简单介绍
原因:普通的RNN(Recurrent Neural Network)对于长期依赖问题效果比较差,当序列本身比较长时,神经网络模型的训练是采用backward进行,在梯度链式法则中容易出现梯度消失和梯度爆炸的问题。
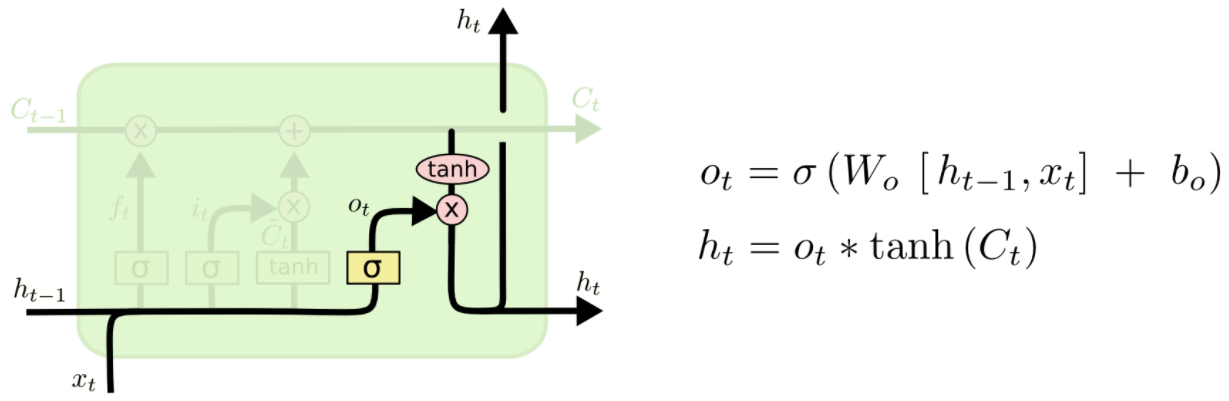
解决:针对Simple RNN存在的问题,LSTM网络模型被提出,LSTM的核心是修改了增添了Cell State,即加入了LSTM CELL,通过输入门、输出门、遗忘门把上一时刻的hidden state和cell state传给下一个状态。
实践
实践1,生成sin(x)的周期序列并预测下一序列
参考:https://blog.csdn.net/hustchenze/article/details/78696771
seq为序列数据,k为LSTM模型循环的长度,使用1 ~ k的数据预测2~k+1的数据。
1.x轴对应的是[0,10],因为0到10,0.01为一份,可以分1000份
2.有用 x = torch.arange(1,N,0.1)试过,效果不好,所以尽量细一些
3. K取值为5效果也不错,第10轮Train Loss:为0.009138899855315685
4. SeriesGen(8*math.pi)该函数用pi的倍数,效果似乎更好Train 第10轮迭代Loss: 0.002424872014671564
import torch
import torch.nn as nn
from torch.autograd import *
import torch.optim as optim
import torch.nn.functional as F
import matplotlib.pyplot as plt
import numpy as npdef SeriesGen(N):x = torch.arange(1,N,0.01)return torch.sin(x)def trainDataGen(seq,k):dat = list() L = len(seq)for i in range(L-k-1):indat = seq[i:i+k]outdat = seq[i+1:i+k+1]dat.append((indat,outdat))return datdef ToVariable(x):tmp = torch.FloatTensor(x)return Variable(tmp)y = SeriesGen(10)
dat = trainDataGen(y.numpy(),10)class LSTMpred(nn.Module):def __init__(self,input_size,hidden_dim):super(LSTMpred,self).__init__()self.input_dim = input_sizeself.hidden_dim = hidden_dimself.lstm = nn.LSTM(input_size,hidden_dim)self.hidden2out = nn.Linear(hidden_dim,1)self.hidden = self.init_hidden()def init_hidden(self):return (Variable(torch.zeros(1, 1, self.hidden_dim)),Variable(torch.zeros(1, 1, self.hidden_dim)))def forward(self,seq):lstm_out, self.hidden = self.lstm(seq.view(len(seq), 1, -1), self.hidden)outdat = self.hidden2out(lstm_out.view(len(seq),-1))return outdatmodel = LSTMpred(1,6)
loss_function = nn.MSELoss()
