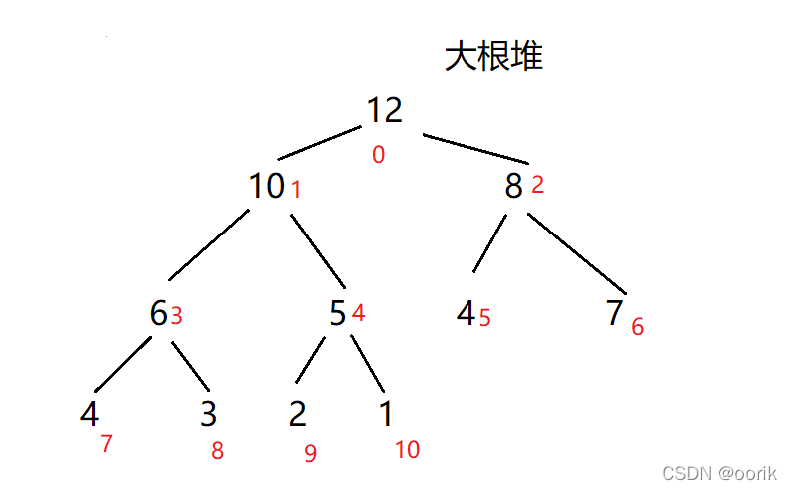
什么是堆
堆是一种叫做完全二叉树的数据结构,可以分为大根堆,小根堆,而堆排序就是基于这种结构而产生的一种程序算法。
堆的分类
大根堆:每个节点的值都大于或者等于他的左右孩子节点的值
小根堆:每个结点的值都小于或等于其左孩子和右孩子结点的值
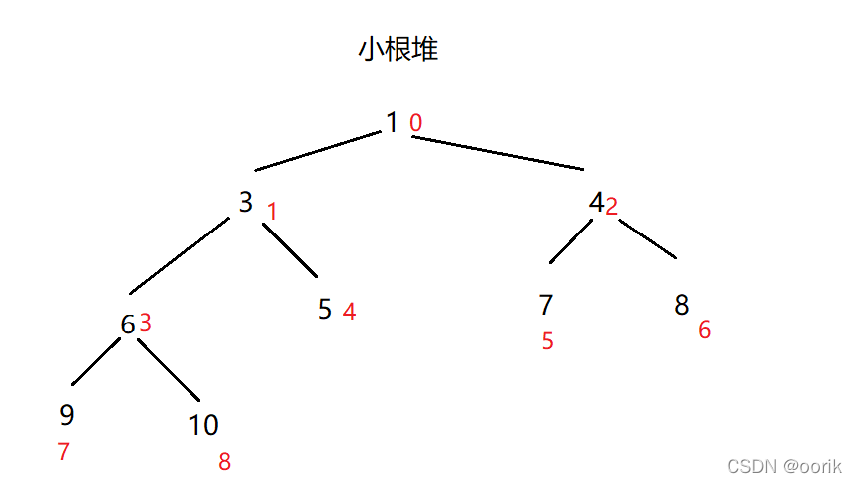
两种结构映射到数组为:
大根堆:
小根堆:
//父-->子:i--->左孩子:2*i+1, 右孩子:2*i+2;
//子-->父:i--->(i-1)/2; (i为下标元素)
排序思想
1.首先将待排序的数组构造成一个大根堆,此时,整个数组的最大值就是堆结构的顶端
2.将顶端的数与末尾的数交换,此时,末尾的数为最大值,剩余待排序数组个数为n-1
3.将剩余的n-1个数再构造成大根堆,再将顶端数与n-1位置的数交换,如此反复执行,便能得到有序数组
注意:升序用大根堆,降序就用小根堆(默认为升序)
构造堆
那么如何构造大根堆呢?


首先我们给定一个无序的序列,将其看做一个堆结构,一个没有规则的二叉树,将序列里的值按照从上往下,从左到右依次填充到二叉树中。
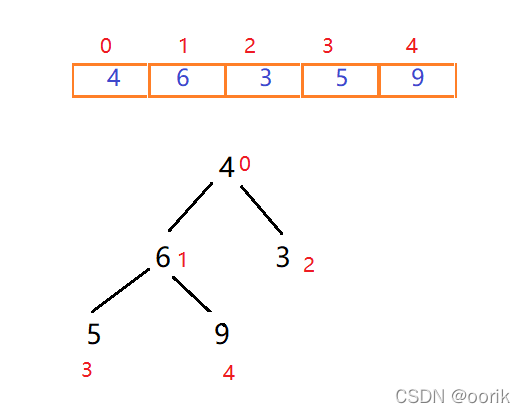
对于一个完全二叉树,在填满的情况下(非叶子节点都有两个子节点),每一层的元素个数是上一层的二倍,根节点数量是1,所以最后一层的节点数量,一定是之前所有层节点总数+1,所以,我们能找到最后一层的第一个节点的索引,即节点总数/2(根节点索引为0),这也就是第一个叶子节点,所以第一个非叶子节点的索引就是最后一个叶子结点的索引-1。那么对于填不满的二叉树呢?这个计算方式仍然适用,当我们从上往下,从左往右填充二叉树的过程中,第一个叶子节点,一定是序列长度/2,所以第最后一个非叶子节点的索引就是 arr.len / 2 -1,对于此图数组长度为5,最后一个非叶子节点为5/2-1=1,即为6这个节点
