Java 文件操作
- 引言
- 1. 对文件的初步认识
- 2. 绝对路径和相对路径
- 一、File 类
- File 类对应的方法
- 创建一个文件
- 测试一
- 测试二
- 测试三
- 测试四
- 测试五( 面试题 )
- 测试六
- 测试七
- 二、InputStream
- 测试一
- try with resources 语法
- 测试二
- 测试三
- 三、OutputStream
- 测试一
- 测试二
- 总结
- 四、案例
- 案例1 检索文件名为 key 的普通文件
- 案例2 普通文件的全文检索
- 案例3 复制普通文件
引言
1. 对文件的初步认识
狭义的文件,一般可以分成两个大类:
① 普通文件( 不可再分 )
② 目录文件( 文件夹 )

2. 绝对路径和相对路径

一、File 类
File 类对应的方法

创建一个文件
这是创建一个 " .txt " 文件最基本的操作,我们需要先进行判定是否重名。
import java.io.File;
import java.io.IOException;public class Test {public static void main(String[] args) throws IOException {String filepath = "D:/Data/123.txt";File file = new File(filepath);if (!file.exists()) {file.createNewFile();} else {System.out.println("文件名已存在,无法创建!");}}
}
测试一
程序清单1:
import java.io.File;
import java.io.IOException;public class Test1 {public static void main(String[] args) throws IOException {//输入代码的时候使用 / ,这样避免了转义字符的语法麻烦File file = new File("d:/test.txt");System.out.println(file.getParent());System.out.println(file.getName());System.out.println(file.getPath());System.out.println(file.getAbsoluteFile());System.out.println(file.getCanonicalFile());System.out.println("-------------------------");File file2 = new File("./test.txt");System.out.println(file2.getParent());System.out.println(file2.getName());System.out.println(file2.getPath());System.out.println(file2.getAbsoluteFile());System.out.println(file2.getCanonicalFile());}
}
输出结果:
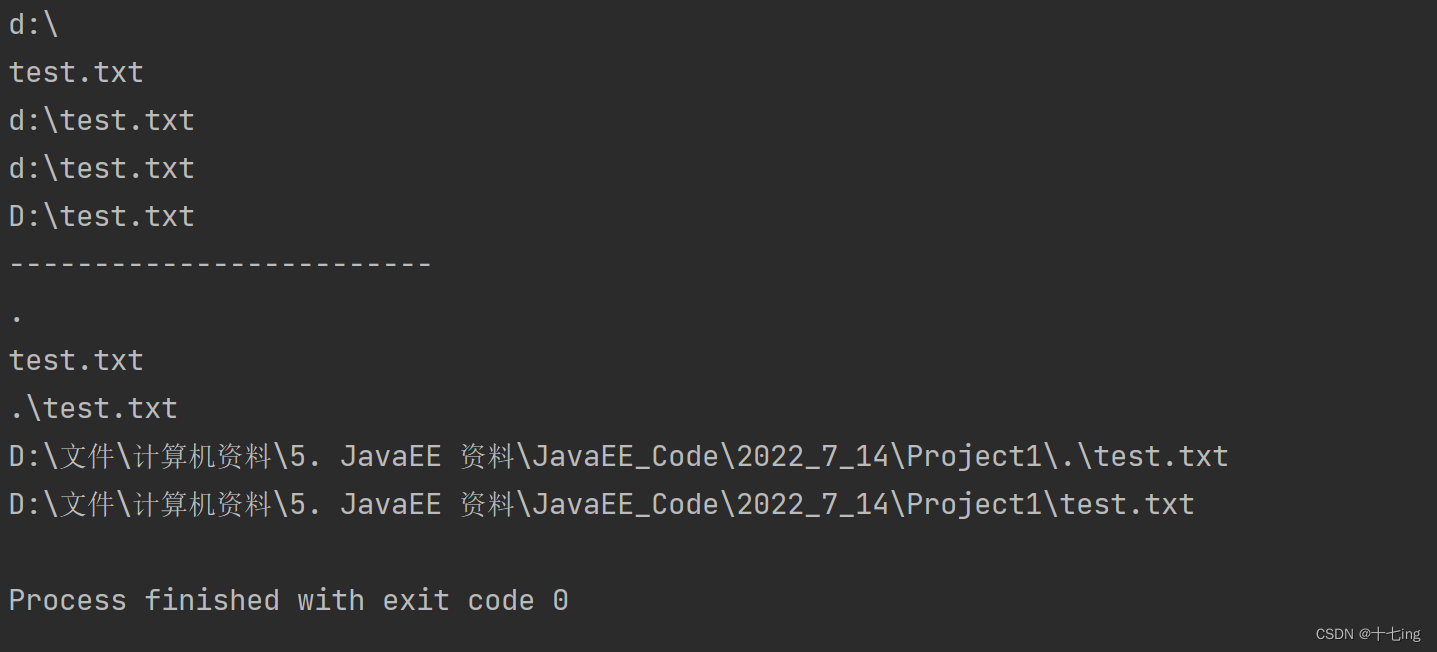
在 IDEA 编译器中,当我们运行一个程序,此时的工作目录就是当前项目所在的目录,而在代码中涉及到的相对路径,其实也就是以这个当前项目所在的目录作为基准。在 IDEA 中,可以通过如下方法来找到当前的工作目录。
当然,代码除了在 IDEA 中,也可以直接通过命令行来运行。如果是通过命令行运行,当前命令行所在的目录,就是工作路径。比方说:windows 的 cmd 控制台
测试二
我们在当前的工作目录中,创建一个 .txt 的文件,三秒之后,我们再将它删除。
注意:我通过 File 类创建出来一个新的对象时,下面的代码并没有为文件加 ./ 或 …/
那么,这其实相当于省略了 ./
File file = new File("hello world.txt");
程序清单2:
import java.io.File;
import java.io.IOException;public class Test2 {public static void main(String[] args) throws IOException, InterruptedException {File file = new File("hello world.txt");System.out.println(file.createNewFile());Thread.sleep(3000);System.out.println(file.delete());}
}
在我们创建文件的时候,会抛出异常:throws IOException,这是为什么?
① 权限问题。因为创建文件之后,你可能对这个文件进行读、写、修改等操作,而为了安全,这就不支持所有用户者都能使用。这就好像有的文件需要管理员才能运行,一个道理。
② 磁盘空间不够。
测试三
我们准备对测试二进行改造,当下面的整个代码执行完之后,起初创建的文件才会被删除。也就是,总共十秒后,文件才会被删除。
程序清单3:
import java.io.File;
import java.io.IOException;public class Test3 {public static void main(String[] args) throws IOException, InterruptedException {File file = new File("hello world.txt");System.out.println(file.createNewFile());System.out.println("文件创建成功");Thread.sleep(3000);file.deleteOnExit();System.out.println("把文件标记成【退出则删除的状态】");Thread.sleep(7000);}
}
这个思想对于实际使用文件的场景下,具有非常大的意义。
举个例子:你通过电脑编辑文档的时候,突然断电了,如果应用了这个思想,它就会产生效果。现在的 Office,当你每次编辑文件的时候,它都会产生一个临时文件,以防意外发生。当你真的停电了关机了,内存中的数据一定会丢失,但下一次开机的时候, Office 就会问你是否恢复上次的文档,你可以通过临时文件将数据备份回来。
测试四
我们来演示一下当前工作目录下的所有文件名( 文件夹 + 文件 )
程序清单4:
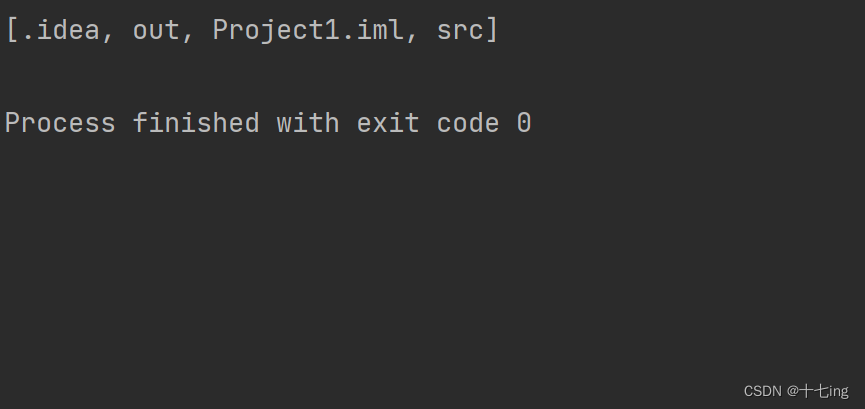
import java.io.File;
import java.util.Arrays;public class Test4 {public static void main(String[] args) {File file = new File(".");String[] files = file.list();System.out.println(Arrays.toString(files));}
}
输出结果:
测试五( 面试题 )
面试题:有什么办法能够将一个目录下的所有文件夹对应的所有文件全部打印出来呢?
