PL-SQL编程
1.PL/SQL的特点
-
PL(Procedure Language)/SQL)是Oracle在数据库中引入的一种过程化的编程语言。
-
PL/SQL是对SQL的扩充:具有为程序开发而设计的特性;
-
在PL/SQL 中可以使用变量,进行流程控制,来实现比较复杂的业务逻辑;
-
PL/SQL嵌入到Oracle服务器中的,可以把它看作Oracle服务器内的一个引擎,所以具有很高的执行效率。
2.PL/SQL程序结构

/
declaren number;result number;
beginn:=0; result:=0;while n<=100 loopresult:=result+n;n:=n+1;end loop;dbms_output.put_line('结果是'||result);
end;
/
set serveroutput on;//系统开关
保存
/
create or replace procedure sp_calcsum
asn1 number; result number;
beginn1:=0; result:=0;while n1<=100 loopresult:=result+n1;n1:=n1+1;end loop;dbms_output.put_line('结果是'||result);
end;
/
3.PL/SQL中特殊类型的变量
- [字段名]%TYPE 类型
声明一个与指定表的指定列的相同类型的变量,用于存放一个字段的值。 - [表名]%ROWTYPE 类型
声明一个与指定表的行结构相同的变量,用于存放一条记录。 - CURSOR 类型
声明一个表对象类型的变量,用于存放一个查询结果集。
注意:
1.在PL/SQL程序中, SELECT语句返回的数据是一行时,SELECT语句总是和INTO相配合,INTO后跟用于接收查询结果的变量,形式如下:
SELECT 列名1,列名2... INTO 变量1,变量2... FROM 表名 WHERE 条件;
2.当程序要接收返回的多行结果时,可以采用游标变量来存放。
✏例1:查询学号为“001101”的学生的学号与姓名。
set serveroutput on;
DECLARE
--说明这个stuno表的类型和xs.sno类型一样
stuno xs.sno%type;
stuname xs.sname%type;
BEGIN
--把sno,sname 放到 stuno,stuname 里
select sno,sname into stuno,stuname from xs where sno='001101';
DBMS_OUTPUT.put_line(stuno||stuname);
END;
/
✏例2:查询学号为“001101”的学生的信息。
set serveroutput on;
DECLARE
--说明这个stu表的类型和xs类型一样,可以保存一行的信息Stu xs%rowtype;
BEGIN
--返回一行select * into stu from xs where sno='001101';
--stu.sno stu.snme 引用 DBMS_OUTPUT.put_line(stu.sno||stu.sname);
END;
/
游标
游标(Cursor):用来查询数据库,获取记录集合(结果集)的指针,可以让开发者一次访问一行或多行结果集,在每条结果集上作操作。
游标是SQL的一个内存工作区,由系统或用户以变量的形式定义。游标的作用就是用于临时存储从数据库中提取的数据块。在某些情况下,需要把数据从存放在磁盘的表中调到计算机内存中进行处理,最后将处理结果显示出来或最终写回数据库。这样数据处理的速度才会提高,否则频繁的磁盘数据交换会降低效率。
1.游标的类型
CURSOR就是PL/SQL中的一种实现对表的对象化操作方法。一共分为两种:
显式游标: 当查询返回结果超过一行时,此时用户不能使用select into语句,就需要一个游标来处理结果集。
隐式游标:在执行SQL语句时,ORACLE系统会自动产生一个隐式游标,主要用于处理数据操纵语句(INSERT和DELETE语句)的执行结果,当使用隐式游标的属性时,在属性名前加上隐式游标的默认名SQL。
2.游标的定义
游标定义格式:CURSOR 游标名 is Select 语句 ;
显式游标有两种使用方式:
游标变量循环;
游标for循环。
游标变量循环格式:open 游标; loop fetch 游标 into 游标变量; -- 处理语句; exit when 游标%notfound; end loop; close 游标;
FOR循环格式:for 游标变量 in 游标 loop -- 处理语句; end loop;
- 游标变量
