文|python
前言
近期,ChatGPT成为了全网热议的话题。ChatGPT是一种基于大规模语言模型技术(LLM, large language model)实现的人机对话工具。现在主流的大规模语言模型都采用Transformer网络,通过极大规模的数据进行自监督训练。但是,如何构建自监督训练数据?在基础的Transformer结构上,大家又做了哪些创新呢?为了保证训练过程高效且稳定,又有哪些黑科技呢?今天给大家介绍一篇来自人民大学的综述论文,为大家解密这些大模型的训练技巧。
论文地址:
https://arxiv.org/pdf/2303.18223.pdf
各个大模型的研究测试传送门
ChatGPT传送门(免墙,可直接测试):
https://yeschat.cn
GPT-4传送门(免墙,可直接测试,遇到浏览器警告点高级/继续访问即可):<br>
https://gpt4test.com
训练数据的收集与处理
大规模语言模型对训练数据的规模与质量都有更高的要求。那现在的大模型都用了什么语料?这些语料都发挥着怎样的作用?如何对语料做清洗和预处理?大模型还有什么特殊的细节需要我们去处理?
数据来源
数据来源上,大规模语言模型的训练数据可以一般性语料与特殊语料。一般性语料,如网页、书籍、对话文本,占比较大,可以在各种话题上为模型提供语言知识;而特殊语料,如多语言数据、科技语料、代码等,可以为模型带来解决特定任务的能力。现有的大模型训练语料的成分比例如下图所示:
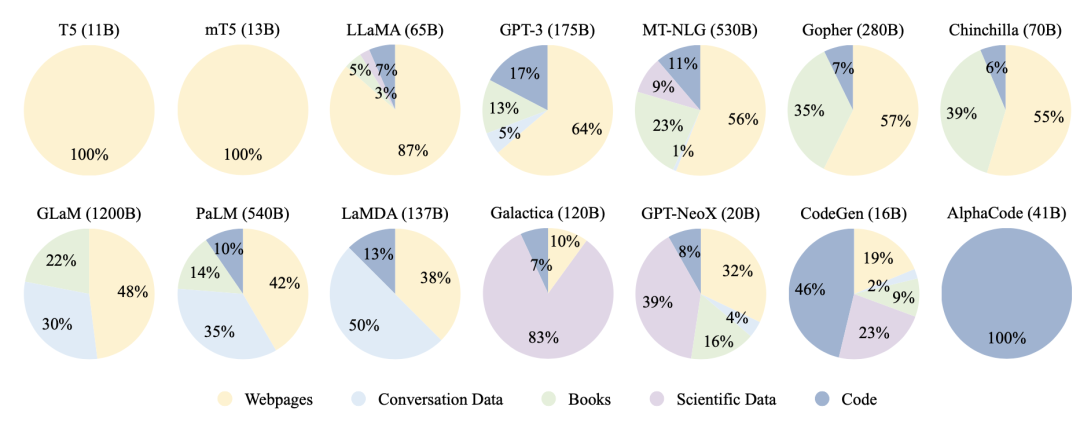
一般性语料中,网页语料规模较大,但其中包含Wikipedia等高质量语料的同时,还包含垃圾邮件等低质量语料,一般需要过滤处理。问答语料,如Reddit等社交媒体平台,可以潜在地提高模型回答问题的能力。社交媒体通常涉及多人对话,对话语料可以根据回复关系整理成树状结构,从而每一条支路都是一段完整的对话内容。书籍语料是少有的书面语长文本,可以帮助模型学习严谨的语言学知识,建模长距离依赖,提高生成内容的连贯性。
特殊语料中,多语言语料可以提升模型在翻译,多语言摘要、问答等任务上的能力。科技语料通过获取arXiv论文、教科书、数学网络社区等内容,可以帮助模型理解特殊符号、术语和表达式,提高模型在科技任务与推理上的表现。代码语料主要来自Stack Exchange等问答社区以及GitHub上的开源项目,包含代码、注释和文档。最近研究表明,代码语料可以提升模型复杂推理的能力(chain-of-thought),因其具有的长距离依赖以及内在精密的逻辑。
目前一些开源的语料的获取地址,可以参考我们以前的推送:训练ChatGPT的必备资源:语料、模型和代码库完全指南。
清洗与预处理
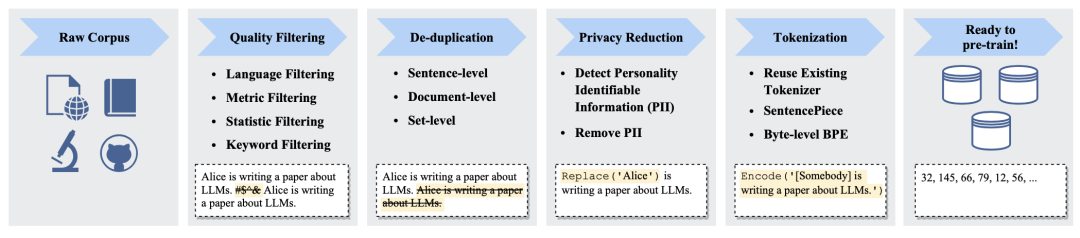
得到语料之后,一般人们通过上图的流程来清洗、预处理语料,提升质量。
