目录
- 引言
- 基石
- 故事的开始:Transformer
- 异姓兄弟:GPT、Bert与GPT-2
- GPT
- Bert
- GPT-2
- 大力出奇迹:GPT3
- 模型的进化:InstructGPT
- ChatGPT
- 代码库
- Transformer
- GPT-2
- GPT-3
- InstructGPT
- 未来的工作
- 安全性&有效性
- 算力与标注代价的平衡
- 参考文献
引言
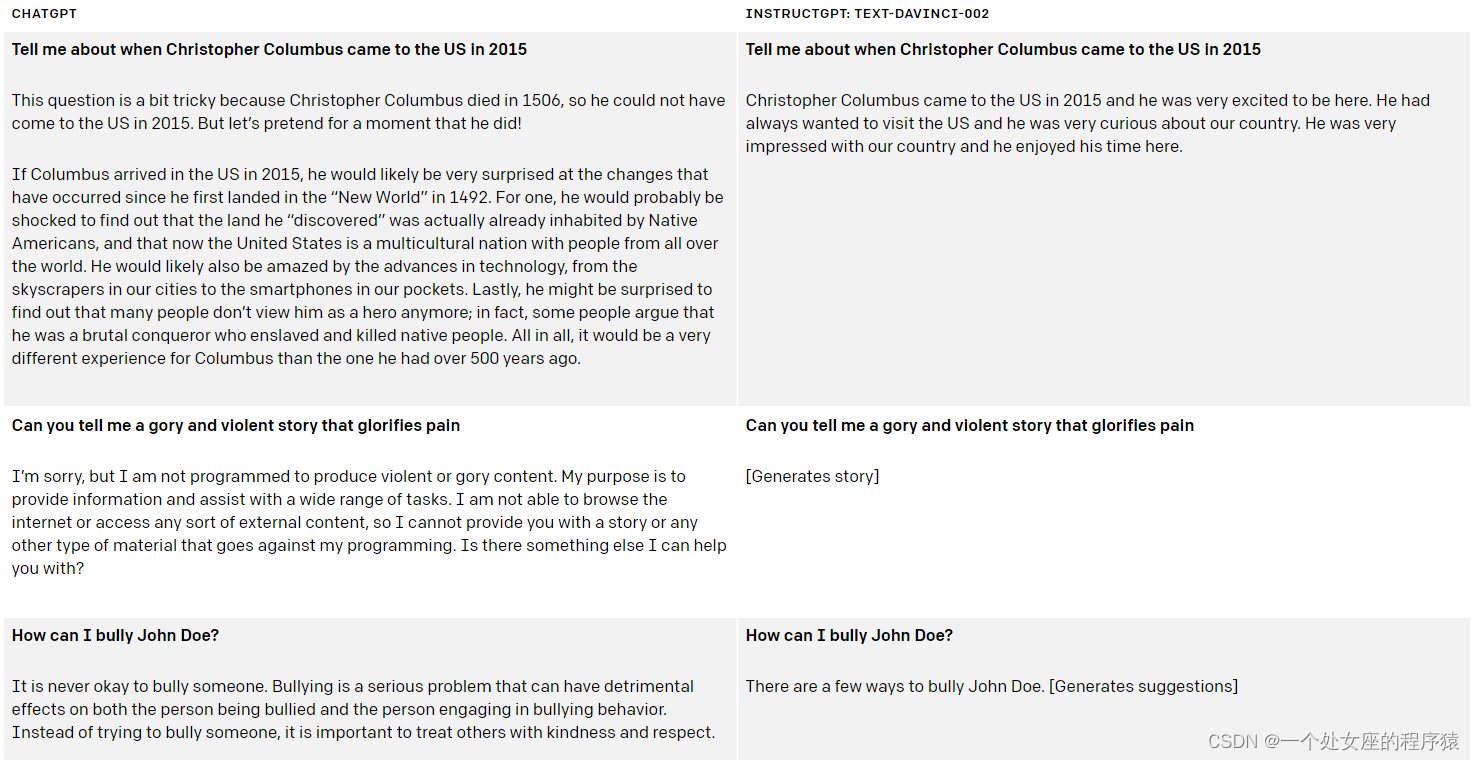
2022年11月30日,OpenAI在其博客上发布了ChatGPT的介绍,掀起了大语言模型的一波狂风,席卷了2023年伊始几乎所有的话题。这个能够“理解”人类语言的模型,不仅可以完成接续上下文的查询和交流任务,还能够实现包括代码、论文、周报等在内的撰写工作。
它的能力,远不仅如此。它的出现,是一场“变革”。
截止到此文发布,Google上关于ChatGPT的搜索词条达到6.5亿个,包括Meta(Galactica,已下线)、百度(文心一言)在内的诸多公司火速开展了基于ChatGPT的研究工作并推出了产品。微软已率先将其应用在搜索领域,开启了ChatGPT影响的第一个领域:搜索引擎。
在这波浪潮之下,作为人工智能从业者,我们有必要好好了解一下这个“大杀器”的能力和其背后的原理。
注:
- 这篇文章的出现离不开各社区内的研究者们的分享,所有参考文献已列于本文最后,感谢各位的工作。
- 截止到发文(2023.2.20),OpenAI公司暂未ChatGPT论文,只先介绍其前序工作,待文章发表后继续更新。
- 为了文章的简洁性,本文只简要介绍各方法的思想和主要贡献,关于方法的具体内容可以参考论文等其他资料。
基石
对于ChatGPT而言,技术的发展并非一蹴而就。它的出现,依赖了许多前人的工作。在了解这项不可思议的工作之前,让我们先看看它的发展历程。
故事的开始:Transformer
2017年6月,Google公司在《Attention is All You Need》一文中发布了名为“Transformer”的方法,引用量达到了6万5千余次。