通过递归来实现。
在 getAllFiles 方法中,我们接收某个工作目录,之后通过递归的方法来搜寻。这个思想和树这个数据结构的思想是相同的,当我们找到的文件是叶子节点,说明这个文件已不再可分,就直接返回,这也就是递归的边界条件;而当我们找到的是目录( 文件夹 ),那么说明还没到树的最底下,我就得继续递归。
程序清单5:
import java.io.File;
import java.util.ArrayList;
import java.util.List;//通过递归的方式,来罗列目录中的所有文件
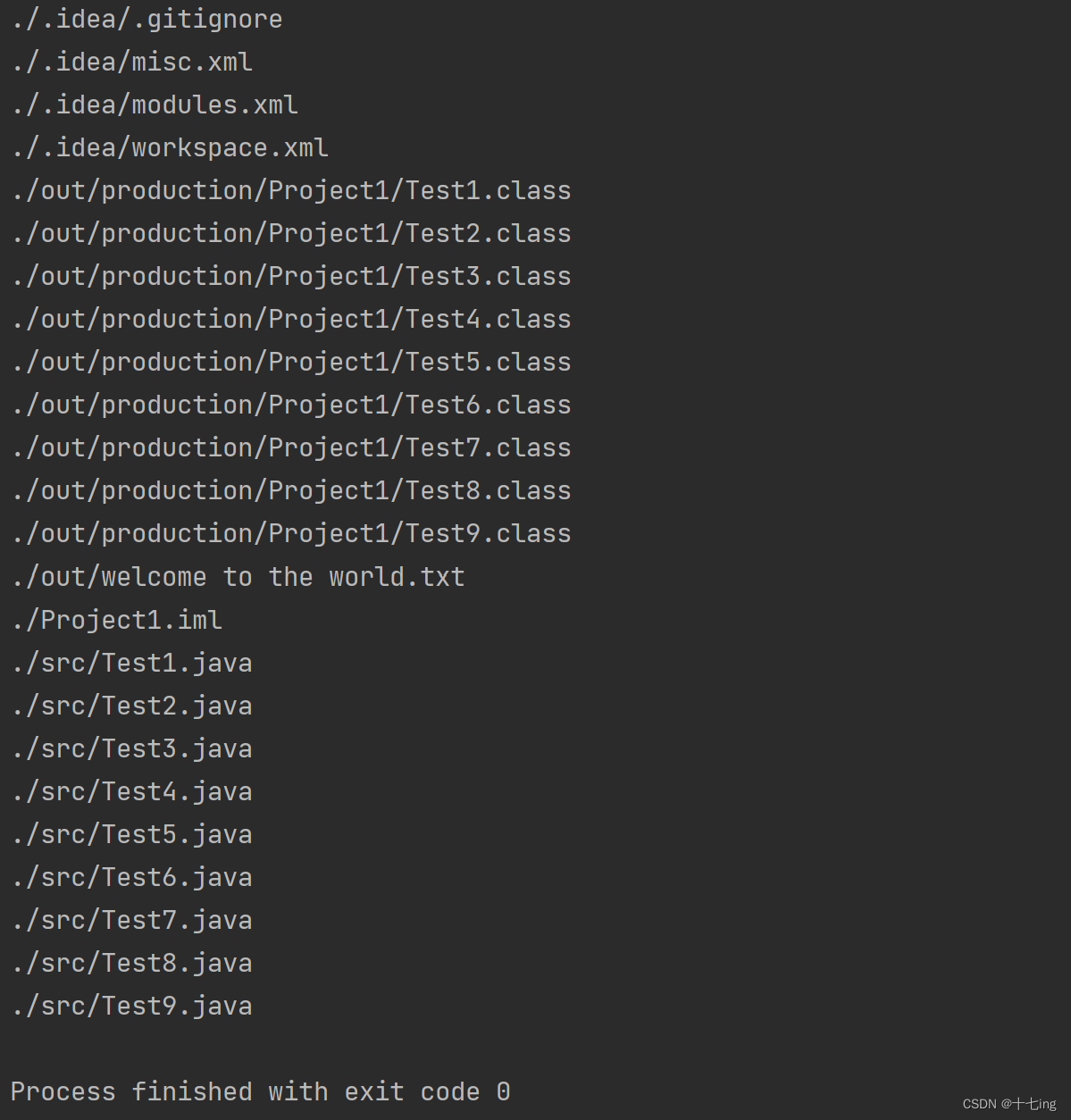
public class Test5 {public static List<String> list = new ArrayList<>();public static void getAllFiles (String basePath) {File file = new File(basePath);//如果是文件,说明已经无法再拆分了if (file.isFile()) {list.add(basePath);return;} else if (file.isDirectory()){//如果是目录,或者说是文件夹,说明还能继续往下打开String[] files = file.list();for (String s : files) {getAllFiles(basePath + "/" + s);}} else {//当前文件既不是普通文件,也不是目录,这个情况暂不考虑//scoket 文件、管道文件、设备快文件...}}public static void main(String[] args) {getAllFiles(".");for (String s : list) {System.out.println(s);}}
}
输出结果:
测试六
演示创建目录的两种方法,一个 mkdir 方法只能创建一个主目录。
而 mkdirs 方法,不但能创建主目录,还能创建主目录下的子目录。
程序清单6:
import java.io.File;
import java.io.IOException;public class Test6 {public static void main(String[] args) throws IOException {File file = new File("demo");file.mkdir();File file2 = new File("demo2/aaa/bbb");file2.mkdirs();}
}
测试七
测试 rename 重命名方法,它有两个功能。
① 重命名
② 可以将一个文件从一个目录移动到另外一个目录中
程序清单7 :
import java.io.File;
import java.io.IOException;public class Test7 {public static void main(String[] args) throws IOException {File file1 = new File("./123.txt");File file2 = new File("./456.txt");file1.renameTo(file2);File file3 = new File("./out/456.txt");file2.renameTo(file3);}
}
上面的代码执行了两个步骤
步骤一:将文件 123 重命名为 456
步骤二:将文件 456 从当前目录移动至 out 目录下
二、InputStream

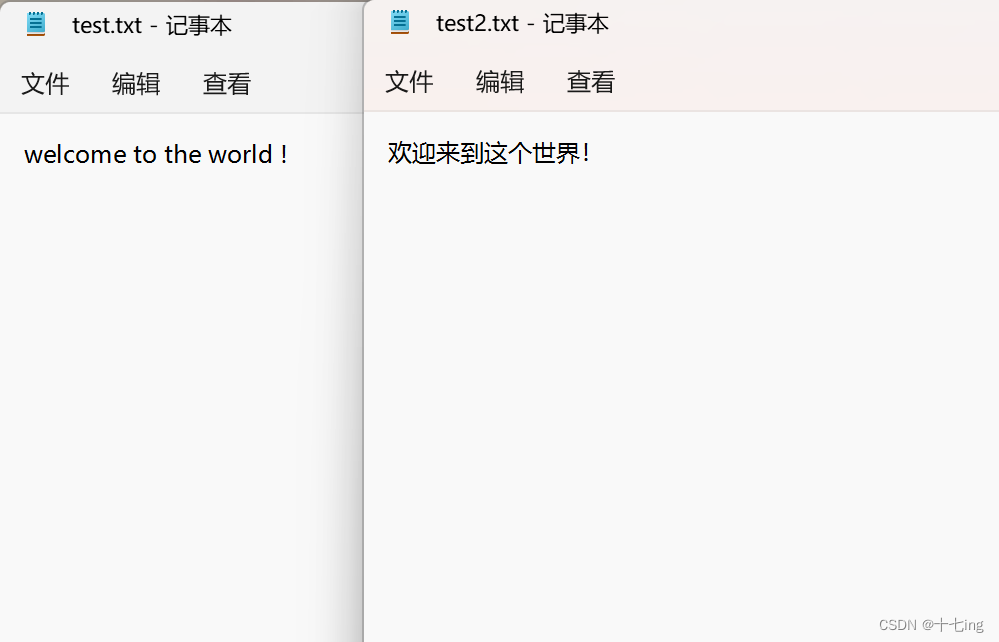
我们在当前的工作目录下,创建两个 .txt 文件,里面的内容如下:
现在我们通过输入流来测试一下读取文件中的内容。
测试一
程序清单8:
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
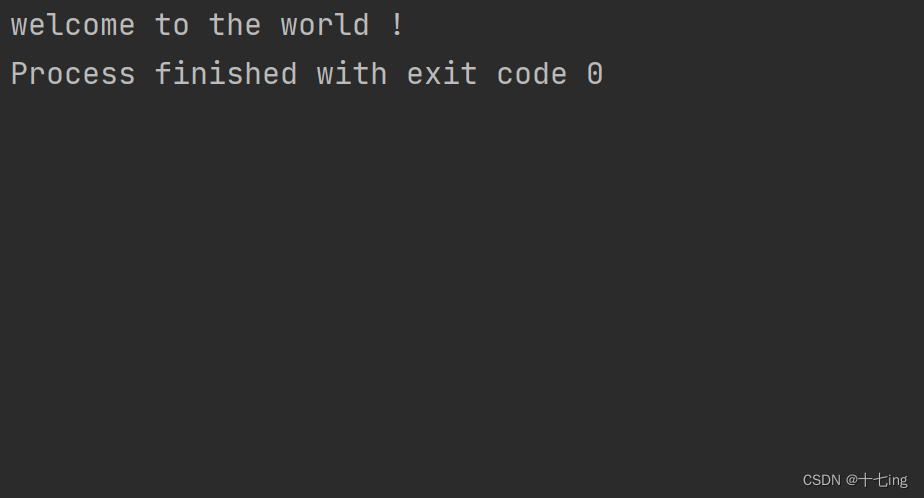
import java.io.InputStream;public class Test8 {public static void main(String[] args) throws IOException {//创建实例的过程:先打开文件,再进行读写InputStream inputStream = new FileInputStream("./test.txt");while (true) {//read 无参版本一次只能读取一个字节,返回值即当前读到的字节//如果读到文件的末尾,就会返回 -1int a = inputStream.read();if (a == -1) {break;}System.out.printf("%c", a);}//这里记得关闭流inputStream.close();}
