前言
今天学习数据结构看到了一个词-静态查找表,还有与之对应的动态查找表,然后我发现。
啊,这是个啥,好像知道又好像不知道,不就是查找吗,干嘛弄这些专业的说法,回头翻了一下数据结构的书,才发现......。
唉,小小的抱怨一下,不过,我从这两个词联想到了一门基础但是要精通又不简单的学问,就是查找,然后还有前天被面试官问到的一个查找题,题目很简单,如何查找单向链表中倒数第K个数?当然你先遍历一遍数组,获取数组的总长度,然后再遍历一遍找倒数第K个数,当然可以,但是既然是面试题,这样的答案基本是凉凉的,我自己都不满意,更别提人家面试官了,当你抛出这个答案之后,面试官会说如果只遍历一遍呢?你就懵逼了,如果你和我一样懵逼的话,那么恭喜你,你现在还来得及,当然正确方法我就不说了,感兴趣的可以去想想,实在想不出来,我相信你会有办法的,xixixi,也不难。
好了,说了这么多,今天既然发现了自己的一个薄弱区-查找,指不准以后哪天还会在查找这里栽倒,于是,何不在这之前好好梳理一下查找这块呢?
目录
1.静态查找表
2.动态查找表
3.哈希表
正文
首先我们需要明白下静态查找表和动态查找表的定义,所谓的静态查找表是指在查找过程中只进行查找操作,动态查找表就是在查找过程中还会进行插入和删除操作,例如,查找某个元素,若查找到了,则删除。
1.静态查找表
静态查找表可以有不同的表示方法,在不同的表示方法中,实现的查找操作方法也不同。
这里列举平时遇到的最为常见的两种情况
a.以顺序表或线性链表表示静态查找表,则查找可用顺序查找来实现
b.以有序表(排好顺序的顺序表) 表示静态查找表,则查找可用折半查找(二分查找)来实现
第一种,就是一个for循环的事,就不赘述了,这里看一下第二种情况,也就是二分查找的代码,思想就是从中间位置起开始查找,如果正好位于正中间,那么就找到了,如果比正中间数据大,那么在后半部分查找,假设整个数据是升序,如果比正中间数据小,那么在前半部分查找,依次类推,递归结束的标志就是左边界大于右边界,也就是已经不能再分了,如果此时还没查找到,那么就返回未查找到即可
public class BinarySearch {public static void main(String[] args) {// TODO Auto-generated method stubint[] a=new int[]{2,3,5,8,9};int index=search(a,50);System.out.println(index);}public static int search(int[] a,int data){return binarlSearch(a, 0, a.length-1,data);}public static int binarlSearch(int[] a,int left,int right,int data){if(left>right)return -1;int mid=(left+right)/2;if(a[mid]==data){return mid;}else if(a[mid]<data){return binarlSearch(a, mid+1, right, data);}else{return binarlSearch(a, left, mid-1, data);}}
}上面的只是查找里的入门知识,学任何东西都像打怪升级一样,先从小怪开始,由简变难,下面我们升级来打一个大点的怪!
2.动态查找表
动态查找表的特点是:表结构本身是在查找过程中动态生成的,即对于给定的key值,若表中存在其关键字等于key的记录,则查找成功返回,否则插入关键字等于key的记录。
动态查找表也可有不同的表示方法,这里主要讨论以各种树结构表示时的实现方法。
a.二叉排序树(又叫 二叉搜索树 二叉查找树)
二叉排序树的特点是:
1.若它的左子树不为空,则左子树上所有节点的值均小于它的根节点的值
2.若它的右子树不为空,则右子树上所有节点的值均大于它的根节点的值
3.它的左右子树也分别为二叉排序树
在了解了这个树的性质之后,我们不难联想到二分查找的思想,只不过大同小异,首先和根节点比较,如果比根节点大,则在右子树中查找,如果比根节点小,则在左子树中查找,如果相等,那么正好查找到了,如果左子树也没有,右子树也没有,则查找失败。
好了,我们掌握了上面的思想,不难写出下面的代码
public boolean contains(Node root, Node node) {if (root == null) {return false;}if (node.data == root.data) {return true;} else if (node.data > root.data) {return contains(root.rChild, node);} else {return contains(root.lChild, node);}}代码不难理解,然后我们再考虑这样一种情况,就是一个有序的链表,是不是也符合二叉排序树的性质,也就是说我们查找的这棵二叉排序树是有可能退化为一个链表的,那么我们再对照着上面这个查找的代码去看,会发现查找的效率已经退化成了O(n),这显然不是我们想要看到的结果,我们想要的效果是尽可能的将一组数据分为等长的两部分,以达到类似“二分”的效果,只有这样最终的效率才可以达到O log(n)的最优效果,于是我们就引出了这样一个问题,如何保证二叉排序树查找的效率维持在O log(n)呢?接着往下看
b.平衡二叉树
在上面,我们发现如果不对二叉排序树做任何处理,发现查找的效率会有可能退化为链表的查找效率,所以我们期望有一种解决方案能避免效率的降低,现在再来想想,为什么我们的查找效率会降低,究其原因就是二叉树退化成了链表,那么我们必须以某种手段来防止退化,比如强制要求左右子树的高度差小于某个值等措施,于是我们自然而然想到了平衡二叉树。
所以解决方案就是让二叉排序树转换为平衡二叉树,这个就好说了,主要涉及到四个操作,左左旋(LL)、右右旋(RR)、左右旋(LR)、右左旋(RL)。通过在插入一个元素的时候,判断是否符合平衡二叉树的性质,也就是左右子树的高度差是否小于1,如果不符合,那么根据情况做相应的旋转处理即可。
由于几个旋转基本类似,只要掌握了一个,剩下的依葫芦画瓢即可,我们现在来看下左左旋的代码
// 左左翻转 LL// 返回值为翻转后的根结点private Node leftLeftRotation(Node node) {// 首先获取待翻转节点的左子节点Node lNode = node.lChild;node.lChild = lNode.rChild;lNode.rChild = node;node.height = max(getHeight(node.lChild), getHeight(node.rChild)) + 1;lNode.height = max(getHeight(lNode.lChild), node.height) + 1;if (node == root) {root = lNode;// 更新根结点}return lNode;}剩下三个操作就不细说了,接下来我们再在插入和删除的时候,进行适当的判断,插入代码如下
public void insert(int data) {if (root == null) {root = new Node(data);} else {insert(root, new Node(data));}}// node 为插入的树的根结点// insertNode 为插入的节点private Node insert(Node node, Node insertNode) {if (node == null) {node = insertNode;} else {if (insertNode.data < node.data) {// 将data插入到node的左子树node.lChild = insert(node.lChild, insertNode);// 如果插入后失衡if (getHeight(node.lChild) - getHeight(node.rChild) == 2) {if (insertNode.data < node.lChild.data) {// 如果插入的是在左子树的左子树上,即要进行LL翻转node = leftLeftRotation(node);} else {// 否则执行LR翻转node = leftRightRotation(node);}}} else if (insertNode.data > node.data) {// 将data插入到node的右子树node.rChild = insert(node.rChild, insertNode);// 如果插入后失衡if (getHeight(node.rChild) - getHeight(node.lChild) == 2) {if (insertNode.data > node.rChild.data) {node = rightRightRotation(node);} else {node = rightLeftRotation(node);}}} else {System.out.println("节点重复啦");}node.height = max(getHeight(node.lChild), getHeight(node.rChild)) + 1;}return node;}删除代码如下
public void remove(int data) {Node removeNode = new Node(data);if (contains(root, removeNode)) {remove(root, removeNode);} else {System.out.println("节点不存在,无法删除"+data);}}// 删除节点private Node remove(Node node, Node removeNode) {if (node == null) {return null;}// 待删除节点在node的左子树中if (removeNode.data < node.data) {node.lChild = remove(node.lChild, removeNode);// 删除节点后,若失去平衡if (getHeight(node.rChild) - getHeight(node.lChild) == 2) {Node rNode = node.rChild;// 获取右节点// 如果是左高右低if (getHeight(rNode.lChild) > getHeight(rNode.rChild)) {node = rightLeftRotation(node);} else {node = rightRightRotation(node);}}} else if (removeNode.data > node.data) {// 待删除节点在node的右子树中node.rChild = remove(node.rChild, removeNode);// 删除节点后,若失去平衡if (getHeight(node.lChild) - getHeight(node.rChild) == 2) {Node lNode = node.lChild;// 获取左节点// 如果是右高左低if (getHeight(lNode.rChild) > getHeight(lNode.lChild)) {node = leftRightRotation(node);} else {node = leftLeftRotation(node);}}} else {// 待删除节点就是node// 如果Node的左右子节点都非空if (node.lChild != null && node.rChild != null) {// 如果左高右低if (getHeight(node.lChild) > getHeight(node.rChild)) {// 用左子树中的最大值的节点代替nodeNode maxNode = maxNode(node.lChild);node.data = maxNode.data;// 在左子树中删除最大的节点node.lChild = remove(node.lChild, maxNode);} else {// 二者等高或者右高左低// 用右子树中的最小值的节点代替nodeNode minNode = minNode(node.rChild);node.data = minNode.data;// 在右子树中删除最小的节点node.rChild = remove(node.rChild, minNode);}} else {// 只要左或者右有一个为空或者两个都为空,直接将不为空的指向node// 两个都为空的话,想当于最后node也指向了空,逻辑仍然正确node = node.lChild == null ? node.rChild : node.lChild;// 赋予新的值}}if(node!=null) {node.height = max(getHeight(node.lChild), getHeight(node.rChild)) + 1;}return node;}
每次在插入和删除时进行这样的操作之后,我们的二叉排序树终于变成一颗平衡二叉树啦,这样我们再执行上面一模一样的查找代码时,查找的效率就可以稳定在O log(n),完美!
其实仔细想想,这个问题,也是一个取舍的问题,虽然我们最后让二叉排序树的查找效率稳定为O log(n),但是我们却付出了不小的代价,就是每次插入以及删除的时候,都要进行大量的判断以及节点转换,这肯定会大大降低插入和删除的效率,与之带来的收益就是查找效率高,这样再一想,发现有点类似数组和链表的优缺点了,hhhh,事物总是有两面性,所以我们在实际使用时,也要根据场景来适当的做出取舍。
3.哈希表
在说哈希表之前,先回忆一下两个最简单的容器,一个是数组,一个是链表,这二者的优缺点我就不啰嗦了,之前的博客我也说过这样一个问题,既然数组查询快,链表插入删除快,就不能发明一种容器能兼具这二者的优点吗?这样岂不时省事多了,答案是能,没错,这个神奇的容器就是HashMap,而其核心就是哈希表,这时候,你兴冲冲的去查询哈希表,可能会遇到很多晦涩难懂的概念,什么关键字冲突,线性探测再散列,链地址法,再哈希等等,一下子头就大了,放心,我不会去给你灌输这些概念,我喜欢以实际使用的东西,或者叫“成品”来学习某个新的东西,然后再反过来看这些概念,这样就自然而然懂了,所以我们先简单了解HashMap的实现原理,再来看哈希表,就自然而然懂了。
既然是了解HashMap的实现原理,最最正确的方式就是直接打开jdk的源码去看,重点看核心方法put和remove即可,限于篇幅,我就说下大致思想。
我们首先需要知道的是HashMap存储的数据是键值对的形式,也就是key-value形式,然后就是HashMap里的一些重要成员变量及类,其中最重要的就是Node对象,每个Node对象含有key和value字段,用于保存插入的key和value值,Node数组的默认长度是16,当插入一个元素的时候,首先计算key的hash值,然后直接和数组长度-1做与运算,这样就定位到一个具体的下标,然后判断下标处是否有元素值存在,如果有,则以尾插法在该处形成一个链表,否则,就直接放入这个插入元素即可,所以最终效果就是这样的

看了这个结构图后,我们再回到我们的主题--查找,我们再来看看HashMap是如何查找的,首先拿到key值,计算key的hash值,然后同样的方法,和长度减1做与运算,得到下标,如果该下标处为空,则返回找不到,如果不为空,则从链表头开始,逐个遍历该链表,直到找到对应的value值与给定value值相等,若链表遍历完了仍然没有找到,则返回找不到。
我们现在再来看看这个设计有什么巧妙的地方,当我们在查询一个元素时,发现,对于哈希表来说,首先会根据key值来定位一个下标,这个巧妙利用了数组的优势,这样就不用去逐个遍历所有元素,然后如果发现该下标处已经存在了元素,则形成一个链表,而在形成一个链表之后,对同一个下标处的元素来说,插入删除的效率也变高了。或者换种通俗的话就是,使用数组将一个链表分割成了多个小段。总的来说这种设计就是结合了数组和链表,利用了二者的优势所在,完美结合!
好了,到这里,其实就已经学习了哈希表的一种,如上图,就是链地址法解决冲突的哈希表,相信到这里你也明白了,所谓的链地址法的具体含义,就是形成一个链表来解决冲突问题。
链地址法也是最常见的一种设计哈希表的方法,我们现在再来看看另外的两种。
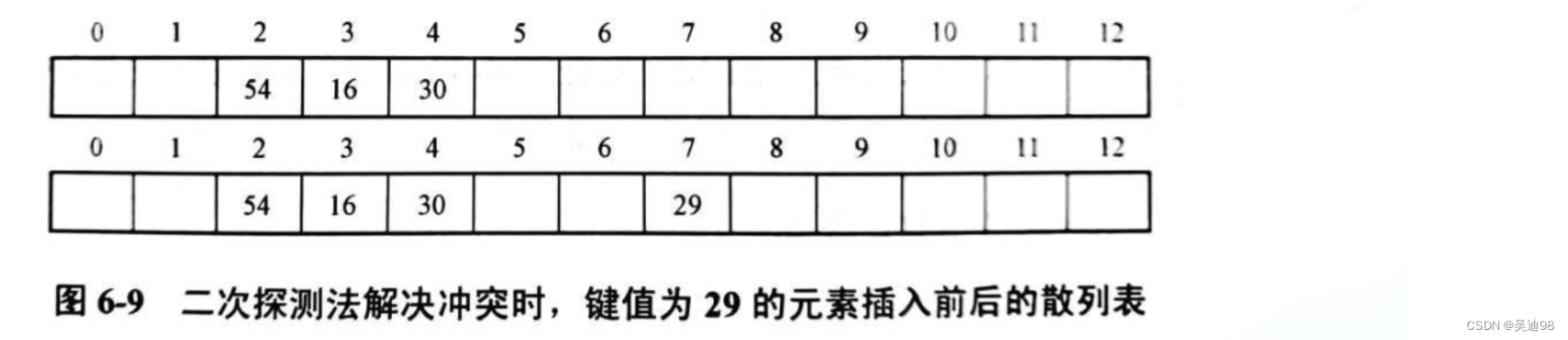
线性探测再散列法,这种设计方式设计的哈希表的原理就是,当插入一个元素的时候,同样的先定位到一个下标,然后如果该下标处已经存在了元素,则判断下标+1的地方是否有元素存在,同样的如果仍然有元素存在,则下标继续+1,直到对应下标处没有元素存在时,则将元素插在这个地方。
再哈希法,这个设计方式就比较简单粗暴了,直接在计算key的hash值的方法时,也就是在定位具体的下标时,用两次hash函数来计算,这样原本一次hash计算到相同地方的元素,因为有第二次hash计算,所以会在二次hash函数处理之后,再次判断是否定位到了同一下标,若还是定位在统一下标,则继续hash函数处理,直到冲突不再发生。
我们仍然回到我们的主旨--查找上来,对这两种方法设计的哈希表,我们在查找时就是先定位,然后如果不存在元素,则“查找返回空”,否则比对对应的value值,如果不相等,则根据设计方法(线性探测再散列或再哈希)得到“下一个地址”,然后判断“下一个地址”是否为要查找的元素。
好了,到这里,基本说完了三种设计哈希表的方式以及对应的查找方法,个人觉得每一种方式都有自己的特点和适用场景,没有孰好孰坏,只有当我们都掌握了之后,我们才可以去选择用哪种方式来实现哈希表,完成业务要求。
结语
这次说的主要是查找,内容相对简单,但是查找这个东西,一但结合实际场景之后,还是有很多需要注意和深究的地方,比如海量数据排序和查找,所以只有会了基础,才能有选择的余地,以后实际场景中若是遇到了相关的问题,再总结归纳一篇“实际场景版”的,今天就到这里了。