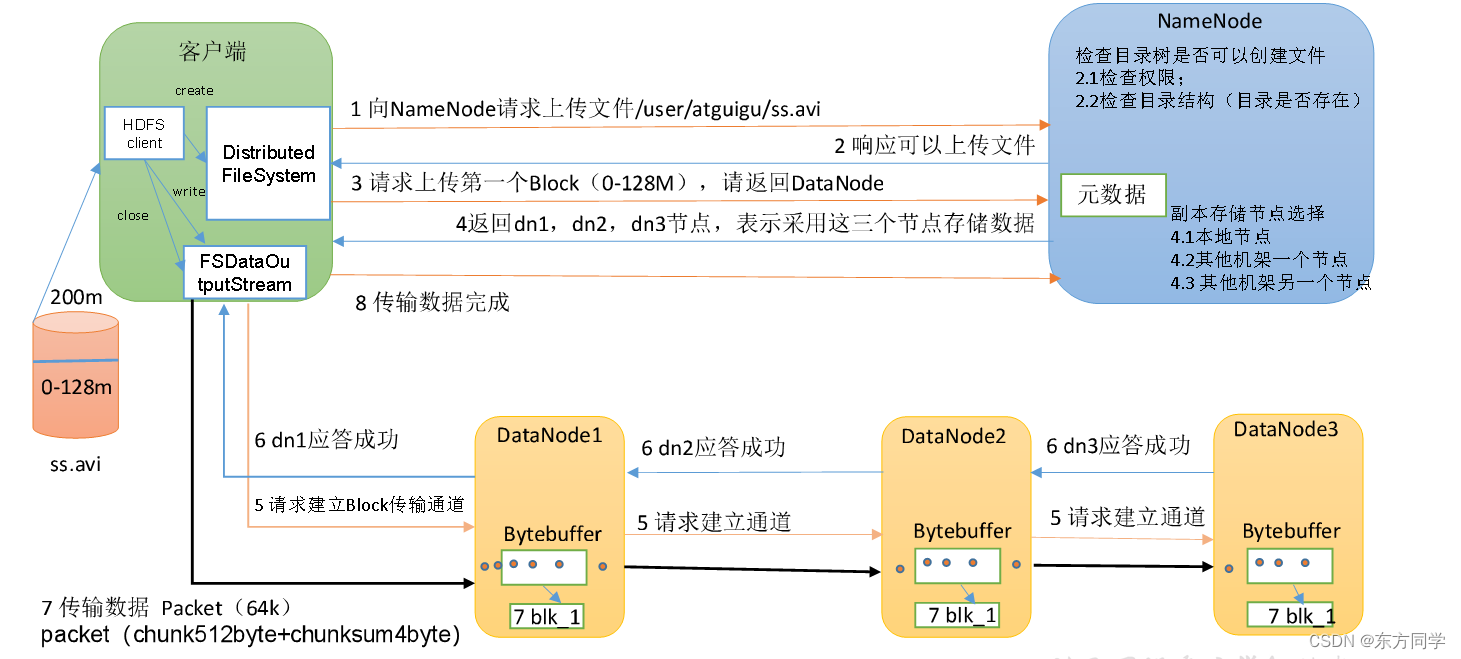
- 读写流程 HDFS的读写流程(面试重点)_简述hdfs的读写流程_你可以自己看的博客-CSDN博客
- 小文件危害 (1)存储 每个文件都必须占用一个NameNode存储元数据。每个NameNode大小150字节。小文件太多,占用空间。 (2)计算 默认的切片原则是每个文件单独切片,即使是1个字节的小文件也需要启动1个对应的maptask处理,每个maptask至少占用1G内存。切片的概念 HDFS的block和切片(split)的区别_贺雨蒙的博客-CSDN博客_hdfs切片
- 小文件怎么解决
(1)har归档 将多个小文件的NamNode进行合并
(2)CombineTextInputformat 把小文件放在一起切片计算
(3)JVM重用 启动一个JVM,计算多个文件。节省开启、关闭的开销。

MR shuffle 过程
案例举例整个过程 080_大数据第五阶段-Hadoop第三天_shuffle下_哔哩哔哩_bilibili
- hdfs中文件是以block块的形式存储,默认block大小为128M,如果电脑磁盘读写速度块,可以配置成246/512M都可以。
- 默认一个block对应一个split逻辑分区。可以配置成多个block对应一个split逻辑分区。
- split分区的数据按行存储。每行的数据调用自己编写的Map函数的逻辑,对数据进行处理。即图中的Map处理。
- map方法处理后的数据写入环形缓冲区。环形缓冲区默认时100M大小的内存,写到80%时异步线程spill溢出到磁盘,写的数据进行向剩下的20%写入。等20%写满时,80%空间基本已经spill结束空间已经空闲可以继续写入,再写满80%,重复spill。因此环形缓冲区可以保证不中断的存储数据。环形缓冲区底层时byte数组。