}
输出结果:
注意几个点:
① InputStream 是抽象类,它本身不能实例化对象,我们只能使用它的实现类来完成 new
② 程序清单8 中的 read 方法是无参的方法,一次只能读一个字节,另外,当读到文件末尾的时候,就会返回 -1,即 EOF ( end of file ),文件结束符。
③ 如果我们读取的是英文,直接转换成字符的形式输出,否则就会输出数字,即 ASCII 码。
④ 在程序的最后,需要使用 close 方法来关闭流,以防资源泄露。一个进程能打开的文件数量是有上限的,其能打开的文件描述符表也是有上限的,如果不使用 close 及时关闭,那么当文件描述表中的资源占满的时候,就会使程序崩溃。
举个例子:这就和我们平时使用自来水一样,当你用完了水龙头,需要关闭,否则,你就会浪费水资源!如果一个小区都这样浪费水的话,那么很快就会发生水资源不足,因为水资源是有上限的。
优化代码:
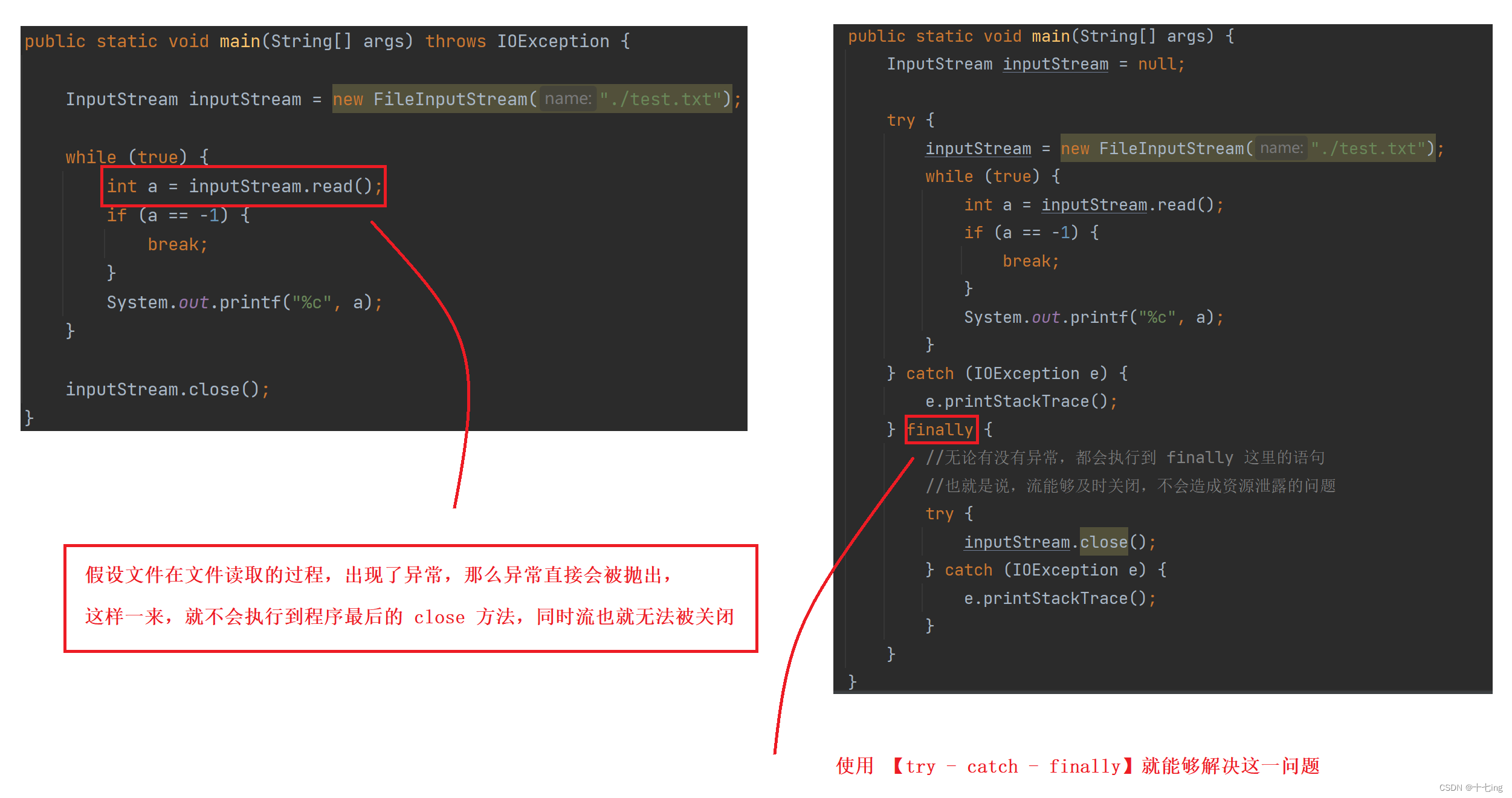
try with resources 语法
在我们解决了所有的问题后,将上图的左边代码转换成了右边代码,但我们可以发现,右边的代码又较为繁杂,所以我们可以使用 【 try with resources 】这个语法,即在 try( ) 中添加类,那么哪些类可以放入这个 try 的括号中呢?
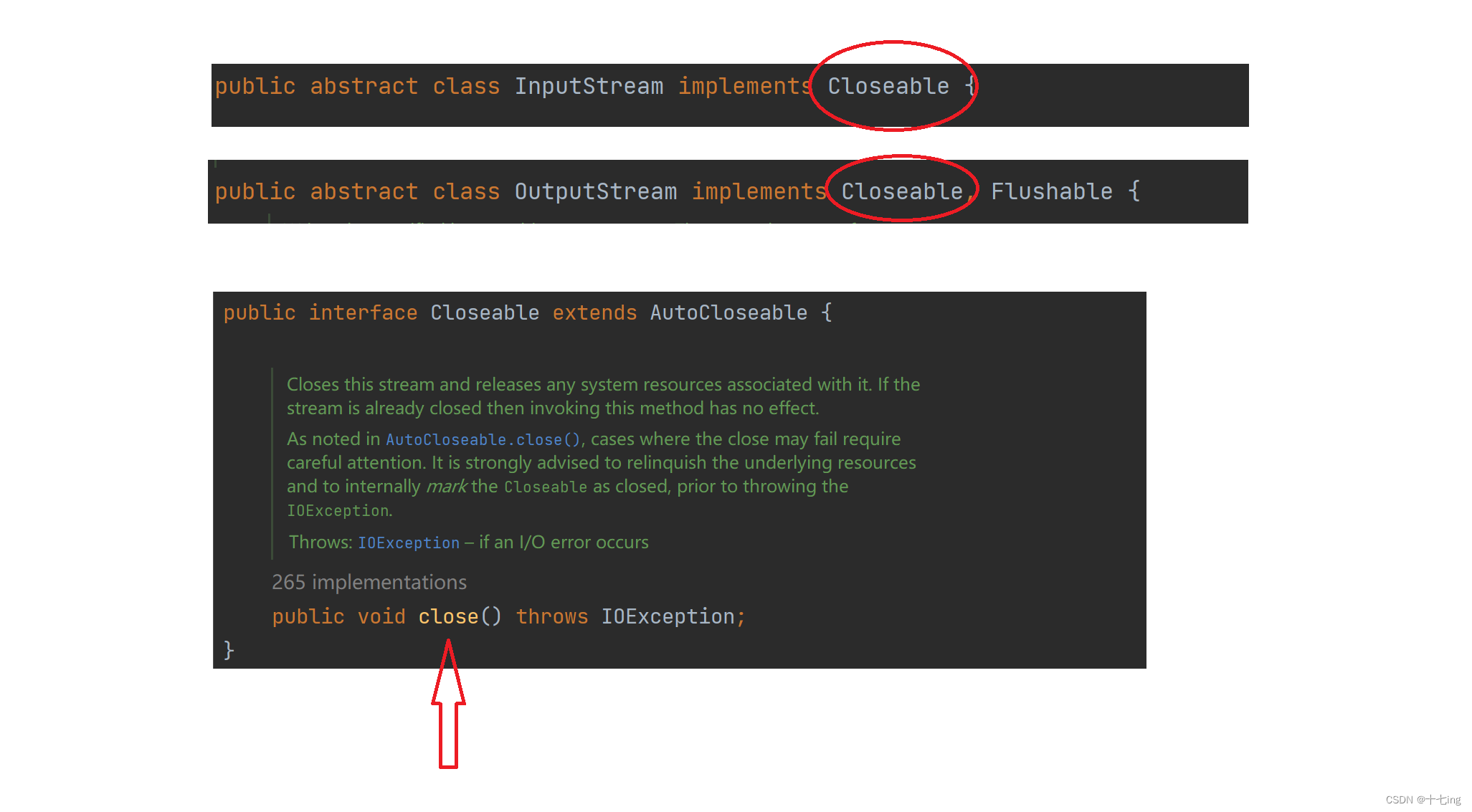
我们查看输入流和输出流都实现了 Closeable 接口,在这个接口的源代码中,我们看到它只有一个方法 close,也就是说:实现了这个 Closeable 接口的类,当我们在 try( ) 中添入的类,这个类就会自动使用 close 方法来关闭资源。
try( ) 这个方法更加简单,而且能够自动使用 close 方法关闭流。也需要我们重点掌握,如下程序清单9。
程序清单9:
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.InputStream;public class Test9 {public static void main(String[] args) throws IOException {try ( InputStream inputStream = new FileInputStream("./test.txt") ) {while (true) {int a = inputStream.read();if (a == -1) {break;}System.out.printf("%c", a);}} catch (IOException e) {e.printStackTrace();}}
}
测试二
程序清单10:
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;public class Test10 {public static void main(String[] args) {try (InputStream inputStream = new FileInputStream("./test.txt") ){byte[] buffer = new byte[1024];while (true) {int len = inputStream.read(buffer);if (len == -1) {break;}for (int i = 0; i < len; i++) {System.out.printf("%c", buffer[i]);}}} catch (IOException e) {e.printStackTrace();}}
}
输出结果:
程序清单10 中的 read 方法会尝试把参数的这个 buffer 给填满,buffer 数组共 1024 个字节。
假设该文件的长度是2049,下面是读取文件的总过程:
第一次循环,读取出1024个字节,放到 buffer 数组中,read 方法返回1024,
第二次循环,读取出1024个字节,放到 buffer 数组中,read 方法返回1024,
第三次循环,读取出1个字节,放到 buffer 数组中,read 方法返回1,
第四次循环,此时已经读到文件末尾了 ( EOF ),read 方法返回-1.
