近期,炫一下(北京)科技有限公司(简称“一下科技”)短视频产品“秒拍”完成了一个“大动作”——将原来部署在虚拟机上的主体业务迁移到华为云,同时将公司的技术体系承载在下一代虚拟技术容器(Docker)上。而这一系列动作是在业务不下线,用户无感知的前提下完成的,秒拍是如何做到的?
秒拍是一个媒体属性很强的业务,在用户规模达到一定体量后,由明星热点事件引发的流量突发状况非常严重,而传统虚机业务存在扩容响应速度慢,成本高等一系列问题,于是秒拍想到了容器。容器服务拥有启动快速、占用资源少、运行效率高等技术特点,在处理海量数据方面拥有天然的优势。但是如何保证业务能够快速无缝地进行切换,让最终用户毫无感知的完成从虚机到容器的迁移,真正要做到这一点非常困难。
尽管困难重重,但秒拍在评估了未来业务需求和技术团队规模之后,还是选择将已部署在云上的主体业务迁移到华为云CCE上。而华为云强大的技术支持能力和服务团队,为这次迁移解决了后顾之忧。
以下是秒拍架构师李东辉对本次业务迁移的记录,如果你也希望从虚机向更灵活的容器升级,又不希望影响业务,不妨一看:
背景
我们现在主体业务已经是部署在某云上了,但整个技术体系,还是基于传统的虚拟机去承载的,由于我们产品本身的媒体属性,导致了不可避免的会经常遇到突发流量,相比于一直比较平稳的流量,这种对服务端的考验更高,核心关注点还是在怎么保障在这种时刻用户都能得到良好的体验。
另一方面,由于云平台本身的一些不可抗力因素,不能保证百分百的高可用,怎么降低单点依赖的风险,也是我们需要重点考虑的。
经过综合性的权衡,我们决定把主体业务迁移到华为云,并且优化升级原来的架构,以便更好的支撑海量用户访问。前端机也从VM过渡到docker,迁移后的整体架构图如下
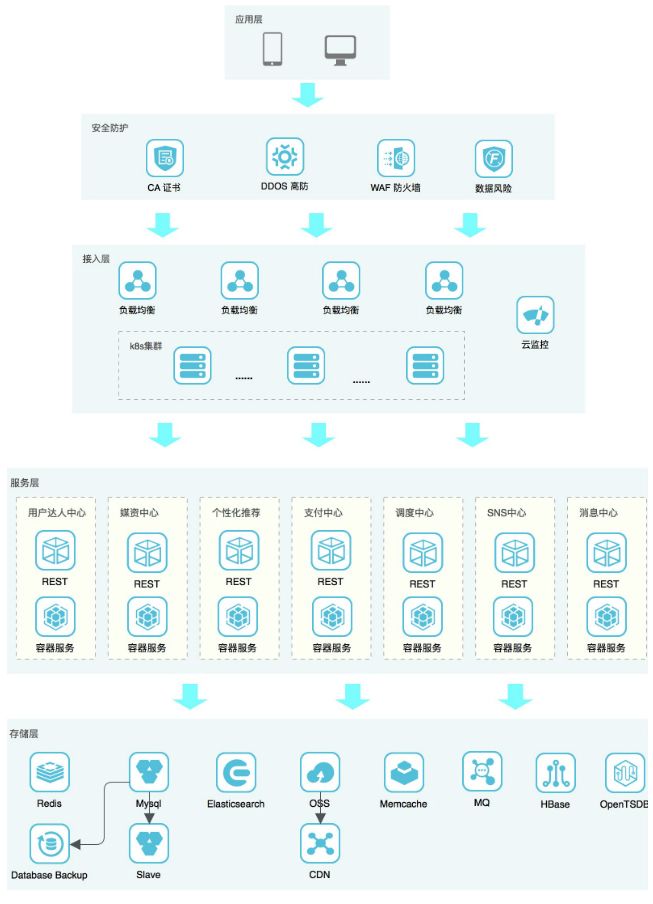
各个资源的迁移过程
1. mc迁移
现在业务上使用mc只是做临时缓存,cache miss会从存储(DB、ES等)拉一份写进去,并且业内也没有比较成熟的mc存量与增量迁移方案,所以这部分数据可以忽略,等上线前,预热一部分热点数据进去。不过使用上有一些区别,原平台使用的是服务端集群,现在是客户端集群,需要建立MC连接的时候,添加所有的服务器列表以及权重。
2. mq迁移
mq主要用来解耦业务模块,生产端生产一份数据,消费端可能有多个,迁移的话,需要先配置好资源的vhost,exechange还有queue,服务端先更新配置上线,数据写入到新资源,消费端在旧资源消费完成后,切换到新资源的消费上。
3. redis迁移
redis的迁移需要区分两个场景的数据,一个是缓存数据,可以按照mc的迁移策略忽略,另一部分是持久化数据,主要是业务上的各种计数,这部分数据要求尽量精确快速的迁移到新资源,当时考虑了两种方案
