从玩玩chatGPT说起
- 起因
- 想法
- 先文本转语音播报
- 再来语音转文本
- 连接AI接口
- 再来添加唤醒
- 空间考虑
- 串成线
- 问题与想法
起因
最近,哦,已经不是最近了,挺长一段时间了,chatGPT火了。出于好奇,注册了账号,而且尝试与其文字对话,询问问题,还有在工作中让其帮忙翻译以及进行语言学习,发现----chatGPTj是一位好老师。虽然这个老师有时候会一本正经地胡说八道,但综合下来,百分之九十以上可以给出比较靠谱回答的。而且其回答的方式很亲和,即使出错,也可以引导其给出正确回答,确实是目前为止非常高级的AI了。不满足于只是文字交流,在想是否可以通过语音交流呢?(由于本人一直活在小世界孤陋寡闻应该早已有此实现,见谅!)恰好又刷 到一个视频,大致内容是某位大神通过树莓派实现了自己的语音助手。于是有此次尝试,希望在没有硬件的前提下考虑实现。
想法
想法其实很简单,如视频中大神的想法。语音唤醒——语音识别——发送识别文本到openai的API并取得文字回答内容——文本转语音播报。本身各部分实现都有现成的接口了应该,考虑胶水语言python完成。
先文本转语音播报
第一步想到的先从文本转语音播放开始。为什么从此步开始而不是语音识别呢?主要是我觉得这一步最简单吧。具体实现代码呢,拼拼凑凑,不会的就问chatGPT,再次赞赏一下这个好老师。完成函数方法实现。
# 该函数用于实现语音转文字并播报
def say_txt_as_audio(text):directory = "./chat-content"if not os.path.exists(directory):os.makedirs(directory)text = text.strip()if len(text) > 0:print("AI:" + text)# 将参数传送过来的txt内容转换为语音保存为mp3文件now = datetime.now()save_name = now.strftime("%Y%m%d%H%M%S.mp3")tts = gTTS(text, lang='zh-cn')tts.save("chat-content/" + save_name)# 通过pygame模块播放保存的mp3文件pygame.init()pygame.mixer.music.load("chat-content/" + save_name)pygame.mixer.music.play()while pygame.mixer.music.get_busy():pygame.time.wait(1000)pygame.quit()
这部分代码有使用pygame,所以不能忘了import pygame。另外由于执行的时候会有部分无关的文字输出到控制台,所以可能会像我一样修改环境设定。主要就是在import pygame之前有如下两行。
from os import environ
environ['PYGAME_HIDE_SUPPORT_PROMPT'] = '1' # pygame导入前此参数设定用于限制pygame的无关内容输出
经执行确认,可以正常将指定文字内容转成mp3文件,并即时播报。
mp3文件名为年月日进分秒。
对了,还有gtts的导入。from gtts import gTTS。
再来语音转文本
这一步就是把上边功能的文本变量的值的来源变成我们自己说的话,只要把我们说话的语音变成文本赋给这个变量就可以衔接上边功能了。嗯,就是这样。感谢google及chatGPT,不费时的就完成了。
# 该函数用于实现将语音的输入转换为文字
def convert_audio_to_text():# 创建麦克风的识别器对象r = sr.Recognizer()# 打开麦克风并录制音频with sr.Microphone() as source:print("我在听,你现在可以开始说话啦!~~")audio = r.listen(source)# 识别语音text = ""try:text = r.recognize_google(audio, language='zh-CN', show_all=False)print("你:" + text)with open("chatHistory.txt", "a", encoding="utf-8") as file:file.write("你:" + text)except Exception as e:print("没听到,无法识别:" + str(e))return text