- 环形缓冲区溢出时会 排序、分区,甚至combine操作。
- 比如reducer为求最大值,那么就可以在此处提前进行combine求出每个分区的最大值。但是如果此时combine会对reduce的计算有影响,那么不进行combine。combine通过在map方法里面指定且溢出文件大于等于3个时才进行。
- 分区一般是根据对key hash 求模reduceTask数量确定分区位置。
6.对多个溢出文件进行归并操作。 每个分区排好序。

yarn
1.yarn工作机制、工作流程
mapreduce yarn流程图_YARN 运行机制分析_投资百晓生的博客-CSDN博客
mapreduce yarn流程图_YARN 运行机制分析_投资百晓生的博客-CSDN博客
2.调度器
大数据技术Hadoop——YARN_阳哥赚钱很牛的博客-CSDN博客
- 公平、容量调度器通常都是默认的1个队列,需要修改 yarn-site.xml中的配置项 yarn.resourcemanager.scheduler.class
- 公司一个yarn,此时根据一个部门一个申请一个队列,如果队列任务过多,可以格局任务重要性将不重要的任务降级使用。

kafka
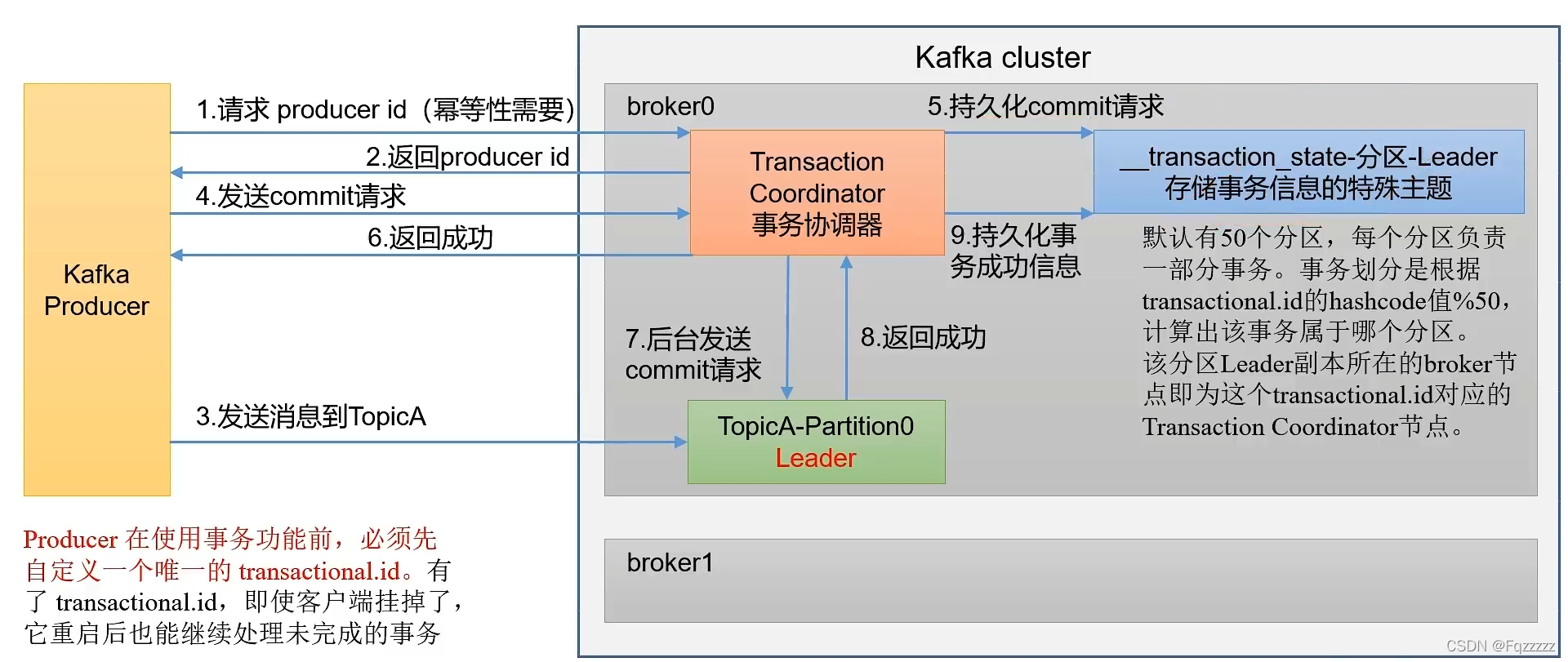
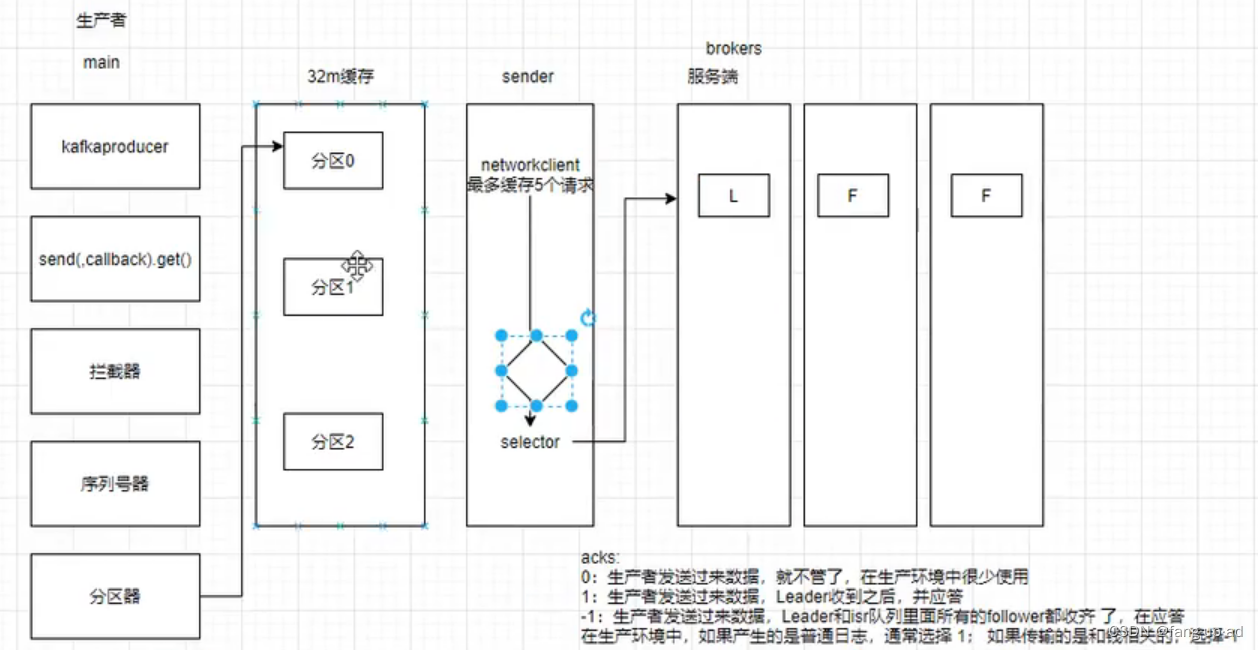
(1)生产者工作流程
生产者两个线程:main、sender
