《数据库原理与运用》上机实验之SPJ
- 前言
- 一、关系模式
- 二、使用SQL语句创建、修改基本表
- 1.对基本表字段名的增加
- 2.对基本表字段名的增加
- 3.索引
- 二、使用SQL语句对数据库表的单表查询
- 1.对指定列的查询
- 2.对表达式计算和改变表达方式的查询
- 3.消除重复行的查询
- 4.WHERE条件查询
- 5.分组查询和排序查询
- 6、实验内容
- 三、利用SQL语句对数据库表的多表查询
- 1、多表间的联接查询和合并查询
- 2、多个SELECT语句的嵌套查询
- 3、实验内容
- 总结
前言
因为最近上机课老师把【数据库的建立与维护】、【创建数据库表及其索引】、【单表查询】、【多表查询】都过了一遍,但是脑子里还是乱乱的,于是整理了这份笔记,便于今后的整理与复习。主要内容是单表和多表的查询。
提示:以下个人上课笔记整理,仅供参考。若有误,期待广大网友的批评指正~
一、关系模式
接下来的所有操作都是针对该数据进行处理操作:




在建立表时一定要注意先后顺序,例如,若你先建立SPJ表,会出现外键调用出错(因为S,P,J这三个表并没有建立,无法调用外键),但是也可以先选择部分执行,外键操作后选择并执行的方式。以防出错,代码顺序尽可能保持一致。
建立表格代码如下:
CREATE DATABASE SPJ;USE SPJ;CREATE TABLE S(SNO VARCHAR(10) PRIMARY KEY,SNAME NVARCHAR(100) NOT NULL,SADDR NVARCHAR(100),
);
CREATE TABLE P(PNO VARCHAR(10) PRIMARY KEY,PNAME NVARCHAR(100) NOT NULL,COLOR NCHAR(1),WEIGHT INT,
);
CREATE TABLE J(JNO VARCHAR(10) PRIMARY KEY,JNAME NVARCHAR(100) NOT NULL,JCITY NVARCHAR(50),BALANCE DECIMAL(10,2),
);
CREATE TABLE SPJ(SNO VARCHAR(10),PNO VARCHAR(10),JNO VARCHAR(10),PRICE DECIMAL(10,2),QTY INT,PRIMARY KEY(SNO,PNO,JNO),FOREIGN KEY(SNO) REFERENCES S(SNO),FOREIGN KEY(PNO) REFERENCES P(PNO),FOREIGN KEY(JNO) REFERENCES J(JNO),
);
注意:not null 指该属性值不可为空,可以根据题目的需要来修改约束条件。
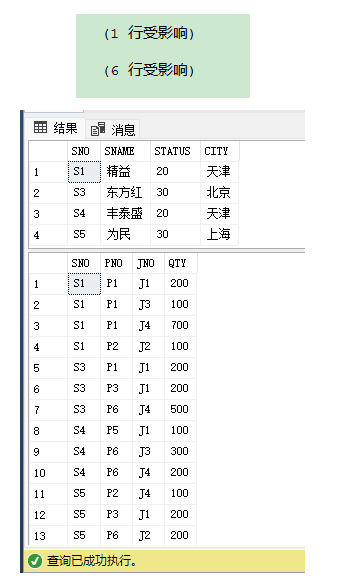
下面是插入表格数据代码,内容如图所示:
INSERT INTO S VALUES('S1','原料公司','南京北门23号')
INSERT INTO S VALUES('S2','红星钢管厂','上海浦东100号')
INSERT INTO S VALUES('S3','零件制造公司','南京东晋路')
INSERT INTO S VALUES('S4','配件公司','江西上饶58号')
INSERT INTO S VALUES('S5','原料厂','北京红星路88号')
INSERT INTO S VALUES('S8','东方配件厂','天津叶西路')INSERT INTO P VALUES('P1','钢筋','黑','25')
INSERT INTO P VALUES('P2','钢管','白','26')
INSERT INTO P VALUES('P3','螺母','红','11')
INSERT INTO P VALUES('P4','螺丝','黄','12')
INSERT INTO P VALUES('P5','齿轮','红','18')INSERT INTO J VALUES('J1','东方明珠','上海','0.00')
INSERT INTO J VALUES('J2','炼油厂','长春','-11.20')
INSERT INTO J VALUES('J3','地铁三号','北京','678.00')
INSERT INTO J VALUES('J4','明珠线','上海','456.00')
INSERT INTO J VALUES('J5','炼钢工地','天津','123.00')
INSERT INTO J VALUES('J6','南浦大桥','上海','234.70')
INSERT INTO J VALUES('J7','红星水泥厂','江西','343.00')INSERT INTO SPJ VALUES('S1','P1','J1','22.60','80')
INSERT INTO SPJ VALUES('S1','P1','J4','22.60','60')
INSERT INTO SPJ VALUES('S1','P3','J1','22.80','100')
INSERT INTO SPJ VALUES('S1','P3','J4','22.80','60')
INSERT INTO SPJ VALUES('S3','P3','J5','22.10','100')
INSERT INTO SPJ VALUES('S3','P4','J1','11.90','30')
INSERT INTO SPJ VALUES('S3','P4','J4','11.90','60')
INSERT INTO SPJ VALUES('S4','P2','J4','33.80','60')
INSERT INTO SPJ VALUES('S5','P5','J1','22.80','20')
INSERT INTO SPJ VALUES('S5','P5','J4','22.80','60')
INSERT INTO SPJ VALUES('S8','P3','J1','13.00','20')
INSERT INTO SPJ VALUES('S1','P3','J6','22.80','6')
INSERT INTO SPJ VALUES('S3','P4','J6','11.90','6')
INSERT INTO SPJ VALUES('S4','P2','J6','33.80','8')
INSERT INTO SPJ VALUES('S5','P5','J6','22.80','8')
注意:插入表格时也要注意先后顺序!
二、使用SQL语句创建、修改基本表
1.对基本表字段名的增加
在基本表S中增加一个联系电话(TELE)属性
代码如下(示例):
ALTER TABLE S ADD TELE CHAR(13)
执行效果图:(红色部分则是刚刚所加字段,因为未进行赋值,默认null)

