Hard Negatie Mining与Online Hard Example Mining(OHEM)都属于难例挖掘,它是解决目标检测老大难问题的常用办法,运用于R-CNN,fast R-CNN,faster rcnn等two-stage模型与SSD等(有anchor的)one-stage模型训练时的训练方法。
OHEM和难负例挖掘名字上的不同。
- Hard Negative Mining只注意难负例
- OHEM 则注意所有难例,不论正负(Loss大的例子)
难例挖掘的思想可以解决很多样本不平衡/简单样本过多的问题,比如说分类网络,将hard sample 补充到数据集里,重新丢进网络当中,就好像给网络准备一个错题集,哪里不会点哪里。
难例挖掘与非极大值抑制 NMS 一样,都是为了解决目标检测老大难问题(样本不平衡+低召回率)及其带来的副作用。
根据每个RoIs的loss的大小来决定哪些是难样例, 哪些是简单样例, 通过这种方法, 可以更高效的训练网络, 并且可以使得网络获得更小的训练loss
OHEM和focal loss的作用类似
实现技巧:
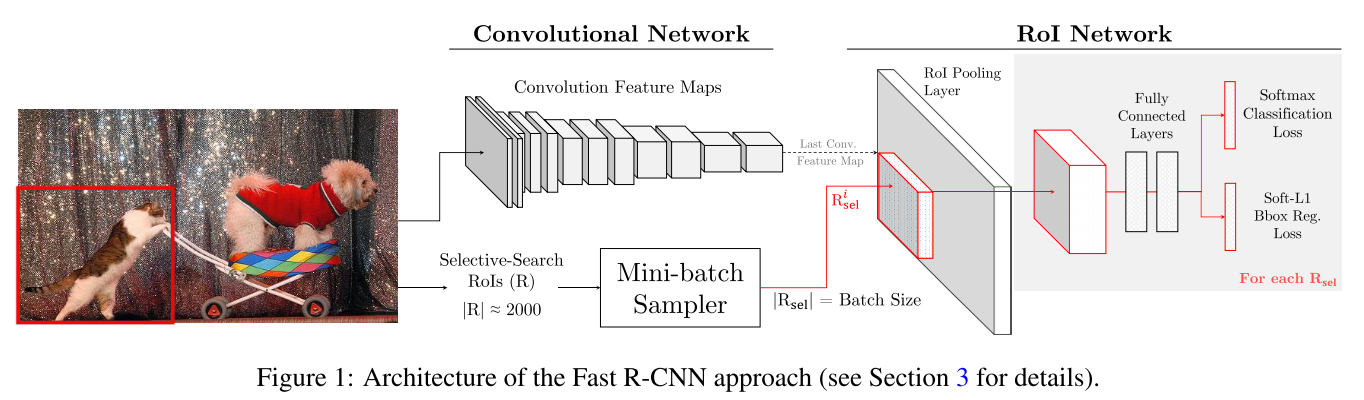
论文,作者将该方法是现在 Fsat R-CNN 目标检测方法中。最简单做法是更改损失函数层,损失函数层首先计算所有 ROI 的 loss, 然后根据 loss 对 ROI 进行排序,并选择 hard RoIs, 让 那些 non-RoIs的损失变为0. 这种方法虽然很简单,但是非常不高效,因为还需要为所有的 RoIs 分配进行反向传播时需要的内存空间。
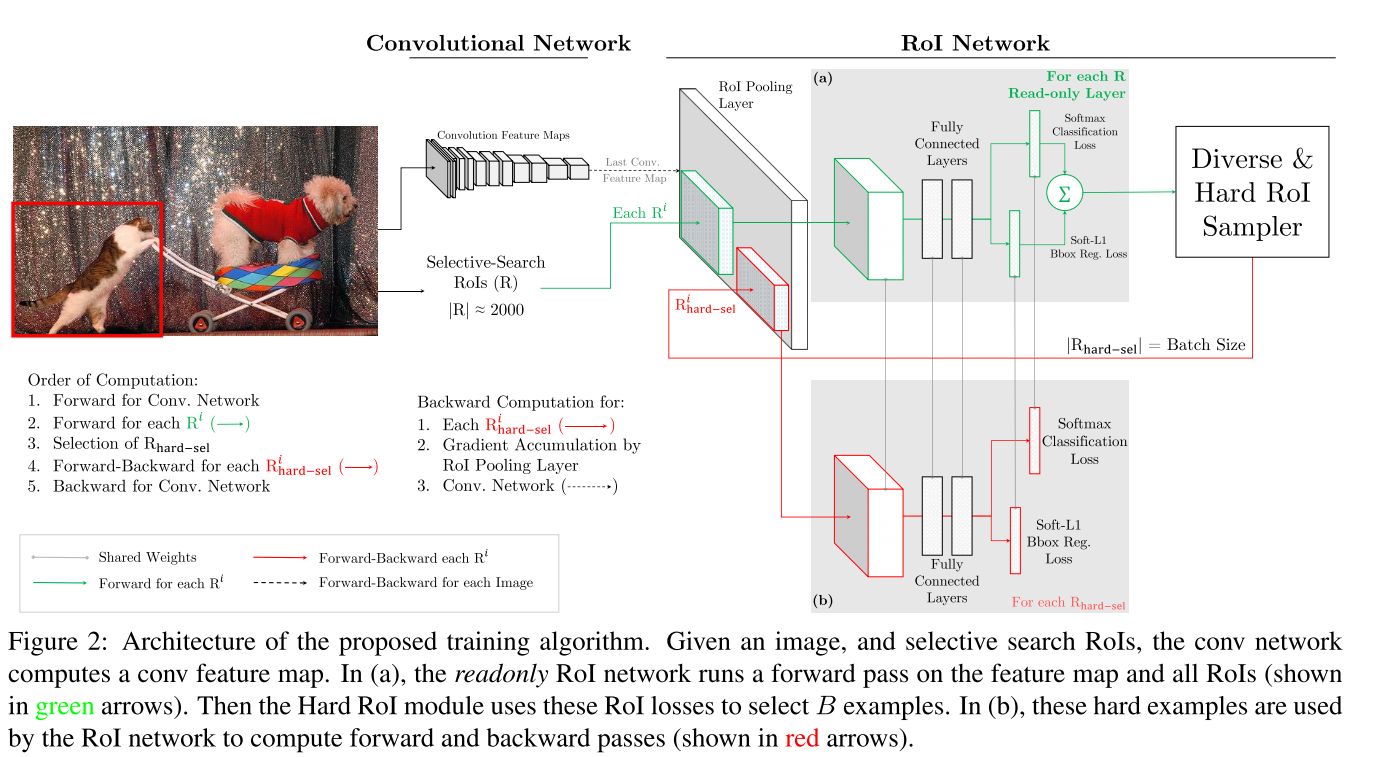
为了克服这个缺点,作者对下面的 Figure 1 进行改进, 如下面的 Figure 2.该改进时使用两份同样的 RoI network。 其中一个是只读的(readonly), 即只进行前向计算,不进行反向传播优化,所以只需要为前向传播分配内存,它的参数实时保持和另一个 RoI network(regular RoI network)保持一样。在每次迭代时,首先使用 readonly RoI network 对每个 ROI 计算起 loss,然后用上面描述的选择 hard RoIs 的方法选择 hard RoIs. 然后利用 regular RoI network来对选择的 hard RoIs 进行前向和后向计算来优化网络。
Pytorch实现