- 一个main线程,创建kafkaproducer,调用send方法。
- send方法异步发送,加上send().get()则同步发送。callback回调函数。
- 拦截器一般不用。
- 自定义序列化器,之所以不用java自带的序列化器,是因为自带的辅助属性太多浪费空间。常见数据类型kafka已经实现序列化器,自定义类需要自己实现序列化器。
- 分区器,决定把数据发送到哪个分区?(1)指定分区发送到指定分区 (2)未指定分区,按照key的hash值取余分区数(3)没有指定分区和key,那么按照粘性分区。粘性分区random随机选择分区,直到16k满了或这一批数据发送完再random切换分区。
2.sender线程 专门用来发送数据
- 创建networkclient对象和broker通信。默认缓存5个发送数据的请求。比如给leader发送数据的一个请求,没有按时ack,那么发送缓存队列中的下一个请求。
- 底层发送数据使用selector nio发送数据
- 将数据发给leader,leader ack应答。如果leader正确收到,那么会删除缓存和分区中的数据,如果没正确收到,会重试,重试次数int最大值。
(2)brokers工作流程
- 每个broker启动后,会将id主车道zk中。
- controller 用来选择谁是leader,每个broker服务器都有。才开始是会随机一个broker的controller和zk的controller通信,选举谁是leader。根据lsr里面的ar顺序先后选择leader。并将leader的id记录在zk中。