注意几个点:
① 程序清单10 中的 read 方法,一次可以读取多个字节。
我们需要明确一个点,读取数据的速度:CPU 上的寄存器 >> 内存 >> 磁盘 ( A >> B,表示 A 的速度远快于 B )
也就是说,相比于一次只读一个字节,这样一次读取多个字节的效果更好,因为一次多读点数据,那么读的次数就会减少,那么磁盘的 IO 次数就会减少,效率也就更高!
举个例子:小明的宿舍住三楼,他准备去一楼的水房接开水,他准备接 1 L 的水,但他打算用水杯接水,所以他来来回回地上下楼跑了好多次。下一次的时候,他心想:用水杯接水太麻烦了,于是他就拿着两个水瓶接水了,这样效率就高很多了。而这就对应着上面的读操作,一次多接点水,那么跑路就少很多。
② read 方法的返回值是一次读取的字节长度,如果读的不为空文件,那么至少一次读取1个字节,和之前一样,当读到文件末尾,read 方法就返回 -1.
测试三
我们来测试一下读取内容是中文的文件。
程序清单11:
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import java.util.Scanner;public class Test11 {public static void main(String[] args) {try (InputStream inputStream = new FileInputStream("./test3.txt") ) {try (Scanner scanner = new Scanner(inputStream, "UTF-8")) {while (scanner.hasNext()) {String s = scanner.nextLine();System.out.println(s);}}} catch (IOException e) {e.printStackTrace();}}
}
输出结果:
注意几个点:
① 在程序去清单11 中,我们这里使用 Scanner 对象,并不是我们之前的 System.in 的标准输入。在这里,我们传入的参数分别是:【 流,字符集】。同样地,这里的 Scanner 对象涉及到流了,那么就得使用 close 方法,当然,使用【 try with resources 】这个语法也行得通!
② 使用 Scanner 这个语法也能读取到中英文混合的文件,我们可以使用 scanner.nextLine 方法来实现这个读取操作。
三、OutputStream

对 flush 方法进行说明:我们知道,计算机读写内存数据的速度是比读写磁盘数据的速度是要快很多的。所以,大多数的 OutputStream 为了减少访问磁盘的次数,在写数据的时候都会将数据暂时先写入内存的缓冲区中,直到该区域满了或者其他指定条件时才真正将数据写入磁盘中。但这可能会造成一个结果,就是我们写的数据,很可能会遗留一部分在缓冲区中。需要在最后或者合适的位置,调用 flush(刷新)操作,将数据刷到设备中,这就是 " 临门一脚 "。
举个例子:当一家人嗑瓜子的时候,不需要嗑一个瓜子,就把瓜子皮往垃圾桶里放,垃圾桶就一个,如果所有人将瓜子皮一个一个往里放,效率太低。我们可以先把瓜子皮放在手中,等吃完了所以瓜子,再一下子放入垃圾桶中。那么最后将手中所以的瓜子皮全放入到垃圾桶中,这个操作就相当于 flush 操作,即刷新缓冲区。
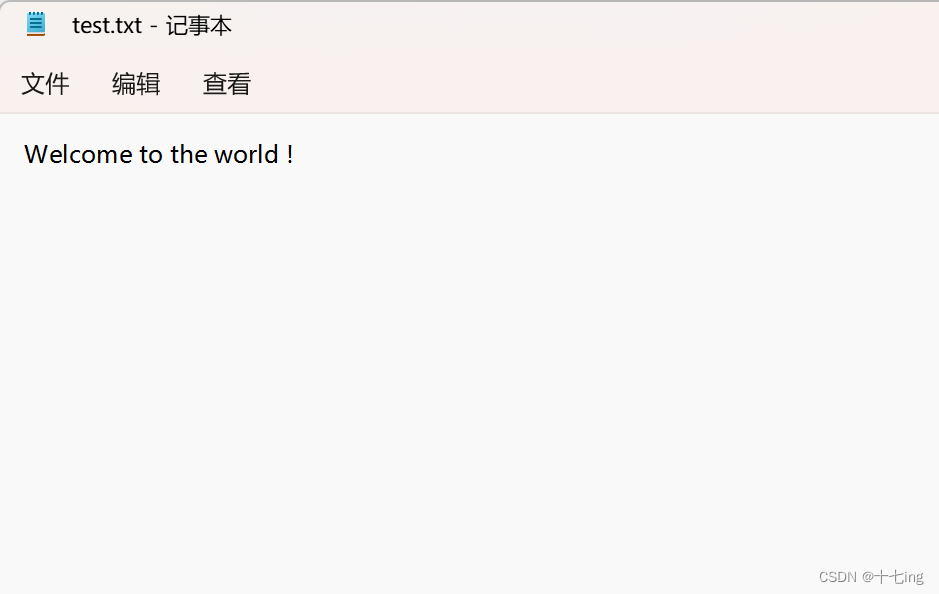
我们在当前的工作目录下,创建一个 .txt 文件,里面的内容如下:
现在我们通过输出流来测试一下读取文件中的内容。
测试一
程序清单12:
import java.io.FileOutputStream;
import java.io.IOException;
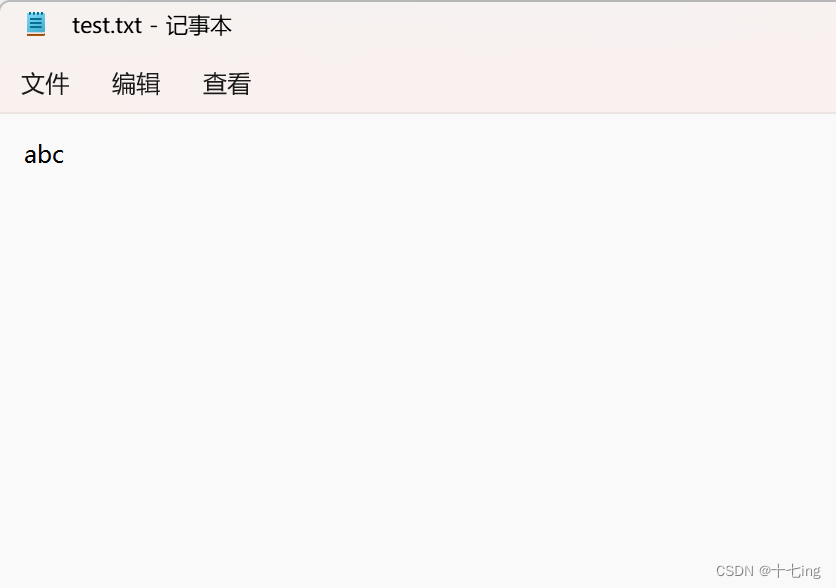
import java.io.OutputStream;public class Test12 {public static void main(String[] args) {//一旦按照 OutputStream 的方式打开文件,就会把文件中的原来内容给清空掉try (OutputStream outputStream = new FileOutputStream("./test.txt") ) {//写入一个字符outputStream.write('a');outputStream.write('b');outputStream.write('c');} catch (IOException e) {e.printStackTrace();}}