具体而言,在第一步的语料清洗中,可以利用Wikipedia等样本作为正例训练一个二分类器筛选高质量语料。不过最近的研究表明,这一筛选方式可能带来偏见。所以现在更推荐使用启发式规则来筛选,比如剔除非目标任务语言、丢弃低perplexity数据、删去标点/符号过多或过长过短的句子、删除具有某些特定词汇(如html标签、链接、脏话、敏感词)的句子。
第二步是去重。包含大量重复词汇或短语的句子可以删掉;重复率(词/n-grams共现)过高的段落可以删掉;删除训练集中可能与测试集相关度过高的内容。这样可以提高训练集质量,缓解语言模型生成内容重复的问题,避免测试集泄露带来的过拟合问题。
第三步是通过关键词等方式剔除用户隐私信息(姓名、地址、电话等)
最后,三步清洗完毕,就可以上分词、准备训练了。分词方面,并没有什么黑科技。要么直接使用GPT-2等现成的分词器,要么对训练语料构建基于SentencePiece、Byte Pair Encoding等算法的分词方式。
一些注意细节
大模型的特点,导致在处理预训练语料时,需要注意一些特殊的细节:
-
需要调节不同来源的语料的混合比例,不能直接基于语料规模。均衡的语料比例有助于提高模型的泛化能力,特定类型的语料可以提升模型特定的能力。
-
语料规模要与模型的参数规模相配合。经验表明,给定算力,语料的token数与模型的参数个数相当时,模型的表现相对更好。所以不要一味地追求大语料,控制规模、提高质量、训练充分,也很重要。
-
语料质量很重要(再次强调)。实验表明,大模型训练时,低质量的语料不用都比用了好。过多的重复数据甚至会让训练过程失效(崩溃或陷入无意义的局部最优)。
模型结构与任务
主流的大规模语言模型都是基于Transformers结构。从下图中可以看出,绝大多数模型均基于Casual decoder结构,即仅使用解码器(单向注意力遮掩)处理输入和输出内容。小编猜测是因为GPT-3展现了Casual decoder很强的能力之后,结合上该结构上的scaling law等研究,人们已经丧失了调研其他结构的兴趣。
另外两种大语言模型的结构,Encoder-decoder结构和最初做机器翻译的模型类似,采用两个不共享参数上的组件分别处理输入和输出内容。而Prefix decoder 和 Casual decoder很像,但是在输入部分内不采用单向注意力遮掩,而允许双向注意力。有点像是共享参数的Encoder-decoder结构。
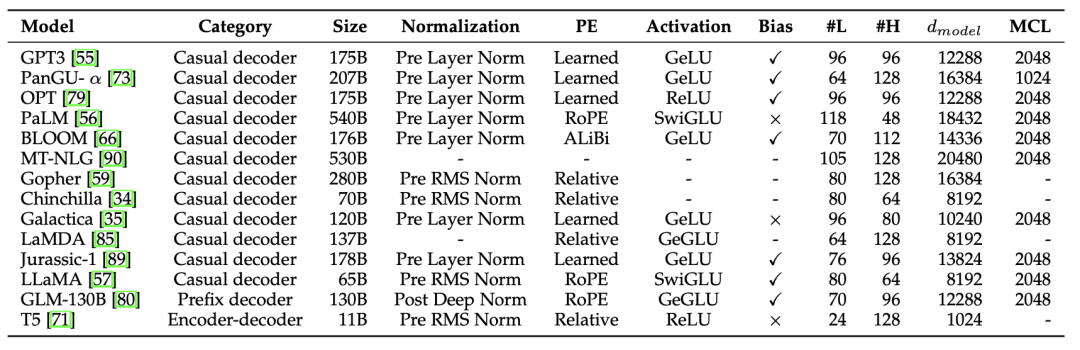
除了Transformer的结构选取。上表还展示一些模型设计细节。具体包括以下几点:
-
Layer Normalization(层归一化)是确保模型收敛,缓解训练崩溃问题的重要手段。具体而言,经典的Pre Norm在每个多头注意力层与前馈网络层前加层归一化。Pre RMS Norm在Pre Norm的基础上,去掉了归一化中的均值部分,即仅就标准差做尺度缩放,让优化过程更平滑,是现在的主流推荐方法。此外,在Embedding后加Norm,虽然会让优化更平滑,但却会明显降低模型表现,所以现在一般不再使用。