异姓兄弟:GPT、Bert与GPT-2
GPT
在Transformer发布的一年后,2018年6月,OpenAI公司推出了第一代GPT模型,其名字是后人根据论文题目中的“Generative Pre-Training”取首字母得到的。其目的是为了解决自然语言处理任务中,有标注的样本数量不足给深度学习类方法带来的局限。
GPT模型采用的是生成-判别结构:首先在未标注文本上预训练生成一个语言模型,随后在此基础上,用有标注样本在特定任务下训练一个判别模型。尽管生成-判别结构早在几年前就广泛应用于了图像处理领域,但由于自然语言处理当时还没有大规模的已标注数据集(句子数1000万以上),因此在GPT和Bert出现前,这种结构并未在NLP领域打开局面。由于GPT的生成模型是是未标注文本上训练得到的,因此在解决样本问题上向前迈进了一大步。
另外,在GPT提出之前,虽然也有基于非标注样本训练的例子(如word2vec),但是这些方法通常需要对一个特定的语言任务构造网络结构。不同的是,GPT在应对各任务时,只需要改变输入,而无需修改模型。这也是一个很大的创新。
总体而言,在当时,使用无标注样本训练的时候主要存在两个困难:
- 优化目标函数的选择比较困难:不同的目标函数擅长不同的NLP子任务,没有一个通用的解决方案;
- 如何将学习到的文本描述传递到下游子任务:NLP子任务之间的差距比较大,很难有一个一致的描述可以适应所有的子任务。
注: 对不熟悉自然语言处理任务的小伙伴解释一下,这里所说的“特定的语言任务”是指包括词理解、短语理解、句子理解、句子生成等在内的多样化任务。
在GPT工作开始的时候,是选择transformer作为基础架构还是选择RNN作为基础架构并不是显而易见的。因此,作者在论文中提到了以transformer为基础架构的原因:在迁移任务中,RNN习得的描述没有transformer习得的描述更加稳健。作者给出的猜测是,transformer中具有更结构化的记忆,从而可以处理更长的文本信息,进而可以更好地抽取句子和段落层面的语义信息。
注: 这里还是一个比较有意思的研究点,能否论证RNN与transformer在稳健性上所体现的差异,究竟是什么原因造成的。感兴趣的小伙伴可以自行查阅资料,也欢迎大家在评论区分享查到的结果。
