常用设计模式
前言
我们经常听到一句话,“写代码要有良好的封装,要高内聚,低耦合”。究竟怎样的代码才算得上是良好的代码。
什么是高内聚,低耦合?
即五大基本原则(SOLID)的简写
- 高层模块不依赖底层模块,即为依赖反转原则。
- 内部修改关闭,外部扩展开放,即为开放封闭原则。
- 聚合单一功能,即为单一功能原则。
- 低知识要求,对外接口简单,即为迪米特法则。
- 耦合多个接口,不如独立拆分,即为接口隔离原则。
- 合成复用,子类继承可替换父类,即为里式替换原则
我们为什么要封装代码?
其实封装代码有这些好处:
- 良好的封装,不会让内部变量污染外部
- 封装好的代码可以作为一个模块给外部调用。外部无需了解细节,只需按约定的规范调用。
- 对扩展开放,对修改关闭,即开放关闭原则。外部不能修改内部代码,保证了内部的正确性;又留出扩展接口,提高了灵活性。
我们可以观察React、Vue、EventEmitter、Axios等等这些优秀的源码,会发现其实他们封装的模块都是有迹可循的。这些规律总结起来就是设计模式。
什么是设计模式?
借用鲁迅先生说过的一句话,世上本没有路,走的人多了也便成了路。所谓设计模式,是前辈们总结下来的,在软件设计、开发过程中,针对特定场景、特定问题的较优解决方案。
为什么需要设计模式?
实际上,不使用设计模式,照样可以进行需求开发。但是这造成的后果是:因设计缺陷、代码实现缺陷,给后期维护、开发、迭代带来了麻烦。
设计模式
设计模式一共分为3大类23种,主要介绍常用的几种
| 模式类型 | 设计模式 |
|---|---|
| 创建型模式 | 单例模式、工厂模式、建造者模式 |
| 结构型模式 | 适配器模式、装饰器模式、代理模式 |
| 行为型模式 | 策略模式、观察者模式、发布订阅模式、职责链模式、中介者模式 |
单例模式
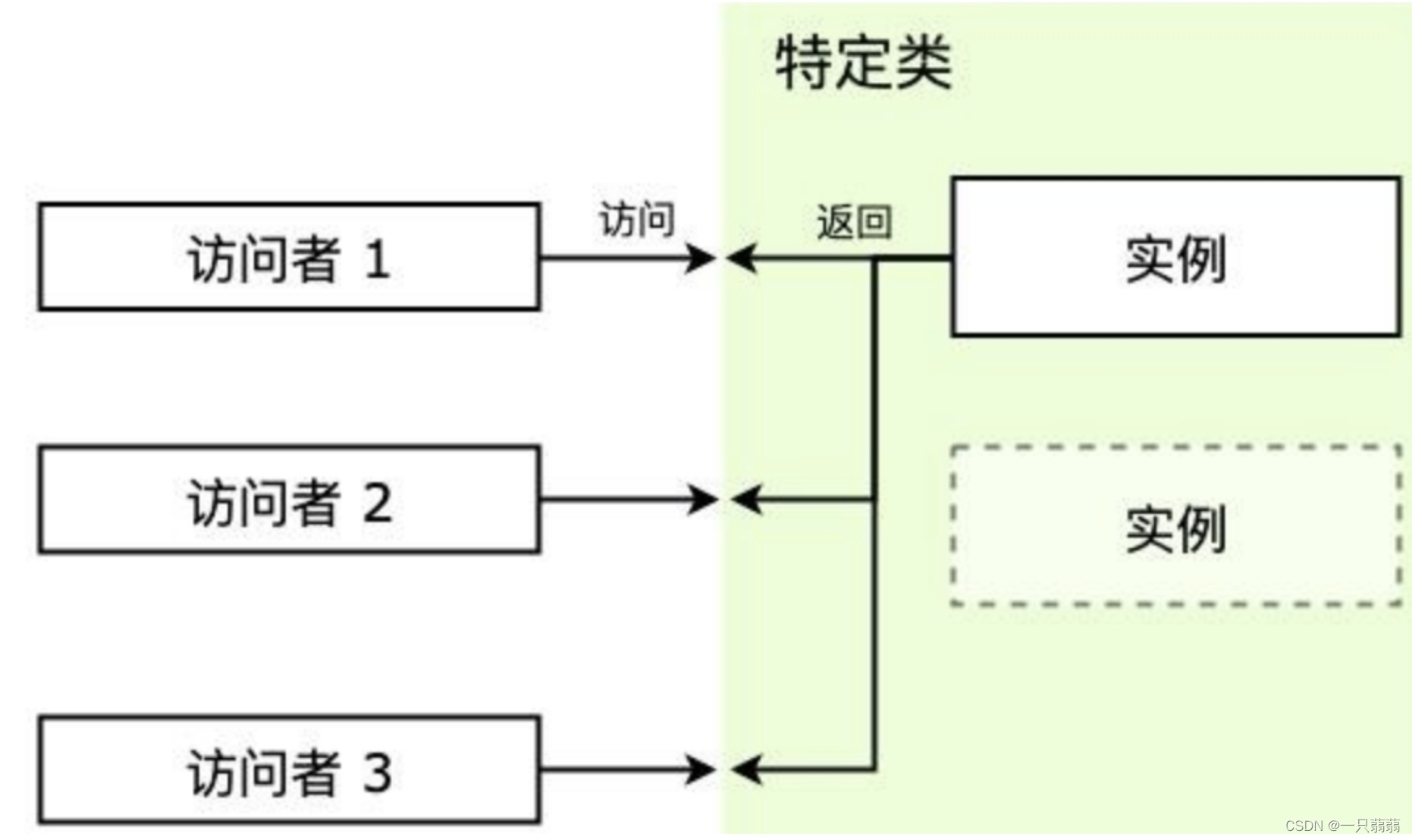
单例模式:一个类只有一个实例,并提供一个访问他的全局访问点。
Singleton:特定类,这是我们需要访问的类,访问者要拿到的是它的实例;
instance:单例,是特定类的实例,特定类一般会提供getInstance方法来获取该单例;
getInstance:获取单例的方法;
class Singleton {let _instance = null;static getInstance() {if (!Singleton._instance) {Singleton.instance = new Singleton()}// 如果这个唯一的实例已经存在,则直接返回return Singleton._instance}
}const s1 = Singleton.getInstance()
const s2 = Singleton.getInstance()console.log(s1 === s2) // true
源码实例
Vuex 源码中的单例模式
Vuex:实现了一个全局的store用来存储应用的所有状态。这个store的实现就是单例模式的典型应用。
// 安装vuex插件
Vue.use(Vuex)// store注入Vue实例
new Vue({el:"$app",store
})