}
文件写入结果:
程序清单13:
import java.io.FileOutputStream;
import java.io.IOException;
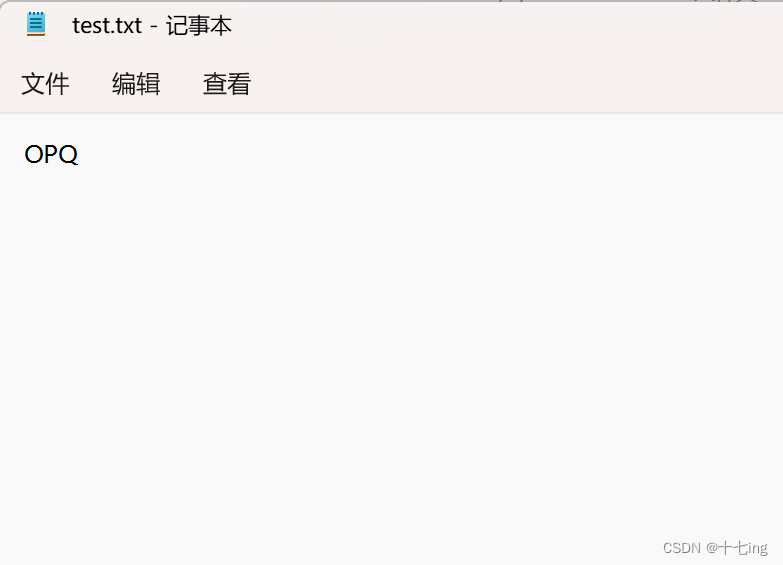
import java.io.OutputStream;public class Test13 {public static void main(String[] args) {try (OutputStream outputStream = new FileOutputStream("./test.txt") ) {//按照字节来写入byte[] bytes = new byte[] {(byte)'O',(byte)'P',(byte)'Q'};outputStream.write(bytes);} catch (IOException e) {e.printStackTrace();}}
}
文件写入结果:
程序清单14:
import java.io.FileOutputStream;
import java.io.IOException;
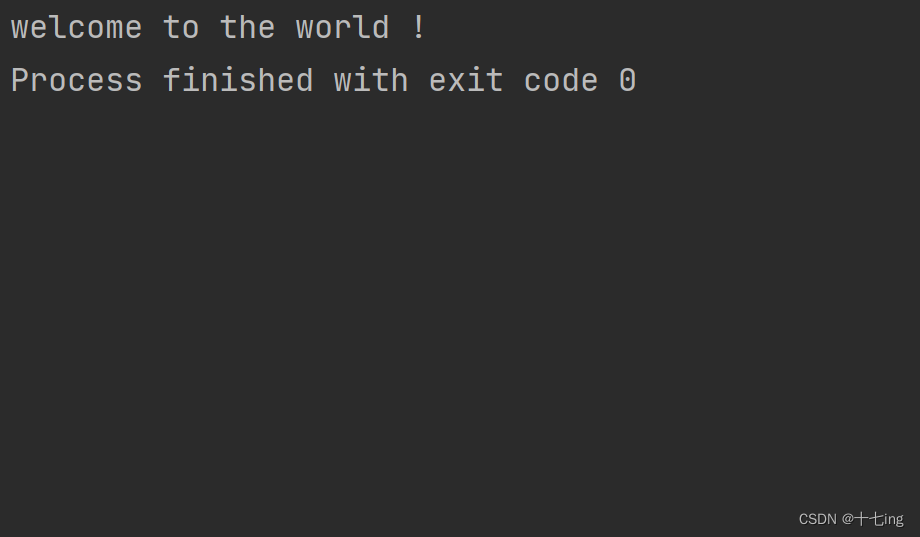
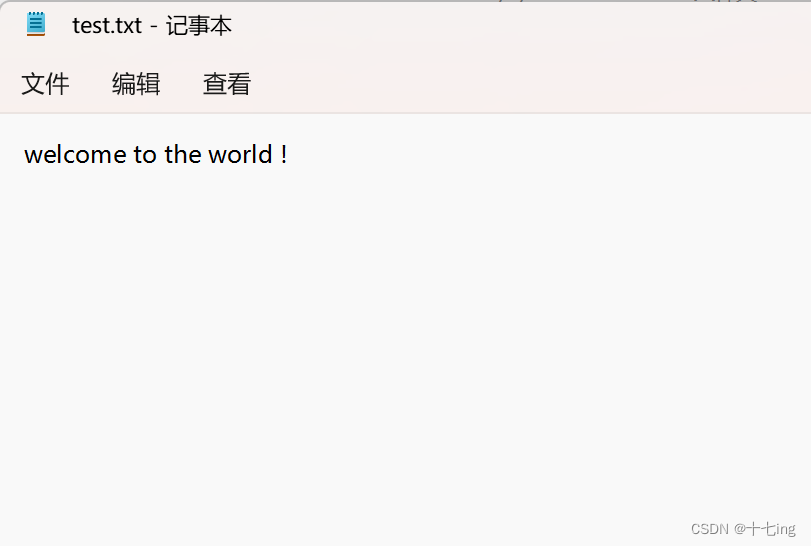
import java.io.OutputStream;public class Test14 {public static void main(String[] args) {try (OutputStream outputStream = new FileOutputStream("./test.txt") ) {//按照字符串来写入String s = "welcome to the world !";outputStream.write(s.getBytes());} catch (IOException e) {e.printStackTrace();}}
}
文件写入结果:
测试二
程序清单15:
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStream;
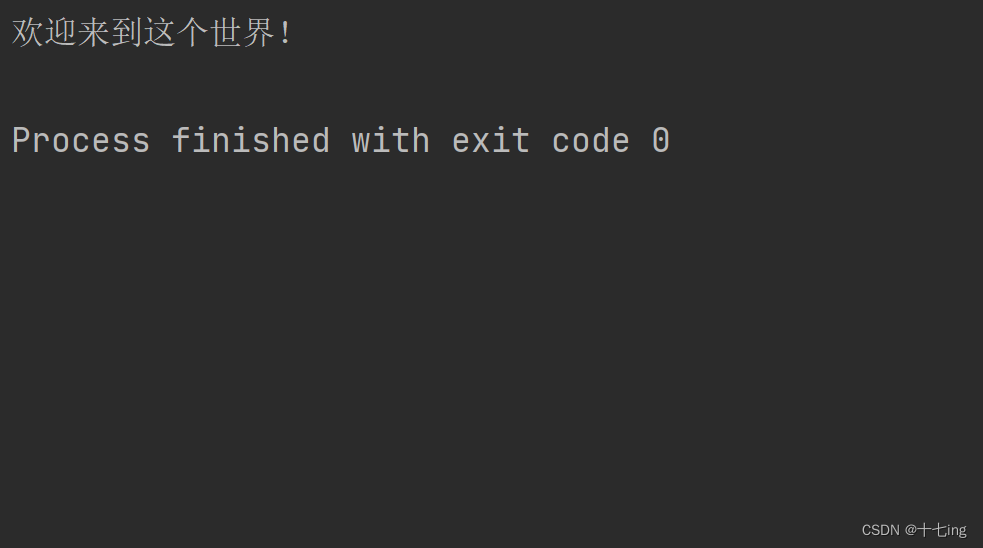
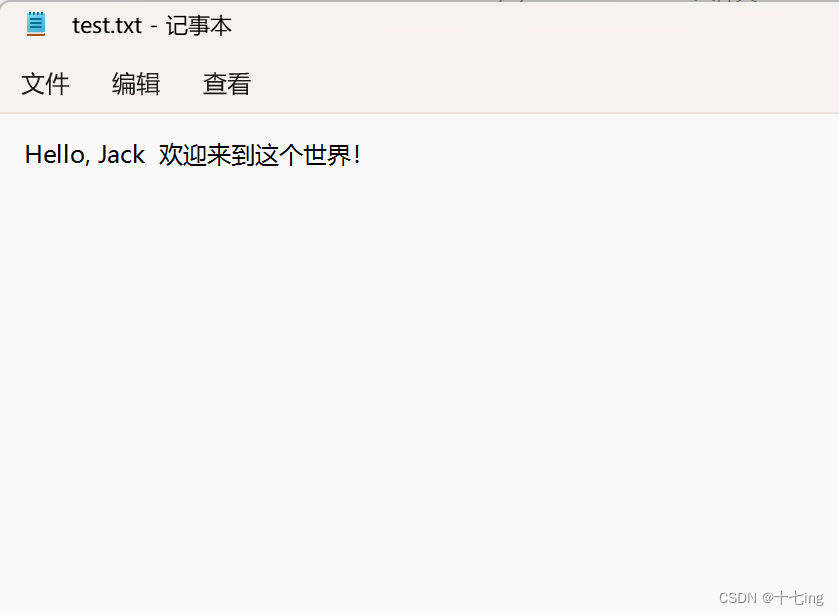
import java.io.PrintWriter;public class Test15 {public static void main(String[] args) {//使用try (OutputStream outputStream = new FileOutputStream("./test.txt") ) {try (PrintWriter printWriter = new PrintWriter(outputStream)) {printWriter.print("Hello, Jack ");printWriter.println("欢迎来到这个世界!");}} catch (IOException e) {e.printStackTrace();}}
}
文件写入结果:
总结
注意几个点:
① OutputStream 和 InputStream 这两个类在用法上差不多,它也需要通过 close 关闭流。
② 正常情况下,按照 OutputStream 的方式打开文件,就会把文件中的原来内容给清空掉,原来的文件内容将被直接替换成重新写入的内容。但我们也可以自己设置,将重新写的内容续在文件的末尾。
只需要将 new FileOutputStream 的第二个参数设置为 true 即可。
try ( OutputStream outputStream = new FileOutputStream(filePath, true) )
③ OutputStream 类支持以字符写入、以字节写入、也可以按照以中英文混合写入。
四、案例
案例1 检索文件名为 key 的普通文件
指定一个待检测的目录,并扫描这个目录,查找整个目录所有普通文件的文件名带有关键字 key,符合关键字 key 的普通文件,展示出来,最后询问用户是否删除。
假设我要删除 D 盘下文件目录下的 test5.txt,很显然,我只要让它递归去跑即可,这就和树的查找很类似了!