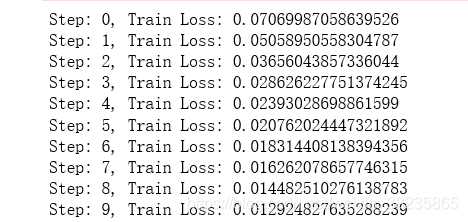
optimizer = optim.SGD(model.parameters(), lr=0.01)for epoch in range(10):for seq, outs in dat[:700]:seq = ToVariable(seq)outs = ToVariable(outs)#outs = torch.from_numpy(np.array([outs]))optimizer.zero_grad()model.hidden = model.init_hidden()modout = model(seq)loss = loss_function(modout, outs)loss.backward()optimizer.step()print('Step: {}, Train Loss: {}'.format(epoch, loss))打印的loss值:可以看出loss不断减小
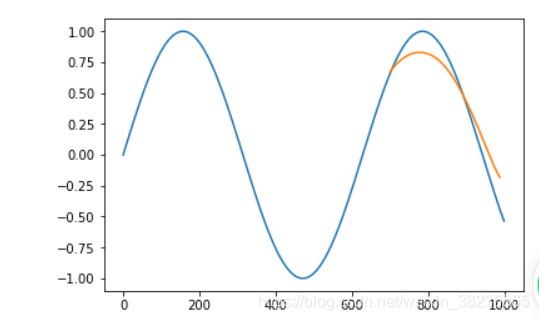
预测,作图
predDat = []
for seq, trueVal in dat[700:]:seq = ToVariable(seq)trueVal = ToVariable(trueVal)predDat.append(model(seq)[-1].data.numpy()[0])fig = plt.figure()
plt.plot(y.numpy())
plt.plot(range(700,889),predDat)
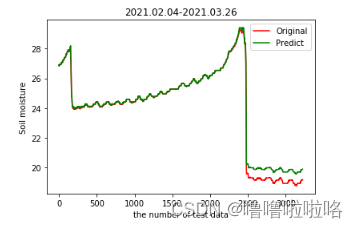
plt.show()结果:
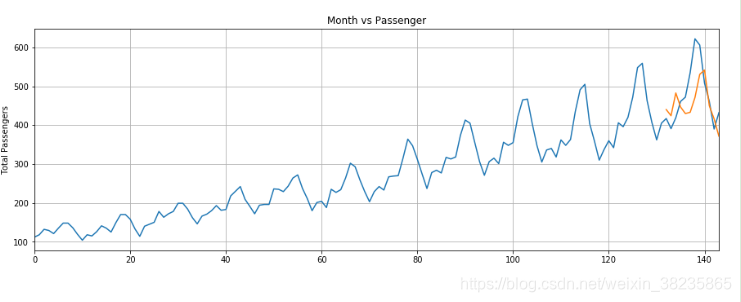
实践2,航班人次预测
flights数据集下载:https://www.arangodb.com/wp-content/uploads/2017/08/GraphCourse_DemoData_ArangoDB-1.zip
参考 :https://blog.csdn.net/weixin_40066612/article/details/111319587/
与实践1最大不同:
1.训练数据归一化
2.创建序列的方法,最后返回的类似是((第1到12月12个数据),(第13个月的值),而不是实践一((i-k个数据),(i+1,k+1))
3.预测值为model(seq).item(),比起实践一model(seq)[-1].data.numpy()[0]更简单
结果:
实践三:Pytorch中的LSTM
Pytorch中 LSTM 的输入形式是一个 3D 的Tensor,每一个维度都有重要的意义,第一个维度就是序列本身, 第二个维度是mini-batch中实例的索引,第三个维度是输入元素的索引。
官网例子:用LSTM来进行词性标注

def prepare_sequence(seq, to_ix):idxs = [to_ix[w] for w in seq]return torch.tensor(idxs, dtype=torch.long)training_data = [("The dog ate the apple".split(), ["DET", "NN", "V", "DET", "NN"]),("Everybody read that book".split(), ["NN", "V", "DET", "NN"])
]
word_to_ix = {}
for sent, tags in training_data:for word in sent:if word not in word_to_ix:word_to_ix[word] = len(word_to_ix)
print(word_to_ix)
tag_to_ix = {"DET": 0, "NN": 1, "V": 2}# 实际中通常使用更大的维度如32维, 64维.