通过调用Vue.use方法,安装Vuex插件。Vuex插件本质上是一个对象,内部实现了一个install方法,这个方法在插件安装时被调用,从而把Store注入到Vue实例中。
let Vue // instance 实例export function install (_Vue) {// 判断传入的Vue实例对象是否已经被install过(是否有了唯一的state)if (Vue && _Vue === Vue) {if (process.env.NODE_ENV !== 'production') {console.error('[vuex] already installed. Vue.use(Vuex) should be called only once.')}return}// 若没有,则为这个Vue实例对象install一个唯一的VuexVue = _Vue// 将Vuex的初始化逻辑写进Vue的钩子函数里applyMixin(Vue)
}
通过这种方式,可以保证一个 Vue 实例只会被 install 一次 Vuex 插件,所以每个 Vue 实例只会拥有一个全局的 Store。
优缺点
优点: 节约资源,保证访问的一致性。
缺点: 扩展性不友好,因为单例模式一般自行实例化,没有接口。
使用场景
- 如果一个类实例化过程消耗资源比较多,可以使用单例避免性能浪费
- 需要公共状态,可以使用单例保证访问一致性。
工厂模式
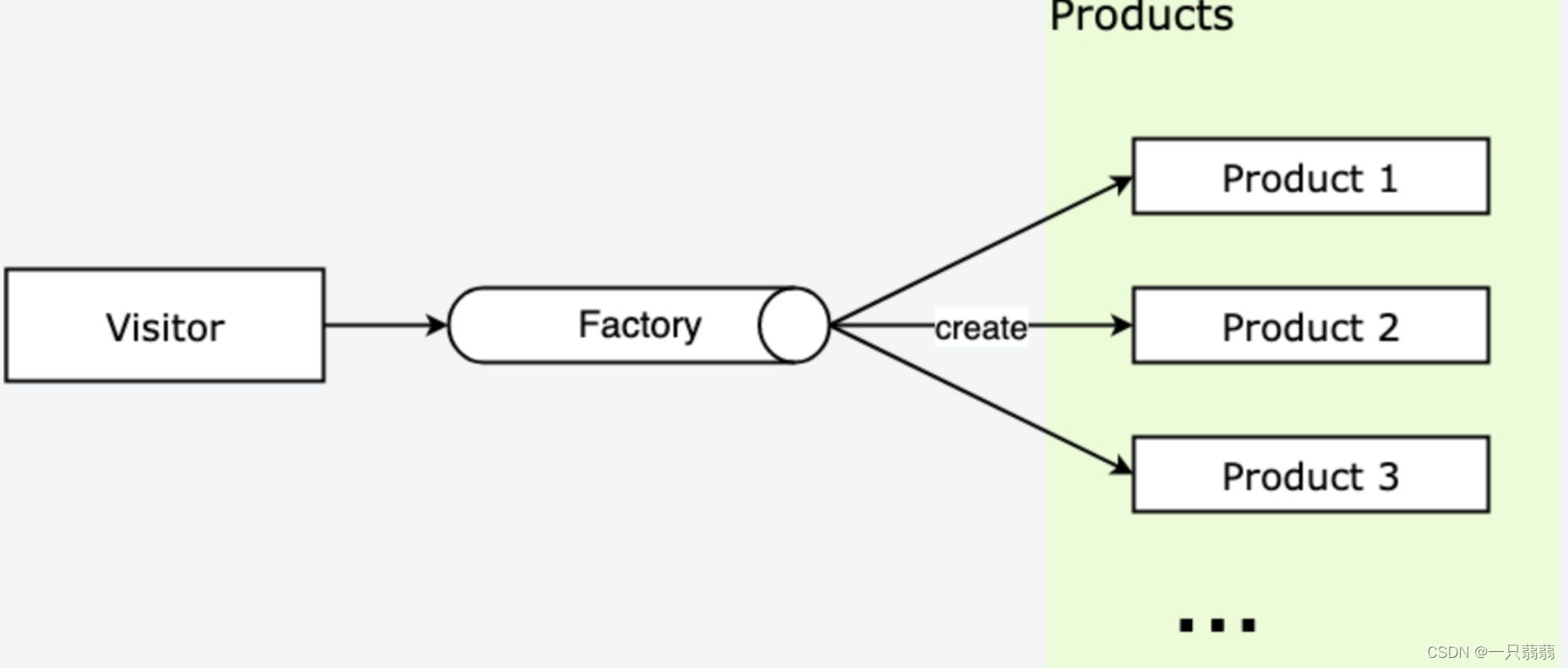
工厂模式:根据不同的参数,返回不同类的实例。
核心思想:将对象的创建与对象的实现分离。实现复杂,但使用简单。工厂会给我们提供一个工厂方法,我们直接去调用即可。
- Visitor :访问者,访问工厂方法。
- Factory :工厂,负责返回产品实例;
- Product :产品,访问者从工厂拿到的产品实例;
🌰 例子
我们去环球影城的餐厅吃饭,点了一份“牛肉拉面”、“馄饨云吞面”,面煮好了,就直接端到桌子上,我们只管吃,不用在乎煮面的过程。
这个过程中,我们扮演访问者的角色,餐厅扮演的就是工厂的角色,“xxx”面就是产品。
class Restaurant{constructor(){this.menuData = {};}// 获取菜品getDish(dish){if(!this.menuData[menu]){console.log("菜品不存在,获取失败");return;}return this.menuData[menu];},// 添加菜品addMenu(menu,description){if(this.menuData[menu]){console.log("菜品已存在,请勿重复添加");return;}this.menuData[menu] = menu;}// 移除菜品removeMenu(menu){if(!this.menuData[menu]){console.log("菜品不存在,移除失败");return;}delete this.menuData[menu];},
}class Dish{constructor(name,description){this.name = name;this.description = description;}eat(){console.log(`I'm eating ${this.name},it's ${`this.description);}
