GPU的硬件结构
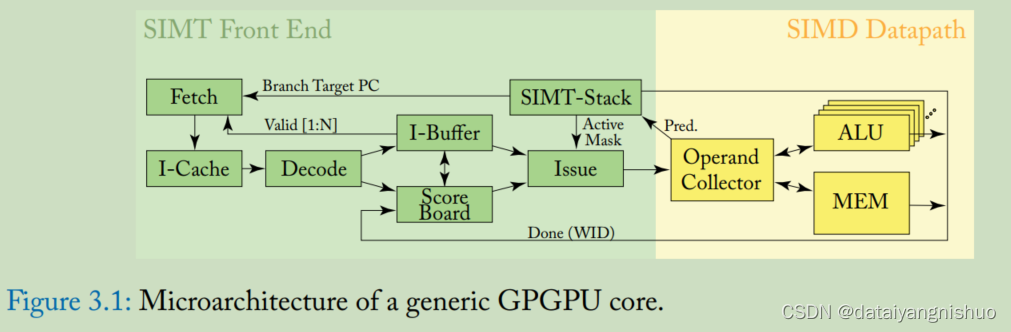
GPU通过一个可扩展的多线程流式多处理器(SMs)构建。一个multiprocessor可以在同一时间处理上百个线程。为了管理这些线程,使用一个特殊的结构SIMT。利用单线程中指令级的并行,以及同步硬件多线程实现的广泛线程级并行性。
SIMT Architecture
warps:32个并行线程组。
组成warps的独立线程在同一个程序地址同时启动,但是他们分别由各自的指令地址计数器和寄存器状态,也因此可以自由的分支和独立执行。意思是,half-warp在一个warp中可以是前一个也可以是后一个。
当multiprocessor给了一个或者多个线程块去执行时,它会将块分成warps,为了执行,每一个warps都可以被warps调度器(warps scheduled)调度。划分warps 的方式是相同,每一个warp中包含一组连续的线程,这些线程我们可以通过线程ID获取,从第一个包含线程ID为0的warps开始,线程ID递增。
在同一时刻,一个warp执行一个共同的指令。当warp中的线程都在同一个执行路径时,效率会完全展现,但是如果warp中的线程因为不同的数据依赖而不得已出现分支,warp会执行每一条分支,但是会禁用不在这条执行路径上的线程。这种分支发散的情况仅仅出现在warp中。注意,不同的warp可以独立执行,不管它们执行的是否是同一个代码指令。
因为SIMT可以指定单个线程的发散和执行,程序员可以写出一个独立的,可以扩展的以及协作线程数据并行的线程级代码。通过独立的线程调度,GPU维护每个线程的执行状态,包括程序计数器和调用堆栈,并可以以每个线程的粒度产生执行,以更好地利用执行资源或允许一个线程等待另一个线程生成数据。调度优化器来确定如何将来自同一个warp的线程组织到SIMT单元中。
Hardware Multithreading
在warp的整个生命周期内,多处理器处理的每个warp的执行上下文(程序计数器、寄存器等)都在芯片上维护。因此,从一个执行上下文切换到另一个执行上下文是没有代价的,并且在每个指令发出时,warp调度器都会选择一个具有准备好执行其下一条指令的线程(warp的活动线程)的warp,并向这些线程发出指令。
对于给定内核,可以驻留在多处理器上并一起处理的块和扭曲的数量取决于内核使用的寄存器和共享内存的数量以及多处理器上可用的寄存器和共享内存的数量。如果multiprocessor没有足够的寄存器或共享内存来处理至少一个块,内核将无法启动。
一个block中warp的数量如下:
c e i l ( T W s i z e , 1 ) ceil(\frac{T}{W_{size}},1) ceil(WsizeT,1)
T是block中的线程数量
W_size是warp的大小,这里等于32
Programmer Model
Kernel
CUDA C++ 可以通过核函数扩展到C++。当它被调用时,它被N个不同的CUDA线程执行N次。使用特殊的声明符号__global__定义各一个核函数,CUDA线程的数量在核函数调用时使用<<<…>>>运算符配置。每一个执行核函数的CUDA线程都有不同的线程ID。
下面有一个例子,将两个大小为N的vector相加,加过放在C:
// Kernel definition
__global__ void VecAdd(float* A, float* B, float* C)
{int i = threadIdx.x;C[i] = A[i] + B[i];
}int main()
{...// Kernel invocation with N threadsVecAdd<<<1, N>>>(A, B, C);...