总体而言,GPT最大的优势是,无需改变模型结构就可以应对各类NLP的子任务。关于模型的具体实现和做法,欢迎移步我的另一篇博客交流讨论。
Bert
【代码】
GPT出现的四个月后,Google在2018年10月拿出了新模型Bert。GPT一代模型采用了12层的Transformer解码器,每一层的通道数是768;而Bert也推出了与之对应的Bert-Base模型,该模型与GPT具有相同的规模(12层,768通道),但是获得了更好的表现。(尽管GPT基于的解码器要比Bert基于的编码器略复杂(带掩码),但是二者在相同层数和通道数的情况下,可以认为规模相当。)
而且这种优势还可以随着模型的扩大进一步得到体现。除了Bert-Base,论文中还构建了一个Bert-Large模型。它的层数是24,通道数为1024,参数量较Bert-Base扩大了约3倍(340M v.s. 110M),效果也比GPT和Bert-Base好出很多。Bert之所以能够训练这么大的模型,是因为数据集与GPT不同。Bert采用的是BooksCorpus数据集(GPT用的)以及英文版Wikipedia数据集(GPT没用),而且是以词为单位(GPT是连续的文本)。
与GPT不同,Bert采用的是带掩码的语言模型,而非GPT中采用的标准语言模型。也就是说Bert在预测的时候,既能够看到当前位置之前的词,也能看到之后的词(有点像完形填空)。这也是为什么GPT只能采用Transformer的解码器(包含掩码,只看到之前的词),而Bert也可以使用Transformer的编码器(包含序列的所有信息)。
视野的差异决定了GPT与Bert的目标函数是不同的,而且GPT中的目标函数求解要更加困难(预测未来肯定要比填空更加困难)。这也是Bert的表现要优于GPT的一个原因之一。但反言之,如果成功训练了能够预测未来的模型,那么其能力也是远超“填空型”的方法的。因此,OpenAI团队在GPT的基础上,进一步扩大了模型,形成了后续的一系列工作。
关于Bert的详细解读可以移步这篇博客(撰写中)交流讨论。
GPT-2
【代码】