}
这些场景都有一些特点:使用者只需要知道产品名字就可以拿到实例,不关心创建过程。所以我们可以把复杂的过程封装在一块,更便于使用。
源码实例
Vue、React 源码中的工厂模式
document.createElement创建DOM元素。这个方法采用的就是工厂模式,方法内部很复杂,但外部使用很简单。只需要传递标签名,这个方法就会返回对应的DOM元素。
和原生的 document.createElement 类似,Vue 和 React 这种具有虚拟 DOM 树机制的框架在生成虚拟 DOM 的时候,都提供了 createElement 方法用来生成 VNode,用来作为真实 DOM 节点的映射。上面实现一致,调用createEle``ment后,返回VNode元素。
// 使用
ccreateElement('h3', { class: 'main-title' }, [createElement('p', { class: 'main-content' }, '真有意思')
])
// 函数大致结构如下
export function createElement(tag,data,children){//....各种判断 判断生成什么样的Vnodeif(!tag){return createEmptyVNode()}return new VNode(tag,data,children);
}
Vue-Router 源码中的工厂模式
vue-router 中使用了工厂模式的思想来获得响应路由控制类的实例,this.history 用来保存路由实例。
export default class VueRouter{constructotr(options){const mode = options.mode || "hash";switch (mode) {case 'history':this.history = new HTML5History(this, options.base)breakcase 'hash':this.history = new HashHistory(this, options.base, this.fallback)breakcase 'abstract':this.history = new AbstractHistory(this, options.base)breakdefault:if (process.env.NODE_ENV !== 'production') {assert(false, `invalid mode: ${mode}`)}}}
}
优缺点
优点:
- 良好的封装,访问者无需了解创建过程,代码结构清晰。
- 扩展性良好,通过工厂方法隔离了用户和创建流程,符合开闭原则。
- 解耦了高层逻辑和底层产品类,符合最少知识原则,不需要的就不要去交流;
缺点:
给系统增加了抽象性,带来了额外的系统复杂度,不能滥用。(合理抽象能提高系统维护性,但可能会提高阅读难度,还是需要合理看待)
使用场景
- 对象创建比较复杂,访问者无需了解创建过程。
- 需要处理大量具有相同/类似属性的小对象。
滥用只是增加了不必要的系统复杂度,过犹不及。
适配器模式
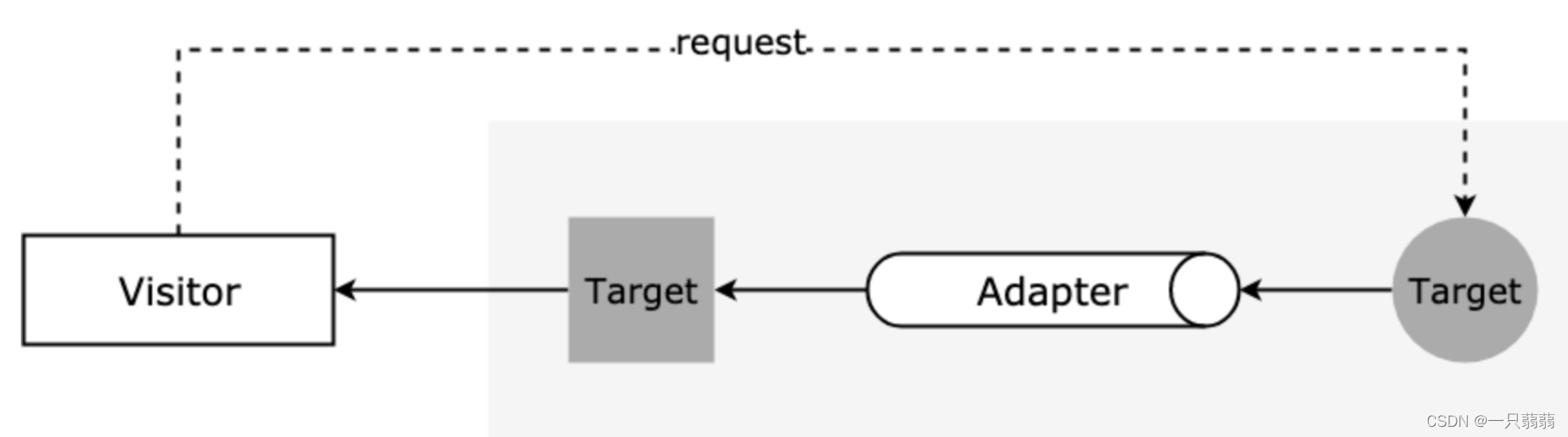
