相关文章:
- 数据挖掘领域十大经典算法之—C4.5算法(超详细附代码)
- 数据挖掘领域十大经典算法之—K-Means算法(超详细附代码)
- 数据挖掘领域十大经典算法之—SVM算法(超详细附代码)
- 数据挖掘领域十大经典算法之—Apriori算法
- 数据挖掘领域十大经典算法之—EM算法
- 数据挖掘领域十大经典算法之—PageRank算法
- 数据挖掘领域十大经典算法之—K-邻近算法/kNN(超详细附代码)
- 数据挖掘领域十大经典算法之—朴素贝叶斯算法(超详细附代码)
- 数据挖掘领域十大经典算法之—CART算法(超详细附代码)
简介
Adaboost算法是一种提升方法,将多个弱分类器,组合成强分类器。
AdaBoost,是英文”Adaptive Boosting“(自适应增强)的缩写,由Yoav Freund和Robert Schapire在1995年提出。
它的自适应在于:前一个弱分类器分错的样本的权值(样本对应的权值)会得到加强,权值更新后的样本再次被用来训练下一个新的弱分类器。在每轮训练中,用总体(样本总体)训练新的弱分类器,产生新的样本权值、该弱分类器的话语权,一直迭代直到达到预定的错误率或达到指定的最大迭代次数。
总体——样本——个体三者间的关系需要搞清除
总体N。样本:{ni}i从1到M。个体:如n1=(1,2),样本n1中有两个个体。
算法原理
(1)初始化训练数据(每个样本)的权值分布:如果有N个样本,则每一个训练的样本点最开始时都被赋予相同的权重:1/N。
(2)训练弱分类器。具体训练过程中,如果某个样本已经被准确地分类,那么在构造下一个训练集中,它的权重就被降低;相反,如果某个样本点没有被准确地分类,那么它的权重就得到提高。同时,得到弱分类器对应的话语权。然后,更新权值后的样本集被用于训练下一个分类器,整个训练过程如此迭代地进行下去。
(3)将各个训练得到的弱分类器组合成强分类器。各个弱分类器的训练过程结束后,分类误差率小的弱分类器的话语权较大,其在最终的分类函数中起着较大的决定作用,而分类误差率大的弱分类器的话语权较小,其在最终的分类函数中起着较小的决定作用。换言之,误差率低的弱分类器在最终分类器中占的比例较大,反之较小。
算法流程
第一步:
初始化训练数据(每个样本)的权值分布。每一个训练样本,初始化时赋予同样的权值w=1/N。N为样本总数。
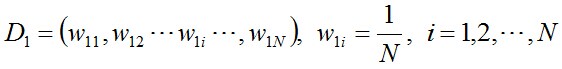
D1表示,第一次迭代每个样本的权值。w11表示,第1次迭代时的第一个样本的权值。
N为样本总数。
第二步:进行多次迭代,m=1,2….M。m表示迭代次数。
a)使用具有权值分布Dm(m=1,2,3…N)的训练样本集进行学习,得到弱的分类器。
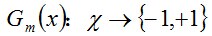
该式子表示,第m次迭代时的弱分类器,将样本x要么分类成-1,要么分类成1.那么根据什么准则得到弱分类器?
准则:该弱分类器的误差函数最小,也就是分错的样本对应的 权值之和,最小。
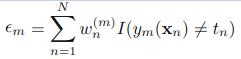
b)计算弱分类器Gm(x)的话语权,话语权am表示Gm(x)在最终分类器中的重要程度。其中em,为上步中的εm(误差函数的值)
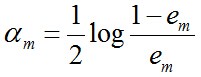
该式是随em减小而增大。即误差率小的分类器,在最终分类器的 重要程度大。
c)更新训练样本集的权值分布。用于下一轮迭代。其中,被误分的样本的权值会增大,被正确分的权值减小。
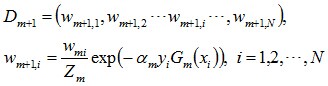
Dm+1是用于下次迭代时样本的权值,Wm+1,i是下一次迭代时,第i个样本的权值。
其中,yi代表第i个样本对应的类别(1或-1),Gm(xi)表示弱分类器对样本xi的分类(1或-1)。若果分对,yi*Gm(xi)的值为1,反之为-1。其中Zm是归一化因子,使得所有样本对应的权值之和为1.