至于代码中的sr当然是speech_recognition了,所以import部分记得添加
import speech_recognition as sr
就好了。由于想要将对话内容输出打印到控制台,且保存到文本文档中。所以代码中有print与write动作。
连接AI接口
了解到目前chatGPT并未开放API,所以只能使用opanai的API,貌似连接的是达芬奇3机器人,后来尝试确实不如在线与chagGPT沟通来得舒服。
首先要取得API key,可以在网站上点击获得。代码中有用到。
# 将指定内容发送给AI并取得回答返回
def get_questions_ai_answer(question):ai_answer_content = ""if len(question) > 0:openai.api_key = ""with open("OpenAiApiKey", 'r') as f:api_key = f.read().strip()openai.api_key = api_keyresponse = openai.Completion.create(model="text-davinci-003",prompt=question,temperature=0.9,max_tokens=2048, #150 OpenAI的API实现中,max_tokens参数的上限值为4096。top_p=1,frequency_penalty=0.0,presence_penalty=0.6,stop=[" Human:", " AI:"])response_result_text = response.get("choices")[0].get("text")ai_answer_content = response_result_textwith open("chatHistory.txt", "a", encoding="utf-8") as file:file.write("\nAI:" + ai_answer_content.strip() + "\n")return ai_answer_content
此部分用于连接前边的两步实现。即接收语音转文字的结果,发给openai再将回答结果传给文字转语音的实现部分。
开始询问chatGPT给出的示例代码中max_tokens设置为150。这样的情况下,当AI回答你问题的输出内容过多时,会中断,也就是说半句话就戛然而止了,经询问chatGPT,可调引参数,了解到上限是4096,所以改150到了2048。
至于OpenAiApiKey文件中存放的内容,就是在openai网站上取得的key值了。不公开了。
再来添加唤醒
上面三步串起来,基本可以完成从说话到ai语音回答了。但是每次都是单个python文件执行才能开始说一回。所以想到还是得加上语音唤醒才可以。不表经过,选了pocketsphinx,网上说要什么sphinxbase就是这一步折腾了挺长时间,不过后来发现纯粹是语音模型配置的路径不对而已。所以,我猜现在导入pocketsphinx库就可以了,当然swig库也加入到工程了,以防万一。
import os
import openai
import speech_recognition as sr
from gtts import gTTS
from datetime import datetime, timedelta
from os import environenviron['PYGAME_HIDE_SUPPORT_PROMPT'] = '1' # pygame导入前此参数设定用于限制pygame的无关内容输出
import pygame
from pocketsphinx import LiveSpeech, get_model_pathmodel_path = get_model_path()# 创建语音识别对象,用于监听说话,以备唤醒
speech = LiveSpeech(verbose=False,sampling_rate=16000,buffer_size=2048,no_search=False,full_utt=False,#hmm=os.path.join(model_path, 'en-us', 'en-us'),#lm=os.path.join(model_path, 'en-us', 'en-us.lm.bin'),#dic=os.path.join(model_path, 'en-us', 'cmudict-en-us.dict')# 此处切用网上下来的中文语音模型hmm = os.path.join(model_path, 'cmusphinx-zh-cn-5.2', 'zh_cn.cd_cont_5000'),lm = os.path.join(model_path, 'cmusphinx-zh-cn-5.2', 'zh_cn.lm.bin'),dic = os.path.join(model_path, 'cmusphinx-zh-cn-5.2', 'zh_cn.dic')