适配器模式:用于解决兼容问题,接口/方法/数据不兼容,将其转换成访问者期望的格式进行使用。
生活案例:
- 耳机转接线。圆孔耳机插不进TypeC的手机里,只需一个TypeC转接头,此时TypeC转接头就是“适配器”。
- 翻译官。老板张三去国外谈业务,带上翻译官李四,李四这个时候就是作为不同语言的人之间交流的“适配器”。
场景特点:
- 同时存在多种格式,旧有接口格式不满足现在需要。
- 增加适配器可以更好使用旧接口。
适配器模式必须包含目标(Target)、源(Adaptee)和适配器(Adapter)三个角色。
🌰 例子
场景:我们要获取通过多个接口获取列表数据,拼接在一起,在一个组件内进行展示。因历史遗留原因,这些列表数据的格式不太一样。
// 格式 1
{book_id: 1001status: 0,create: '2021-12-12 08:10:20',update: '2022-01-15 09:00:00',
},// 格式 2
{id: 1002status: 0,createTime: 16782738393022,updateAt: '2022-01-15 09:00:00',
},// 格式 3
{book_id: 1003status: 0,createTime: 16782738393022,updateAt: 16782738393022,
}
三个数据来源,三种时候数据结构,这时候我们有几种实现方式。
- 组件针对不同的数据来源分别采用不同的渲染。(需要对数据类型进行区分)
- 在外部将数据转换成一种数据格式的列表传入,组件单一职责:展示。
对比之下,使用适配器模式 ,将不同的数据结构适配成展示组件所能接受的数据结构。保持了组件的单一职责,更优。
- 定义一个统一的数据结构
interface bookData {book_id: number;status: number;createAt: string; // 时间戳updateAt: string; // 时间戳
}
- 通过适配器模块,适配成访问者所要数据格式
interface bookDataType1 {book_id: number;status: number;create: string;update: string;
}interface bookDataType2 {id: number;status: number;createTime: number;updateAt: string;
}interface bookDataType3 {book_id: number;status: number;createTime: number;updateAt: number;
}const getTimeStamp = function (str: string): number {//.....转化成时间戳return timeStamp;
};//适配器