那么如何构建呢? 我们找到了最后一个非叶子节点,即元素值为6的节点,比较它的左右节点中最大的一个的值,是否比他大,如果大就交换位置。
在这里5小于6,而9大于6,则交换6和9的位置
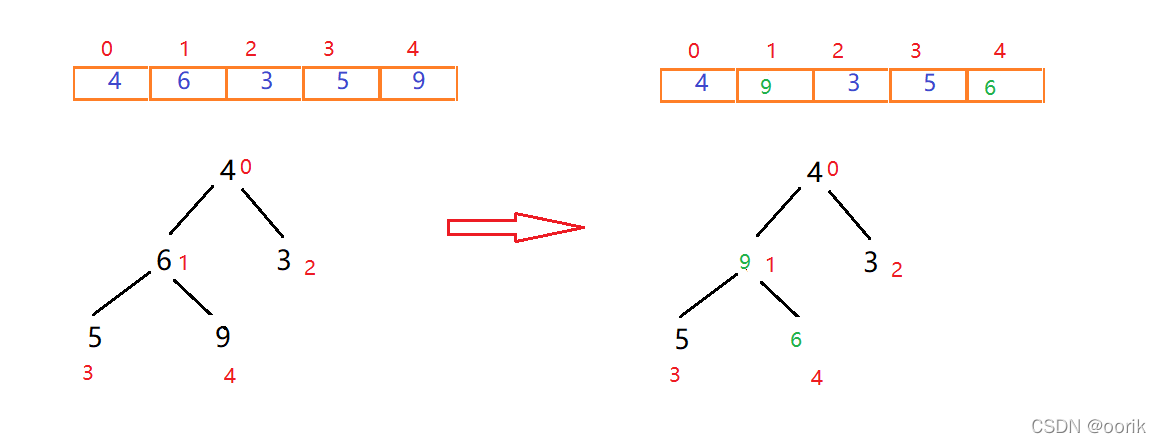
找到下一个非叶子节点4,用它和它的左右子节点进行比较,4大于3,而4小于9,交换4和9位置
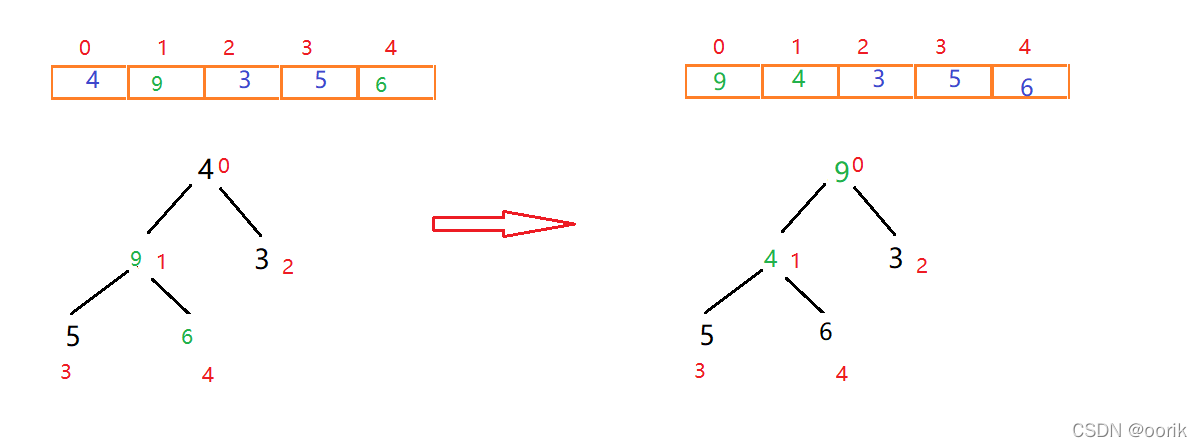
此时发现4小于5和6这两个子节点,我们需要进行调整,左右节点5和6中,6大于5且6大于父节点4,因此交换4和6的位置
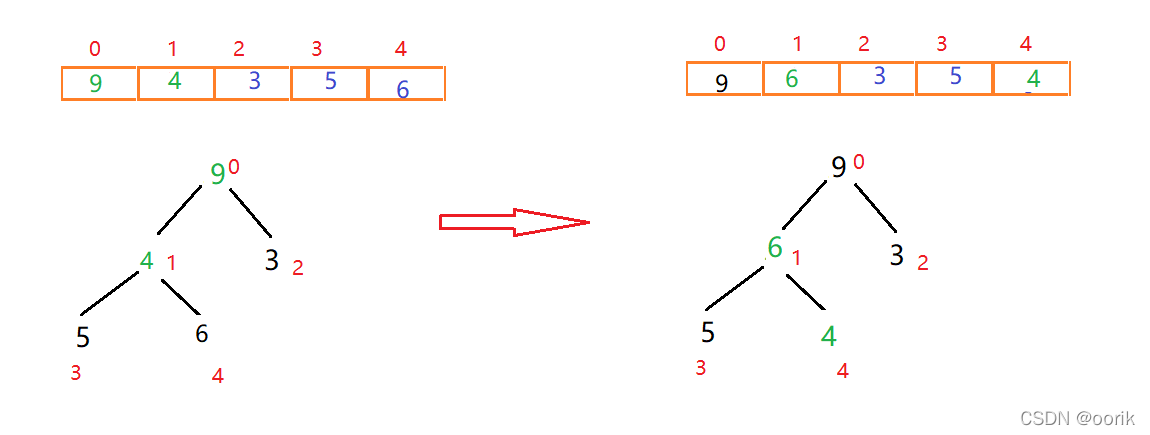
此时我们就构造出来一个大根堆,下来进行排序
首先将顶点元素9与末尾元素4交换位置,此时末尾数字为最大值。排除已经确定的最大元素,将剩下元素重新构建大根堆