(1) %FOUND:布尔型,如果SQL语句至少影响一行数,则%FOUND等于true,否则等于false 。
(2) %NOTFOUND:布尔型,与%FOUND相反。
(3) %ROWCOUNT:整型,返回受SQL语句影响的行数。
(4) %ISOPEN:布尔型,判断游标是否被打开,如果打开%ISOPEN等于true,否则等于false。
🚩✏例1:查询所有学生的学号与姓名。(利用游标变量循环)
DECLARE--类 stu 类型是xs型stu xs%rowtype;--(select * from xs)返回一个集合(多个值)--返回的对象用一个游标变量cur_stu存储 cursor cur_stu is select * from xs;
BEGIN--打开这个游标变量cur_stuopen cur_stu;----用循环-----loop--每次提取cur_stu的一行,放入stu中fetch cur_stu into stu;--当cur_stu指到了表的最后 退出循环exit when cur_stu%notfound;--cur_stu没有指到了表的最后,输出此行的stu.sno,stu.sname DBMS_OUTPUT.put_line(stu.sno||stu.sname);end loop;--关闭游标close cur_stu;
END;
✏例2:查询所有学生的学号与姓名。(利用for循环)
DECLARE--定义一个游标cur_stucursor cur_stu is select * from xs;
BEGIN--for循环,每次取cur_stu的一行for stucur in cur_stu loop--输出DBMS_OUTPUT.put_line(stucur.sno||stucur.sname);end loop;
END;
----省略了游标定义,直接用(cur_stu is select * from xs)作为游标
BEGINfor stucur in select * from xs loopDBMS_OUTPUT.put_line(stucur.sno||stucur.sname);end loop;
END;
异常处理
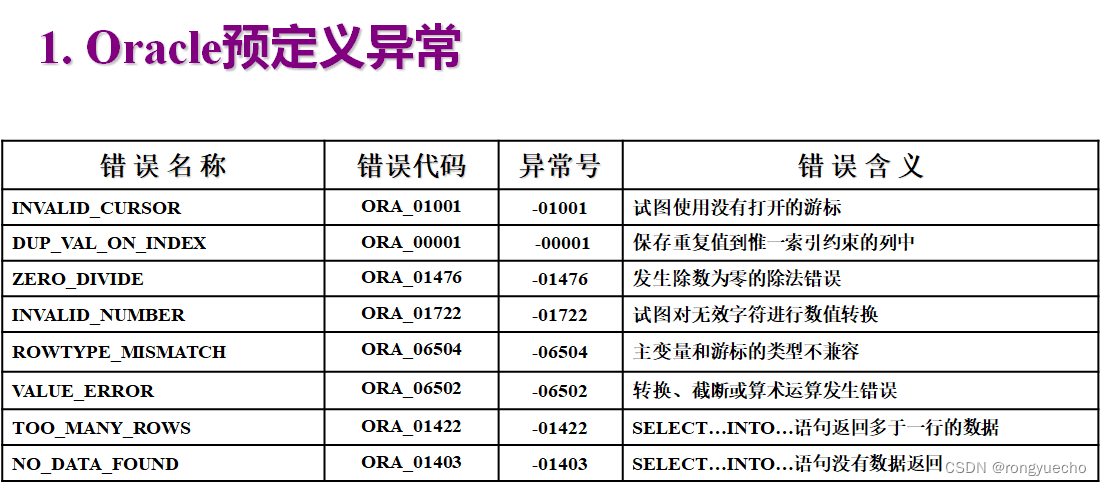
在编写PL/SQL程序时,避免不了会发生一些错误.对于出现的这些错误,ORACLE通常采用异常来处理,异常处理代码通常放在PL/SQL块的EXCEPTION代码块中,根据异常产生的机制和原理,可将ORACLE系统异常分为两大类:
1.预定义异常:
ORACLE系统自身为用户提供的,以便检查用户代码失败一般原因。
2.自定义异常:
用户自己定义的异常。
✏例1:查询学号为“001101”的学生的信息。
DECLAREstuno xs.sno%type;stuname xs.sname%type;
BEGIN--这句异常select sno,sname into stuno,stuname from xs ;DBMS_OUTPUT.put_line(stuno||stuname);EXCEPTIONWHEN no_data_found thendbms_output.put_line('数据没找到');--WHEN too_many_rows thendbms_output.put_line('结果集超过一行');
END;

✏例2:CJ表中的GRADE列不能插入NULL值。
DECLARE--定义新的 异常类型null_exp exception;stucj cj%rowtype;
BEGINstucj.sno:='001241'; stucj.cno:='206';--没有给stucj.grade赋值insert into cj values(stucj.sno,stucj.cno,stucj.grade);-- raise null_exp 抛出null_exp异常if stucj.grade is null then raise null_exp; end if;
EXCEPTIONWHEN null_exp thendbms_output.put_line('成绩不能为空值');--回滚rollback;WHEN others thendbms_output.put_line('其他异常');
END;
存储过程
存储过程和函数也是一种PL/SQL块,是存入数据库的PL/SQL块。但存储过程和函数不同于已经介绍过的PL/SQL程序,我们通常把PL/SQL程序称为无名块,而存储过程和函数是以命名的方式存储于数据库中的。其优点如下:
- 存储过程在服务器端运行,执行速度快;
- 确保数据库的安全性,只有被授权的用户或创建者本身才能执行存储过程;
- 简化输入;
- 可以重复执行.