def ohem_loss(batch_size, cls_pred, cls_target, loc_pred, loc_target, smooth_l1_sigma=1.0 ):"""Arguments:batch_size (int): number of sampled rois for bbox head trainingloc_pred (FloatTensor): [R, 4], location of positive roisloc_target (FloatTensor): [R, 4], location of positive roispos_mask (FloatTensor): [R], binary mask for sampled positive roiscls_pred (FloatTensor): [R, C]cls_target (LongTensor): [R]Returns:cls_loss, loc_loss (FloatTensor)"""ohem_cls_loss = F.cross_entropy(cls_pred, cls_target, reduction='none', ignore_index=-1)ohem_loc_loss = smooth_l1_loss(loc_pred, loc_target, sigma=smooth_l1_sigma, reduce=False)#这里先暂存下正常的分类loss和回归lossloss = ohem_cls_loss + ohem_loc_loss#然后对分类和回归loss求和sorted_ohem_loss, idx = torch.sort(loss, descending=True)#再对loss进行降序排列keep_num = min(sorted_ohem_loss.size()[0], batch_size)#得到需要保留的loss数量if keep_num < sorted_ohem_loss.size()[0]:#这句的作用是如果保留数目小于现有loss总数,则进行筛选保留,否则全部保留keep_idx_cuda = idx[:keep_num]#保留到需要keep的数目ohem_cls_loss = ohem_cls_loss[keep_idx_cuda]ohem_loc_loss = ohem_loc_loss[keep_idx_cuda]#分类和回归保留相同的数目cls_loss = ohem_cls_loss.sum() / keep_numloc_loss = ohem_loc_loss.sum() / keep_num#然后分别对分类和回归loss求均值return cls_loss, loc_loss
OHEM(Online Hard Example Mining)在线难例挖掘(在线困难样例挖掘) Pytorch实现 HNM (目标检测)
article/2025/11/11 6:38:55
相关文章



OHEM(Online Hard Example Mining )算法
