在事务机制中,锁机制是为了保证高并发,数据一致性的重要实现方式。MySQL除了Innodb引擎层面的行锁,还有latch锁。latch锁的作用资源协调处理。包含表句柄,线程,cpu线程,内存池等。其保证非常短时间内快速处理的同时,通过wait,loop方式进行队列,实现资源协调。期间这些资源被互斥锁“保护”,不存在死锁机制,通过队列机制处理。
比如:两个线程,两个用户会话同时执行一个查询,需要访问相同的资源(一个文件、一个缓冲区或一些数据)时,这两个线程相互竞争。因此,第一个获取互斥锁的查询会导致另一个查询等待,直到第一个查询完成并解锁互斥锁。MySQL持有互斥锁时执行的工作被称为“critical section临界区”,虽然数据库本身的处理机制里实现了并行方式,但底层资源确实以序列化方式(一次一个)执行这个临界区, 这是一个潜在的瓶颈。
临界资源的使用的信号量(mutex互斥量),就是为了不同线程占有的资源,在硬件资源(cpu,内存,io,网络)里有效的使用的方式。
Mutex实现和理解
MySQL 8.0版本对mutex进行了拆分,其实现3种mutex锁, 2种策略的实现方式:
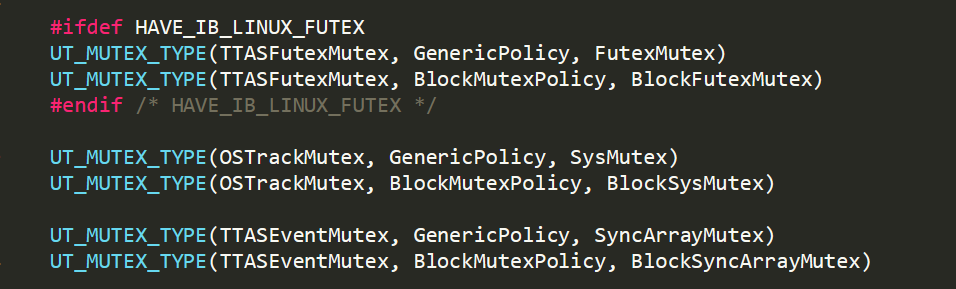
- TTASFutexMutex:spin + futex的实现, 在mutex_enter 之后, 会首先spin 然后在futex 进行wait。
通过这些状态唤醒进程。【futex是linux内核为用户空间实现锁等同步机制而设计的同步排队(队列queueing)服务】。 - OSTrackMutex:在系统自带的mutex上进行封装, 增加统计计数,通过state状态。
- TTASEventMutex: InnoDB使用的自己实现的Mutex, 使用spin + event 的实现。
这两种策略(GenericPolicy,BlockMutexPolicy)主要的区别在于在show engine innodb mutex 的时候不同的统计方式.
- BlockMutexPolicy 用于统计所有buffer pool使用的mutex, 该Mutex特别多, 如果每一个bp单独统计, 浪费大量的内存空间,。
- GenericPolicy 用于除了buffer pool mutex以外的其他地方。
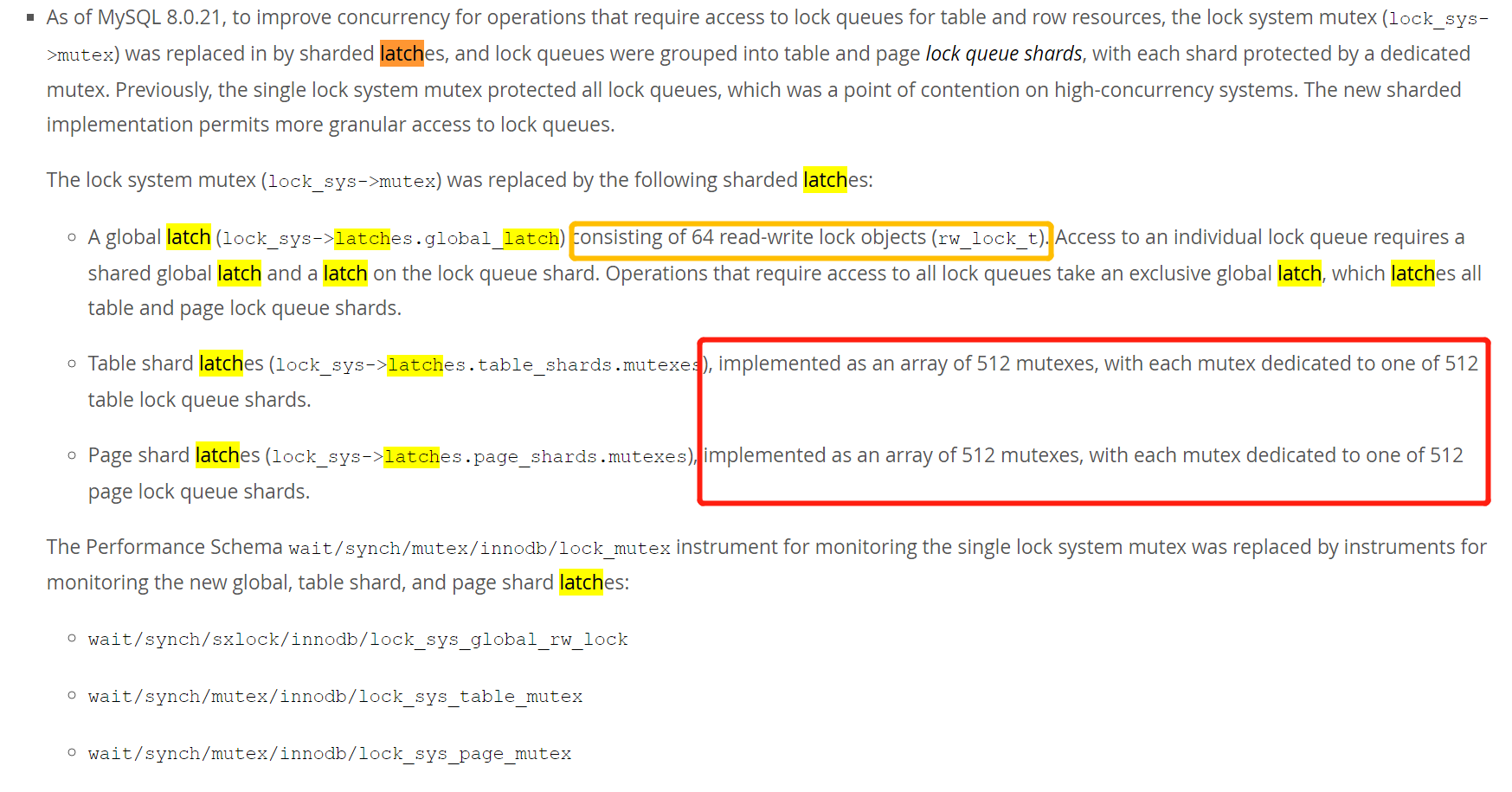
8.0.21版本开始互斥锁(lock_sys->互斥锁)被以下分片锁取代:
-
一个全局锁存器(lock_sys->latch .global_latch),由64个读写锁对象(rw_lock_t)组成。访问单个锁队列需要共享全局锁闩和锁队列的锁闩。需要访问所有锁队列的操作使用一个独占的全局锁存器,该锁存器锁存所有表和页锁队列碎片。
-
Table shard latch (lock_sys->latch .table_shards.mutexes),实现为一个512互斥锁的数组,每个互斥锁专用于512个表锁队列。512*512=262144表数量
-
Page shard latch (lock_sys->latch .page_shards.mutexes),实现为一个由512个互斥锁组成的数组,每个互斥锁专用于512个Page lock queue。512*512=262144页,比如一个页100行数据 26214400行,每次也就操作2600w行。
互斥锁查看
- 通过SHOW ENGINE INNODB MUTEX
通过命令行显示INNODB MUTEX和rw-lock的统计信息。是innodb_buffer_pool_instances整体聚合的值,也不会列出未被等待过的互斥锁或rw-locks信息。起码这些互斥锁和rw锁已经导致了至少一次os层的等待,才会记录下来。
mysql > SHOW ENGINE INNODB MUTEX;
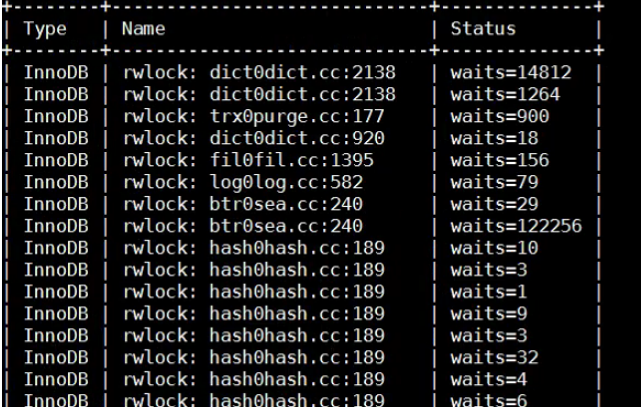
| 字段 | 字段意义 |
|---|---|
| Type | Always InnoDB |
| Name | 互斥对象,对于rwlock实现rwlock的源文件,以及创建rwlock的文件中的行号。 |
| Status | 旋转、等待和调用的数量: 1.自旋数表示自旋个数。 2.await表示互斥对象等待的数量。 3.Calls表示请求互斥锁的次数。 |
在performance_schema也输出mutex相关信息:
通过指标 可检测包含互斥的线程之间的瓶颈:
- Mutex_instances,查看其他线程当前拥有一个互斥对象
当某些代码创建了一个互斥量时,就会向mutex_instances表添加一行,销毁时,对应的行将从删除。
mutex_instances表不允许使用TRUNCATE TABLE。
当线程解锁一个互斥对象时,表示该互斥对象现在没有所有者(THREAD_ID列为NULL)。
mysql > SHOW CREATE TABLE performance_schema.mutex_instances;
CREATE TABLE `mutex_instances` (
`NAME` varchar(128) NOT NULL,
`OBJECT_INSTANCE_BEGIN` bigint(20) unsigned NOT NULL,
`LOCKED_BY_THREAD_ID` bigint(20) unsigned DEFAULT NULL
) ENGINE=PERFORMANCE_SCHEMA DEFAULT CHARSET=utf8
| 字段 | 字段意义 |
|---|---|
| NAME | 互斥锁关联名 |
| OBJECT_INSTANCE_BEGIN | 被检测互斥锁的内存地址 |
| LOCKED_BY_THREAD_ID | 当线程当前锁定了一个互斥锁时,LOCKED_BY_THREAD_ID为锁定线程的THREAD_ID,则为NULL。 |
- Events_waits_current,查看线程正在等待什么互斥量
当一个线程试图锁定一个互斥锁时,events_waits_current表显示该线程的一行,指示它正在等待一个互斥锁(在EVENT_NAME列中),并指示正在等待哪个互斥锁(在OBJECT_INSTANCE_BEGIN列中)。等待已经完成(在TIMER_END和TIMER_WAIT列中)
在setup_instruments里wait/synch/mutex/ 统计mutex相关信息。InnoDB互斥锁等待 有85种。ommit,buf_pool_LRU,dict_table_mutex 等:
mysql > UPDATE performance_schema.setup_instruments SET ENABLED = 'YES' WHERE NAME LIKE '%wait/synch/mutex/innodb%';mysql > SELECT *FROM performance_schema.setup_instrumentsWHERE NAME LIKE '%wait/synch/mutex/innodb%';
+---------------------------------------------------------+---------+-------+------------+------------+---------------+
| NAME | ENABLED | TIMED | PROPERTIES | VOLATILITY | DOCUMENTATION |
+---------------------------------------------------------+---------+-------+------------+------------+---------------+
| wait/synch/mutex/innodb/commit_cond_mutex | YES | NO | | 0 | NULL |
| wait/synch/mutex/innodb/innobase_share_mutex | YES | NO | | 0 | NULL |
| wait/synch/mutex/innodb/buf_pool_chunks_mutex | YES | NO | | 0 | NULL |
| wait/synch/mutex/innodb/buf_pool_flush_state_mutex | YES | NO | | 0 | NULL |
| wait/synch/mutex/innodb/buf_pool_zip_mutex | YES | NO | | 0 | NULL |
| wait/synch/mutex/innodb/clone_snapshot_mutex | YES | NO | | 0 | NULL |
| wait/synch/mutex/innodb/ddl_autoinc_mutex | YES | NO | | 0 | NULL |
| wait/synch/mutex/innodb/dict_sys_mutex | YES | NO | | 0 | NULL |
。。。
| wait/synch/mutex/innodb/sync_array_mutex | YES | NO | | 0 | NULL |
| wait/synch/mutex/innodb/row_drop_list_mutex | YES | NO | | 0 | NULL |
+---------------------------------------------------------+---------+-------+------------+------------+---------------+
85 rows in set (0.01 sec)控制参数
多核系统中,多个线程调用系统层面的同一个共享对象,目前基本实现方式是轮询机制。过多频繁的调动,可能会导致“cache ping pong”现象。当处理跟不上的时候,就会堵塞,穷住等情况。InnoDB通过强制轮询之间的随机延迟(spin-wait loop机制)来减少这个问题,从而去同步轮询活动。
mysql > show variables like '%spin%';
+------------------------------------+-------+
| Variable_name | Value |
+------------------------------------+-------+
| innodb_log_spin_cpu_abs_lwm | 80 |
| innodb_log_spin_cpu_pct_hwm | 50 |
| innodb_log_wait_for_flush_spin_hwm | 400 |
| innodb_spin_wait_delay | 6 |
| innodb_spin_wait_pause_multiplier | 50 |
| innodb_sync_spin_loops | 30 |
+------------------------------------+-------+| 参数 | 说明 | 类型 |
|---|---|---|
| innodb_sync_spin_loops | 线程在挂起一个InnoDB互斥锁之前等待释放的次数。 | buffer策略 |
| innodb_spin_wait_delay | 旋转锁轮询之间的最大延迟时间间隔。这种机制的底层实现取决于硬件和操作系统的组合。 | buffer策略 |
| innodb_spin_wait_pause_multiplier | 定义一个倍增器值,用于确定线程等待获取互斥锁或rw-lock时发生的自旋等待循环中的PAUSE指令数。 | buffer策略 |
| innodb_log_spin_cpu_pct_hwm | 配置选项尊重处理器相关性。例如,如果一个服务器有48个内核,但是mysqld进程只固定在4个CPU内核上,那么其他44个CPU内核将被忽略。 | Redo Log刷新策略 |
| innodb_log_spin_cpu_pct_hwm | 定义用户线程在等待刷新时不再旋转的最大CPU使用量。该值表示为所有CPU核的总处理能力之和的百分比。缺省值为50%。例如,2个CPU核的使用率为100%,则4个CPU核的服务器的CPU处理能力总和的50%。 | Redo Log刷新策略 |
| innodb_log_spin_cpu_abs_lwm: | 定义用户线程在等待刷新时不再旋转的最小CPU使用量。取值为CPU核心占用率之和。例如:默认值80为单个CPU核的80%。在具有多核处理器的系统中,值150表示一个CPU核的使用率为100%,加上第二个CPU核的使用率为50%。 | Redo Log刷新策略 |
| innodb_log_wait_for_flush_spin_hwm | 定义用户线程在等待刷新重做时不再旋转的最大平均日志刷新时间。缺省值是400微秒。 | Redo Log刷新策略 |
2种类型:
- buffer策略:innodb buffer pool里loop之间和wait 之间的协调,并且是所有实例的全局变量。
- Redo Log刷新策略:通过等待刷新的redo的用户线程优化旋转延迟的使用。自旋延迟有助于,在高并发性期间下减少io处理的延迟。
总结:
MySQL数据库中的mutex是一个需要考虑硬件协调性实现,其中要考虑多种资源的平衡因素的关键性机制。
在实际环境中哪里会知道 不同的操作系统的互斥层和innodb层互斥,该设置多少合理。所以一般维持默认值。
- 常见的情况是mutex 实现会导致cpu 利用过高, 并且上下文切换也会更高。
- 对于非常大的缓冲池,每一块在缓冲池有一个互斥锁。因此,块大小越小 开销越高。