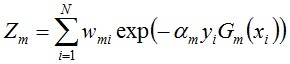
该公式并不难,仔细看看、想想。
第三步迭代完成后,组合弱分类器。
首先,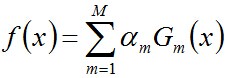
然后,加个sign函数,该函数用于求数值的正负。数值大于0,为1。小于0,为-1.等于0,为0.得到最终的强分类器G(x)
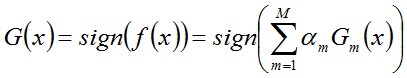
*额外(关于权值、话语权、弱分类器准则的公式,想深入了解的可以看看。使用的话,知道上面的内容已经足够)
利用前向分布加法模型(简单说,就是把一起求n个问题,转化为每次求1个问题,再其基础上,求下一个问题,如此迭代n次),adaboost算法可以看成,求式子的最小。tn时样本n对应的正确分类,fm是前m个分类器的结合(这里乘了1/2,因为博主看的文章的am是1/2*log(~~),这个无所谓,无非是多个1/2少个1/2。
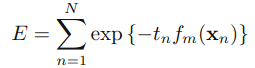
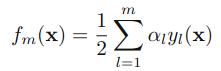
然后,假设前m-1个相关的参数已经确定。通过化简E这个式子,我们可以得到:
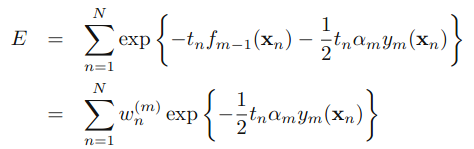
其中,是一个常量。
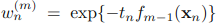
然后,
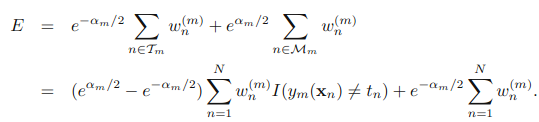
其中,Tm是分类正确的样本的权值,Mm是分类错误的样本的权值。式子不算难,自己多看几遍就能理解了。
到现在,可以看出,最小化E,其实就是最小化
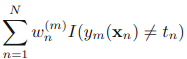
这个式子是什么?看看前面,这个就是找弱分类器时的准则!
然后得到了弱分类器ym后,我们可以进推导出am和样本的权值。这里给出am的推导过程(手写的,字很烂)其中,ε是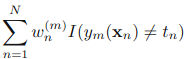
该图中,最右边的是“+exp(-am/2)*1”,写得太乱(—_—)

最后求出来的am没有1/2,这个无所谓。因为这里定义fm是多乘了个1/2。
优点
(1)精度很高的分类器
(2)提供的是框架,可以使用各种方法构建弱分类器
(3)简单,不需要做特征筛选
(4)不用担心过度拟合
实际应用
(1)用于二分类或多分类
(2)特征选择
(3)分类人物的baseline
代码
代码已在github上实现,这里也贴出来
# encoding=utf-8import pandas as pd
import timefrom sklearn.cross_validation import train_test_split
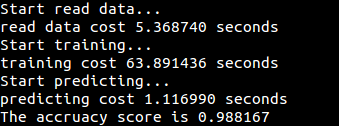
from sklearn.metrics import accuracy_scorefrom sklearn.ensemble import AdaBoostClassifierif __name__ == '__main__':print("Start read data...")time_1 = time.time()raw_data = pd.read_csv('../data/train_binary.csv', header=0) data = raw_data.valuesfeatures = data[::, 1::]labels = data[::, 0]# 随机选取33%数据作为测试集,剩余为训练集train_features, test_features, train_labels, test_labels = train_test_split(features, labels, test_size=0.33, random_state=0)time_2 = time.time()print('read data cost %f seconds' % (time_2 - time_1))print('Start training...') # n_estimators表示要组合的弱分类器个数;# algorithm可选{‘SAMME’, ‘SAMME.R’},默认为‘SAMME.R’,表示使用的是real boosting算法,‘SAMME’表示使用的是discrete boosting算法clf = AdaBoostClassifier(n_estimators=100,algorithm='SAMME.R')clf.fit(train_features,train_labels)time_3 = time.time()print('training cost %f seconds' % (time_3 - time_2))print('Start predicting...')test_predict = clf.predict(test_features)time_4 = time.time()print('predicting cost %f seconds' % (time_4 - time_3))score = accuracy_score(test_labels, test_predict)
print("The accruacy score is %f" % score)测试数据集为经过二分类处理后的MNIST数据集,获取地址train_binary.csv
运行结果