OHEM算法提出于论文 Training Region-based Object Detectors with Online Hard Example Mining,链接:https://arxiv.org/abs/1604.03540。在hard example(损失较大的样本)反向传播时,可以减少运算量。
OHEM主要思想是…
虚拟机VMware官网下载教程,中文详细步骤(图文)
目录
一、找到官网
二、注册,登录(之前有账号的直接登录)
三、下载
四、VMware安装
五、Ubuntu下载,安装 一、找到官网 中文官网:VMware 中国 - 交付面向企业的数字化基础 | CNhttps://www.vmware.com/cn.html …
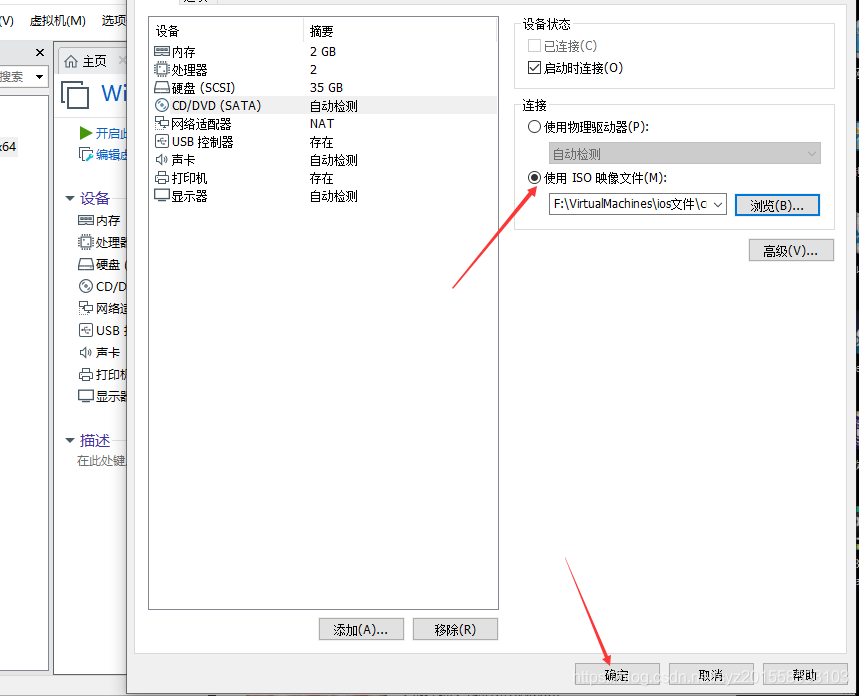
虚拟机VMware Workstation安装使用教程
1.官网下载,百度一个序列号进行注册。
2.打开VM,创建虚拟机 2.初次使用的话,选择典型就可以 3.如果有已有的iso文件,可以选择“安装程序光盘印象文件”,但是这是简易安装,可能后期会出现bug,不…

VMware安装虚拟机详细教程
VMware安装虚拟机目录 一、VMware添加虚拟机二、虚拟机启动及配置三、IP地址、子网掩码、网关和域名 一、VMware添加虚拟机 在我们安装完VWware,下载好安装的操作系统的镜像文件后(这里我们是(centos7版本),可以开始安…
VMware下载与安装教程(详细)
虚拟机VMware下载与安装教程 1. VMware最新版下载Vmware历史版本下载 2. VMware的安装 1. VMware最新版下载
Vmware官网 官网界面如下
点击产品,找到 Workstation Pro
之后会跳转到如下界面,点击下载试用版
根据自己的操作系统是Linux还是Windows选择对应的版…

虚拟机 VMware 16安装教程
虚拟机 VMware 16下载
见评论区 软件简介
VMware(虚拟机)是指通过软件模拟的具有完整硬件系统功能的、运行在一个完全隔离环境中的完整计算机系统,它能在Windows系统上虚拟出多个计算机,每个虚拟计算机可以独立运行,…

虚拟化技术之 VMware Workstation教程(一)
目录 第一章 虚拟化技术
1.1虚拟化技术简介
1.2主流的虚拟化厂商及产品
第二章 虚拟机的安装
2.1安装VMwareWorkstation 12
2.2物理机所需硬件
2.3在虚拟机中安装Windows 7操作系统
第三章 虚拟机的网络设置
3.1网络接入模式
3.2设置虚拟机上网
3.3设置两台虚拟机之…

VMware Workstation Pro详细安装教程
一,VMware Workstation Pro介绍 VMware Workstation(中文名“威睿工作站”)是一款功能强大的桌面虚拟计算机软件,提供用户可在单一的桌面上同时运行不同的操作系统,和进行开发、测试 、部署新的应用程序的最佳解决方案…
