一、Kafka是什么?
Kafka是最初由Linkedin公司开发的一个分布式、分区的、多副本的、多订阅者,由Scala和Java编写的基于zookeeper协调的分布式流处理平台,常见可以用于web日志、访问日志,消息服务等等,Linkedin于2010年将其贡献给了Apache基金会并成为顶级开源项目。
1、Kafka的核心架构和功能
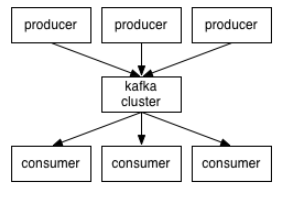
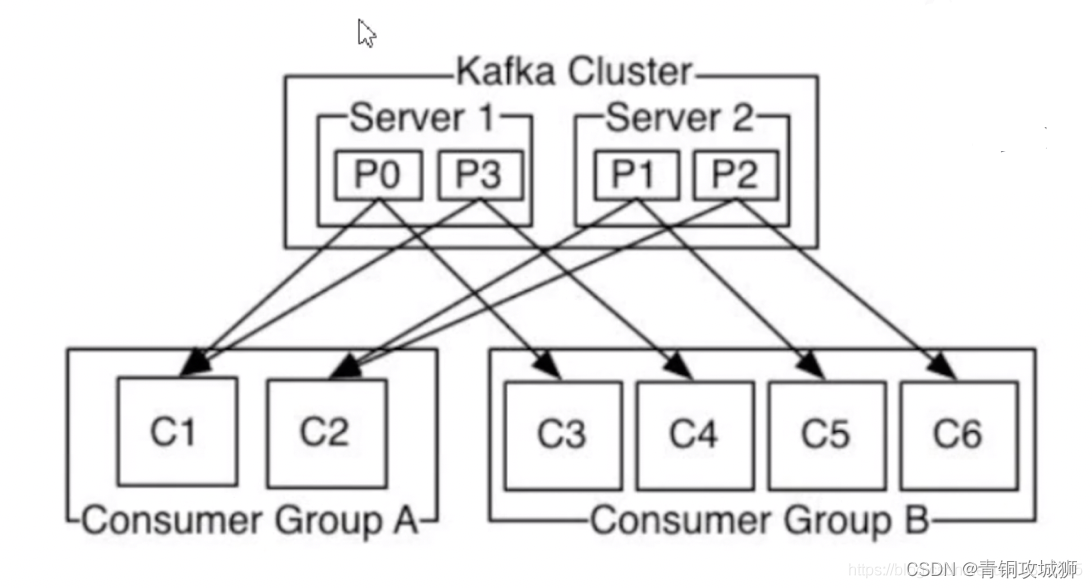
Kafka的核心功能是:高性能的消息发送与高性能的消息消费;其核心架构如下图:

2、Kafka主要功能可以用以下三句话概括
生产者发送消息给kafka服务器
消费者从kafka服务器读取消息
Kafka服务器依托zookeeper集群进行服务的协调管理
3、Kafka中涉及到的术语
broker:一般中文翻译为经纪人,掮客,代理人,但这些词不能很好的表达broker的意思,所以只要知道broker是表示kafka服务器即可;
message:消息,使用紧凑的二进制字节数据来保存消息,节省内存空间和传输效率;
topic:主题,代表了一类消息;
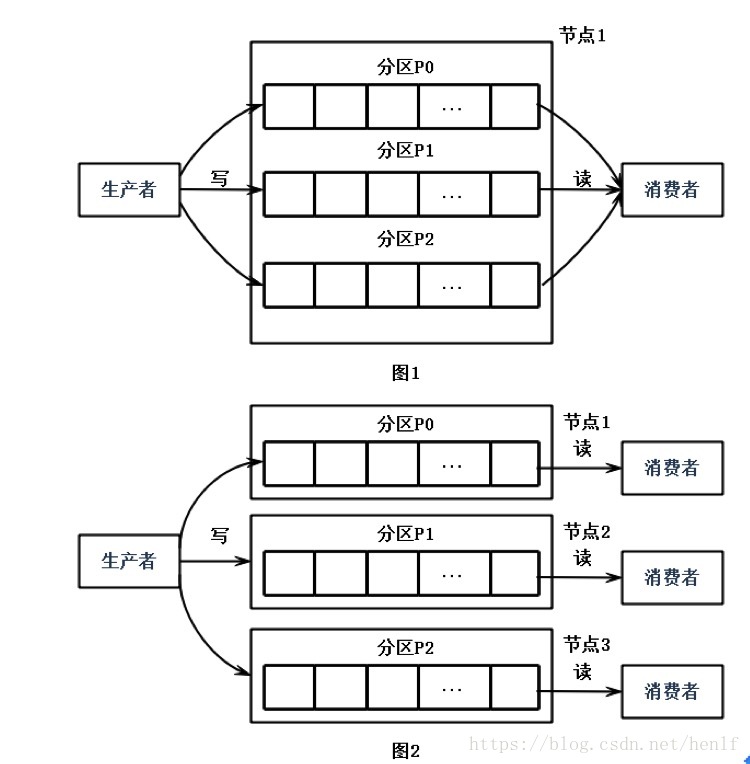
partition:分区,kafka采用topic-partition-message的三级结构来分散负载;
offset:位移,分区下每条消息都被分配一个位移值,表示消息在分区中的位置;需要注意到是消息者也有位移的概念;
replica:副本,备份多份日志,防止数据丢失;分为两类:领导者副本(leader replica)和追随者副本(follower replica);
leader和follower:领导者和追随者,通常leader对外提供服务,follower只是被动地追随leader的状态,保持与leader的同步,充当leader的候补,以便leader挂掉后被选举成新的leader接替它的工作;
ISR(in-sync replica):表示与leader replica保持同步到replica集合,
4、Kafka安装及使用实例
1)下载安装包
Kafka的下载地址:https://kafka.apache.org/downloads