- broker 会将topic的每个partition以多个segment存储,默认大小1G。每个segment包括为 .index .log .timestatmp 。.log存储具体数据,.index稀疏矩阵,没4kb数据存储一个索引 timestamp存储文件创建时间。
- lsr 记录能和leader正常通信的follow节点 正常通信是40s内有心跳。

消费者组消费流程
- 多个消费者根据配置的groupid来确定是一个消费者组。id对默认的分区数50取余的分区,向分区所在的消费者组协调器通信。consumer offset默认50个分区kafka consumer offset机制 - 简书
- 消费者全部发送joingroup信息。然后回复信息,随机选择消费者中某个作为leader ,将结果告知协调器。
- 协调器所有信息发送给消费者的leader,leader根据 range/粘性、roundin消费策略分配每个消费者的消费组。告知协调器,协调器告知所有消费者。
- 消费者每隔3s和协调器进行一次通信,超过45s没有通信;消费者如果超过5分钟没有再拉取数据,都会认为消费者挂掉,会再平衡。 再平衡会所有数据发送暂停,分配好在发送。 很不好
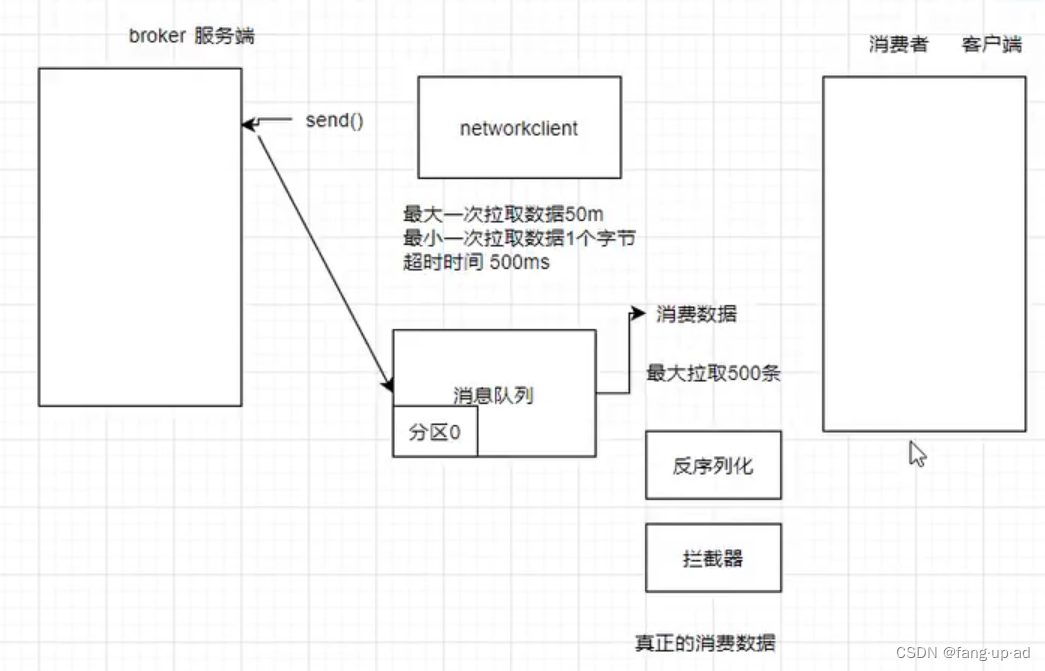
消费者真正消费数据流程
- 消费者有networkclient对象,创建时会初始化一些参数。 比如最大一次拉取数据大小50M、最小一次拉取数据1个字节。如果分区数据超过500ms没有凑够50M那么直接数据拉回不等待,防止等待时间太长
- networkclient调用send方法,有回调函数取回数据,消息队列中按照数据本来分区进行存储。消费者根据确定的分区拉取。拉取回后对数据反序列化、拦截器进行处理。