· 一种呢,是基于快照文件迁移 存量数据可以通过RDB快照,只需要原平台有备份RDB的权限,在新资源通过快照回放完成全量数据的迁移。 这种方案优点比较突出,操作简单快速,但缺点是不支持增量同步。
· 另一种呢,基于业务迁移 首先,读 优先从新资源读,没有命中的从老资源读取一份,写入到新资源并返回这个值。 其次,写 (incr decr操作) 优先更新老资源,并且按照更新后的返回值写入到新资源。
这种方案能兼顾存量与增量数据,但存在的问题是,读写新老资源的过程非原子性,理论上高并发情况下会存在一定误差,并且业务上的这种改造增加了后期的维护成本,另外,从性能方面考虑,原来一次连接(短连接)、一次redis操作就能搞定的事,现在都需要两到三次。
综合现在的业务量考虑,我们采取了第一种方案,但是时间点选在凌晨四点低峰时段,将影响范围尽可能降到最低,后续通过落到DB的数据做统计恢复。
4. db迁移
db迁移相对比较容易,全量数据预先复制一份过去,增量数据因为都是基于binlog订阅,只需要获取原平台DB的权限,就可以通过binlog同步到新数据库。
这里需要注意的是一个主从同步的问题,新资源主从是半同步复制,主库只需要等待一个从库节点收到并且 Flush Binlog 到 Relay Log 文件即可,同时,这里只是一个收到的反馈,而不是已经完全完成并且提交的反馈,这时候,主库就会进行其他操作,相比与之前的全同步的事务复制,节省了很多时间,但是也造成了新的问题,即:主从有理论上1ms的延迟,实际测试延迟时间是0.5-0.8ms,这在“更新DB后又立马读取一次DB数据”的场景下会有问题,并且根据Cache Aside Pattern的缓存更新策略,DB更新成功会直接删除缓存,由于主从延迟,这时候读进程读取到老数据并且写入到缓存,从而导致了一段时间内的脏数据。
有一个比较快速的方式能够解决这个问题,那就是在DB更新成功后直接更新缓存,但是这样处理后会产生新的问题,并发的写操作,又会导致同一资源key的脏数据,不过是概率大小的问题。这就涉及到了取舍,就像为了保证DB、cache的强一致性,采用2PC(prepare, commit/rollback),大大降低性能一样,软件设计从来都是取舍。
5. ES迁移
ES主要服务的是APP以及Admin后台,用户、媒资等数据的搜索,数据源在DB,所以存量数据直接从DB拉一份进去,增量数据通过监听DB更新,同步到ES里。
6. 版本库迁移
版本库的迁移主要是方便接入镜像构建与k8s部署,同时呢,项目使用到的资源链接地址、用户名、密码等也需要更新,这部分都是统一配置,直接修改就行。