VMware虚拟机下载与安装教程(详细的很,一看就懂)
CSDN话题挑战赛第2期 参赛话题:学习笔记 🔶 个人主页: 神仙阿姨的博客 🔴 分享网站: 《Python自学网》👉👉适合新手入门到精通 | python全栈体系课程 | WEB开发 | 爬虫 | 自动化运维 …
![VMware安装虚拟机操作步骤[史上最详细]](https://img-blog.csdnimg.cn/1795b06cf4254965a81ff0a6f3059b88.png)
VMware安装虚拟机操作步骤[史上最详细]
一、下载并安装VMware虚拟化软件
百度搜索关键词 安装步骤:傻瓜式安装(鼠标点点点,这里不做截屏演示)
二、安装秘钥
1、百度搜索关键词VMware秘钥,秘钥不一定都有效,一个一个试总有一个可以的 …
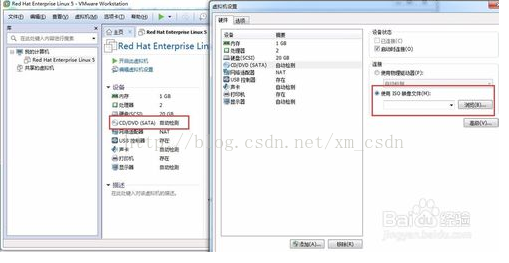
虚拟机VMware的安装及使用
一 虚拟机VMware的安装 1.准备工作 1)需要软件VMware安装包 VMware下载地址:
http://www.uzzf.com/soft/51188.html 2)需要一个系统镜像 windows系统:
http://www.xitongcheng.com/win7/ ubuntu系统镜像下载:
http://www.ubuntu.org.cn/do…
VMware虚拟机安装教程
虚拟机(Virtual Machine)是通过软件模拟的完整计算机系统。在实体计算机中能够完成的工作在虚拟机中都能够实现。在计算机中创建虚拟机时,需要将实体机的部分硬盘和内存容量作为虚拟机的硬盘和内存容量。每个虚拟机都有独立的CMOS、硬盘和操作系统,可以像…
vmware虚拟机的基础使用
1.vmware VMWare虚拟机软件来测试软件、测试安装操作系统(如linux)、测试病毒木马等。 VMWare是真正“同时”运行,多个操作系统在主系统的平台上,就象标准Windows应用程序那样切换。而且每个操作系统你都可以进行虚拟的分区、配置…
虚拟机介绍与使用(VMware Workstation)
目录 一、虚拟机概述
1、什么是虚拟机?
2、软件运行的架构
①传统运行模式
②虚拟机运行的模式
3、虚拟机产品
①VMware(威睿)
②Micro Soft(微软)
③Citrix(思杰)
二、虚拟机的安装与…
VMware 虚拟机安装与使用
VMware 下载
进入官网的 VMware Workstation Pro 页面,浏览功能特性、应用场景、系统要求等。下滑页面点击 试用 Workstation 16 Pro 下方的下载链接,跳转至下载页面。 在下载页面中下滑,根据操作系统选择合适的产品,在这里以 Wi…