export const bookDataAdapter = {adapterType1(list: bookDataType1[]) {const bookDataList: bookData[] = list.map((item) => {return {book_id: item.book_id,status: item.status,createAt: getTimeStamp(item.create),updateAt: getTimeStamp(item.update),};});return bookDataList;},adapterType2(list: bookDataType2[]) {const bookDataList: bookData[] = list.map((item) => {return {book_id: item.id,status: item.status,createAt: item.createTime,updateAt: getTimeStamp(item.updateAt),};});return bookDataList;},adapterType3(list: bookDataType3[]) {const bookDataList: bookData[] = list.map((item) => {return {book_id: item.book_id,status: item.status,createAt: item.createTime,updateAt: item.updateAt,};});return bookDataList;},
};
- 将数据经过适配器处理后进行整合,组件展示
//整合数据
const bookDataList = [...bookDataAdapter.adapterType1(type1MatailList),...bookDataAdapter.adapterType2(type2MatailList),...bookDataAdapter.adapterType3(type3MatailList),
];
优缺点
优点: 可以使原有逻辑得到更好的复用,有助于避免大规模改写现有代码;
缺点: 会让系统变得零乱,明明调用 A,却被适配到了 B,如果滥用,那么对可阅读性不太友好。
使用场景
- 想要使用一个已经存在的对象,但是接口不满足需求,那么可以使用适配器模式转换成你需要的接口。
- 想要创建一个可以复用的对象,而且确定需要和一些不兼容的对象一起工作,这种情况可以使用适配器模式。
装饰器模式
装饰器模式:在不改变原对象的基础上,增加新属性/方法/功能。
一个对象被另一个对象包装,形成一条包装链,在原对象上增加功能。
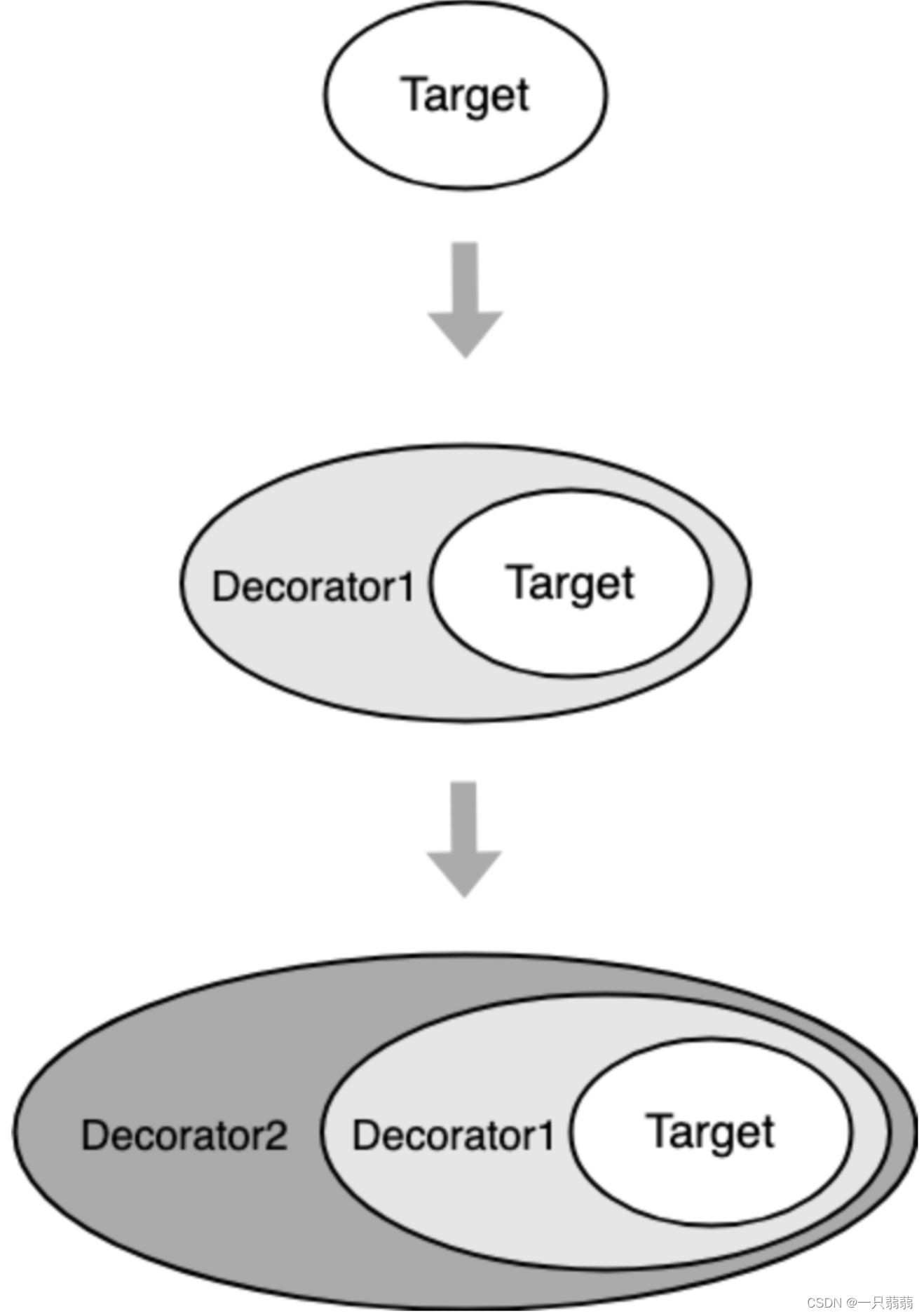
🌰 例子
暂时想不到什么好的例子和实际应用场景。
优缺点
优点:
- 对象的核心职责和装饰功能区分开,可以通过动态增删装饰去除目标对象中的装饰逻辑。
策略模式
策略模式:定义一系列算法,根据输入的参数决定使用哪个算法。
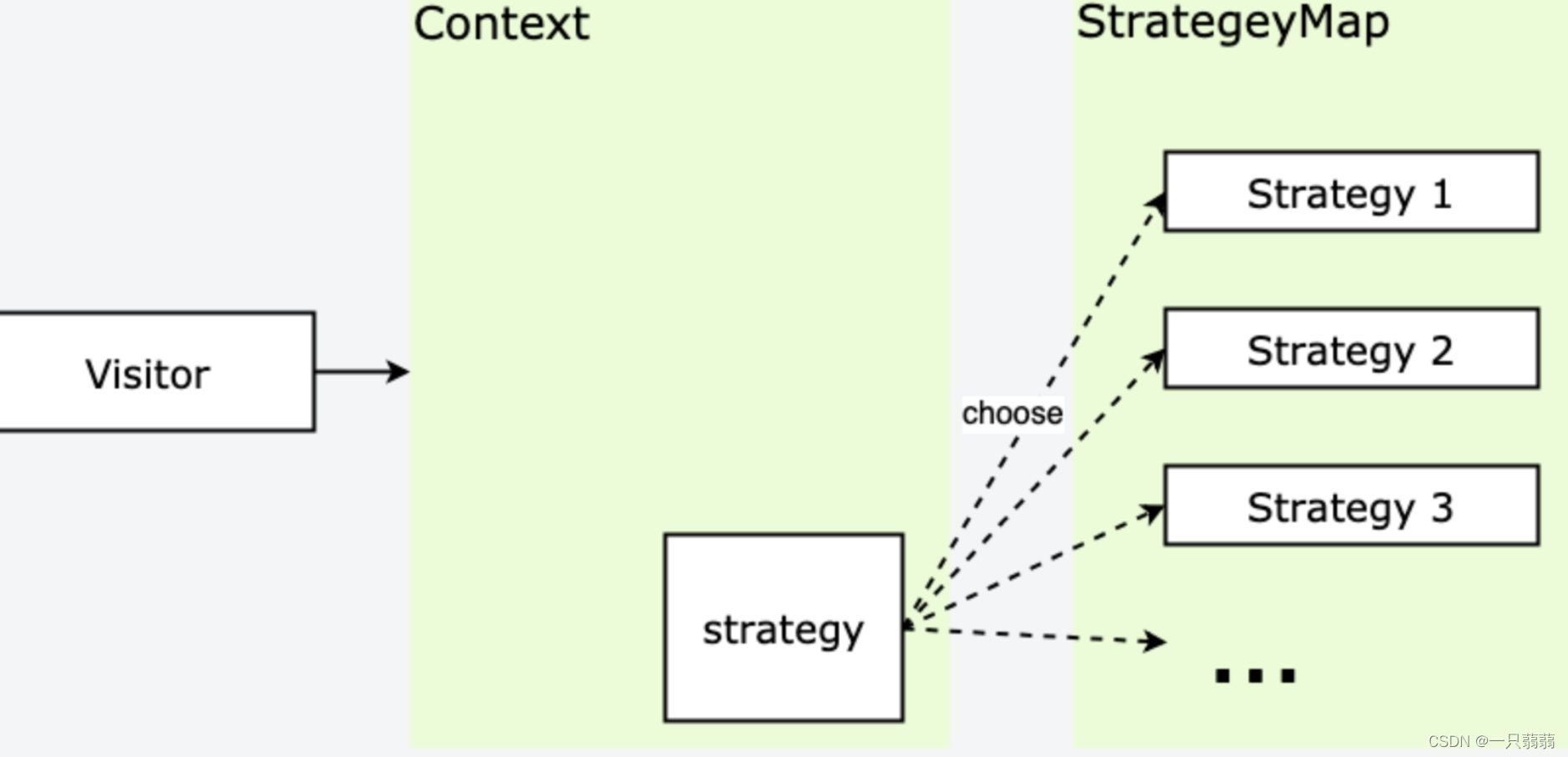
重点:算法的实现和算法的使用分开。
- Context :封装上下文,根据需要调用需要的策略,屏蔽外界对策略的直接调用,只对外提供一个接口,根据需要调用对应的策略;
- Strategy :策略,含有具体的算法,其方法的外观相同,因此可以互相代替;
- StrategyMap :所有策略的合集,供封装上下文调用;
🌰 例子
场景:双十一满减活动。满200-20、满300-50、满500-100。这个需求,怎么写?
if-else暴力法直接梭哈。
通过判断输入的折扣类型来计算商品总价的方式
function priceCalculate(discountType,price){if(discountType === 'discount200-20'){return price - Math.floor(price/200) * 20;}else if(discountType === 'discount300-50'){return price - Math.floor(price/300) * 50;}else if(userType === 'discount500-100'){return price - Math.floor(price/500) * 100;}
}
缺点:
- 随着折扣类型的增加,
if-else会变得越来越臃肿。
- 折扣活动算法改变或折扣类型增加时,都需要改动
priceCalculate方法,违反开闭原则。
- 复用性差,如果其他地方有类似的算法,但规则不一样,上述代码不能复用。
使用策略模式对代码改写
// 算法的实现
const discountMap = {'discount200-20': function(price) {return price - Math.floor(price / 200) * 20;},'discount300-50': function(price) {return price - Math.floor(price/300) * 50;},'discount500-100': function(price) {return price - Math.floor(price/500) * 100;},
}// 算法的使用
function priceCalculate(discountType,price){return discountMap[discountType] && discountMap[discountType](price);
}
以上代码就将算法的实现和算法的使用分开,以后不管增加或修改了算法,都无需对priceCalculate方法进行改动。
当然以上代码的抽象程度并不高,如果我们想隐藏计算算法,可以借助 IIFE 使用闭包的方式,提供一个添加策略的方法。
const priceCalculate = (function(){const discountMap = {'discount200-20': function(price) {return price - Math.floor(price / 200) * 20;},'discount300-50': function(price) {return price - Math.floor(price/300) * 50;},'discount500-100': function(price) {return price - Math.floor(price/500) * 100;},};return {addStategy(stategyName,fn){if(discountMap[stategyName]) return;discountMap[stategyName] = fn;},priceCal(discountType,price){return discountMap[discountType] && discountMap[discountType](price);}}
})()// 使用
priceCalculate.priceCal('discount200-20',250); // 230priceCalculate.addStategy('discount800-200',function(price){return price - Math.floor(price/800) * 200;
})
这样算法就被隐藏起来,并且预留了增加策略的入口,便于扩展。
场景:表单验证。
表单验证项一般会比较复杂,所以需要给每个表单项增加 validator 自定义校验方法。以ElementUI 的 Form 表单为例。
我们可以像官网示例一样把表单验证都写在组件的状态 data 函数中。