7. 服务发现
原来业务上都是基于服务端发现的模式,一个微服务对应着一个LB,通过DNS解析到对应的LB IP,LB实现VM的负载均衡策略与保活机制。LB下层现在多了一层k8s的调度,k8s调度的单元也不再是VM,而是Pod(逻辑主机),在这里VM的存在也仅仅是提供不同规格的物理资源。
其次使用DNS解析也可以方便不同VPC子网指向不同的资源IP,例如测试环境与生产环境,项目使用到的资源地址是相同的,只不过解析到了不同的资源。
8. Dokerfile
需要预先制作好基础镜像,包含基本的php、nginx环境跟用户权限这些,Dokerfile主要实现将项目代码复制到容器。

9. 切流量
后端资源迁移完成,准备就绪以后,就可以开始切公网流量了,非核心业务直接修改公网DNS,解析到新LB IP,核心业务LB上层还有一层高防,在高防不变的情况下,只需要修改高防源站IP到新LB就行。
流量迁移完毕后,全线验证,观察错误日志,当然这个过程并不是只有等流量切完才会开始,而是从资源迁移开始就一直持续进行的。
10. 部署上线
原来的部署是通过中控机,将代码分发到各个线上服务器,现在呢,需要使用上一步创建的Dockerfile,构建镜像,将构建好的镜像通过k8s滚动升级(先kill老镜像,再派生出新镜像)。升级的步骤如下:
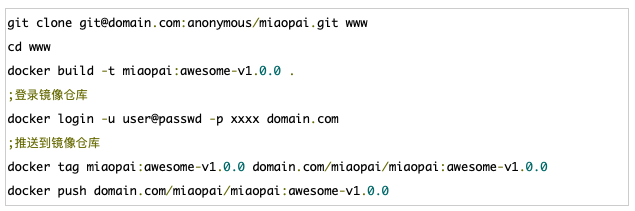
push后镜像已经推送到私有仓库,现在需要创建k8s的配置文件用于管理和升级容器。
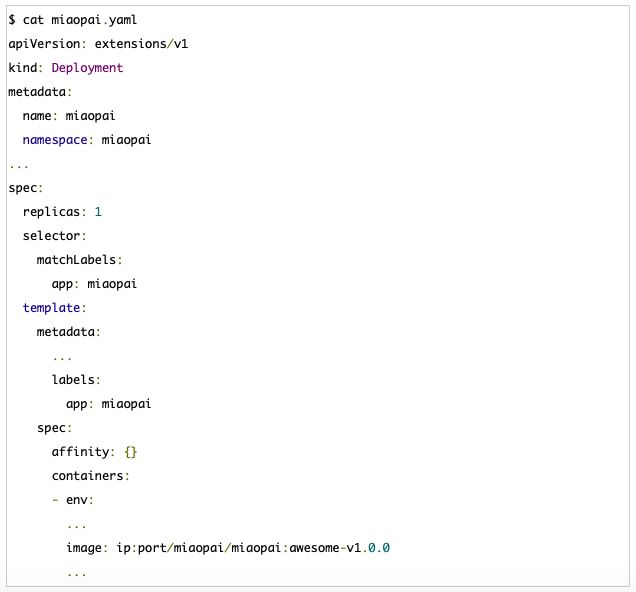
创建pod kubectl create -f miaopai.yaml 后边再升级容器,先把容器更新push到仓库后,修改image地址,通过apply进行升级就可以。
架构优化
架构优化的目标是分析现在业务上存在的问题,并针对性的优化解决,结合压测结果,主要确定了几个优化点。
1. mc、redis的优化
mc使用上存在的问题是,只有在存储查询到的情况下才会缓存数据,这样就会导致很多空查询落到存储,解决这个问题只需要将没有查询到数据的情况,也写一份空数据到缓存就能解决。
除此之外,mc的批量查询,存在太多的伪批量(redis也存在),例如:foreach每次循环里都使用get查询,需要将这样的处理都改成multiget的形式,不过multiget在集群的情况下会存在hole现象,这个问题最早是由 facebook 的工作人员提出的
facebook 在 2010 年左右,memcached 节点就已经达3000 个.缓存数千 G 内容.他们发现了一个问题-memcached 连接频率,效率下降了,于是加 memcached 节点, 添加了后, 发现因为连接频率导致的问题, 仍然存在, 并没有好转,称之为”multiget hole现象”。请求多台服务器并不是问题的症结,真正的原因在于客户端在请求多台服务器时是并行的还是串行的!问题是很多客户端,包括Libmemcached在内,在处理Multiget多服务器请求时,使用的是串行的方式!也就是说,先请求一台服务器,然后等待响应结果,接着请求另一台,结果导致客户端操作时间累加,请求堆积,性能下降。
有推荐根据key做hash的,这样就可以使得相同key前缀的数据分布在一台机器上,但是这样又会导致新的问题,例如:增加业务复杂度,每个节点的数据分布不均等等,不过相信大部分公司业务的体量都没办法对标facebook的,如果真的到了需要考虑这个问题的时候,其实是推荐使用redis的pipeline并行机制来解决的。
2. 核心业务的降级策略
作为APP内首屏的几个tab,数据都是从推荐系统中获取,一旦推荐系统挂掉,基本没有了用户体验,所以必要时还是需要采用熔断降级策略,降级策略相对来说,只需要保证用户能获取到部分列表数据,即使所有用户获取到的数据都一样。实现上呢,先把部分列表数据存储到cache,一旦发生熔断,那么数据从推荐系统读取的渠道会直接切断,转而从cache里读取返回给用户。但是有一个问题,读取的这个流程应该是由业务完成,还是由前端web服务器(nginx)直接完成呢。我们目前采用的后者,一方面使用ngx_lua能保证系统的吞吐,另一方面不仅仅是推荐系统,即使在服务端整体挂掉的情况下,也可以继续提供服务。
触发熔断的条件可以有很多,例如:每20个请求中,50%失败,当然了,失败包括响应失败跟超时,也可以根据当次请求结果来判断。熔断的条件其实并没有什么标准,更多的是依照以往系统的经验来一步步调整。在以前并没有很多熔断经验的情况下,尽量扩大这个阈值,随着经验的一步步积累,再确定各个模块比较合理的熔断条件和降级策略。
3. 负载均衡策略
传统负载均衡LB,实现的是请求到VM和端口的负载均衡,容器化之后,LB下层挂载了k8s集群,实际上这里的负载均衡除了LB的,还有k8s的,即请求到达节点(VM)后,再负载均衡到不同的容器。
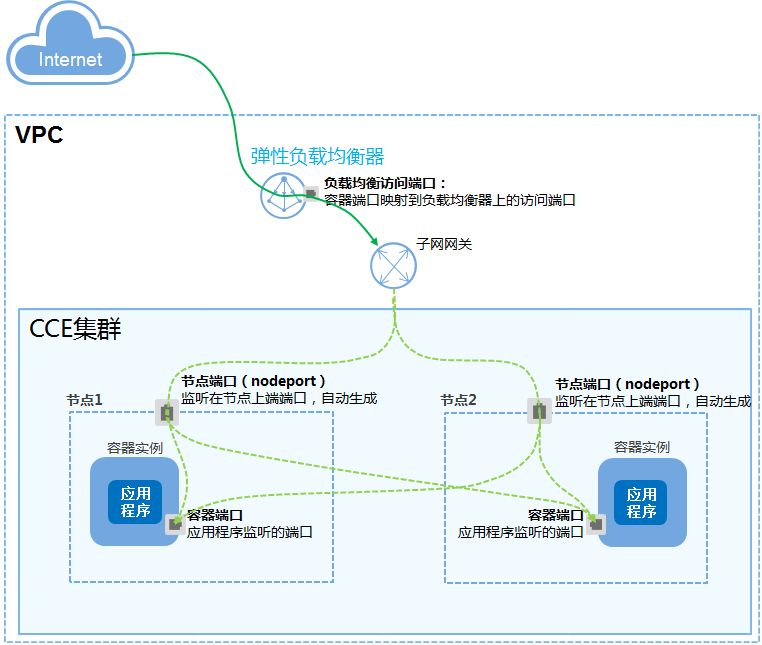
上边提到的负载均衡只是四层(IP加端口),如果要根据应用层的信息,比如:URI,cookie等等,做负载均衡,就需要使用七层LB,我们使用到的场景,主要是还没有切割成微服务的大单体,根据URI,将不同模块的请求打到不同的四层LB。
4. Mysql HA