2.对基本表字段名的增加
在基本表S中删除联系电话(TELE)属性
代码如下(示例):
ALTER TABLE S DROP COLUMN TELE
执行后,刚刚添加的字段【TELE】就会被删除
3.索引
创建索引的语句一般格式为:
CREATE [UNIQUE] [CLUSTERED| NONCLUSTERED] INDEX < 索引名> ON {< 表名>| <视图名 >} (<列名 > [ASC|DESC ] [ ,…n])
其中,UNIQUE指唯一索引,CLUSTERED指聚集索引,NONCLUSTERED指非聚集索引
索引可以建在该表或视图的一列或多列上,各列名之间用逗号分隔,每个列名后面还可以用次序指定索引值的排列次序(ASC升序,DESC降序)
例:对SPJ表作非聚集索引,其中,SNO作降序排列,PNO和JNO作升序排列
代码如下:
CREATE NONCLUSTERED INDEX SPJ_SNO_PNO_JNO ON SPJ(SNO DESC,PNO ASC,JNO ASC)
删除索引:运用DROP关键字
DROP INDEX SPJ_SNO_PNO_JNO ON SPJ(SNO DESC,PNO ASC,JNO ASC)
二、使用SQL语句对数据库表的单表查询
查询是数据库应用的核心内容,sql中运用SELECT进行查询
1.对指定列的查询
例:查询零件全部信息
代码如下:
SELECT * FROM S
其中【*】是指所有的字段名,等价于:
SELECT SNO,SNAME,SADDR FROM S
2.对表达式计算和改变表达方式的查询
目标表达式中各个列的先后顺序可以与表中的顺序不一致。也就是说,用户在查询时可以根据需要改变列的显示顺序。(这里不做演示)
此外,SELECT子句的目标列表不仅可以是表中的属性列,也可以是有关表达式。
例:将价格作为【原价】列输出,QTY作为【折扣后数量】输出(随意例子并无含义)
代码如下:
SELECT PRICE AS 原价,0.8*QTY AS 折扣后数量 FROM SPJ
(as可以省略不写)
运行结果如图:

3.消除重复行的查询
在SELECT查询语句中,第一行有ALL|DISTINCT选择,ALL表示对所有行查询,默认状态;DISTINCT查询后会取消重复的行。
例如:
1、查询所有零件的零件编号
代码如下:
SELECT DISTINCT SNO FROM SPJ
运行结果如图:

倘若不加DISTINCT,默认为ALL
SELECT SNO FROM SPJ
结果输出如下:

显然,第二个图的结果并不是我们想要的,重复行太多。可见DISTINCT在统计方面很重要
4.WHERE条件查询
查询满足指定条件的记录可以通过WHERE子句来实现。WHERE子句常用的查询条件如图所示:

5.分组查询和排序查询
*分组查询:*GROUP BY子句可以将查询结果表的各行按一列或多列取值相等的原则进行分组,查询结果分组的目的是为了**细化集函数的作用对象。**如果分组后还要求按一定的条件对这些分组进行筛选,则可以使用HAVING短句指定筛选条件。
注意:HAVING条件是指分组后要求设定的条件,而WHERE是指对查询表(或多个表)内所有内容设定的条件。
*排序查询:*通过ORDER BY子句指定一个或多个字段值的升序(ASC)或降序(DESC)重新排列查询结果。(默认升序)
6、实验内容
1、查询工程为J1的供应商数、提供零件的最大数量,最少数量及平均数量。
代码如下:
SELECT COUNT(JNO)供应商数 ,MAX(QTY)最大数量,MIN(QTY)最小数量,AVG(QTY)平均数量
FROM SPJ
WHERE JNO='J1'
注意:此处省略了AS
2、查询供应零件给工程J1,且零件编号为P1的供应商编号SNO。
代码如下:
SELECT SNO FROM SPJ
WHERE JNO='J1' AND PNO='P1'
3、查询上海的供应商名称,假设供应商关系的SADDR列都以城市名开头。
代码如下:
SELECT SNAME FROM S
WHERE SADDR LIKE '上海%'
4、查询使用零件数量在100~1000的工程编号、零件号和数量。
代码如下:
SELECT JNO,PNO,QTY
FROM SPJ
WHERE QTY BETWEEN 100 AND 1000
5、查询给出三个以上(包含三个)工程,供贷的供应商号及提供的工程数(注意提供一个工程多种零件,可算作多个工程)。
代码如下:
SELECT DISTINCT SNO, COUNT(JNO)
FROM SPJ
GROUP BY SNO HAVING COUNT(JNO)>=3
运行结果如图:

6、查询没有正余额的工程编号、名称以及城市,结果按工程编号升序排列。
代码如下:
SELECT JNO,JNAME,JCITY
FROM J
WHERE BALANCE <= 0
ORDER BY JNO
三、利用SQL语句对数据库表的多表查询
1、多表间的联接查询和合并查询
联接查询:若一个查询同时涉及两个或两个以上的表,则称为联接查询。
按照它们的联接方式的不同可以分为等值与非等值联接、自身联接、外联接、合并联接等几种。
- 等值联接与非等值联接:如之前所学关系代数操作方法执行。