# 这里我们使用小的维度, 为了方便查看训练过程中权重的变化.
EMBEDDING_DIM = 6
HIDDEN_DIM = 6class LSTMTagger(nn.Module):def __init__(self, embedding_dim, hidden_dim, vocab_size, tagset_size):super(LSTMTagger, self).__init__()self.hidden_dim = hidden_dimself.word_embeddings = nn.Embedding(vocab_size, embedding_dim)# LSTM以word_embeddings作为输入, 输出维度为 hidden_dim 的隐藏状态值self.lstm = nn.LSTM(embedding_dim, hidden_dim)# 线性层将隐藏状态空间映射到标注空间self.hidden2tag = nn.Linear(hidden_dim, tagset_size)self.hidden = self.init_hidden()def init_hidden(self):# 一开始并没有隐藏状态所以我们要先初始化一个# 关于维度为什么这么设计请参考Pytoch相关文档# 各个维度的含义是 (num_layers, minibatch_size, hidden_dim)return (torch.zeros(1, 1, self.hidden_dim),torch.zeros(1, 1, self.hidden_dim))def forward(self, sentence):embeds = self.word_embeddings(sentence)lstm_out, self.hidden = self.lstm(embeds.view(len(sentence), 1, -1),self.hidden)tag_space = self.hidden2tag(lstm_out.view(len(sentence), -1))tag_scores = F.log_softmax(tag_space, dim=1)return tag_scoresmodel = LSTMTagger(EMBEDDING_DIM, HIDDEN_DIM, len(word_to_ix), len(tag_to_ix))
loss_function = nn.NLLLoss()
optimizer = optim.SGD(model.parameters(), lr=0.1)# 查看训练前的分数
# 注意: 输出的 i,j 元素的值表示单词 i 的 j 标签的得分
# 这里我们不需要训练不需要求导,所以使用torch.no_grad()
with torch.no_grad():inputs = prepare_sequence(training_data[0][0], word_to_ix)tag_scores = model(inputs)print(tag_scores)for epoch in range(300): # 实际情况下你不会训练300个周期, 此例中我们只是随便设了一个值for sentence, tags in training_data:# 第一步: 请记住Pytorch会累加梯度.# 我们需要在训练每个实例前清空梯度model.zero_grad()# 此外还需要清空 LSTM 的隐状态,# 将其从上个实例的历史中分离出来.model.hidden = model.init_hidden()# 准备网络输入, 将其变为词索引的 Tensor 类型数据sentence_in = prepare_sequence(sentence, word_to_ix)targets = prepare_sequence(tags, tag_to_ix)# 第三步: 前向传播.tag_scores = model(sentence_in)# 第四步: 计算损失和梯度值, 通过调用 optimizer.step() 来更新梯度loss = loss_function(tag_scores, targets)loss.backward()optimizer.step()# 查看训练后的得分
with torch.no_grad():inputs = prepare_sequence(training_data[0][0], word_to_ix)tag_scores = model(inputs)# 句子是 "the dog ate the apple", i,j 表示对于单词 i, 标签 j 的得分.# 我们采用得分最高的标签作为预测的标签. 从下面的输出我们可以看到, 预测得# 到的结果是0 1 2 0 1. 因为 索引是从0开始的, 因此第一个值0表示第一行的# 最大值, 第二个值1表示第二行的最大值, 以此类推. 所以最后的结果是 DET# NOUN VERB DET NOUN, 整个序列都是正确的!print(tag_scores)