}
每一个线程都会执行Vecadd(),完成一对元素相加的任务。
Thread Hierarchy (线程等级)
threadIdx是一个三分量向量,因此可以使用一维、二维或三维线程索引来识别线程,形成一维、二维或三维线程块。在跨域中的元素(如向量、矩阵或体积),这提供了一种调用计算的自然方式。
线程索引和线程ID之间有一个明确的关系。对于一维线程块来说,它们是一样的。对于二维来说(Dx,Dy),线程索引(x,y)的线程ID是(x+yDx);对于三维的线程块(Dx,Dy,Dz),线程索引(x,y,z)的线程ID是(x+yDx+zDxDy)。
例子,下面代码是将两个NxN的矩阵相加
// Kernel definition
__global__ void MatAdd(float A[N][N], float B[N][N],float C[N][N])
{int i = threadIdx.x;int j = threadIdx.y;C[i][j] = A[i][j] + B[i][j];
}int main()
{...// Kernel invocation with one block of N * N * 1 threadsint numBlocks = 1;dim3 threadsPerBlock(N, N);MatAdd<<<numBlocks, threadsPerBlock>>>(A, B, C);...
}
每一个线程块的数量是有限制的,因为一个块的所有线程都应该驻留在同一个处理器内核上,并且必须共享该内核的有限内存资源。在目前的GPUs中,一个线程块包含1024个线程。但是,内核可以由多个形状相同的线程块执行,因此线程总数等于每个块的线程数乘以块数。块被组织到一个线程块网格中。网格中线程块的数量通常由正在处理的数据的大小决定,该大小通常超过系统中的处理器数量。

每一个块中的线程数量和每一个网格中块的数量可以在<<<…>>>中用int或者dim3来配置。
更新MatAdd()
// Kernel definition
__global__ void MatAdd(float A[N][N], float B[N][N],
float C[N][N])
{int i = blockIdx.x * blockDim.x + threadIdx.x;int j = blockIdx.y * blockDim.y + threadIdx.y;if (i < N && j < N)C[i][j] = A[i][j] + B[i][j];
}int main()
{...// Kernel invocationdim3 threadsPerBlock(16, 16);dim3 numBlocks(N / threadsPerBlock.x, N / threadsPerBlock.y);MatAdd<<<numBlocks, threadsPerBlock>>>(A, B, C);...
}
16x16(256个线程)的线程块大小是常见的选择。网格是用足够多的块创建的,与以前一样,每个矩阵元素有一个线程。为简单起见,此示例假设每个维度中每个网格的线程数可以被该维度中每个块的线程数平均整除。
线程块是独立执行的,必须能够以任何顺序并行或串联执行它们。这种独立性要求允许线程块按任意顺序在任意数量的内核上调度,从而使程序员能够编写随内核数量扩展的代码。如图一样

块内的线程可以通过共享内存共享数据,并通过同步执行来协调内存访问来进行协作。共享内存应该是靠近每个处理器核心的低延迟内存。
Memory Hierarchy
CUDA线程在执行期间可以访问多个内存空间中的数据。每一个线程都有一个私有本地内存,每一个线程块都有一个块内线程都可见的共享内存,它和线程块有相同的生命周期。还有一个所有线程都可以访问的全局内存。
有两个对所有线程只读的内存空间:常量内存和texture内存。全局,常量和texture通过不同的内存使用方式优化。全局、常量和texture内存空间在同一应用程序启动的内核中是持久的。

Heterogeneous Programming(异构编程)
CUDA编程模型假设CUDA线程在物理上独立的设备(device)上执行,该设备作为运行C++程序的主机(host)的协处理器运行。意思就是,核函数在GPUs上执行,其余的C++程序在CPU上执行。CUDA编程模型假设主机和设备都在DRAM上维持着它们自己独立的内存空间,分别是主机内存和设备内存。因此,程序可以通过调用CUDA运行时API来管理内核中可见的全局、常量和texture内存空间。包括设备内存的分配和释放,主机与设备之间的转换。
统一内存提供托管内存(managed memory),以桥接主机和设备内存空间。可从系统中的所有CPU和GPU访问托管内存,并将其作为具有公共地址空间的单个一致内存映像进行访问,此功能可以实现设备内存的过度订阅,并且可以通过消除在主机和设备上显式镜像数据的需要,大大简化移植应用程序的任务。(Unified Memory provides managed memory to bridge the host and device memory spaces. Managed memory is accessible from all CPUs and GPUs in the system as a single, coherent memory image with a common address space. This capability enables oversubscription of device memory and can greatly simplify the task of porting applications by eliminating the need to explicitly mirror data on host and device.)。

Asynchronous SIMT Programming Model(异步SIMT编程模型)
在CUDA编程模型中,做计算和内存管理时,线程是最低级的抽象概念。异步编程模型定义了关于CUDA线程的异步操作行为。
Asynchronous Operations
An asynchronous operation is defined as an operation that is initiated by a CUDA thread and is executed asynchronously as-if by another thread。
这样一个异步线程(as-if thread)总是与启动异步操作的CUDA线程相关联。异步操作使用同步对象同步操作的完成。我一段我不太理解它在说什么,还没学到位。我把原文放在这里。
An asynchronous operation is defined as an operation that is initiated by a CUDA thread and is executed asynchronously as-if by another thread. In a well formed program one or more CUDA threads synchronize with the asynchronous operation. The CUDA thread that initiated the asynchronous operation is not required to be among the synchronizing threads.
Such an asynchronous thread (an as-if thread) is always associated with the CUDA thread that initiated the asynchronous operation. An asynchronous operation uses a synchronization object to synchronize the completion of the operation. Such a synchronization object can be explicitly managed by a user (e.g., cuda::memcpy_async) or implicitly managed within a library (e.g., cooperative_groups::memcpy_async).
A synchronization object could be a cuda::barrier or a cuda::pipeline. These objects are explained in detail in Asynchronous Barrier and Asynchronous Data Copies using cuda::pipeline. These synchronization objects can be used at different thread scopes. A scope defines the set of threads that may use the synchronization object to synchronize with the asynchronous operation. The following table defines the thread scopes available in CUDA C++ and the threads that can be synchronized with each.
| Thread Scope | Description |
|---|---|
| cuda::thread_scope::thread_scope_thread | Only the CUDA thread which initiated asynchronous operations synchronizes. |
| cuda::thread_scope::thread_scope_block | All or any CUDA threads within the same thread block as the initiating thread synchronizes. |
| cuda::thread_scope::thread_scope_device | All or any CUDA threads in the same GPU device as the initiating thread synchronizes. |
| cuda::thread_scope::thread_scope_system | All or any CUDA or CPU threads in the same system as the initiating thread synchronizes. |
Compute Capability
设备的计算能力被表示为它的版本号,也被称为"SM version"。此版本号标识GPU硬件支持的功能,并由应用程序在运行时使用,以确定当前GPU上可用的硬件功能和/或指令。
计算能力包括主要修订号X和次要修订号Y,并用X.Y表示。相同的主修订号版本设备有相同的核心架构。主修订号为8的核心架构是NVIDA Ampere GPU,7是Volta,6是Pascal,5是Maxwell,3是Kepler,2是Fermi,1是Tesla。次要修订号对应于核心架构的增量改进,可能包括新功能。
Turing是计算能力7.5的架构,这是在Volta架构上增量式的改进。