-
激活函数方面,传统的ReLU一般是不够看的。现在认为,SwiGLU 和 GeGLU 可以带来更好的表现,但相对于GeLU等激活函数而言,会带来更多的参数。
-
位置信息编码,传统的有习得的绝对位置编码(Learned)与针对相对距离的相对位置编码(Relative)。后者针对测试时的更长语料时具有更好的外推性。最近,RoPE使用较为广泛,特点在于使用类似于核函数、三角旋转的方式,给query和key向量带上绝对位置编码,从而使得其内积中带有表达相对位置信息的项。
除此之外,上表中还汇总了部分超参数信息,如#L层数、#H头数、隐层规模、MCL最大上下文长度。
相较模型结构细节,预训练任务上的设计就很朴实无华了。最常见的预训练任务就是自回归语言模型,让语言模型逐一地根据输入历史预测下一个词,广泛地被GPT-3等语言模型所采纳。而像T5 和 GLM-130B 引入了降噪自编码训练目标,让模型还原输入内容中被遮掩的语段。
优化设置与技巧
大规模语言模型为了使训练过程更加高效、平稳,在训练过程中还有一系列的“黑科技”。具体而言,这些技巧可以:1、提升模型最终表现;2、提升模型收敛速度;3、避免模型收敛到loss很高的局部最优,或者不收敛;4、避免训练过程崩溃。现有的大模型公开的优化设置与技巧如下表所示。
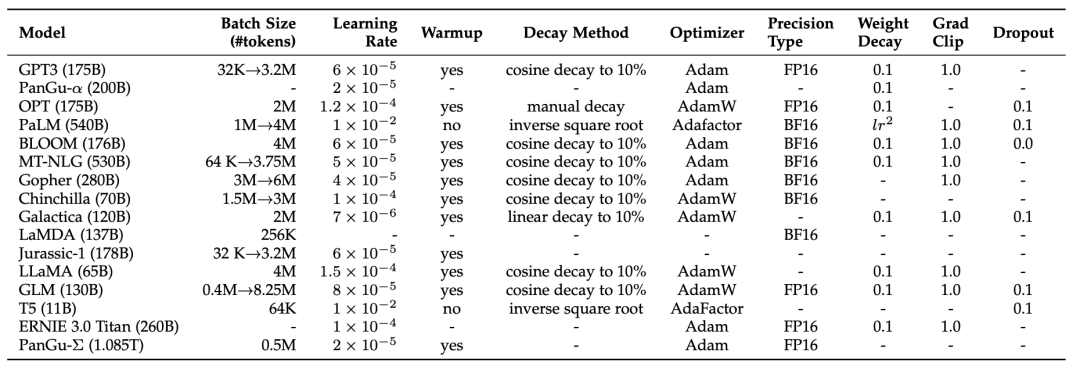
batch-size一般设置较大,为了更好地利用大规模训练数据,让模型训练过程更加稳定。比如使用8196的batch-size(每个batch处理1.6M个token输入)。GPT-3使用动态调整Batch-size的方式,使其处理的Token数从32K逐渐增大到3.2M。
学习率 一般较小,且包含warm up设置,以确保训练平稳。比如在前0.1%~0.5%的训练步骤中,设置一个线性的学习率递增。峰值学习率一般在 以下,比如GPT-3的学习率是。之后,会采用cosine decay strategy,逐渐减小学习率,在收敛前将学习率再下降10%左右。
优化器一般采用Adam、AdamW、以及Adafactor。其中,Adafactor是Adam的一个节约显存的变体。
其它稳定训练过程的技巧包括梯度裁剪(gradient clipping),以1.0为阈值;weight decay(类似于L2正则)率为0.1。即使如此,大模型的训练过程依然经常崩溃。PaLM 和 OPT 提出,在发生崩溃时可以从之前的一个中间节点开始继续训练,并且跳过之前那段导致崩溃的训练数据。GLM 发现embedding层经常有异常梯度,需要适当调整。