当前最新版本是:
kafka_2.11-2.3.1.tgz
kafka_2.12-2.3.1.tgz
这两个文件中2.11/2.12分别表示编译Kafka的Scala语言版本,后面的2.3.1是Kafka的版本。从稳定性上看Scala2.11版本编译的Kafka更好一些,所以我们可以下载kafka_2.11-2.3.1.tgz。
下载完成后上传到我们服务器上
2)安装
解压缩:
tar -zxvf kafka_2.11-2.3.1.tg
cd kafka_2.11-2.3.1
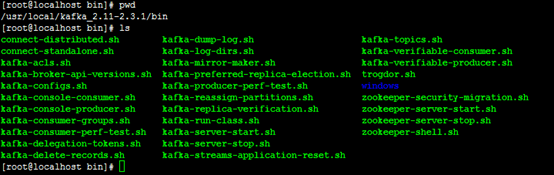
启动Kafka(启动之前首先应该安装JDK8)
Kafka解压缩后可以直接运行,进入可执行文件目录并查看可执行文件,如下图所示:
3)启动ZooKeeper
首先要启动ZooKeeper服务器(ZooKeeper是为Kafka提供协调服务的工具),
Kafka内置了一个ZooKeeper,可以直接启动:./zookeeper-server-start.sh …/config/zookeeper.properties
[2019-10-28 09:22:17,425] INFO Reading configuration from: ../config/zookeeper.properties (org.apache.zookeeper.server.quorum.QuorumPeerConfig)
[2019-10-28 09:22:17,437] INFO autopurge.snapRetainCount set to 3 (org.apache.zookeeper.server.DatadirCleanupManager)
[2019-10-28 09:22:17,437] INFO autopurge.purgeInterval set to 0 (org.apache.zookeeper.server.DatadirCleanupManager)
[2019-10-28 09:22:17,437] INFO Purge task is not scheduled. (org.apache.zookeeper.server.DatadirCleanupManager)
[2019-10-28 09:22:17,438] WARN Either no config or no quorum defined in config, running in standalone mode (org.apache.zookeeper.server.quorum.QuorumPeerMain)
[2019-10-28 09:22:17,487] INFO Reading configuration from: ../config/zookeeper.properties (org.apache.zookeeper.server.quorum.QuorumPeerConfig)
[2019-10-28 09:22:17,488] INFO Starting server (org.apache.zookeeper.server.ZooKeeperServerMain)
[2019-10-28 09:22:17,512] INFO Server environment:zookeeper.version=3.4.14-4c25d480e66aadd371de8bd2fd8da255ac140bcf, built on 03/06/2019 16:18 GMT (org.apache.zookeeper.server.ZooKeeperServer)
[2019-10-28 09:22:17,512] INFO Server environment:host.name=localhost (org.apache.zookeeper.server.ZooKeeperServer)
[2019-10-28 09:22:17,512] INFO Server environment:java.version=1.8.0_25 (org.apache.zookeeper.server.ZooKeeperServer)
…
[2019-10-28 09:22:17,586] INFO binding to port 0.0.0.0/0.0.0.0:2181 (org.apache.zookeeper.server.NIOServerCnxnFactory)当看到启动日志中出现0.0.0.0/0.0.0.0:2181时,基本上已经启动成功(使用端口2181)
4)启动kafka
接着启动Kafka服务器:启动命令:./kafka-server-start.sh …/config/server.properties
[2019-10-28 09:22:45,571] INFO Registered kafka:type=kafka.Log4jController MBean (kafka.utils.Log4jControllerRegistration$)
[2019-10-28 09:22:46,495] INFO Registered signal handlers for TERM, INT, HUP (org.apache.kafka.common.utils.LoggingSignalHandler)
[2019-10-28 09:22:46,497] INFO starting (kafka.server.KafkaServer)
[2019-10-28 09:22:46,499] INFO Connecting to zookeeper on localhost:2181 (kafka.server.KafkaServer)
[2019-10-28 09:22:46,547] INFO [ZooKeeperClient Kafka server] Initializing a new session to localhost:2181. (kafka.zookeeper.ZooKeeperClient)
…
[2019-10-28 09:22:50,272] INFO Kafka version: 2.3.1 (org.apache.kafka.common.utils.AppInfoParser)
[2019-10-28 09:22:50,273] INFO Kafka commitId: 18a913733fb71c01 (org.apache.kafka.common.utils.AppInfoParser)
[2019-10-28 09:22:50,273] INFO Kafka startTimeMs: 1572225770265 (org.apache.kafka.common.utils.AppInfoParser)
[2019-10-28 09:22:50,281] INFO [KafkaServer id=0] started (kafka.server.KafkaServer)启动日志中出现[KafkaServer id=0] started(kafka.server.KafkaServer)表示Kafka启动成功(服务端口默认为9092)
5)创建主题(topic)
Kafka启动成功后我们要创建一个主题(topic)用消息的发送与消费,以下日志创建一个名为test的主题,主题中只有一个分区(partition)和一个副本(replica)。
./kafka-topics.sh --create --zookeeper localhost:2181 --topic test --partitions 1 --replication-factor 1
主题创建成功后可以查看该主题状态:
6)查看主题(topic)
./kafka-topics.sh --describe --zookeeper localhost:2181 --topic test
[root@localhost bin]# ./kafka-topics.sh --describe --zookeeper localhost:2181 --topic test
Topic:test PartitionCount:1 ReplicationFactor:1 Configs:Topic: test Partition: 0 Leader: 0 Replicas: 0 Isr: 0``7)生产消息
Kafka提供了脚本攻击可以不断地接收标准输入并发送到指定的主题上。该脚本工具启动命令如下:
./kafka-console-producer.sh --broker-list localhost:9092 --topic test
`[root@localhost bin]# ./kafka-console-producer.sh --broker-list localhost:9092 --topic test
hello world!
this my first Kafka example;
``打开这个控制台后可以不断地输入字符形成消息,按回车键后该文本就会被发送。按Ctrl+C组合键退出。
8)消费消息
Kafka也提供了对应的脚本用户消费指定主题下的消息并打印到标准输出。
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning
`
[root@localhost bin]# ./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning
hello world!
this my first Kafka example;二、kafka设计思路要点
1、消息引擎系统