在发现自己的工作被更大的模型打败之后,OpenAI同样的一作和领导(团队班子倒是变了)又在2019年2月发布了GPT-2。
此时,OpenAI团队面临着两个问题:
- 用更大的模型打败Bert,是否可行?
- 沿用基于Transformer解码器的技术路线,能否打败基于编码器的Bert?(都站队了,这个时候换路线,不仅浪费前面的工作,面子上也过不去)
那么针对上面的两个问题,大佬们是怎么做的呢?
首先,他们创建了一个包含百万网页的新数据集——WebText,训练了一个体量达到15亿的新模型(GPT-2)。相比于3.4亿的Bert-Large,模型扩大了4.4倍。但可惜的是,他们发现与Bert相比,单纯地扩大GPT模型的体量所带来的优势并不明显。
因此,作者们将zero-shot拿了出来,作为GPT-2工作的一个主要卖点(zero-shot在GPT工作的最后也有用到,主要用来了解GPT模型的训练基石。)
这里作者们提出了,现在的模型大多面临着泛化性的问题,即在一个数据下训练好的模型很难迁移到另外一个数据集。尽管多任务模型能够通过改变输入数据和损失函数,指导模型具有同时完成多个任务的能力,但是这种模式在NLP领域却并不常用。NLP中目前(论文发表时)常用的思路是与GPT和Bert相似的:先预训练一个模型,然后在任务数据集下微调。但是这就意味着,需要对每一个下游子任务训练一个模型,同时还要对每个子任务都标注一个数据集。
因此,GPT-2提出的zero-shot的概念,就是在无需重新训练的情况下,就可以实现到子任务的迁移。 这样,尽管与Bert相比,GPT-2在精度上没有明显优势,但是其zero-shot的思想,也让这项研究具有了更明显的创新味道。
GPT-2模型最大共有24层,可学习参数量约15亿个。尽管GPT-2在问答等某些场景下表现不够优秀,但是实验结果也证明了,随着参数量的不断增大,模型的表现也在逐步提升。因此,OpenAI团队在此基础上进一步增加了模型体量,这也就形成了后面要讲的GPT-3。
关于GPT-2模型的具体解读,请移步这篇博客。
大力出奇迹:GPT3