一次交换重构如图: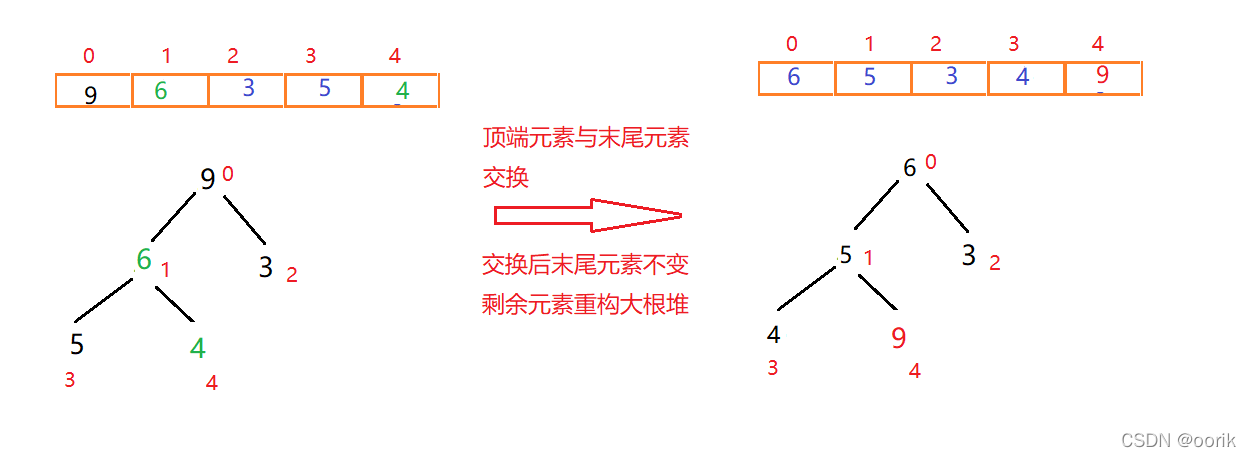
此时元素9已经有序,末尾元素则为4(每调整一次,调整后的尾部元素在下次调整重构时都不能动)
二次交换重构如图:
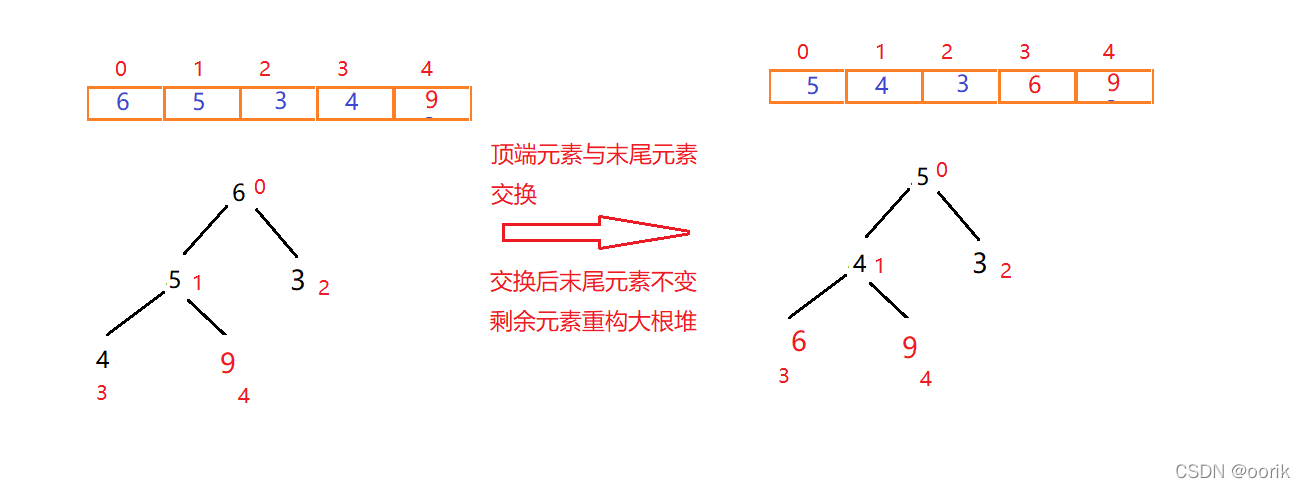
最终排序结果:
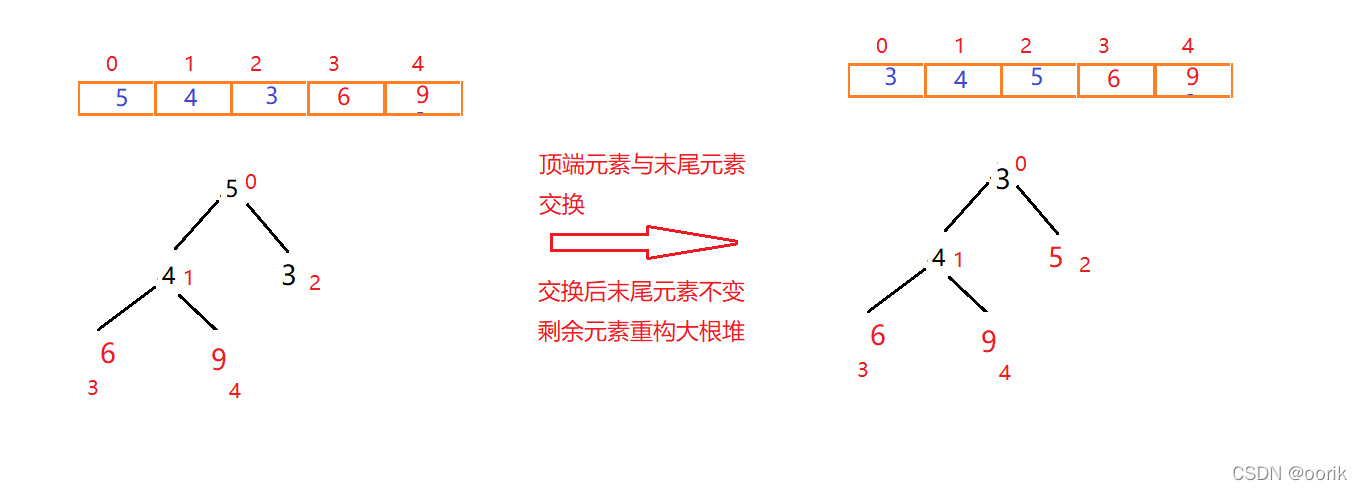
由此,我们可以归纳出堆排序算法的步骤:
1. 把无序数组构建成二叉堆。
2. 循环删除堆顶元素,移到集合尾部,调节堆产生新的堆顶。
当我们删除一个最大堆的堆顶(并不是完全删除,而是替换到最后面),经过自我调节,第二大的元素就会被交换上来,成为最大堆的新堆顶。
正如上图所示,当我们删除值为9的堆顶节点,经过调节,值为6的新节点就会顶替上来;当我们删除值为6的堆顶节点,经过调节,值为5的新节点就会顶替上来.......
