问题:
1、线上容器环境pod报错无法创建本地线程,如下图所示:

2、日志中出现报错信息 “fork:Cannot allocate memory”。如下图所示:

可能原因
1、内存不够
2、可能是进程数超限导致。系统内部的总进程数达到了 pid_max 时,再创建新进程时会报 “fork:Cannot allocate memory” 错。
解决思路
1、驱逐pod,先保证业务正常
2、查看实例内存使用率是否过高。
执行命令,查看系统 pid_max 值:sysctl -a | grep pid_max
pid_max 默认值为32768,返回结果如下图所示:

3、核实总进程数是否超限,并修改总进程数 pid_max 配置。
执行命令,查看系统内部总进程数:pstree -p | wc -l
若总进程数达到了 pid_max,则系统在创建新进程时会报 “fork Cannot allocate memory” 错。
同时你也可以执行 ps -efL 命令,定位启动进程较多的程序。
4、将 /etc/sysctl.conf 配置文件中的 kernel.pid_max 值修改为65535,以增加进程数。修改完成后如下图所示:

5、执行以下命令,使配置立即生效。
sysctl -p
注:当然这里面一般都不会将 kernel.pid_max 设置的很小,那出现这种情况该怎么办?
现实问题
1、出问题的时候可能为了优先保证服务正常,先简单查看下CPU,进程等相关情况。先驱逐pod,恢复服务
2、因为是宿主机出现问题,所以如果是开发不是运维的话就很难有权限查看到宿主机的一些日志情况,也就无法定位到哪个进程导致的
3、可能出问题的时候有权限的不在现场,等过后再排查,此时日志已经没有了
等等各种情况,那么要在事后分析原因,该如何处理?
事后处理问题依赖工具Atop
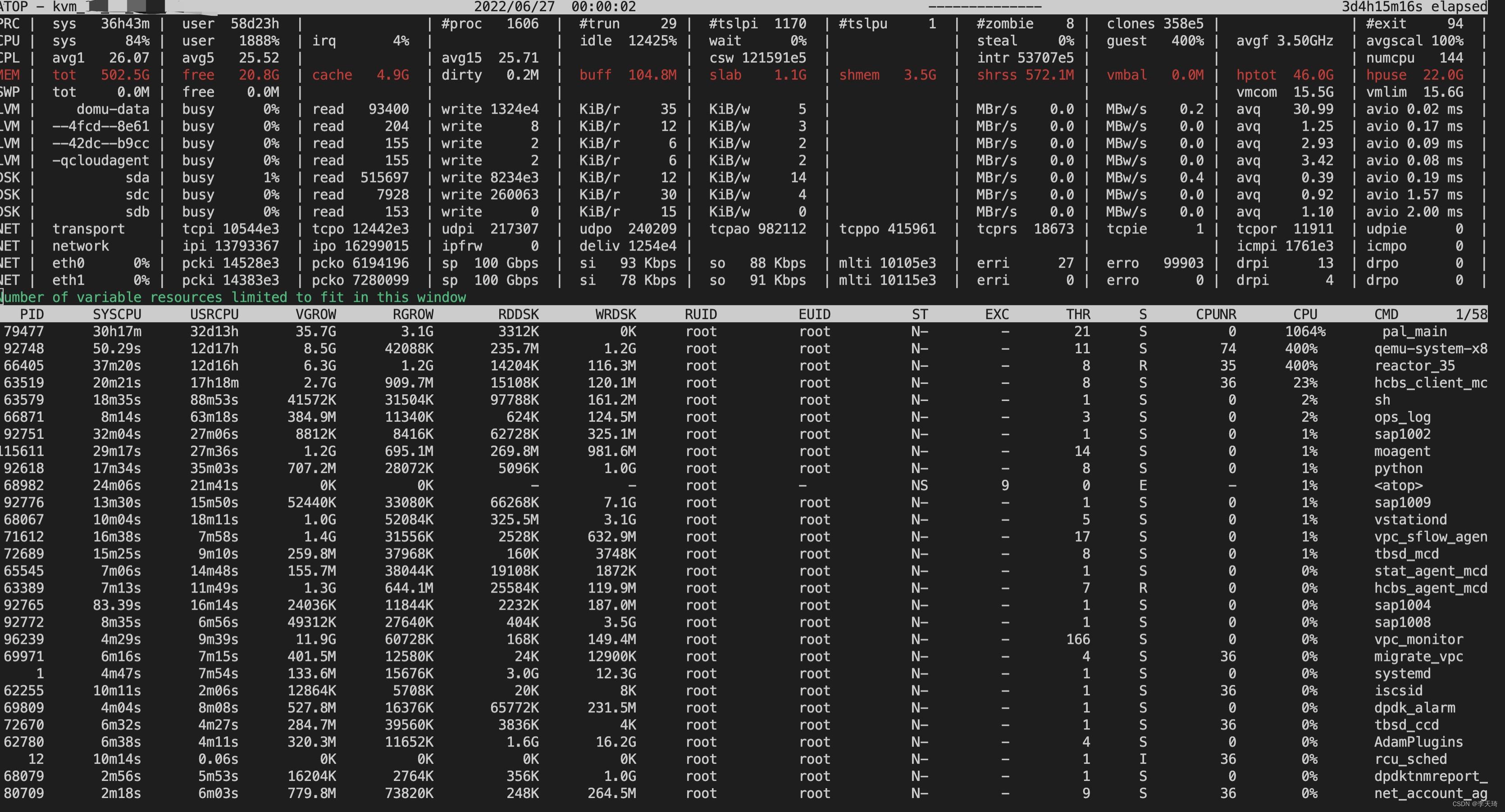
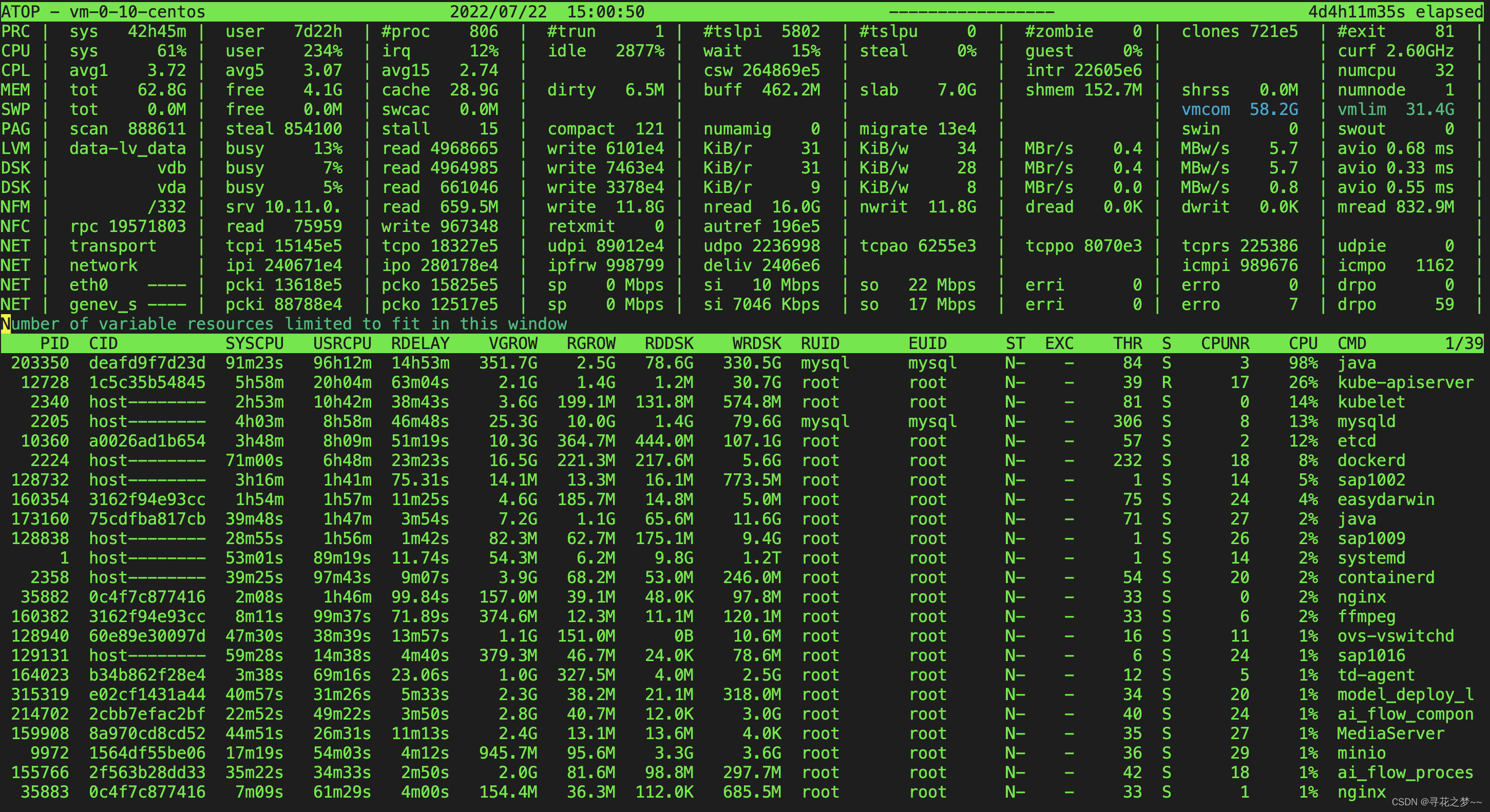
atop 是一款用于监控 Linux 系统资源与进程的工具,以一定的频率记录系统的运行状态,采集系统资源(CPU、内存、磁盘和网络)使用情况及进程运行情况数据,并以日志文件的方式保存在磁盘中。当实例出现问题时,可获取对应的 atop 日志文件用于分析。
atop安装
yum install atop -y
配置并启动atop
参考以下步骤,配置 atop 监控周期及日志保留时间。
1、执行以下命令,使用 VIM 编辑器打开 atop 配置文件。
vim /etc/sysconfig/atop
2、按 i 进入编辑模式,修改以下配置:
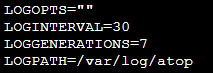
将 LOGINTERVAL=600 修改为 LOGINTERVAL=30,表示将默认的600s监控周期修改为30s。建议修改为30s,您可结合实际情况进行修改。
将 LOGGENERATIONS=28 修改为 LOGGENERATIONS=7,表示将默认的日志保留时间28天修改为7天。为避免 atop 长时间运行占用太多磁盘空间,建议修改为7天,您可结合实际情况进行修改。
修改完成后如下图所示:
分析Atop
atop 启动后,会将采集的数据记录在 /var/log/atop 目录的日志文件中。请获取实际的日志文件名,执行以下命令,查看日志文件并参考 atop 常用命令 及 系统资源监控字段说明 进行分析。atop -r /var/log/atop/atop_2021xxxx
atop 常用命令
您可在打开日志文件后,使用以下命令筛选所需数据:
- c:按照进程的 CPU 使用率降序筛选。
- m:按照进程的内存使用率降序筛选。
- d:按照进程的磁盘使用率降序筛选。
- a:按照进程资源综合使用率进行降序筛选。
- n:按照进程的网络使用率进行降序筛选(使用此命令需安装额外的内核模块,默认不支持)。
- t:跳转到下一个监控采集点。
- T:跳转到上一个监控采集点。
- b:指定时间点,格式为 YYYYMMDDhhmm。
系统资源监控字段说明
下图为部分监控字段以及数值,数值根据采样周期获取,仅作为参考。

主要参数说明如下:
- ATOP 行:主机名、信息采样日期和时间点。
- PRC 行:进程整体运行情况。
- sys 及 user:CPU 被用于处理进程时,进程在内核态及用户态所占 CPU 的时间比例。
- #proc:进程总数。
- #zombie:僵死进程的数量。
- #exit:Atop 采样周期期间退出的进程数量。
- CPU 行:CPU 整体(即多核 CPU 作为一个整体 CPU 资源)的使用情况。CPU 行的各字段数值相加结果为N00%,N 为 CPU 核数。
- sys 及 user:CPU 被用于处理进程时,进程在内核态及用户态所占 CPU 的时间比例。
- irq:CPU 被用于处理中断的时间比例。
- idle:CPU 处在完全空闲状态的时间比例。
- wait:CPU 处在“进程等待磁盘 IO 导致 CPU 空闲”状态的时间比例。
- CPL 行:CPU 负载情况。
- avg1、avg5 和 avg15:过去1分钟、5分钟和15分钟内运行队列中的平均进程数量。
- csw:指示上下文交换次数。
- intr:指示中断发生次数。
- MEM 行:内存的使用情况。
- tot:物理内存总量。
- cache :用于页缓存的内存大小。
- buff:用于文件缓存的内存大小。
- slab:系统内核占用的内存大小。
- SWP 行:交换空间的使用情况。
- tot:交换区总量。
- free:空闲交换空间大小。
- PAG 行:虚拟内存分页情况
- swin 及 swout:换入和换出内存页数。
- DSK 行:磁盘使用情况,每一个磁盘设备对应一列。如果有 sdb 设备,那么增加一行 DSK 信息。
- sda:磁盘设备标识。
- busy:磁盘忙时比例。
- read 及 write:读、写请求数量。
- NET 行:多列 NET 展示了网络状况,包括传输层(TCP 和 UDP)、IP 层以及各活动的网口信息。
- xxxxxi:各层或活动网口收包数目。
- xxxxxo:各层或活动网口发包数目。
停止 atop
不建议在业务环境下长期运行 atop,您可在问题排查完成后停止 atop。在 CentOS 7 及以上版本可执行以下命令,停止 atop。
systemctl stop atop