Mysql作为我们底层的核心存储,必须要保障它的高可用,现在架构是采用主从+主备的形式,不过这两种方式都有个共性的问题,主机故障后,无法进行写操作,如果主机一直无法恢复,需要人工指定新主机角色。优化的目标也显而易见,就是设计双机切换,在主机故障之后,能够自动切换到其他主机。
PHP本身实现了mysql的负载均衡和failover策略,需要依赖插件mysqlnd_ms,详见http://php.net/mysqlnd_ms,不过仅限于PHP5.x版本,倒是有支持PHP7.0以上的非官方版本,https://github.com/sergiotabanelli/mysqlnd_ms,但如果直接用在生产环境,并不十分明智,并且mysqlnd_ms需要特殊格式的资源配置,在一个项目里维护两份资源配置,也会带来新的复杂度问题。
要实现双击切换的核心点在于,对主机状态的判断,和状态决策,可以通过引入一个中介角色,主机和备机把状态传递给中介,由中介完成决策功能,但引入中介的角色并不是没有代价的,那就是要考虑中介角色的高可用。这就陷入了一个递归的陷阱:为了实现高可用,我们引入中介,但中介本身又要求高可用,于是又要设计中介的高可用方案……如此递归下去就无穷无尽了。
MongoDB的Replica Set采取的就是这种方式,基本架构如下:
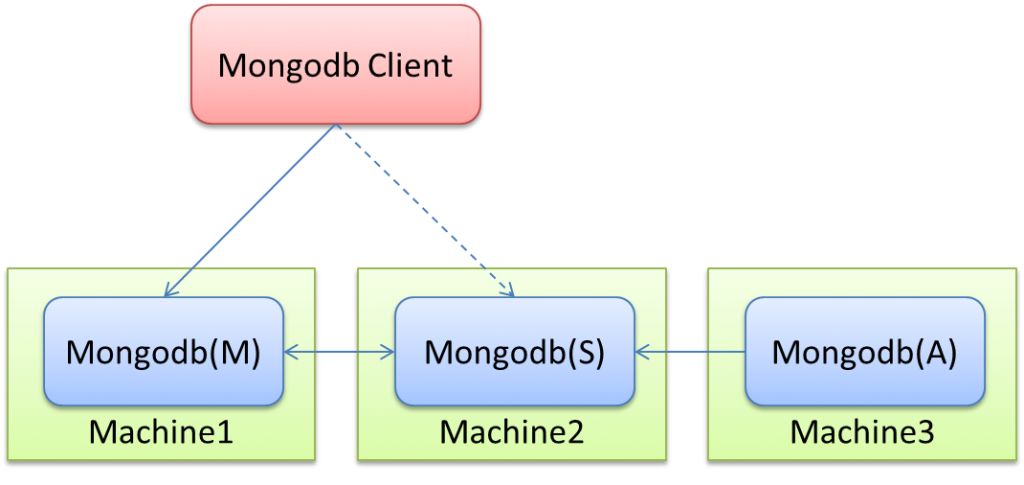
幸运的是,开源方案已经有比较成熟的中介式解决方案,例如:Zookeeper和Keepalived。ZP本身已经实现了高可用集群架构,因此已经解决了中介本身的可靠性问题,在实践中也推荐这种架构。
5. 日志与监控
线上日志的定时收集反馈也是必不可少的,日志包括服务器的access_log,error_log,当然还有业务的自定义log。收集的目的主要是用来统计一段时间内的http code 分布、响应时间和错误信息。
通过在实例跟资源上部署agent,定时收集CPU和内存信息也是必要的。统计型的数据需要收集汇总成表格,方便观察,各种指标的阈值也需要提前设置好,超过阈值后能够及时报警,通知到责任人。当然了,监控不是最终目的,及时巡检线上资源、接口,排除系统隐患,防范于未然才是终极之道。
不得不说,互联网企业把大多数业务部署在云服务器上,现在已渐成趋势,但由于历史原因,技术往往是架设在传统的虚拟机(VM)上。如果企业要过渡到下一代虚拟技术容器,会涉及到各类资源迁移和技术架构优化,整个过程是必须短暂而痛苦的。但如果没有相应规模的技术团队来操作,再加上云厂商没有完善的技术支持团队,这个过程会更加痛苦。如何减少企业业务升级的痛苦,这就非常考验企业技术决策者的选择智慧!华为云,目前已经展现出了在技术服务的独特优势,未来肯定是摆在企业面前最具竞争力的选项之一。