数据并行(Data parallelism) 是最常用的一种多卡训练方式。将训练数据分配到多块显卡上,分别计算前向和反向传播之后,再汇总梯度,更新参数,同步模型。该方法可以解决单卡batch过小的问题。
流水线并行(Pipeline parallelism) 在一块显卡上只存储、计算一些相邻的层。为了缓解时序操作等待带来的低效问题,GPipe 和 PipeDream 等工具提出在流水线中集合多个batch的数据,并异步更新参数。该方法可以缓解单卡跑不动batch-size为1的情况。
张量并行(Tensor parallelism) 对大矩阵乘法运算:中的A矩阵做拆分,从而使该运算转化成两个较小的矩阵的乘法结果的拼接:,而两个较小的矩阵乘法可以放在两块显卡上进行。该方法被 Megatron-LM、Colossal-AI等工具实现,可以缓解单一大矩阵乘法显存占用过高的问题,同时也会带来一定的通讯成本。
混合精度训练 使用半精度浮点计算来代替训练过程的部分参数(特别是前向传播部分),从而起到降低显存提升速度的作用。A100等显卡对半精度浮点计算做了优化,从而使混合精度训练更加有效。最近也有提出用Brain Floating Point (BF16)取代传统的FP16,增加指数位,减少有效数字。不过,虽然混合精度计算提速明显,但经验表明还是会降低准确度与模型表现。
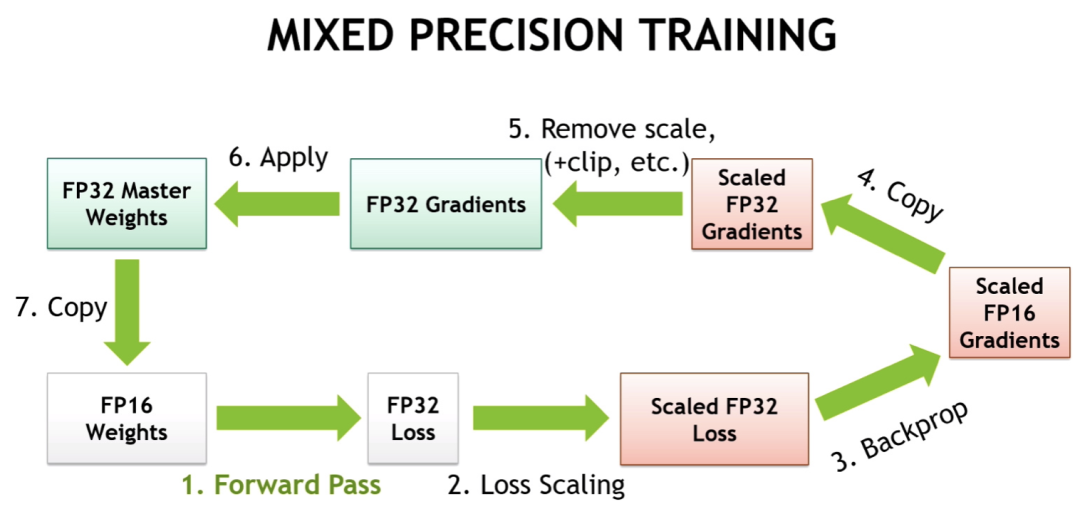
ZeRO 是DeepSpeed提出进一步优化数据并行的一个方案,用于提高模型参数之外的显存空间并行性。上图的混合精度计算流程就非常明显,有大量参数之外的储存资源消耗。事实上,1.5B参数的半精度GPT-2储存空间只有3GB,却无法在32GB的显卡上训练,就是这个原因。ZeRO主要思想包括,将梯度、动量等更新相关的信息也分布式地储存在每块卡上,这样汇总更新时每块卡分别更新对应位置的参数再同步即可;在更新梯度后释放梯度相关的显存等。由于该方法比较复杂,我们这里就不详述了。PyTorch的DeepSpeed和FSDP工具均支持ZeRO。
在实际使用中,上述优化设置通常组合使用。比如BLOOM模型的384块A100采用了8路数据并行,4路张量并行和12路流水线并行,并采用了基于BF16的混合精度训练策略。DeepSpeed, Colossal-AI,Alpa 等开源工具支持并行相关的功能。
除此之外,为了减少试错成本,GPT-4还提出了predictable scaling,通过较小的神经网络模型来预测大模型设置的可能表现。PyTorch的FSDP还支持让CPU分担部分计算压力。
结束语
大规模语言模型的训练已经不仅仅是一个科学问题,同时也是一个复杂的工程问题。科学家和工程师们必须携手合作,才能有效推动大模型的发展。各种训练技巧有助于提高大模型的训练效率和稳定性。然而,相关的工程细节仅通过论文只能了解皮毛。真正深入掌握,还需要仔细阅读开源项目代码并尝试运行。
后台回复关键词【入群】
加入卖萌屋NLP、CV、搜推广与求职讨论群