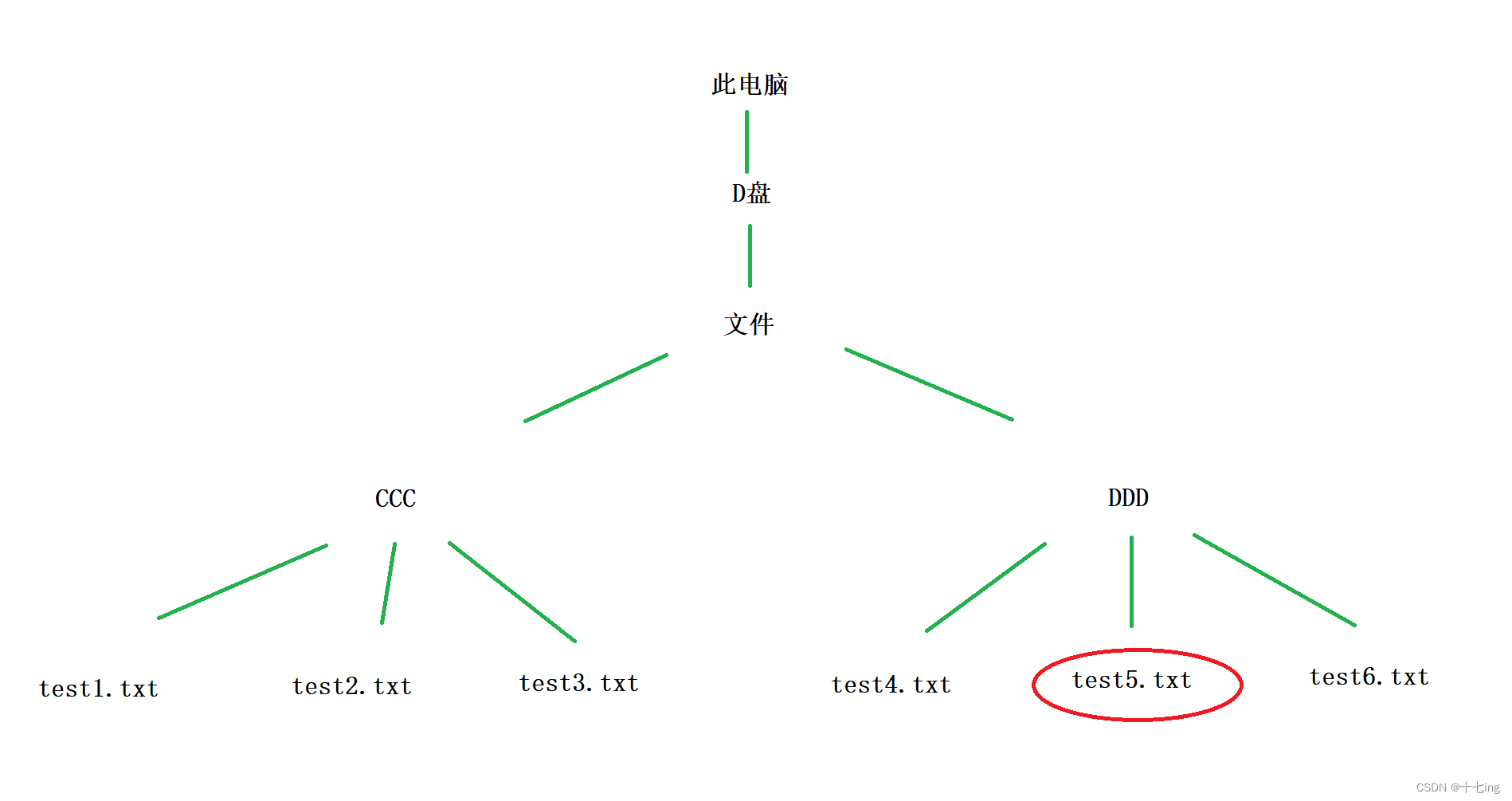
程序清单16:
import java.io.File;
import java.util.ArrayList;
import java.util.List;
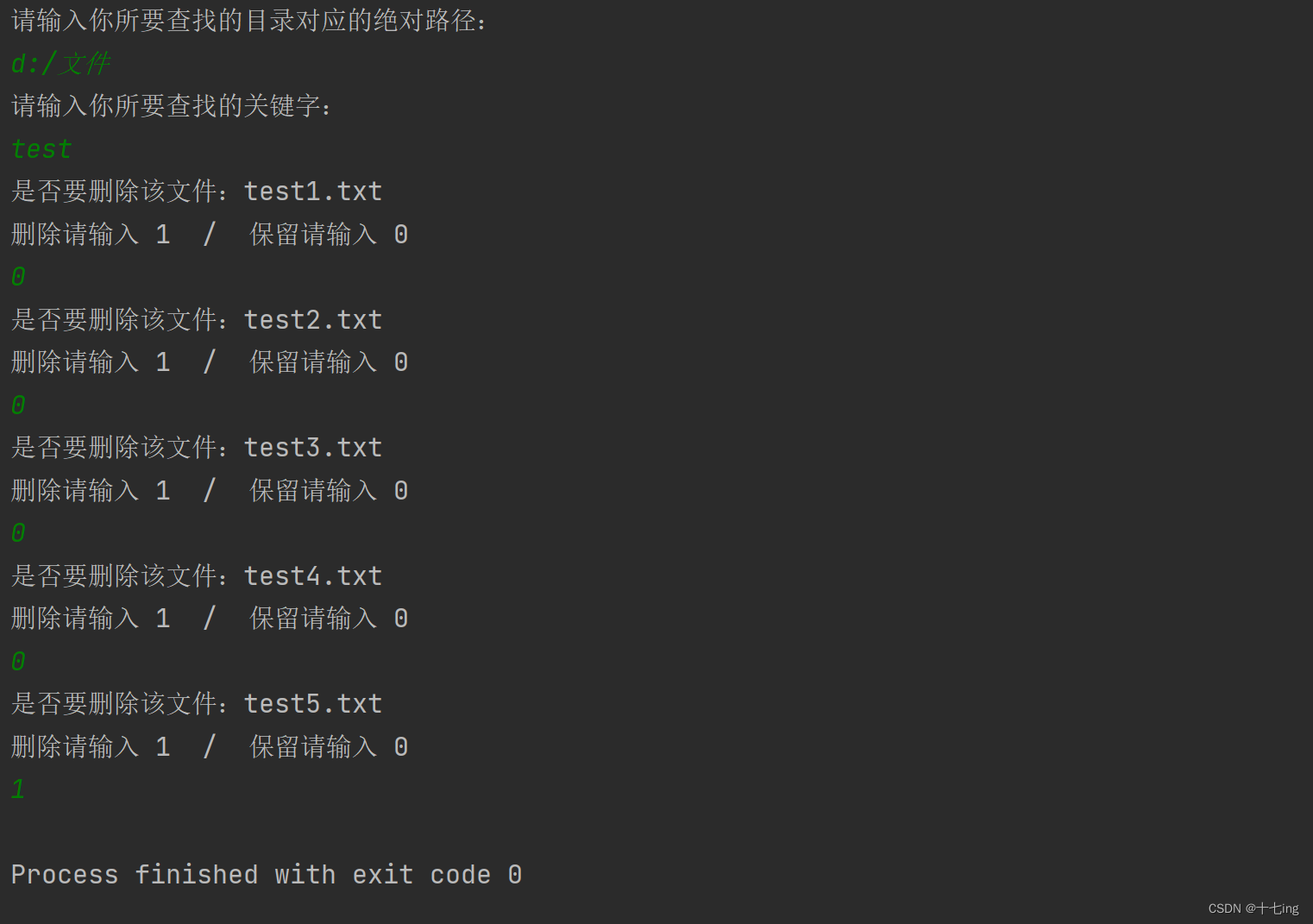
import java.util.Scanner;public class Test16 {public static void main(String[] args) {//1. 让用户输入一个待扫描的目录、待查询的关键字Scanner scanner = new Scanner(System.in);System.out.println("请输入你所要查找的目录对应的绝对路径:");String root = scanner.nextLine();File rootDir = new File(root);if(!rootDir.isDirectory()) {System.out.println("你所输入的不是目录,即将退出程序!");return;}System.out.println("请输入你所要查找的关键字:");String key = scanner.nextLine();//2. 递归整个目录// list 中表示递归遍历的结果,里面存放着所有带 key 关键字的文件路径List<File> list = new ArrayList<>();finding(rootDir,key,list);//3. 遍历 list,询问用户是否要删除该文件,再根据用户的输入来决定是否要删除for (File f : list) {System.out.println("是否要删除该文件:" + f.getName());System.out.println("删除请输入 1 / 保留请输入 0");int r = scanner.nextInt();if (r == 1) {f.delete();break;}}}/*** 用 finding 方法进行递归查找*/public static void finding(File rootDir, String key, List<File> list) {//从主目录出发,往下搜寻对应的文件夹和普通文件File[] files = rootDir.listFiles();if (files == null || files.length == 0) {//当前目录是一个空目录,就直接返回return;}for (File f : files ) {if(f.isDirectory()) {//如果当前的文件是一个目录,就继续递归查找finding(f, key, list);} else {if( f.getName().contains(key) ) {list.add(f.getAbsoluteFile());}}}}
}
输出结果:
案例2 普通文件的全文检索
扫描指定目录,并找到内容中包含指定内容关键字的所有普通文件。
假设我们在文件目录下的测试目录下查找内容包含 【world】关键字的普通文件,如果存在,就打印出普通文件的路径。
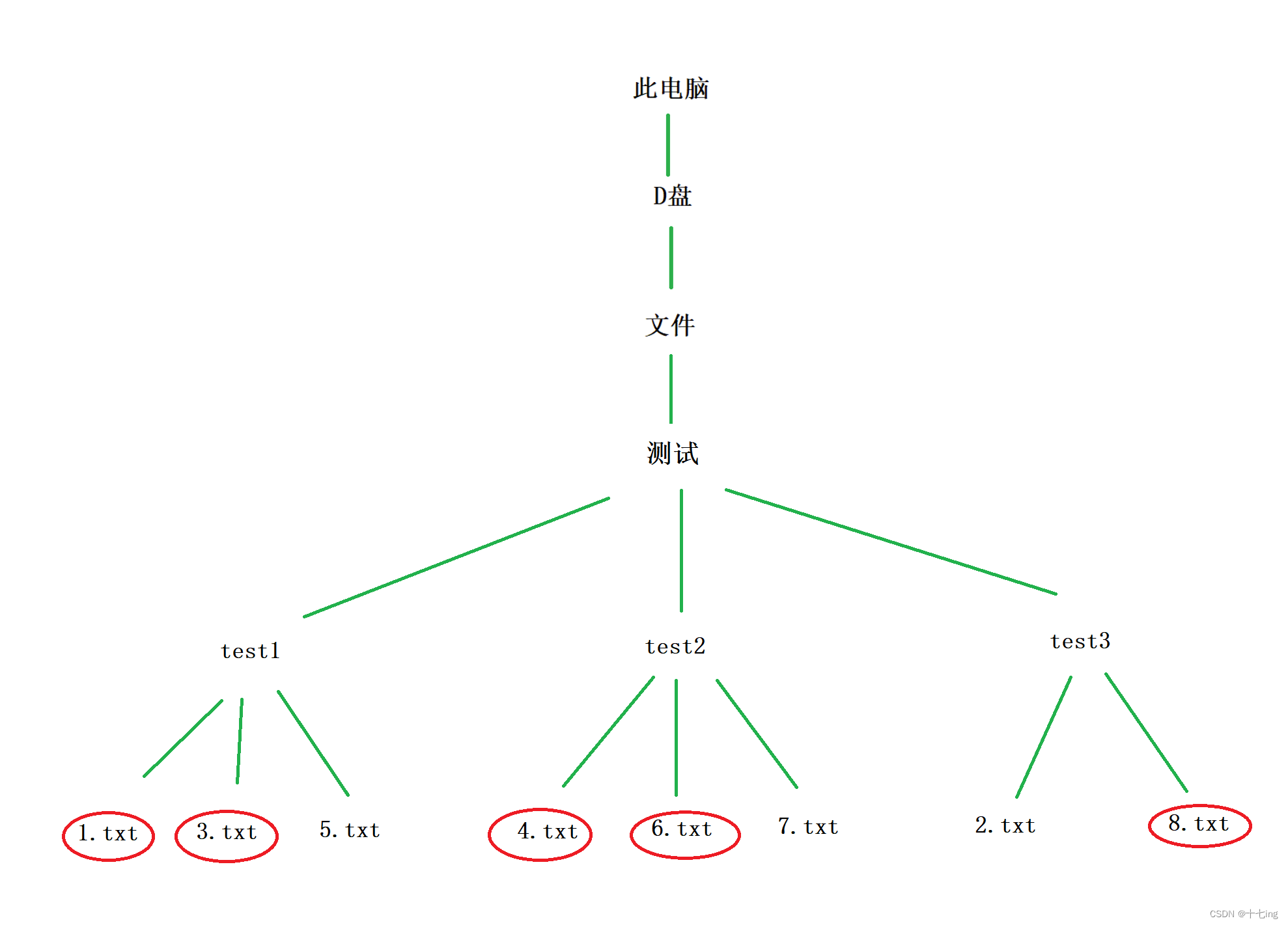
程序清单17:
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import java.util.ArrayList;
import java.util.List;
