目录
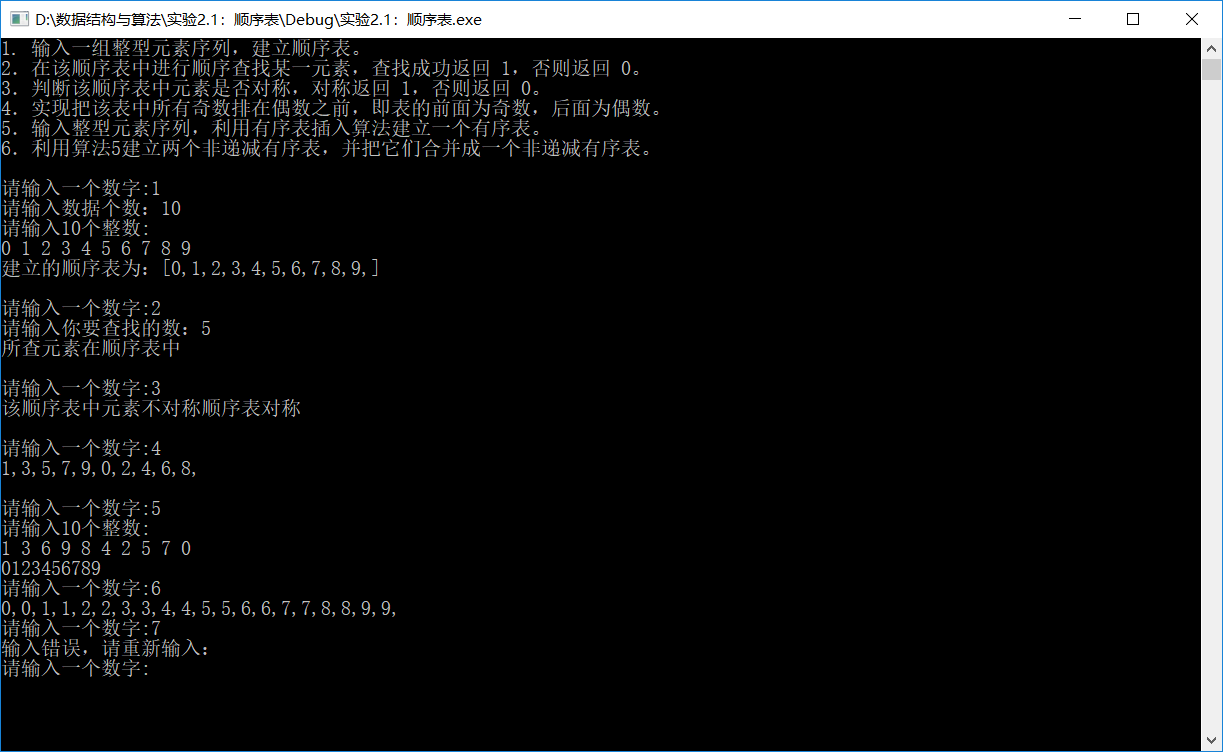
问题描述
基本要求
问题分析
实验代码
运行结果
实验总结
问题描述
利用哈夫曼编码进行通信可以大大提高信道利用率,缩短信息传输时间,降低传输成本。但是,这要求在发送端通过一个编码系统对待传数据预先编码,在接收端将传来的数据进行译码(复原)。对于双工信道(即可以双向传输信息的信道),每端都需要一个完整的编/译码系统。试为这样的信息收发编写一个哈夫曼码的编/译码系统。
基本要求
(1)接收原始数据(电文):从终端输入电文(电文为一个字符串,假设仅由26个小写英文字母构成)。
(2)编码:利用已建好的哈夫曼树,对电文进行编码。
(3)打印编码规则:即字符与编码的一一对应关系。
(4)打印显示电文以及该电文对应的哈夫曼编码。
(5)接收原始数据(哈夫曼编码):从终端输入一串哈二进制哈夫曼编码(由
0和1构成)。
(6)译码:利用已建好的哈夫曼树对该二进制编码进行译码。
(7)打印译码内容:将译码结果显示在终端上。
问题分析
(一)算法设计思路:
(1)接收原始数据:从Huffm.txt读入字符及其对应权值,建立哈夫曼树。
| 字符 | - | A | B | C | D | E | F | G | H | I | J | K | L | M |
| 频度 | 186 | 64 | 13 | 22 | 32 | 103 | 21 | 15 | 47 | 57 | 1 | 5 | 32 | 20 |
| 字符 | N | O | P | Q | R | S | T | U | V | W | X | Y | Z | |
| 频度 | 57 | 63 | 15 | 1 | 48 | 51 | 80 | 23 | 8 | 18 | 1 | 16 | 1 |
(2)编码:利用建好的哈夫曼树进行编码,存入HuffCode中,输入字符串,输出相应的密文。
(3)译码:利用已建好的哈夫曼树,将密文解码,输出对应明文。
(4)打印编码规则:字符与编码一一对应。
(二)使用模块及变量的说明
(1)typedef struct HNodeType:定义叶子结点。
(2)typedef struct HNodeType HFMTree[2*HUFFCODE-1]:建立储存哈夫曼树的数组。
(3)typedef struct HCodeType:定义储存编码的结点
(4)HCodeType HuffCode[HUFFCODE]:建立编码的数组
(5)void Creat_HuffMTree(HNodeType HFMTree[],int n):构造哈夫曼树
(6)void HaffmanCode(HNodeType HFMTree[], HCodeType HuffCode[],int n):哈夫曼编码过程,左分支是0,右分支是1
(7)void print_HuffCode(HCodeType HuffCode[]):打印编码规则
(8)void code_Huff(HCodeType HuffCode[],string s):编码过程,将字符串进行编码并输出对应二进制数
(9)void decode_Huff(string s, HNodeType HFMTree[], int n):译码过程,将二进制数使用哈夫曼树进行译码
实验代码
C++版
#include<iostream>
#include<fstream>
#include<string>
using namespace std;
#define HUFFCODE 27 //27个字符
#define MAXVALUE 10000 //构造哈夫曼树时使用//定义叶子结点
typedef struct {char data;int weight;int parent, lchild, rchild;
}HNodeType;
HNodeType HFMTree[2*HUFFCODE-1];//结构数组储存各字符编码
typedef struct {char data; //每个结点储存字符int bit[HUFFCODE]; int start;
}HCodeType;
HCodeType HuffCode[HUFFCODE];//储存编码的数组//构造哈夫曼树
void Creat_HuffMTree(HNodeType HFMTree[],int n) { int m1, x1, m2, x2; //x1,x2存储最小和次小权值,m1,m2存储其位置int i, j;for (int i = 0; i < 2 * n - 1; i++) { //HFMTree初始化HFMTree[i].weight = 0; HFMTree[i].parent = -1;HFMTree[i].lchild = -1; HFMTree[i].rchild = -1;}HFMTree[0].data = '_'; HFMTree[0].weight = 186;//设置空格(改为_了)的权值ifstream myfile("Huffm.txt");for (int i = 1; i < n; i++) { myfile >> HFMTree[i].data;myfile >> HFMTree[i].weight;}myfile.close();for (int i = 0; i < n - 1; i++) { //构造哈夫曼树x1 = x2 = MAXVALUE;m1 = m2 = 0;for (int j = 0; j < n + i; j++) { //找出根结点具有最小和次小权值的两棵树if (HFMTree[j].parent == -1 && HFMTree[j].weight < x1) {x2 = x1; m2 = m1;x1 = HFMTree[j].weight; m1 = j;}else if (HFMTree[j].parent == -1 && HFMTree[j].weight < x2) {x2 = HFMTree[j].weight; m2 = j;}}HFMTree[m1].parent = n + i; HFMTree[m2].parent = n + i;//合并两棵树HFMTree[n + i].weight = HFMTree[m1].weight + HFMTree[m2].weight;HFMTree[n + i].lchild = m1; HFMTree[n + i].rchild = m2;}
}//哈夫曼编码过程,左分支是0,右分支是1
void HaffmanCode(HNodeType HFMTree[], HCodeType HuffCode[],int n) {HCodeType cd; //字符编码的缓冲变量int i, j, c, p;for (i = 0; i < n; i++) { //求每个叶子结点的哈夫曼编码cd.start = n - 1;c = i;p = HFMTree[c].parent;cd.data = HFMTree[c].data;while (p != -1) {if (HFMTree[p].lchild == c) cd.bit[cd.start] = 0;else cd.bit[cd.start] = 1;cd.start--;c = p;p = HFMTree[c].parent;}for (j = cd.start + 1; j < n; j++) { //保存求出的每个叶结点的哈夫曼编码和编码的起始位置HuffCode[i].bit[j] = cd.bit[j];}HuffCode[i].start = cd.start + 1;HuffCode[i].data = cd.data;}
}//打印编码规则
void print_HuffCode(HCodeType HuffCode[]) {for (int i = 0; i < HUFFCODE; i++) {cout << HuffCode[i].data<<"对应编码:";for (int j = HuffCode[i].start; j < HUFFCODE; j++) {cout << HuffCode[i].bit[j];}cout << endl;}
}//编码过程,将字符串进行编码并输出对应二进制数