由于二叉堆的这个特性,我们每一次删除旧堆顶,调整后的新堆顶都是大小仅次于旧堆顶的节点。那么我们只要反复删除堆顶,反复调节二叉堆,所得到的集合就成为了一个有序集合,
堆排序是不稳定的排序,空间复杂度为O(1),平均的时间复杂度为O(nlogn),最坏情况下也稳定在O(nlogn)
代码示例:
void HeapAdjust(int* arr, int start, int end)
{int tmp = arr[start];for (int i = 2 * start + 1; i <= end; i = i * 2 + 1){if (i < end&& arr[i] < arr[i + 1])//有右孩子并且左孩子小于右孩子{i++;}//i一定是左右孩子的最大值if (arr[i] > tmp){arr[start] = arr[i];start = i;}else{break;}}arr[start] = tmp;
}
void HeapSort(int* arr, int len)
{//第一次建立大根堆,从后往前依次调整for(int i=(len-1-1)/2;i>=0;i--){HeapAdjust(arr, i, len - 1);}//每次将根和待排序的最后一次交换,然后在调整int tmp;for (int i = 0; i < len - 1; i++){tmp = arr[0];arr[0] = arr[len - 1-i];arr[len - 1 - i] = tmp;HeapAdjust(arr, 0, len - 1-i- 1);}
}
int main()
{int arr[] = { 9,5,6,3,5,3,1,0,96,66 };HeapSort(arr, sizeof(arr) / sizeof(arr[0]));printf("排序后为:");for (int i = 0; i < sizeof(arr) / sizeof(arr[0]); i++){printf("%d ", arr[i]);}return 0;
}
排序结果:

路过有帮助麻烦点个赞再走!博主画图不容易┭┮﹏┭┮
2022/11/19 补充
这篇文章写的也挺早的了,今天抽空重新补充一下,因为很多朋友私信我说是没看懂或者怎么样的,(写的早,文笔表达确实有限)。我今天就再拿文字和简单的图把思路说一下,补充的我按照构建小顶堆,就是从大到小排序一组数字。也有很多朋友问啊大根堆构建出来堆顶是最大的元素,你最后排序输出可又是从小到大,问出这些问题就说明你没有好好看步骤。
再提一嘴,像数据结构优先队列这种他底层就是按照大根堆的方式去实现的,top返回的是最大值,排序取出优先级最高的,是一个降序队列
补充:
理解堆排序,他其实就是对于一组数去进行排序(这里放在数组里),而我们所说的大根堆,小根堆都是逻辑上的让我们去理解排序算法,千万别混为一谈迷糊了
还是这么一组无序的数字,我们把它逻辑构造成一个完全二叉树
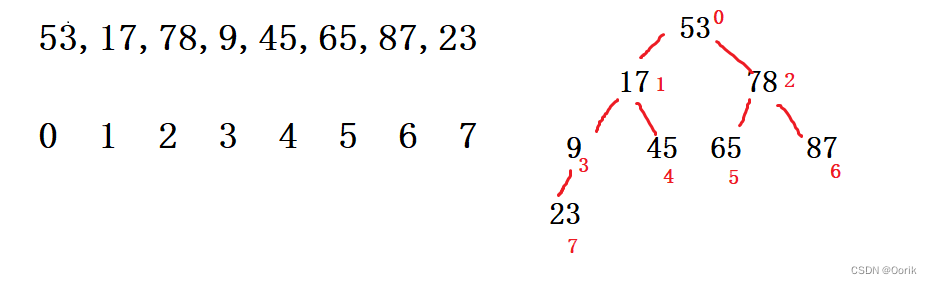
我们这里按照从大到小排序,构建小根堆的大致思路来说
我们堆排序的步骤就是这样
先把这个最初的堆去 给他构建成一个小根堆,所谓小根堆就是堆顶元素最小
注意构建的时候就需要我们找分支结点,我最上面提到的那数学公式,我们从这个分支结点开始把它的父结点这么一个小树弄成小根堆,再往上跳,从他的父结点开始,找双亲把他们这一部分调整成最小堆。依次类推,说白了就是从下面局部构成小根堆,一点一点,最后整体全局构建小顶堆。这样构建之后你全局的堆顶才是最小的一个元素,这才是所谓的完整的一次构建。体现在数组上就是你数组首元素现在是最小的,因为你堆顶就代表着0号下标元素不是。(大根堆就是上面元素是最大的而已,怎么构建还都是一样啊,就是把大元素往上覆盖,判断条件变了而已)