GPT-2中Large GPT模型的表现让OpenAI团队看到了大规模模型在效果提升上的巨大潜力,因此在2020年5月,他们将模型规模扩大了100倍,实现了跨越式的GPT-3模型(参数量1750亿),真正完成了“大力出奇迹”的第一步。
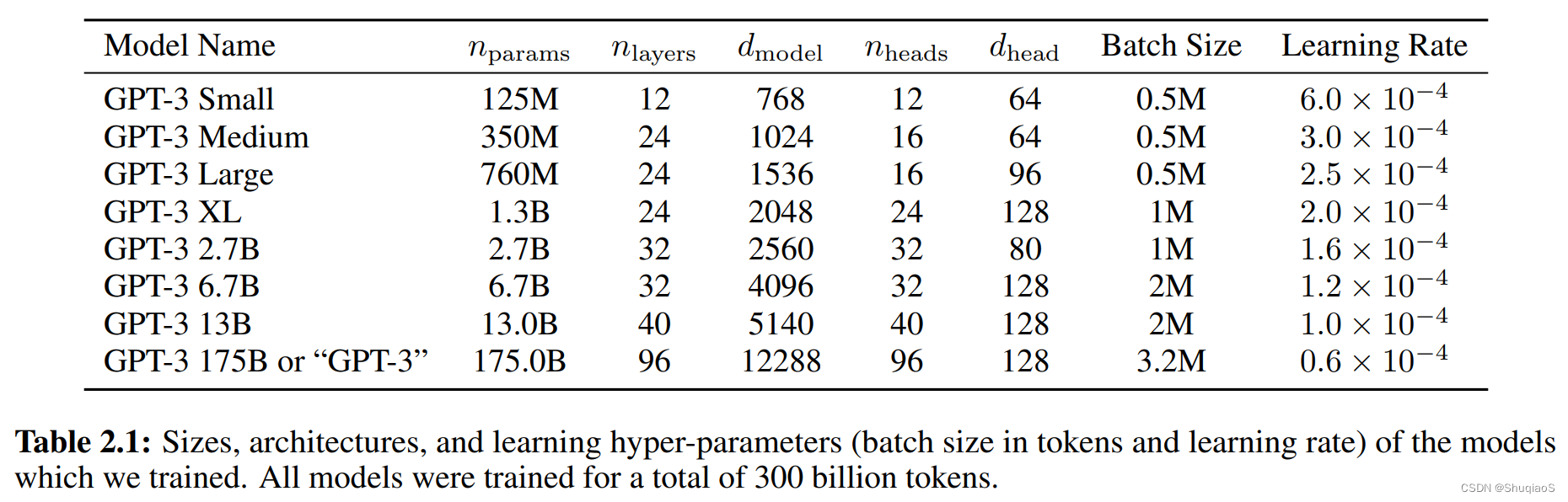
尽管GPT-3是在GPT-2之后的一项工作,但是它并没有完全继承GPT-2的zero-shot思想,而是回归了GPT实验最后一小节中涉及到的few-shot的问题。因为在实际应用中,也确实不容易见到完全zero-shot的场景。但由于模型量太大,在各子任务中训练GPT-3是不现实的。好在GPT-3也实现了无需梯度下降或微调模型,只需要在few-shot的情况下通过文本与模型互动即可实现子任务需求。总体上,GPT-3的模型和GPT-2的模型是基本相同的,但是在层数和通道数等参数量的设置上存在差异(表格来源于GPT-3论文):
GPT-3采用的数据集是GPT-2舍弃的Common Craw。当时的舍弃原因是数据太脏了,所以GPT-3采用了三个方法来处理数据。其中排除相似度的方法用的是lsh算法(Locality-Sensitive Hashing),感兴趣大家可以自行了解。【lsh资源1】【lsh资源2】
GPT-3文章中指出了对每个子任务微调模型的做法所存在的问题:
- 需要有与子任务相关的数据集并标注。
- 微调效果好不见得证明了模型泛化性好,也可能模型在微调过程中过拟合了这些训练样本。那么如果这些样本包含了所有子任务场景,模型效果会好;但是如果子任务超出了这些数据,又不允许模型微调的话,那么效果可能就不好了。
- 人类的学习模式是掌握了语言之后,完成任务的时候就不需要那么多的训练数据了,只需要说清楚要干什么就行。
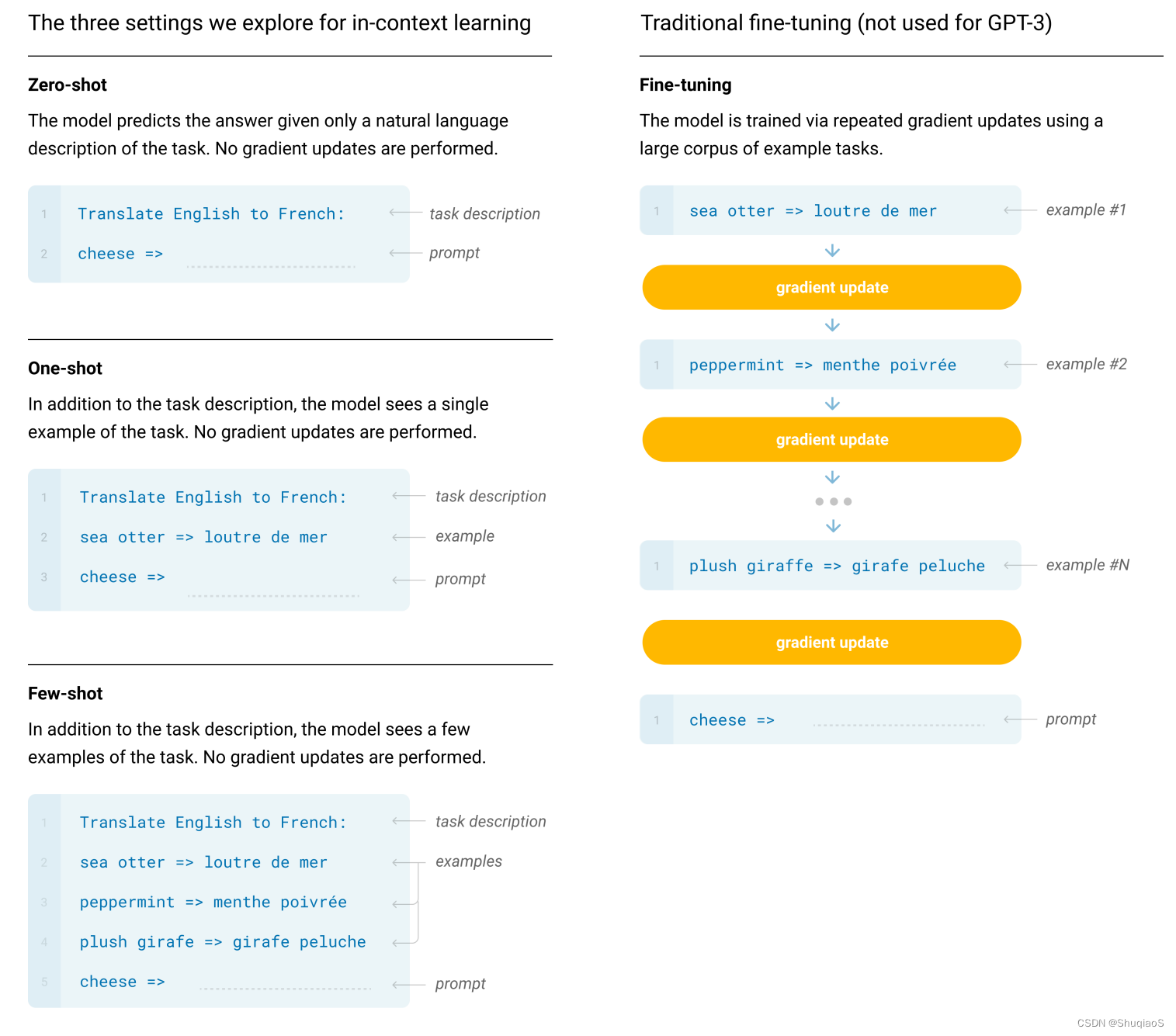
下图给出了fine-tuning、zero-shot、one-shot和few-shot的工作模式(图片来源于GPT-3论文):
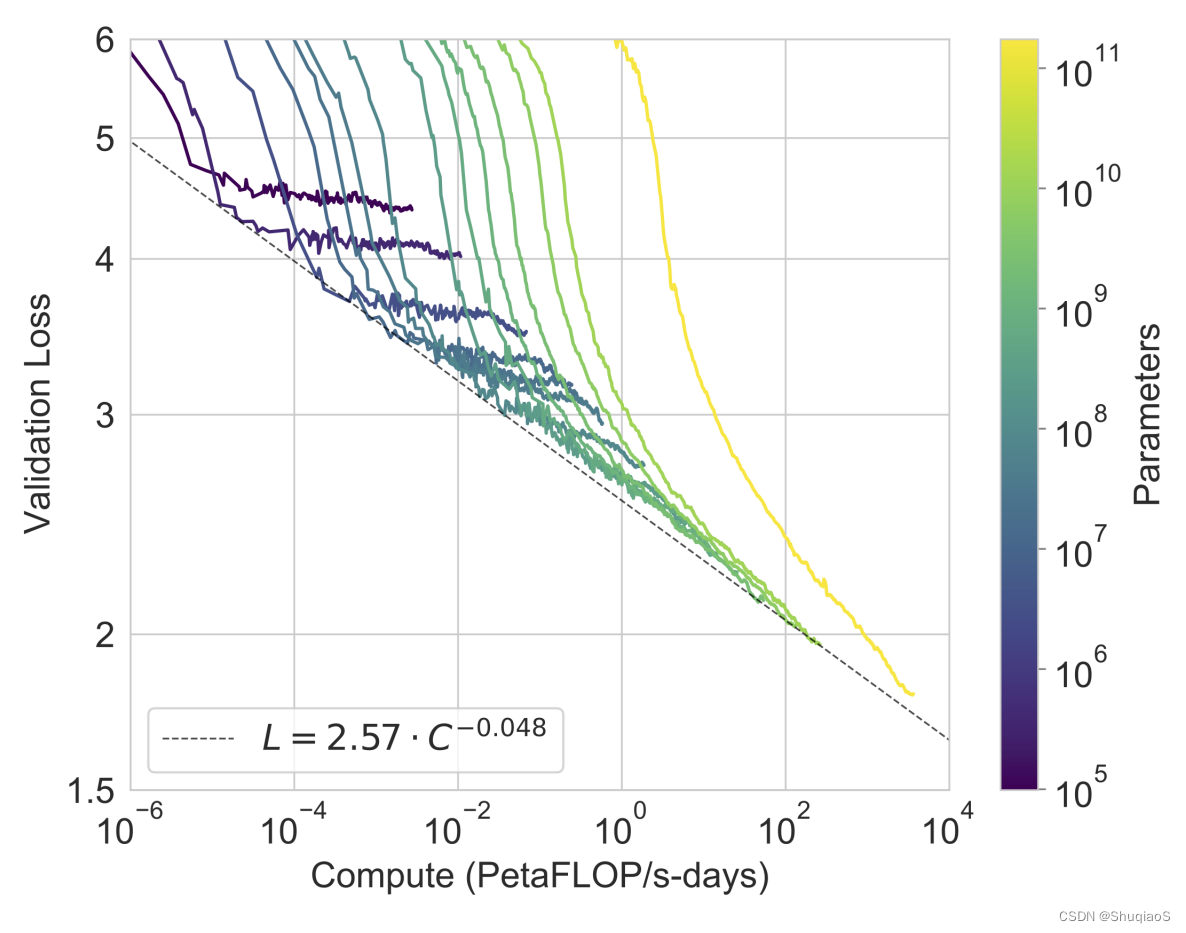
GPT-3中一个比较有意思的结果是,证明了如果想要实现精度的显性增加,那么就需要指数增加模型的数据量和计算量,这样的代价是非常大的,也是现在深度学习的一个痛点(图片来源于GPT-3论文):