void code_Huff(HCodeType HuffCode[],string s) {int i = 0;ofstream outfile("textfile.txt");while (s[i] != '\0') {for (int j = 0; j < HUFFCODE; j++) { //遍历HuffCodeif (s[i] == HuffCode[j].data) {for (int k = HuffCode[j].start; k < HUFFCODE; k++) {cout << HuffCode[j].bit[k];}i++;break;}}}cout << endl;
}//译码过程,将二进制数使用哈夫曼树进行译码
void decode_Huff(string s, HNodeType HFMTree[], int n) {int i = 0, j = 0, p = 2 * n - 2;char a[1000] = {};while (s[i] != '\0') {if (s[i] == '0') {p = HFMTree[p].lchild;}else if (s[i] == '1') {p = HFMTree[p].rchild;} //判断p是否为叶子结点,是则将对应数据储存进aif (HFMTree[p].lchild == -1 && HFMTree[p].rchild == -1) {a[j] = HFMTree[p].data; j++;p = 2 * n - 2;}else if (s[i + 1] == '\0' && HFMTree[p].lchild != -1 && HFMTree[p].rchild != -1) {cout << "译码失败!" << endl;return;}i++;}int k = 0;while (a[k]!=0 ) cout << a[k++];cout << endl;
}int menu() {int a;cout << "请选择功能键:";cin >> a;if (a >= 0 && a <= 3) return a;else return -1;
}int main() {int a;string s1, s2;Creat_HuffMTree(HFMTree, HUFFCODE);HaffmanCode(HFMTree, HuffCode, HUFFCODE);cout << "********************" << endl;cout << "1.编码" << endl;cout << "2.译码" << endl;cout << "3.打印编码规则" << endl;cout << "0.退出" << endl;cout << "********************" << endl;a = menu();while (a != 0) {switch (a) {case 1:cout << "请输入要进行编码的明文:";cin >> s1;code_Huff(HuffCode, s1); //进行编码a = menu();break;case 2:cout << "请输入要进行解码的密文:";cin >> s2;decode_Huff(s2, HFMTree, HUFFCODE); //进行译码a = menu();break;case 3:cout << "编码规则为:" << endl;print_HuffCode(HuffCode);a = menu();break;case -1:cout << "请输入正确的功能键!" << endl;a = menu();break;} }cout << "退出成功!" << endl;system("pause");return 0;
}
运行结果


实验总结
1、构造哈夫曼树时,从Huffm.txt读入字符及对应权值,需要使用fstream库。构造过程中数组下标没有处理好,导致出现各种问题。
2、译码过程用字符数组储存结果,若译码失败则不输出。这个过程最开始使用的是一个字符串变量储存,出现错误,程序无法运行,改用字符数组储存,并进行初始化,就解决了问题。