函数
1.创建函数
create or replace function <函数名>(参数 数据类型,…)
as[变量声明;]
begin执行语句; [exception 错误处理部分]
end;
/
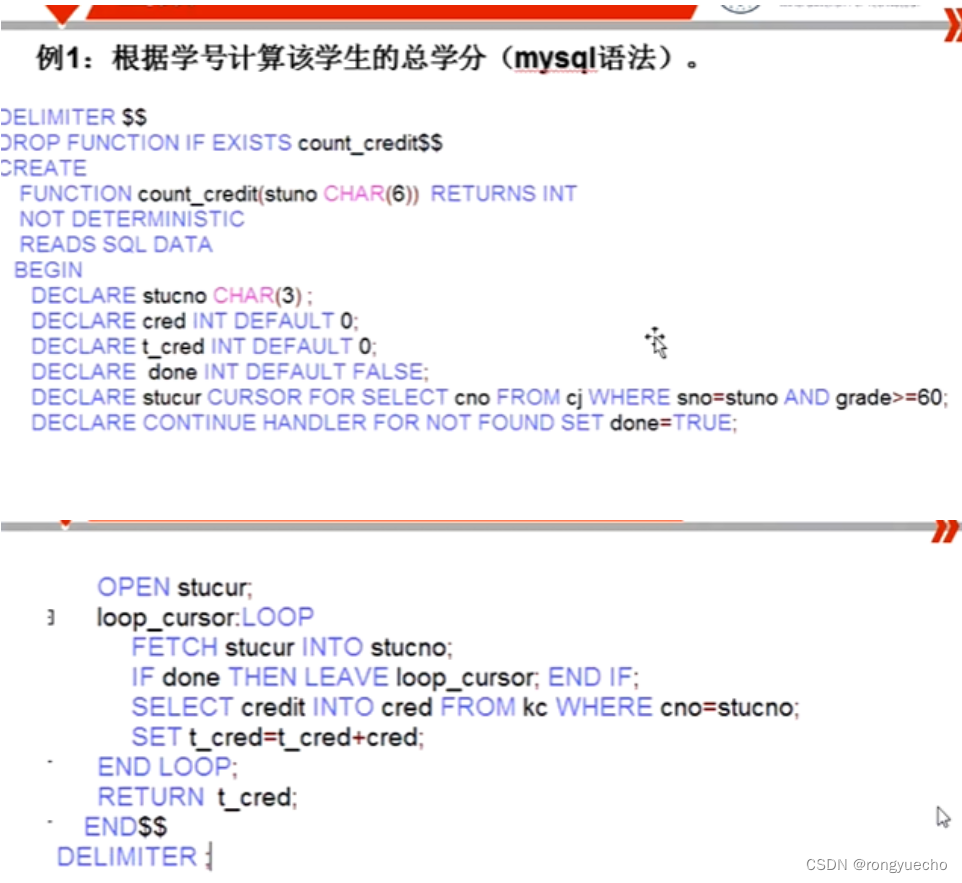
✏例1:根据学号计算该学生的总学分
分析:看这个学生修了那些课(课程表),找到每门的成绩(成绩表),成绩大于60才能拿到学分
(totalcredit 不应该 放在表的字段里,是多余的,因为他可以通过其他字段计算而来)
plsql:
--函数名count_Credit,形参stuno char(学号),返回值number(总学分)
create or replace function count_Credit(stuno char)return number
as
--变量声明:
cred number:=0;--用来存储每次循环取到的学分
total_cred number:=0;--存储累加学分
begin--定义一个游标把成绩表里相关的记录取出----where sno=stuno用参数找课程号(成绩表:学号,课程,成绩)for stucur in (select sno,cno,grade from cj where sno=stuno and grade>=60)loop--把此学分取出放在变量cred中(课程表:课程号,学分)select credit into cred from kc where cno=stucur.cno;--累加total_cred:=total_cred+cred;
end loopreturn total_cred;
end;
编译后,调用:
select sno,count_credit(sno) from xs;
更改:(一次只能改一条记录,效率低)
update xs set totalcredit('001101') where sno='001101';
mysql:(从对象进去)
储存过程
存储过程和函数的区别:
-
存储过程可以没有返回值,但是函数一定要有返回值
-
存储过程的参数可以是输入的和输出的,函数只有输入参数
in(输入)|out(输出)|in out(输入\输出)
-
调用方法不同,函数可直接调用
- 创建储存过程
create or replace procedure <过程名>(参数 [in|out|in out] 数据类型,…)
as[变量声明;]
begin执行语句; [exception 错误处理部分]
end;
✏例1:创建存储过程,利用count_Credit函数更新所有学生的总学分
CREATE OR REPLACE PROCEDURE PRO_COUNT_CREDIT AS
BEGINfor xs_cur in(select sno from xs)loopupdate xs set totalcredit=count_credit(xs_cur.sno)where sno=xs_cur.sno;end loop;
END PRO_COUNT_CREDIT;
编译后,调用执行储存:
execute pro_count_credit;

✏例2:根据学号计算该学生的学分绩
学分绩 = ∑ 学分 ∗ 成绩 总学分 学分绩=\sum{\frac{学分*成绩}{总学分}} 学分绩=∑总学分学分∗成绩
----储存过程名REPLACE PROCEDURE
--传入参数stuno(学号)传出参数creditj(学分绩)
CREATE OR REPLACE PROCEDURE PRO_COUNT_CREDITJ (STUNO IN VARCHAR2
, CREDITJ OUT NUMBER )
AScred number:=0;--学分toltal_cred number:=0; --学分和成绩相乘
BEGIN--游标 cjcurfor cjcur in (select sno,cno,grade from cj where stuno=sno and grade>=60)loop--从课程表得到学分select credit into cred from kc where cno=cjcur.cno;--学分*成绩:cred*cjcur.grade 总的学分*成绩: toltal_cred 每次累加toltal_cred:=toltal_cred+cred*cjcur.grade;end loop;--如果此人总学分小于零,计算会出错if count_credit(stuno)>0 thencreditj:=toltal_cred/count_credit(stuno);end if;
END PRO_COUNT_CREDITJ;
编译后,调用
execute PRO_COUNT_CREDITJ;
declare
--声明creditj用于存储输出学分绩