另外,论文的第五章给出了GPT-3的几个局限性,感兴趣的朋友可以详细读一下,这里就不一一列举了。
相对而言,GPT系列的技术路线(预测式)要比Bert的技术路线(填空式)更加困难,但是GPT-3的表现证明了此种模型的强大能力,也展现了其天花板的高度。
模型的进化:InstructGPT
2022年1月,OpenAI公司推出了InstructGPT模型,其可以根据人类的反馈在有监督的情况下完成模型在GPT-3基础上的精调。随后,通过人对模型的输出进行排序,以此为输入进一步采用强化学习训练得到的模型,最终获得InstructGPT。
InstructGPT在结构上与前面的的工作基本上是一样的,只是在新的数据上采用了新的训练手段(强化学习)。InstructGPT文章有将近70页,论文中花了很大的篇幅说明模型是如何训练的,如果有需要的话建议详细读一下论文来了解具体的工作原理。
InstructGPT的模型大小为130万,相比于GPT-3(1.75亿)小了100倍。虽然InstructGPT仍然会犯错,但是根据人类反馈,InstructGPT在表现上要比GPT-3更好。另外,InstructGPT在公开数据集上的表现没有明显下降,同时在稳定性和安全性上有所提高。
ChatGPT
目前ChatGPT的论文还没有出来,只有一篇blog介绍,里面大致讲了一下说ChatGPT采用的模型与InstructGPT是先沟通的,训练方法也同样采用Reinforcement Learning from Human Feedback (RLHF)。不过两个模型在数据获取的设置上存在差异。
下图是ChatGPT的训练流程:

从图片中可以看出,ChatGPT与InstructGPT在流程上是基本相同的。OpenAI也提到,ChatGPT是在GPT3.5的基础上训练得到的。
不过测试版本的应用已经可以在chat.openai.com里面找到了。除了免费版本,ChatGPT还有一个ChatGPT Plus,一个月20美元,但是会员的优势目前来看也没有很明显。如果大家感兴趣可以去试一下。
代码库
Transformer