import java.util.Scanner;public class Test17 {public static void main(String[] args) {//1. 输入起始目录和内容关键字Scanner scanner = new Scanner(System.in);System.out.println("请输入起始目录:");String srcPath = scanner.nextLine();File rootDir = new File(srcPath);if (!rootDir.isDirectory()) {System.out.println("你所指定的不是目录,程序即将退出!");return;}System.out.println("请输入查询的内容关键字:");String keyword = scanner.nextLine();//2. 利用递归来查找内容List<File> list = new ArrayList<>();finding(rootDir,keyword, list);//3. 打印出所有符合要求的文件名for (File f : list) {System.out.println(f.getAbsoluteFile());}}/*** 利用递归来找到包含指定 keyword 的普通文件,并所有符合要求的放入顺序表中*/public static void finding(File rootDir, String keyword, List<File> list) {//从主目录出发,往下搜寻对应的文件夹和普通文件File[] files = rootDir.listFiles();if (files == null || files.length == 0) {return;}for (File f : files) {if (f.isDirectory()) {finding(f, keyword, list);}else{if ( isContains(f, keyword) ){list.add(f);}}}}/*** 判断是否满足普通文件中包含关键字 keyword,利用主串与子串的关系来解决*/private static boolean isContains(File f, String keyword) {StringBuilder stringBuilder = new StringBuilder();try( InputStream inputStream = new FileInputStream(f.getAbsoluteFile()) ) {Scanner scanner = new Scanner(inputStream, "utf-8");while (scanner.hasNext()) {//将普通文件中的所有内容全部拼接至 stringBuilder 中String str = scanner.nextLine();stringBuilder.append(str + "\n" );}} catch (IOException e) {e.printStackTrace();}//看看主串 stringBuilder 中是否有子串 keyword,如果有,必定不是-1return stringBuilder.indexOf(keyword) != -1;}
}
测试结果:
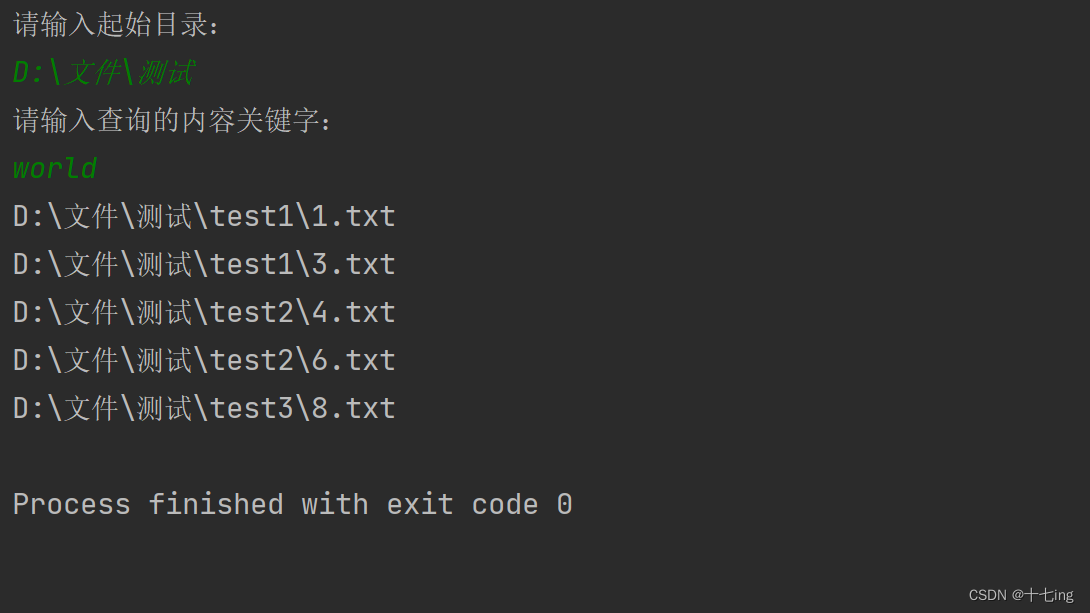
在程序清单17 中的代码,在扫描目录和普通文件数量较多时,效率较低,因为它涉及到了密集的磁盘 IO,每一次查询都要重新扫一遍磁盘,扫描的工作都是在查询中进行,所以较慢。举个例子:小明口渴了,准备从家里出发去小卖部买水,于是他就得跑过去再跑回来,当回家的时候,他的妈妈说,烧菜的时候缺盐,于是小明又得重新从家里出发,去便利店买了袋盐。
有一个软件叫做 《Everything》,这个软件的查询速率十分高效,当你按文件名搜索的时候,2秒钟不到,磁盘中的所有数据都能够按照关键字检索出来,相比于 windows 的直接搜索,Everything 这个软件极快。而 Everything 这个软件就是在查找数据之前,其通过了一些数据结构对磁盘数据做了预处理,做足了一些准备工作,所以快是有原因的。