creditj number;
begin
--begin里面调用
PRO_COUNT_CREDITJ('001101',creditj);
--输出
dbms_output.put_line(creditj);
end;
-
执行存储过程
-
方法1:
EXECUTE 模式名.存储过程名[(参数1,…)];
-
方法2:
BEGIN模式名.存储过程名[(参数1,…)]; END;
触发器
-
触发器(Trigger)是一种特殊类型的存储过程。
-
触发器不同于存储过程。触发器主要是通过事件触发而被系统自动调用执行的,而存储过程是通过存储过程名字而被直接调用。
-
触发器通常是与基本表紧密联系在一起的,可以看作是基本表定义的一部分。触发器是在特定表上进行定义的,该表也称为触发器表。当有针对触发器表的操作时,例如,在表中插入(Insert)、删除(Delete)、修改(Update)数据时,那么触发器就自动触发执行。
- 触发器类型(本课程只介绍DML触发器)

2.触发器事件
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oCYJTRnU-1679588580364)(C:\Users\rongyu\AppData\Roaming\Typora\typora-user-images\image-20220412110813745.png)]](https://img-blog.csdnimg.cn/88e40fd6a14c43c0a26223d082745d85.png)
-
创建DML触发器
BEFORE|AFTER|INSTEAD OF(触发器在事件之前/之后/视图中定义前后)
on 表名:在哪个表上增删改查
[FOR EACH ROW]:改动每一行,触发器都要运行
CREATE [OR REPLACE] TRIGGER 触发器名 {BEFORE|AFTER|INSTEAD OF} 触发事件1 [OR 触发事件2...] ON 表名 WHEN 触发条件 [FOR EACH ROW] DECLARE 声明部分 BEGIN 主体部分 END [触发器名];
注意:
-
触发事件:插入(Insert)、删除(Delete)、修改(Update);
-
触发时机:事件前(before)、事件后(after);
-
.触发级别:表级(默认)、行级(for each row)针对每一行
-
触发器表:新记录表(new) 旧记录表(old):
插入:新记录→ (:new) ;
删除:原记录→ (:old);
修改:新记录→ (:new) 、原记录→ (:old)
-
触发器中谓词:INSERTING、DELETING和UPDATING,它们实际上是触发器中的3个内部逻辑变量,用于判断事件类型。
✏例1:在STUDENT方案中创建一个保存操作日志的表cj_log,用于记录对成绩表所做的增、删、改操作。
--日志表
create table cj_log(operate_type varchar2(20),--操作类型(增删改)operate_date date,--操作执行的时间operate_user varchar2(20)--执行操作的用户
);
--创建触发器tri_cj
----在触发事件 DELETE OR INSERT OR UPDATE 之后触发
----ON cj 在成绩表上操作
CREATE OR REPLACE TRIGGER TRI_CJ AFTER DELETE OR INSERT OR UPDATE ON cjfor each row--每一行
declareoperate_type varchar2(20);
BEGIN--operate_type: 操作类型声明变量 if语句获得--operate_date: 操作时间为当前时间sysdate--operate_user: 操作用户为系统变量获取的用户ora_login_userif deleting then operate_type:='删除操作';elsif updating then operate_type:='修改操作'; elsif inserting then operate_type:='插入操作';end if;insert into cj_log values(operate_type,sysdate,ora_login_user);
END;
编译后,调用
--显示一些两个表看看
select * from cj;
select * from cj_log;
--删,改,插
delete from cj where sno='001101';
update cj set grade=80 where sno='001102';
insert into cj valuse('001101','101',90);