消息引擎系统用于在不同的应用间传输消息的系统,所以其他设计包含两个重要因素:消息设计、传输协议设计
消息设计:Kafka的消息是用二进制方式来保存的结构化消息;
传输协议设计:Kafka自定义一套二进制的消息传输协议;
2、消息引擎范型:
1)消息队列模型
基于队列提供消息传输服务,多用于进程/线程间通信。该模型定义了消息队列、发送者和接收者,提供了一种点对点的消息传递方式。典型示例:客服接电话

2)发布/订阅模型
定义了类似于生产者、消费者这样的角色及发布者和订阅者。发布者将消息生产出来发送到指定的主题中,所有订阅了该主题的订阅者都可以接收到该主题下的所有消息。典型示例:报纸订阅

Kafka同时支持这两种消息引擎范型,其设计初衷就是为了解决互联网公司超大量级数据的实时传输。
3、kafka高吞吐量、低延时的设计思路
Kafka设计之初就考虑了以下4个方面的问题,

Kafka做到高吞吐量、低延时的设计思路是:每次写入操作都只是把数据写入到操作系统的页缓存中,然后由操作系统自行决定什么时候把页缓存中的数据写回磁盘上。读取消息时会首先从OS的页缓存中读取,如果命中便把消息经页缓存直接发送到网络的Socket上(零拷贝技术)。
三、kafka使用场景
Kafka以消息引擎闻名,它特别适合处理生产环境中的那些流式数据,以下是其在实际应用中的一些典型使用场景。

小结:
本文介绍了kafka的基本概念,设计思路及其使用场景,需要深入理解kafka的同学可以去到网站http://kafka.apachecn.org/或者阅读《Apache kafka实战》;需要《Apache kafka实战》同学可以关注我们的微信公众号,回复“kafka”获取下载地址。