缺点:不好复用使用频率比较高的表单验证方法,造成代码冗余。
使用策略模式和函数 柯里化 对代码进行改写。
utils/validates.js为通用验证规则,即为StrategyMap。
utils/index.js中的formValidateGene通过柯里化动态选择表单验证方法,即为Context。
// src/utils/validates.js
// 姓名校验 由2-10位汉字组成
export function validateUsername(str) {const reg = /^[\u4e00-\u9fa5]{2,10}$/return reg.test(str)
}// 手机号校验 由以1开头的11位数字组成
export function validateMobile(str) {const reg = /^1\d{10}$/return reg.test(str)
}// 邮箱校验
export function validateEmail(str) {const reg = /^[a-zA-Z0-9_-]+@[a-zA-Z0-9_-]+(.[a-zA-Z0-9_-]+)+$/return reg.test(str)
}// src/utils/index.js
import * as Validates from './validates.js';export function formValidateGene = (key,msg) => {return function(rule,value,cb){if(Validates[key] && Validates[key](value)){cb()}else{cb(new Error(msg))}}
}// 使用
<script>import { formValidateGene } from '@/utils'export default {data() {return {ruleForm: {username: '',telephone: '',},rules: {username: [{ validator: formValidateGene('validateUsername','用户名格式为2~10个汉字,请重新输入'), trigger: 'blur' }],telephone: [{ validator: formValidateGene('validateMobile','手机号格式错误,请重新输入'), trigger: 'blur' }],}};}}
</script>
优缺点
优点:
- 策略相互独立,可以互相切换。提高了灵活性以及复用性。
- 不需要使用
if-else进行策略选择,提高了维护性。
- 可扩展性好,满足开闭原则。
缺点:
- 策略相互独立,一些复杂的算法逻辑无法共享,造成资源浪费。
- 用户在使用策略时,需要了解具体的策略实现。不满足最少知识原则,增加了使用成本。
使用场景
- 算法需要自由切换的场景。
- 多个算法只有行为上有些不同,可以考虑策略模式动态选择算法。
- 需要多重判断,可以考虑策略模式规避多重条件判断。
观察者模式
观察者模式:一个对象(称为subject)维持一系列依赖于它的对象(称为observer),将有关状态的任何变更自动通知给它们(观察者)。
观察者模式中的角色有两类:观察者和被观察者。
- 观察者必须订阅内容改变的事件,定义一对多的依赖关系。
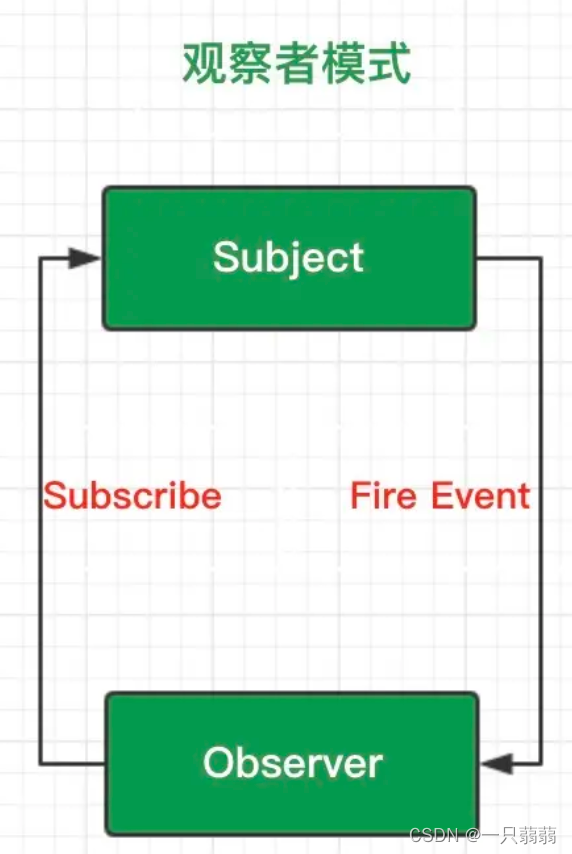
生活中的例子:领导(被观察者)在台上介绍防疫政策,底下的工作人员(观察者)“观察”领导说的防疫政策的变化,当政策变化时,通知(update)到街道。
工作人员(观察者)必须订阅内容改变的事件,即用耳朵去听政策的变化。
🌰 例子
简单的代码基本实现
// 观察者模式 被观察者Subject 观察者Observer Subject变化 notify观察者
let observerIds = 0;// 被观察者Subject