✏例2:创建一个删除触发器,对xs表进行删除操作,删除一个xs表中的学生,则删除cj表中对应学号的所有记录。
前提:成绩表是根据学生表定义级联
相当于级联删除在学生表上操作,删除成绩表
在delete on xs这个delete之前就调用触发器,因为要先删除成绩表的信息,才能删除学生表的信息。
create or replace trigger tri_del_cj before delete on xsfor each row
begin--待删除的那条记录临时存放在old表中delete from cj where sno=old.sno;
end;
调用:
delete from xs where sno='001241';
✏练习:根据图书借阅关系,存在图书表、学生表、借阅表,当借阅表中插入一条新的记录(即图书表中借出一本图书),把图书表中的图书状态更改为“借出”;当更新借阅表中的归还日期时(即图书归还了),把图书表中的图书状态更改为“在馆”,使用触发器实现。
分析:在lendbook表中操作,去触发一个动作——修改book表中的state
先创建三个表,插入语句:
----------------图书表-------------------------
create table Book(bookid number(10) primary key,bookname varchar2(50),states varchar2(20)
);
--状态有‘在馆,,借出,丢失’
insert into book values(1112221111,'java程序设计','在馆');
insert into book values(1112221112,'vb程序设计','在馆');
-------------学生表---------------------------------
create table Student(stuid number(10) primary key;stuname varchar2(50)
);
insert into student values(169074264,'刘韩');
insert into student values(169074108,'李萌萌');
-------------借阅表--------------------------
create table booklend(
lendid number(10) primary key,stuid number(10) not null,bookid number(10) not null,lenddate date,returndate date
);
-------------顺序填写借阅表lendid-----------------
create sequence lendid_seq
start with 1 --从1开始
increment by 1 --每次增加1
maxvalue 9999999999 --最大
cycle; --循环(最大值用完之后,再从1开始)
插入操作的触发器——更改book.state为‘借出’
create or replace trigger lend_trig after insert on booklend for each row
beginupdate book set states='借出' where bookid=:new.bookid;
end;
更新操作的触发器——更改book.state为‘在馆’
create or replace trigger return_tring before update on booklendfor each row
beginupdate book set states='在馆' where bookid=:old.bookid;--用new也可以
end;
编译后调试
insert into booklend values(lendid_seq.nextval,'169074264','1112221111',sysdate,null);update booklend set returndate=sysdate where stuid='169074264' and bookid='1112221111'; pragma autonomous_transaction
编译自治性事务,子事务不会影响主事务,子事务也不影响主事务;主事务和子事务互相独立,互不影响;
主事务中如果有未提交的数据,子事务中无法查询到;同时,子事务提交,不影响主事务,事务依然需要提交;
自治事务的特点
第一,这段程序不依赖于原有Main程序,比如Main程序中有未提交的数据,那么在自治事务中是查找不到的。
第二,在自治事务中,commit或者rollback只会提交或回滚当前自治事务中的DML,不会影响到Main程序中的DML。