)
上面代码的Import部分,包括前面几步的import方便就一齐粘过来了。主要是构建了speech对象,但是还没使用,所以还要有下面一部分
# 开始语音识别
for phrase in speech:print("识别到的语音内容:", phrase)# 这里再执行唤醒后的动作
空间考虑
考虑到MP3文件存放大小的问题,又是以年月日时分秒命名的mp3文件,所以干脆每次问答的时候都删除几分种以前的文件好了。所以添加了一个文件删除的方法。
# 为了节省磁盘占用空间,删除指定分钟数以前的mp3文件。在每次执行前开始算起。
def delete_mp3_files_several_minutes_ago(minute):now = datetime.now()several_minutes_ago = now - timedelta(minutes=minute)several_minutes_ago_str = several_minutes_ago.strftime("%Y%m%d%H%M%S")for filename in os.listdir("chat-content/"): # 遍历该路径下的所有文件if not filename.endswith('.mp3'): # 如果不是mp3文件,跳过continueelse:file_time = filename[:-4] # 取出文件名即时间if file_time < several_minutes_ago_str:# 如果该文件是指定分钟数以前的,删除os.remove(os.path.join("chat-content/", filename))
至于保存的txt文档一直在变大的问题,其实也可以判断大小清除就好啦,毕竟是文本内容,暂不考虑,暂不实现。
串成线
前面几个基本可以串起来了,在语音唤醒之后的动作部分把几个函数方法体串起来就可以了。
# 开始语音识别
for phrase in speech:print("识别到的语音内容:", phrase)word_heared = str(phrase)if word_heared == "如果":print("我被唤醒了,您请说话!")# 语音识别人类说话you_said_txt = convert_audio_to_text()# 调用AI的API将语音识别内容发送,并将回答取回ai_answer_text = get_questions_ai_answer(you_said_txt)# 语音播报AI的回答say_txt_as_audio(ai_answer_text)# 为了不长期占用磁盘空间,只保存当前时间算起几分钟以内的mp3音频文件,其他生成的mp3文件进行删除delete_mp3_files_several_minutes_ago(3)
上面把关键词设成了【如果】,至于为什么设成如果,是因为这个模型的错误率实在太高了,试了几个词这个词相对能听清,测试嘛,就用它了。整体执行下来还可以。
问题与想法
整体跑起来,主要有两点问题,一个是响应速度,在询问问题后到播放出语音来间隔时间有点长,再琢磨吧。再有一个问题就是这个唤醒的错误率太高了,我说了好多次【如果】它才有一次识别对了。这个貌似可以通过更换模型来解决。可模型查了查,不好搞,暂先搁置吧。
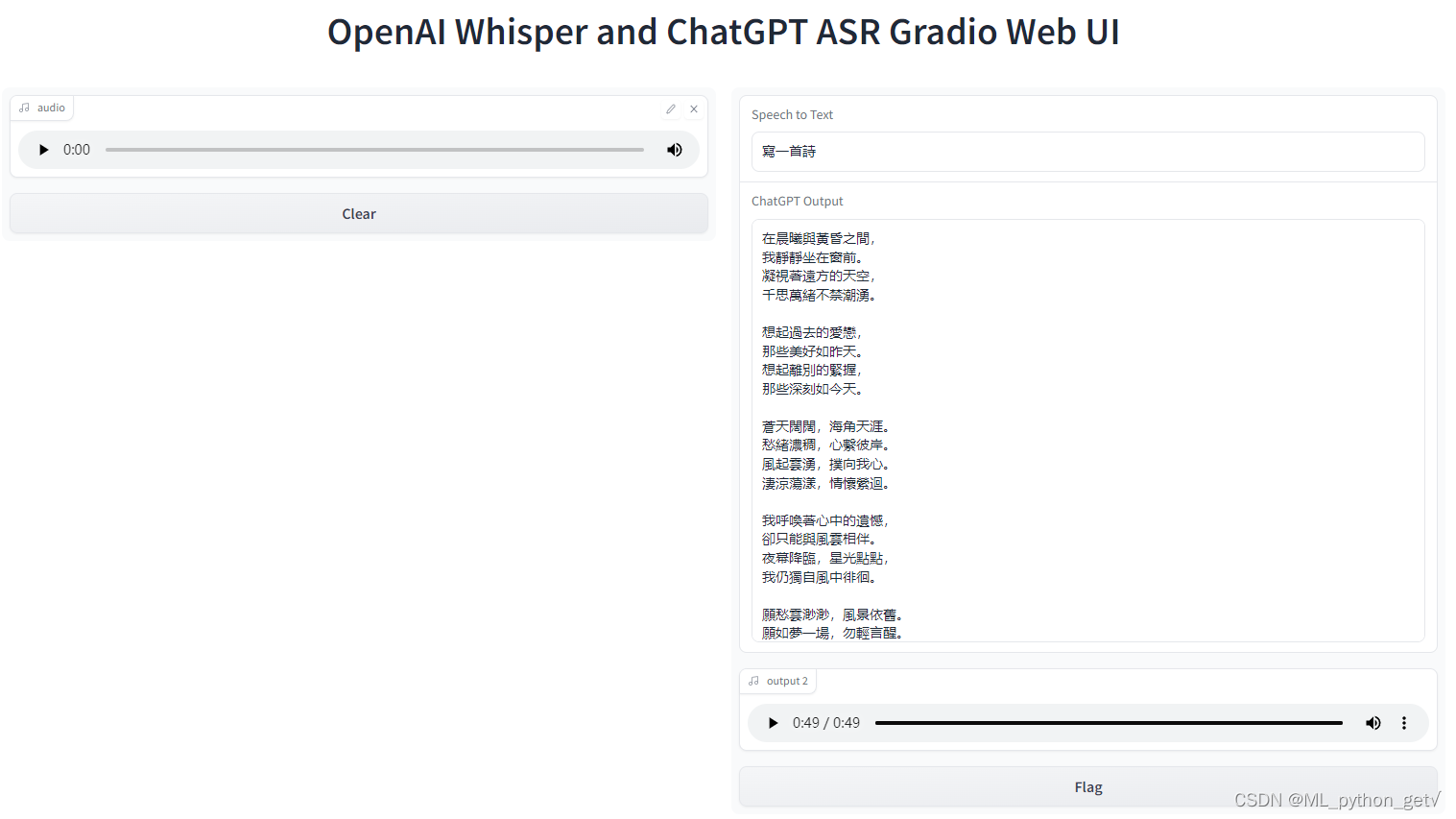
还有一点想法,可以整出一个应用界面来,就一个钮,点击可以问ai问题,看文字回答并收听语音朗读。或者还可以进行设置,达到实时监听唤醒词。当然可能会考虑更多东西才可以。这两天摸鱼,搞了这么个东西,聊以记录一下。
PS:翻出了几年前获赠的google home mini,原来只当个小音箱,现在忽然想想是否可以让google assistant 连openai呢。由于openai是预训练模型能不能实时与assistant切换呢。在Actions on Google上可以搞定的么,有空再研究一下。