class Subject {constructor() {this.observers = [];}// 添加观察者addObserver(observer) {this.observers.push(observer);}// 移除观察者removeObserver(observer) {this.observers = this.observers.filter((obs) => {return obs.id !== observer.id;});}// 通知notify观察者notify() {this.observers.forEach((observer) => observer.update(this));}
}// 观察者Observer
class Observer {constructor() {this.id = observerIds++;}update(subject) {// 更新}
}
优缺点
优点:目标变化就会通知观察者,这是观察者模式最大的优点。
缺点: 不灵活。目标和观察者是耦合在一起的,要实现观察者模式,必须同时引入被观察者和观察者才能达到响应式的效果。
使用场景
发布-订阅模式
发布/订阅模式:基于一个主题/事件通道,希望接收通知的对象(称为subscriber)通过自定义事件订阅主题,被激活事件的对象(称为publisher)通过发布主题事件的方式被通知。
发布-订阅模式的角色有两类:发布者和订阅者
- 使用一个主题通道,这个通道介于发布者和订阅者之间。
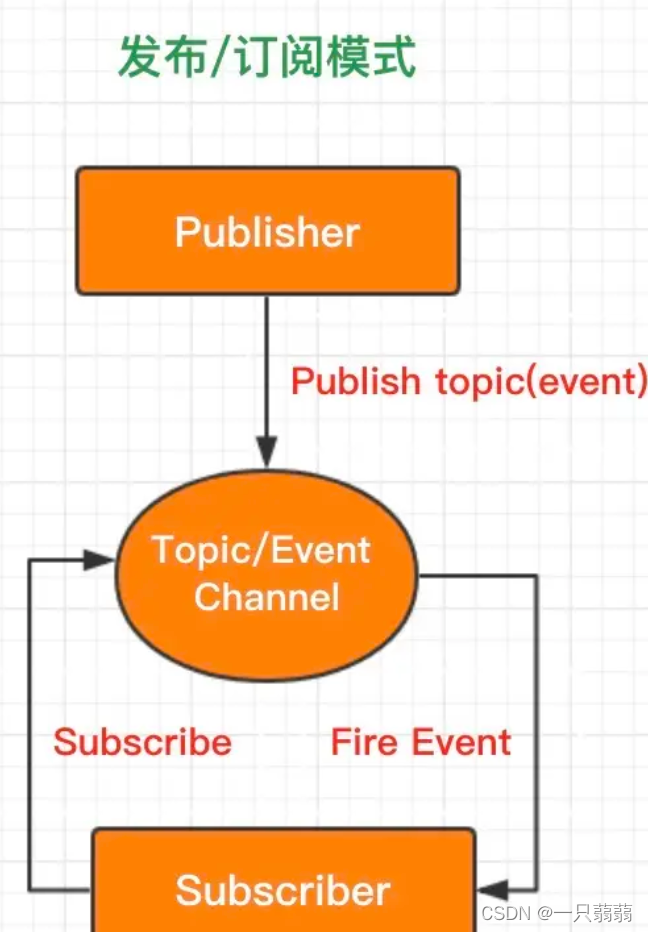
容
🌰 例子
我们微信会关注很多公众号,公众号有新文章发布时,就会有消息及时通知我们文章更新了。
这个时候公众号为发布者,用户为订阅者,用户将订阅公众号的事件注册到事件调度中心,当发布者发布新文章时,会发布事件至事件调度中心,调度中心会发消息告诉订阅者。
class Event {constructor() {this.eventEmitter = {};}// 订阅on(type, fn) {if (!this.eventEmitter[type]) {this.eventEmitter[type] = [];}this.eventEmitter[type].push(fn);}// 取消订阅off(type, fn) {if (!this.eventEmitter[type]) {return;}this.eventEmitter[type] = this.eventEmitter[type].filter((event) => {return event !== fn;});}// 发布emit(type) {if (!this.eventEmitter[type]) {return;}this.eventEmitter[type].forEach((event) => {event();});}
}
源码实例
Vue 双向绑定中的发布订阅模式
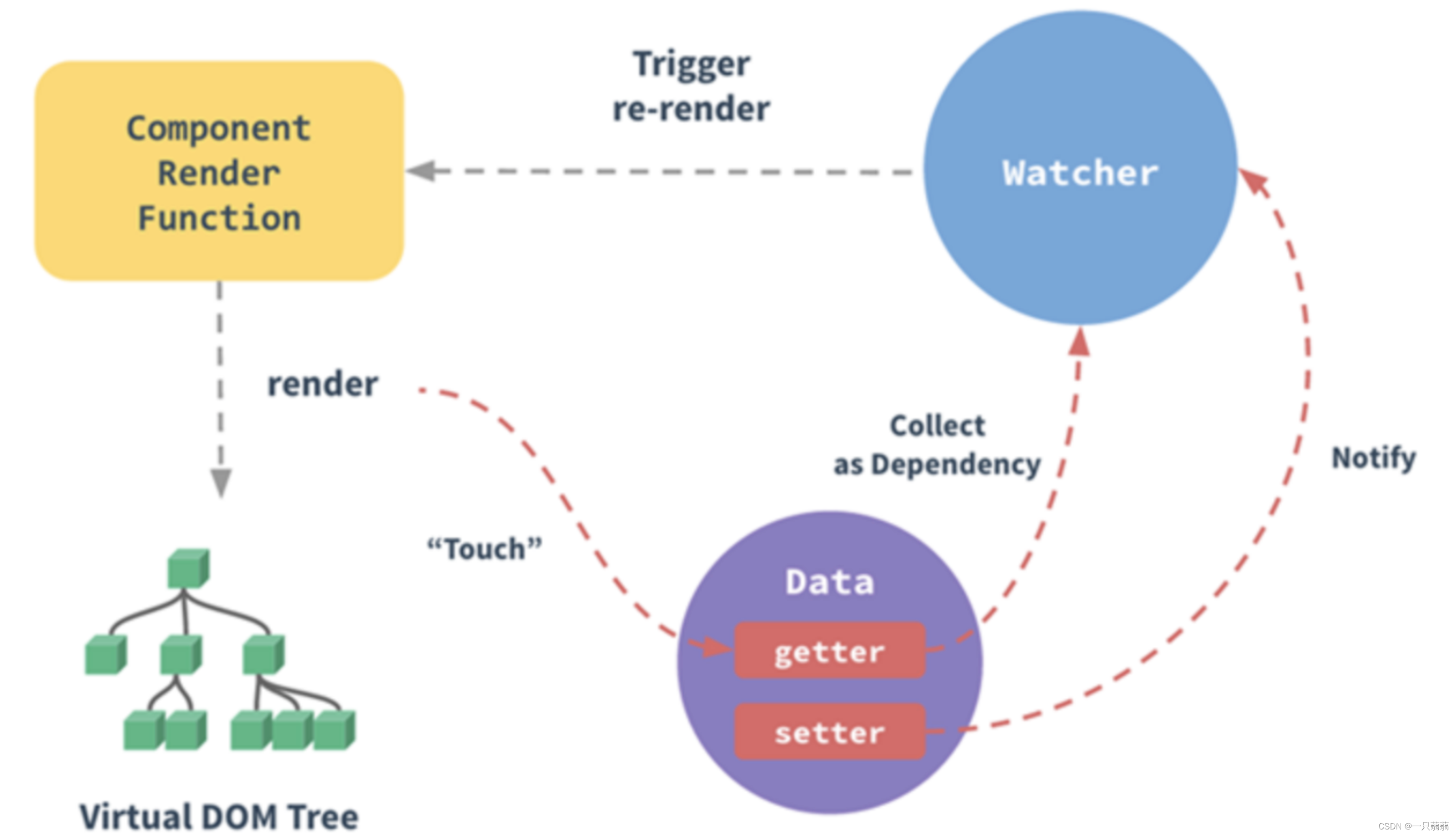
Vue 双向绑定通过数据劫持和发布-订阅模式实现。
- 通过
DefineProperty劫持各个数据的setter和getter,并为每个数据添加一个订阅者列表,这个列表将会记录所有依赖这个数据的组件。响应式后的数据相当于消息的发布者。
- 每个组件都对应一个
Watcher订阅者,当组件渲染函数执行时,会将本组件的Watcher加入到所依赖的响应式数据的订阅者列表中。相当于完成了一次订阅,这个过程叫做“依赖收集”。
- 当响应式数据发生变化时,会出
setter,setter负责通知数据的订阅者列表中的Watcher,Watcher触发组件重新渲染来更新视图。视图层相当于消息的订阅者。
EventEmitter
跟 🌰 差不多,略。
优缺点
优点:
- 时间解耦:注册的订阅行为由发布者决定何时调用,订阅者无需持续关注,由发布者负责通知。
- 对象解耦:发布者无需知道消息的接受者,只需遍历订阅该消息类型的订阅者发送消息,解耦了发布者和订阅者之间的联系,互不持有,都依赖于抽象。
缺点:
- 资源消耗:创建订阅者需要一定的时间和内存。
- 增加复杂度:弱化了联系,难以维护调用关系,增加了理解成本。
使用场景
- 各模块相互独立
- 存在一对多的依赖关系
- 依赖模块不稳定、依赖关系不稳定
- 各模块由不同的人员开发