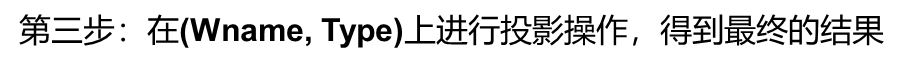

在SQL语言中,一般格式为:
表名1.列名1 <比较运算符> 表名2.列名2
当联接运算符为“=”时,称为等值联接,反之为非等值联接。
- 自然联接:表与自己进行联接。
- 外联接:为了保存没条件联接的本来要删除的记录信息。
外联接符号:FULL[OUTER] JOIN
左外联接符号:LEFT[OUTER] JOIN
右外联接符号:RIGHT[OUTER] JOIN
- 合并查询: 合并查询结果使用UNION操作符将来自不同查询数据组合起来,形成一个具有综合信息的查询结果。UNION会自动将重复的数据剔除。必须注意的是,参加合并查询结果的各子查询使用的表结构应该相同,即各子查询的数据数目相同,对应的类型要相容。
2、多个SELECT语句的嵌套查询
带有IN谓词的子查询
基本语法:
表达式[not] in (子查询)
语法中,表达式的最简单形式就是列名或常数。该语义是判断某一表达式的值是否在子查询结果中。
带有比较运算符的子查询
基本语法:
表达式 θ some (子查询)
表达式 θ all (子查询)
语法中, θ是比较运算符: < , > , >= , <= , = , <>。语义是将表达式的值与子查询的结果进行比较:
· 如果表达式的值至少与子查询结果的 某一个值 相比较满足θ 关系,则“表达式θ some (子查询)”的结果便为真;
· 如果表达式的值与子查询结果的所有值相比较 都 满足θ 关系,则“表达式θ all (子查询)”的结果便为真;
注意:
当“表达式=some(子查询)”时,
相当于“表达式 in (子查询)“
但是not in 和“<> some“含义不同,not in 对应“<>all”
带有EXISTS谓词的子查询
基本语法:
[not] EXISTS(子查询)
语义是子查询中有无元组存在。exists表示( )内子查询语句返回结果不为空说明where条件成立就会执行主sql语句,如果为空就表示where条件不成立,sql语句就不会执行。
然而 not Exists 却可以实现很多新功能
not exists和exists相反,子查询语句结果为空,也就是不符合条件的则表示where 条件成立,执行sql语句
3、实验内容
1、求使用了P3零件的工程全称
代码如下:
SELECT DISTINCT JNAME
FROM J,SPJ
WHERE SPJ.PNO = 'P3' AND SPJ.JNO = J.JNO
也可以使用IN谓词,如下:
SELECT DISTINCT JNAME
FROM J
WHERE JNO IN(SELECT JNO FROM SPJWHERE PNO='P3' )2、求至少使用了零件编号为P3和P5的工程编号JNO
代码如下:
SELECT DISTINCT X.JNO
FROM SPJ X, SPJ Y
WHERE X.JNO=Y.JNO AND X.PNO='P3' AND Y.PNO='P5'
3、求使用了全部零件的工程名称
代码如下:
SELECT JNAME
FROM J
WHERE NOT EXISTS (SELECT * FROM PWHERE NOT EXISTS(SELECT * FROM SPJWHERE JNO=J.JNO AND PNO=P.PNO ))
4、统计上海地区的工程使用零件总数(超过三种)和零件总数量。要求查询结果按零件的种数升序排列,种数相同的按总数量降序排列。
代码如下:
SELECT SPJ.JNO,COUNT(DISTINCT PNO) AS COUNT_PNO, SUM(QTY) AS SUM_QTY
FROM J,SPJ
WHERE JCITY = '上海' AND J.JNO=SPJ.JNO
GROUP BY SPJ.JNO
HAVING COUNT(DISTINCT PNO)>3
ORDER BY 2,3 DESC方法2:
SELECT SPJ.JNO,COUNT(DISTINCT PNO) AS COUNT_PNO, SUM(QTY) AS SUM_QTY
FROM J INNER JOIN SPJ ON J.JNO=SPJ.JNO AND JCITY='上海'
GROUP BY SPJ.JNO
HAVING COUNT(DISTINCT PNO)>3
ORDER BY 2,3 DESC
5、检索至少不使用P3和P5这两种零件的工程编号JNO,把检索结果放在表STORE中存储起来
代码如下;
SELECT JNO INTO STORE
FROM J
WHERE JNO NOT IN (SELECT X.JNO FROM SPJ X, SPJ Y WHERE X.PNO='P3' AND Y.PNO='P5'AND X.JNO=Y.JNO)
总结
1、在编码时在注意数据备份,方便后续使用。
2、在执行语句时记得选中执行。
3、一个题目最先考虑内联接方法,若无法解决再考虑子查询,最最最后考虑笛卡尔积(一般也不用该方法)。
(emmm,暂时先这样了,后续补充,用于个人复习用,可参考)