当遇到大sql批量导入时几十万上百万数据,使用plsql执行等都是非常的慢。因此开发一套自定义线程池处理sql:
1,线程代码
import java.util.ArrayList;/*** @ClassName: com.ai.order.esb.yulang.tools.handle* @Description: TODO* @version: v1.0.0* @author: yulang* @date: 2019/5/22 10:51* <p>* Modification History:* Date Author Version Description* ------------------------------------------------------------* 2019/5/22 yulang v1.1.0 第一次创建*/
public class DateHandleThread extends Thread {@Overridepublic void run() {//System.out.println("线程:" + Thread.currentThread().getName());Integer num = BatchImportData.getLine();//获取对应的线程锁,每个线程处理各自对应的数据ArrayList<String> sqlData = BatchImportData.getSqlData(num);//获取每个线程需处理的数据/*for (String sqlDatum : sqlData) {System.out.println("第"+num+"个线程取到的数据:"+sqlDatum);}*/BatchImportData.runSql(sqlData);}
}
2、BatchImportData.java
package com.ai.order.esb.yulang.tools.handle;import org.springframework.jdbc.datasource.init.ScriptUtils;import java.io.*;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
import java.sql.Statement;
import java.util.ArrayList;
import java.util.Timer;
import java.util.concurrent.ConcurrentLinkedQueue;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.AtomicInteger;/*** @ClassName: com.ai.order.esb.yulang.tools.handle* @Description: 多线程批量导入数据,导入失败会记录到[sqlFilePath]err.sql* @version: v1.0.0* @author: yulang* @date: 2019/5/22 10:51* <p>* Modification History:* Date Author Version Description* ------------------------------------------------------------* 2019/5/22 yulang v1.1.0 第一次创建*/
public class BatchImportData {private static AtomicInteger line = new AtomicInteger(0);static int threadNum = 4;//配置需要执行的线程数static String sqlFilePath = "D:\\qq文件\\6.sql";//sql文件的路径static int batchHandleNum = 1;//一次批量导入的条数,批量导入可以大幅度提升性能static String url = "jdbc:oracle:thin:@127.0.0.1:1521:test";static String user = "yulang";static String password = "yulang";static ExecutorService pool = Executors.newFixedThreadPool(threadNum);static ArrayList<String> sqlList = new ArrayList<>();//异常日志记录 TODO String泛型可以改成 日志记录表的对象protected static ConcurrentLinkedQueue<String> queue = new ConcurrentLinkedQueue<>();private static Boolean isInit = Boolean.FALSE;public static Boolean DateThreadisRes = Boolean.FALSE;/* public static void getInstance() {synchronized (isInit) {if (isInit.equals(Boolean.FALSE)) {Timer timer = new Timer(true);timer.schedule(new MsgInfo(), 3000l, 1000l);//默认3秒后,每秒定时扫描isInit = Boolean.TRUE;}}}*/public static void main(String[] args) throws Exception {Timer timer = new Timer(true);//TODO 此方法如果系统更新时间之后,会导致挂起 可使用timer.schedule(new MsgInfo(), 1000l, 1000l);//默认1秒后,每秒定时扫描long starttime = System.currentTimeMillis();BatchImportData.doJob();try {// awaitTermination返回false即超时会继续循环,返回true即线程池中的线程执行完成主线程跳出循环往下执行,每隔10秒循环一次while (!pool.awaitTermination(10, TimeUnit.SECONDS)) ;DateThreadisRes=Boolean.TRUE;//标记线程池处理结束long spendtime = System.currentTimeMillis() - starttime;System.out.println("数据处理线程池执行结束,处理成功,耗时:" + spendtime / 1000 + "秒");//如果当前队列大于0,说明还有消息没有保存if (queue.size()>0){System.out.println("当前队列剩余:"+queue.size()+"。主线程将休眠:"+queue.size()+"s,若执行完毕可手动关闭!");Thread.sleep(queue.size()*1000);//主线程等待队列,最坏的情况一秒保存一条一直出现提示即可关闭}} catch (InterruptedException e) {e.printStackTrace();}}public static int getLine() {return line.addAndGet(1);}public static ArrayList<String> getSqlData(int num) {//获取本次执行的线程数int piece = sqlList.size() / threadNum;//每个线程应该分派的任务数量//每个线程应该取的范围集合int res = num * piece;int start = piece * (num - 1);ArrayList<String> tempSql = new ArrayList();if (num == threadNum) {System.out.println("第" + num + "个线程处理数据范围为:[" + start + "," + sqlList.size() + ")");for (int i = start; i < sqlList.size(); i++) {tempSql.add(sqlList.get(i));}} else {System.out.println("第" + num + "个线程处理数据范围为:[" + start + "," + res + ")");for (int i = start; i < res; i++) {tempSql.add(sqlList.get(i));}}return tempSql;}public static Connection getConnect() {Connection con = null;try {Class.forName("oracle.jdbc.driver.OracleDriver");con = DriverManager.getConnection(url, user, password);} catch (Exception e) {e.printStackTrace();}return con;}public static void runSql(ArrayList<String> stringList) {Connection con = getConnect();try {Statement st = con.createStatement();StringBuilder sb = new StringBuilder();for (int i = 0; i < stringList.size(); i++) {st.addBatch(stringList.get(i));sb.append(stringList.get(i)).append(";").append(System.getProperty("line.separator"));if (i == stringList.size()) {//剩余不足batchHandleNum条数的批量执行dealDate(st, sb);}if (i % batchHandleNum == 0) {//满batchHandleNum批量执行dealDate(st, sb);}}} catch (Exception e) {e.printStackTrace();} finally {try {con.close();} catch (SQLException e) {e.printStackTrace();}}}private static void dealDate(Statement st, StringBuilder sb) {try {st.executeBatch();sb.setLength(0);//清空} catch (Exception e) {System.out.println("执行异常:异常原因:" + e.getMessage());//记录失败sql//logs(sb.toString());//TODO 可使用队列,mq,kafka,异步处理queue.add(sb.toString());sb.setLength(0);//清空}}public static void logs(String text) {try {BufferedWriter out = new BufferedWriter(new FileWriter(sqlFilePath + "err.sql", true));//追加写入out.write(text);out.close();} catch (IOException e) {}}private static String readSql(String filePath) throws IOException {//读取文件File file = new File(filePath);BufferedReader br = new BufferedReader(new InputStreamReader(new FileInputStream(file), "GBK"));StringBuilder sql = new StringBuilder();//替换String line = null;int i = 1;//以行为单位进行遍历while ((line = br.readLine()) != null) {sql.append(line);}//关闭输入流br.close();return sql.toString();}public static void doJob() throws Exception {//单线程读取String sql = readSql(sqlFilePath);ScriptUtils.splitSqlScript(sql, ";", sqlList);System.out.println("解析到待处理sql数量:" + sqlList.size());//每个线程只取自己处理的那部分数据for (int i = 0; i < threadNum; i++) {Thread thread = new DateHandleThread();pool.execute(thread);}pool.shutdown();}
}
异步处理定时任务:MsgInfo.java
package com.ai.order.esb.yulang.tools.handle;import java.util.TimerTask;
import java.util.concurrent.ConcurrentLinkedQueue;/*** 日志消息异步处理*/
public class MsgInfo extends TimerTask {public void run() {ConcurrentLinkedQueue<String> value = BatchImportData.queue;try {while (!value.isEmpty()) {String logInfo = value.poll();//TODO 存入数据库或者写入文件BatchImportData.logs(logInfo);//System.out.println("错误sql记录完成!");}} catch (Exception e) {System.err.println("save messagelogs error:" + e);}if (BatchImportData.DateThreadisRes){System.out.println("当前队列剩余数量:"+value.size()+",异步保存完毕,可手动关闭主线程!");}}
}执行结果展示:
当前执行,一次批量执行一条效果展示。
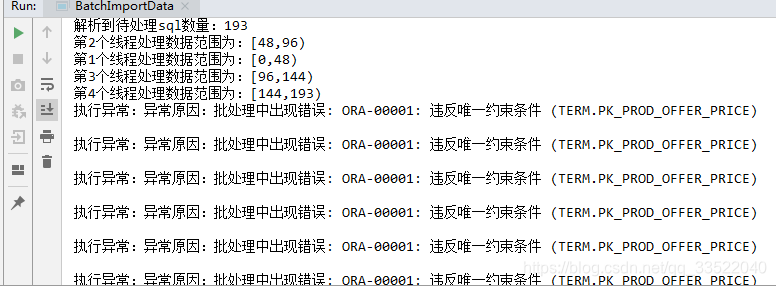

不足的地方,欢迎指正,谢谢!
评测效果:
批量导入249665条数据,数据大小为238M,耗时238s:
线程数:4
单次批量导入:2000

执行失败的sql记录错误日志:如图1.sqlerr.sql

后期扩展:
可以解析的使用单独的工程进行解析,将解析后的数据放到MQ中,以及执行出错的sql记录也可使用mq。