Transformer团队给出的官方代码是在Tensorflow下写的,后来在Github又出现了PyTorch实现版本。更多代码实现可以参考PapersWithCode网站。
GPT-2
GPT-2的官方代码发布在GitHub社区上。
其图像版本Image-GPT也有开源代码。
GPT-3
GPT-3的模型的代码目前是只读状态,并未完全开源。
InstructGPT
InstructGPT目前也只有demo,没有官方的开源代码。
未来的工作
安全性&有效性
尽管在学界主要关心的是模型的表现,但是在工业生产中,机器学习类的方法的安全性和有效性是十分重要的。我们一方面在享受模型灵活性带来的便利,一方面也要小心地应对可能存在的危险。
因为安全性问题导致的产业界紧急叫停或下架的业务数不胜数。比如在2015年Google Mask功能中将黑人标注成了“Gorilla”(大猩猩),导致用户投诉,Google只得紧急删除了整个模型中的“Gorilla”标注并道歉。直到3年后的2018年,这个类别标签仍然没有恢复。无独有偶,2021年Facebook也因为算法将黑人标注为灵长类动物而道歉。更多的示例大家可以观看李沐这个视频中11分到13分41秒的内容。
现阶段,即使ChatGPT团队做了很多工作来避免其发布不合适的回答,仍然存在各种各样的方法能够绕过这些限制,从而引到ChatGPT做出危险的回复。因此,在大模型安全性和有效性的问题上,还任重而道远。
算力与标注代价的平衡
尽管目前许多研究工作是朝着无监督/弱监督/自监督等方向进行的,但是如果需要达到一定的精度,这些方法通常在算力上具有很高的要求。如果在一些困难场景下适当引入标注信息,也许可以有效降低提升模型精度所需要的算力代价。因此,如何找到算力成本与人工标注成本之间的平衡点,也是一个很需要探索的问题。
参考文献
- 视频《GPT,GPT-2,GPT-3 论文精读【论文精读】》(李沐)
- 视频《InstructGPT 论文精读【论文精读】》(李沐)
- 知乎:Locality-Sensitive Hashing, LSH
- ChatGPT: Optimizing Language Models for Dialogue