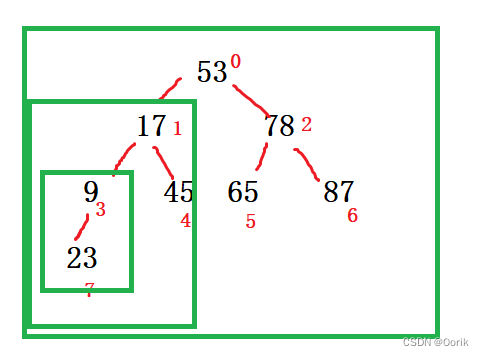
现在你首元素最小了,说明逻辑上就是个小根堆了,你是怎么倒叙呢?不就是首元素和尾元素交换。然后你数组最后面不就成了最小的(这是体现在数组上的),那么同样体现在此时这个小根堆上,就是把堆顶元素和尾巴一交换。
那为什么每次交换完,需要我尾巴元素不能动,去构建剩余元素呢?你每构建完一次小根堆,交换元素,你此时在数组上是不是把最小的元素放在末尾了,说明已经确定了,那我们就不需要动了,我们要动的就是数组那些没确定的元素,在这些里面去找一个最小的。那么这一步体现在堆上,是不是需要我们重新再除了尾巴元素以外剩下结点上从局部到整体去构建小根堆了。
再一次构建,是不是这里面最小的跑到堆顶了(数组里就是最小的跑到了首元素位置),再去交换首元素和没有排好序的这一段数组的最后一个下标位置,交互完了再重构.....
举个例子,6,2,1,4 这么一组数我们第一次构建小根堆之后,1就跑到了堆顶,也就是跑到了数组首元素1,数组此时为1 * * *,和最后一个元素交换,就成了* * * 1,那么这个时候1就已经确定了,我们下来要做的是把* * *这三个构建出一个小根堆,这三个里最小的放在首元素,
比方说是2 * * 1,我们交换2和这次没确定的数组最后一个元素,成了* * 2 1,此时2 和1已经确定了,我们再去剩下两个* *去构建,去交换,最后得到 6 4 2 1
还是这三步:
- 把无序的这一串数,想象成一个堆,根据要求去从局部到整体构建一个大顶堆或者小顶堆,我们要的就是此时这个堆顶元素
- 把堆顶元素和末尾元素交换,就是把堆顶元素(数组首元素)换到了数组的末端
- 重新调整除了数组末端(已经确定顺序的元素)以外的元素,去构建堆,然后交换堆顶和当前末尾,构建,交换堆顶和当前末尾..
给个小根堆的测试代码
void FF(vector<int>& nums, int start, int end)//构建最小堆
{int i = start, j = 2*i+1;int tmp = nums[i];while (j<=end){if (j < end&& nums[j] > nums[j + 1]) j += 1;if (tmp <= nums[j])break;nums[i] = nums[j];i = j;j = i * 2 + 1;}nums[i] = tmp;
}
void SortFF(vector<int>&nums, int n)//堆排序
{//if ( nums.size()==0||n < 2)return;int pos = (((n - 1) - 1) / 2);while (pos >= 0)//从下往上局部,最后整体去调整成小顶堆{FF(nums, pos,n - 1);pos-=1;}//调整完了此时这个二叉堆最上面就是最小的数//在数组里就是一顿调整之后,第一个元素是最小的pos = n - 1;//让pos指向数组最后一个位置while (pos > 0){swap(nums[0], nums[pos]);//交换第一个元素和pos指向的位置第一次完了之后,最小元素就在数组最后pos-=1; //让pos指向数组往前一个位置,相当于最后一个元素是最小的已经确认FF(nums,0,pos);//那么就是开始重新调整除过已经确认元素剩下那一段数组元素//这下又把这一段数组里面最小的放在堆顶//再次进入循环,去交换位置 }
}int main()
{vector<int>vv{53,17,78,9,45,65,87,23};SortFF(vv,vv.size());for (auto const& x : vv) {cout << x << " ";}return 0;
}
就到这里了,我用大白话把整个过程描述了一遍