举个例子:刚刚小明需要什么东西才出门买,那么当小明从家里出发之前,如果事先列好一份清单,再制定出行程路线,那么效率自然就上去了。
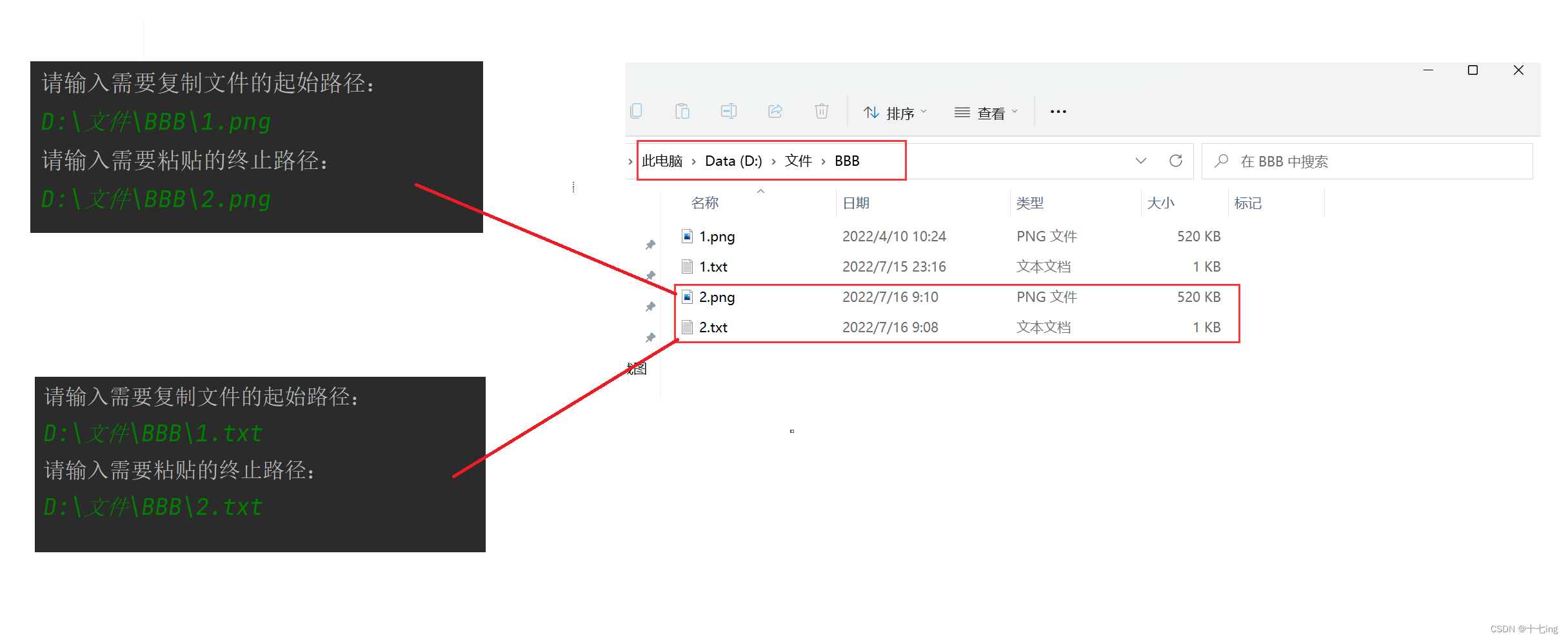
案例3 复制普通文件
编写代码复制一个文件,要求这个文件是一个普通文件,不是目录。启动程序之后,让用户指定一个待复制文件的绝对路径,再指定一个粘贴文件的终止路径。再通过这两个路径,来完成复制文件的逻辑。
假设我要让文件目录下的 BBB目录中 的 1.txt 和 1.png 分别复制成 2.txt 和 2.png
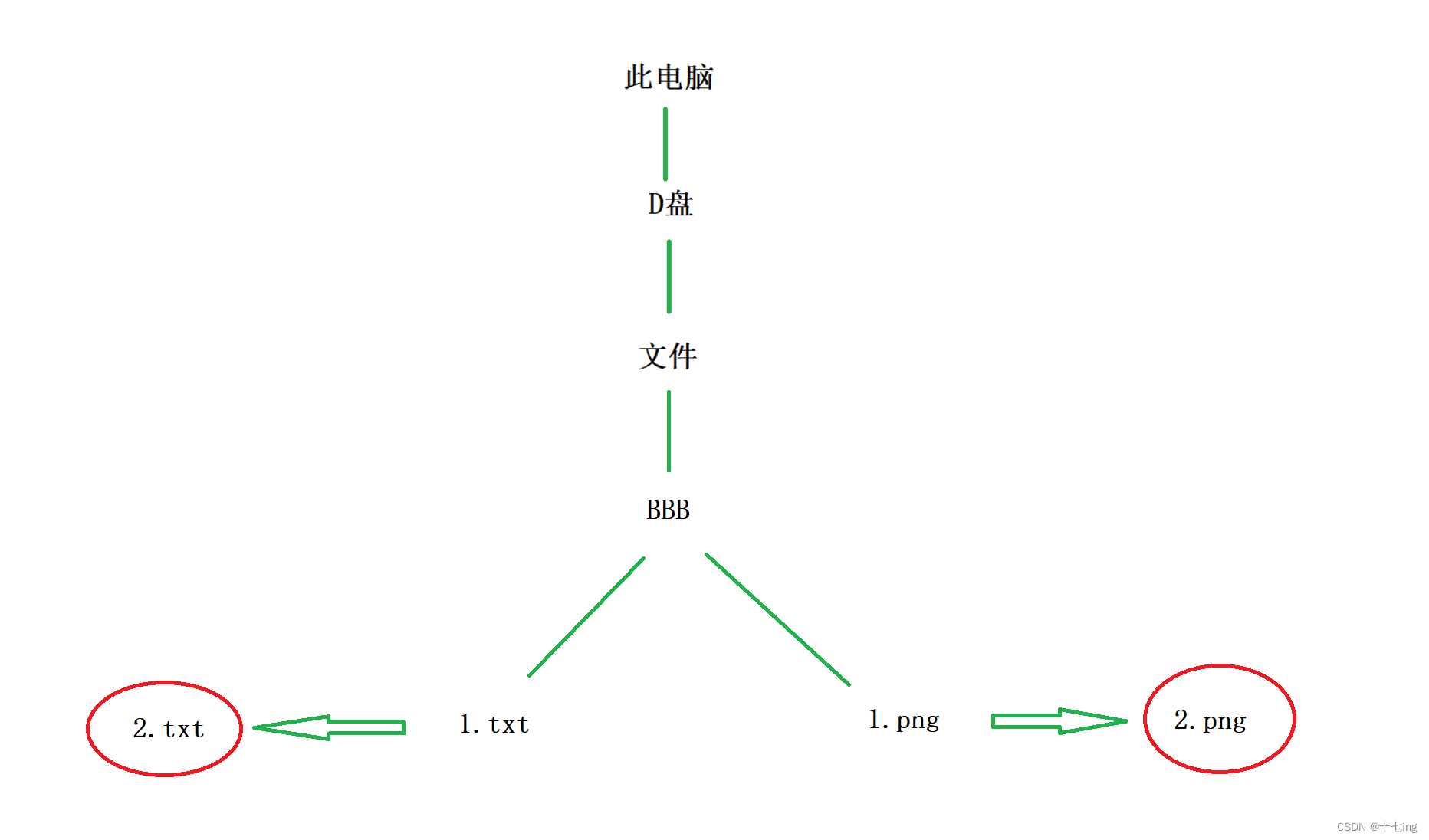
程序清单18:
import java.io.*;
import java.util.Scanner;public class Test18 {public static void main(String[] args) {//1. 让用户输入一个起始路径和一个目标路径Scanner scanner = new Scanner(System.in);System.out.println("请输入需要复制文件的起始路径:");String srcPath = scanner.nextLine();File srcFile = new File(srcPath);//2. 判断几种特殊情况//2.1 所复制的文件不存在 或 不是一个文件格式if (!srcFile.exists() || !srcFile.isFile()) {System.out.println("你所要复制的文件不存在 或 它不是一个文件格式,请检查格式!");return;}System.out.println("请输入需要粘贴的终止路径:");String destPath = scanner.nextLine();File destFile = new File(destPath);//2.2 所复制的文件在终止路径下重名if (destFile.exists()) {System.out.println("你所要复制的文件在终止路径下已经存在,即将退出程序!");return;}//2.3 所复制的文件的父目录不存在if (!destFile.getParentFile().exists() ) {System.out.println("你所要复制的文件的终止路径不存在,即将退出程序!");return;}//3. 先读待复制的文件,再将读到的内容写入到终止路径中try ( InputStream inputStream = new FileInputStream(srcFile);OutputStream outputStream = new FileOutputStream(destFile) ) {while (true) {byte[] buffer = new byte[1024];int len = inputStream.read(buffer);if (len == -1) {break;}//这里应该注意 len 的范围,当 len > 1024 还好说//但假设 len = 500 < 1024 的时候,我们就必须控制范围,//最好不要超过当前 len 的值,防止写入一些无效的数据//outputStream.write(buffer); //不建议使用带有一个参数的 write 方法outputStream.write(buffer,0,len);}//刷新缓冲区//这里如果不加 flush,try() 会自动触发 close 方法,也就能自动刷新缓冲区outputStream.flush();} catch (IOException e) {e.printStackTrace();}}
}
测试结果: