目录
一、介绍
二、安装
三、inflxudb保留字
四、基本语法
1、客户端操作
1. 数据库操作
2. 数据表和数据操作
3. series 操作
4.Shard
5. 用户操作
2、API操作
状态码
3、Java操作
五、常用函数
六、存储策略
1.查看策略
2.创建策略
3、修改策略
4. 删除
七、目录与文件结构
八、数据备份
1、备份和恢复DB数据
一、DB备份
二、DB恢复
二、备份和恢复元数据
1、备份元数据
2、恢复元数据
一、介绍
InfluxDB 是一个时间序列数据库,GO 编写的,旨在处理高写入和查询负载。InfluxDB 旨在用作涉及大量时间戳数据的任何用例的后备存储,包括 DevOps 监控、应用程序指标、物联网传感器数据和实时分析。
特点:
- 专门为时间序列数据编写的自定义高性能数据存储。TSM 引擎允许高速摄取和数据压缩
- 完全用 Go 编写。它编译成一个没有外部依赖性的二进制文件。
- 简单、高性能的写入和查询 HTTP API。
- 插件支持其他数据摄取协议,例如 Graphite、collectd 和 OpenTSDB。
- 专为轻松查询聚合数据而定制的类似 SQL 的表达查询语言。
- 标签允许为系列建立索引以实现快速高效的查询。
- 保留策略有效地自动使陈旧数据过期。
- 连续查询自动计算聚合数据,使频繁查询更高效。
InfluxDB有三大特性:
Time Series (时间序列):你可以使用与时间有关的相关函数(如最大,最小,求和等)
Metrics(度量):你可以实时对大量数据进行计算
Eevents(事件):它支持任意的事件数据
InfluxDB 提供三种操作方式:
- 客户端命令行方式
- HTTP API 接口
- 各语言 API 库
InfluxDB 和传统数据库(如:MySQL)区别:
| InfluxDB | 传统数据库中的概念 |
|---|---|
| database | 数据库 |
| measurement | 数据库中的表 |
| points | 每个表里某个时刻的某个条件下的一个 field 的数据,因为体现在图表上就是一个点,于是将其称为 point。Point 由时间戳(time)、数据(field)、标签(tags)组成 |
| series | 序列,所有在数据库中的数据,都需要通过图表来展示,而这个 series 表示这个表里面的数据,可以在图表上画成几条线。具体可以通过 SHOW SERIES FROM "表名" 进行查询 |
| Retention policy | 数据保留策略,可以定义数据保留的时长,每个数据库可以有多个数据保留策略,但只能有一个默认策略 |
注意:point由3部分组成time+fields+tags。
| Point 属性 | 传统数据库中的概念 |
|---|---|
| time | 每行记录都有一列time,主索引,记录时间戳,单位纳秒,时区UTC(东八区减8小时) |
| fields | 普通列,key-value结构,value数据类型支持型(float、integer、string、boolean) |
| tags | 索引列,key-value结构,value数据类型只支持string |
说明:
- 在插入新数据时,tag、field 和 time之间用空格分隔 。
- fields和tags key名称严格区分大小写。
fields数据类型:
| 类型 | 备注 |
| float | influxdb的fields默认是float浮点型 |
| integer | 整型,insert语句如需写入field是整型,需在数值后面加个i |
| string | 字符串,insert语句如需写入field是字符串,需英文双引号包含数值 |
| boolean | 布尔型,真可以用 t , T , true , True , TRUE表示;假可以用 f , F , false , False 或者 FALSE表示 |
注意
在influxdb中,字段必须存在。因为字段是没有索引的。如果使用字段作为查询条件,会扫描符合查询条件的所有字段值,性能不及tag。tags是可选的,但是强烈建议你用上它,因为tag是有索引的,tags相当于SQL中的有索引的列。tag value只能是string类型。
端口
- 8083:Web admin 管理服务的端口, http://localhost:8083
- 8086:HTTP API 的端口
- 8088:集群端口 (目前还不是很清楚, 配置在全局的 bind-address,默认不配置就是开启的)
二、安装
docker pull influxdb:1.8.3 docker run -d -p 18083:8083 -p 18088:8088 -p 18086:8086 --name my_influxdb influxdb:1.8.3 docker container update --restart=always my_influxdb
可视化工具:
1、web界面
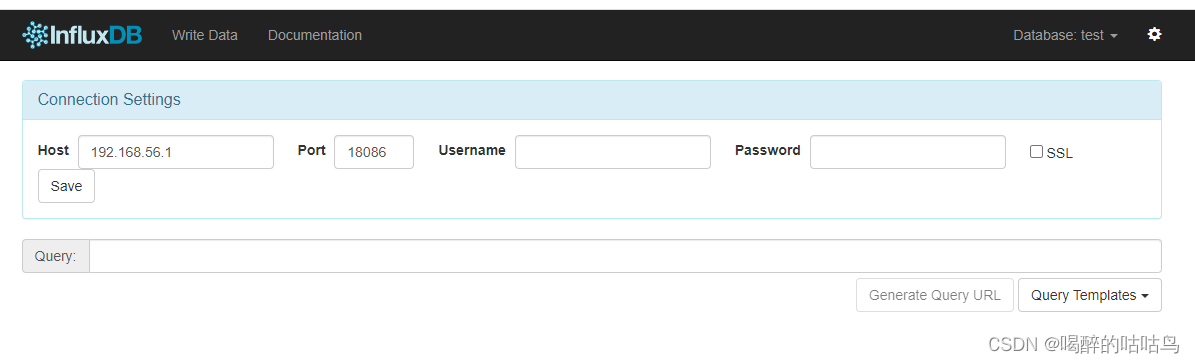
2、influxDB Studio
客户端为绿色版,下载解压打开即可。
下载地址:Releases · CymaticLabs/InfluxDBStudio
案例数据:
curl https://s3.amazonaws.com/noaa.water-database/NOAA_data.txt -o NOAA_data.txt
导入数据:
influx -import -path=NOAA_data.txt -precision=s -database=NOAA_water_database
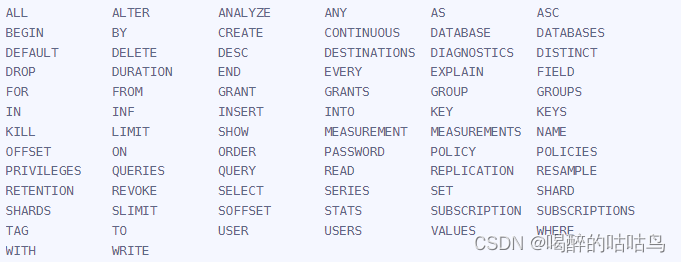
三、inflxudb保留字
四、基本语法
docker exec -it my_influxdb bash
cd /etc/influxdb/
influx
1、客户端操作
1. 数据库操作
# 查看所有数据库
show databases;
# 建库
create database dbname;
# 删库
drop database daname
# 切换使用数据库
use dbname
2. 数据表和数据操作
查看所有表
show measurements
数据中的时间字段默认显示的是一个纳秒时间戳,改成可读格式。时间默认是UTC时间
precision rfc3339; # 之后再查询,时间就是rfc3339标准格式
# 或可以在连接数据库的时候,直接带该参数
influx -precision rfc3339
查看一个measurement中所有的tag key
show tag keys
查看一个measurement中所有的field key
show field keys
查看一个measurement中所有的保存策略(可以有多个,一个标识为default)
show retention policies;
插入数据
标准格式,注意在写数据的时候如果不添加时间戳,系统会默认添加一个时间。InfluxDB 中没有显式的新建表的语句,只能通过 insert 数据的方式来建立新表。
insert <measurement>[,<tag-key>=<tag-value>...] <field-key>=<field-value>[,<field2-key>=<field2-value>...] [unix-nano-timestamp]insert 表名,tags fileds;
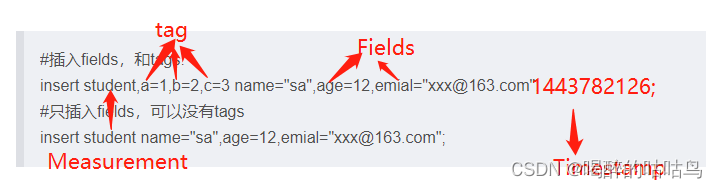
#插入fields,和tags.
insert student,a=1,b=2,c=3 name="sa",age=12,emial="xxx@163.com";
#只插入fields,可以没有tags
insert student name="sa",age=12,emial="xxx@163.com";
删表
drop measurement student
查询
SELECT field keys [time | tag kyes | * ] FROM measurements WHERE conditions GROUP BY [tag keys | time] ORDER BY time [asc | desc] LIMIT number [OFFSET number]
- SELECT后面查询显示字段必须至少有一个field key,否则会抛异常ERR: at least 1 non-time field must be queried。还可显示tag keys、time,或者*显示所有字段。
- FROM查询数据来源一个或者多个measurement。
- WHERE查询条件可为tag keys和time,field keys 也可作为查询条件但是不常用,因为不是索引,查询效率比较低。tag keys条件操作符支持=、!=、<>、正则,field keys支持=、!=、<>、>、>=、<、<=、正则。
- GROUP BY只能对tag keys和time进行合分组,可以多字段排序,如group by tag1,tag2,time,也可一个*对所有的tag进行分组聚合(不包括time)。
- ORDER BY只能对time进行排序,asc升序,desc降序。
- LIMIT分页,LIMIT后面的数字是查询显示多少条,OFFSET后面数字代表偏移量(从0开始代表第一条),如limit 10 offset 10意思为从第11条开始往后10条。
正则
#每个表输出一行(支持 Go 语言的正则表达式、支持类似于 MySQL 中的 limit 语句)
SELECT * FROM /.*/ LIMIT 1
limit
limit可单独使用,也可配合offset使用,offset偏移量的意思
select * from student limit 2;
排序
order by 只能对time进行排序,asc升序,desc降序。
select * from student order by time desc;
分组
SELECT <function>(<field_key>) FROM_clause WHERE <time_range> GROUP BY time(time_interval,[<offset_interval])[,tag_key] [fill(<fill_option>)]
(1)group by tag
select * from h2o_pH group by location limit 2
(2)group by time(1m)
对time分组时并不是简单的group by time,time后面还需要加一个分组聚合的持续时间,如group by time(1m)。支持的持续时间单位有:
(3)fill(0)填充null
可以看到values结果集中有null的情况,可在查询语句中加fill(0),遇到null用0来填充。fill()中只能填数字。
条件查询
select * from student where a='1' and age=12; # a字段是tag :字符串
select sum(age) as ageNums from student where time < now() group by a order by time desc;
格式化显示查询数据
format json
select * from student where a='1' and age=12;
模糊查询(正则表达式)
# location名称中包含coyote的数据
select * from h2o_quality where location=~/.*coyote.*/ limit 10
没有in还有or
select * from h2o_pH where location='coyote_creek' or location='santa_monica' limit 4

from多表查询
多表查询,以时间进行连接,不存在的值用null填充。一般情况连接的两张表tag和field上有一定的联系和比较,毫不相干的两表连接查询没什么价值。
select * from h2o_feet,h2o_pH limit 1
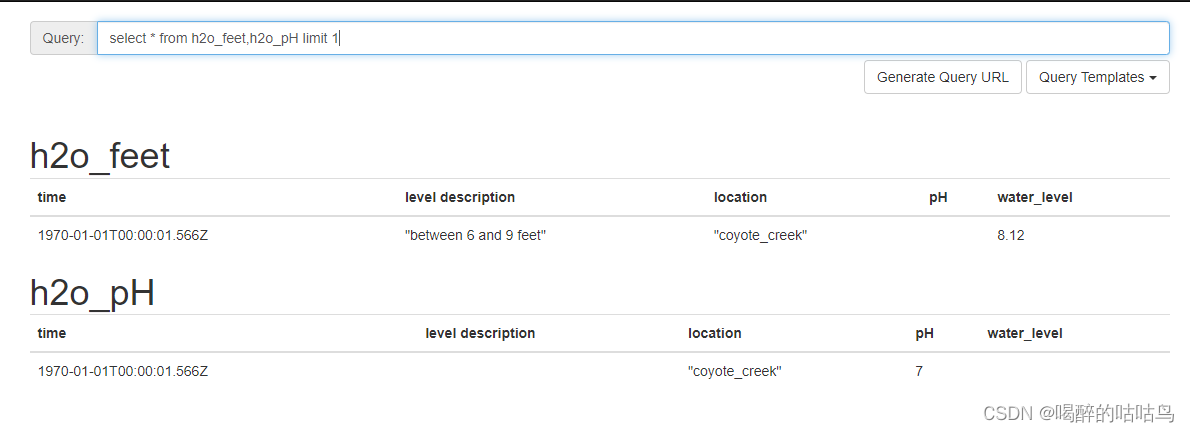
注意:
1.field tag是关键字 如果字段名是这两个,则需要加上单引号。
2.tags之间用逗号分隔,fields之间用逗号分隔,tags和fields之间用空格分隔。
3.tags都是字符串类型,但是不用双引号括起来;fields中有字符串类型需要用英文双引号括起来,如果不用英文双引号,会报语法错误invalid boolean,会认为是无效的布尔值,因为布尔类型无需加双引号。
4.tags中设置布尔值就是字符串,fields中有布尔值,可用 t , T , true , True , TRUE,f , F , false , False表示。
3. series 操作
series 相当于是 InfluxDB 中一些数据的集合,在同一个 database 中,retention policy、measurement、tag sets 完全相同的数据同属于一个 series,同一个 series 的数据在物理上会按照时间顺序排列存储在一起。
shard主要由4部分组成Cache、Wal、Tsm file、Compactor。
#series 表示这个表里面的数据,可以在图表上画成几条线,series 主要通过 tags 排列组合算出来。
show series from student;
4.Shard
shard 在 InfluxDB 中是一个比较重要的概念,它和 retention policy 相关联。每一个存储策略下会存在许多 shard,每一个 shard 存储一个指定时间段内的数据,并且不重复,例如 7点-8点 的数据落入 shard0 中,8点-9点的数据则落入 shard1 中。每一个 shard 都对应一个底层的 tsm 存储引擎,有独立的 cache、wal、tsm file。
如果创建一个新的 retention policy 设置数据的保留时间为 1 天,则单个 shard 所存储数据的时间间隔为 1 小时,超过1个小时的数据会被存放到下一个 shard 中。
5. 用户操作
# 显示用户
SHOW USERS
# 创建用户
CREATE USER "username" WITH PASSWORD 'password'
# 创建管理员权限的用户#influxdb 的权限设置比较简单,只有读、写、ALL 几种。
CREATE USER "username" WITH PASSWORD 'password' WITH ALL PRIVILEGES
# 删除用户
DROP USER "username"
2、API操作
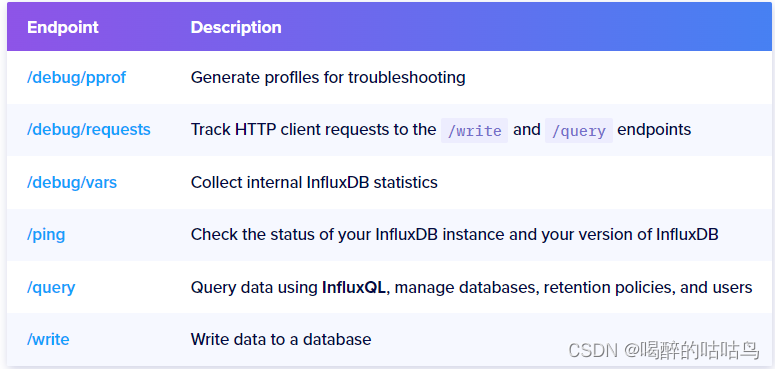
状态码
- 2xx:服务请求正常
- 4xx:代表请求语法有问题
- 5xx:服务端出问题,导致超时等故障
官方地址
3、Java操作
<dependency><groupId>org.influxdb</groupId><artifactId>influxdb-java</artifactId><version>2.23</version>
</dependency>spring:application:name: spring-lean-influxdbinflux:url: http://192.168.56.22:18086user:password:database: testimport lombok.Data;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Configuration;
@Data
@Configuration
public class InfluxDBConfig {@Value("${spring.influx.user}")public String userName;@Value("${spring.influx.password}")public String password;@Value("${spring.influx.url}")public String url;//数据库@Value("${spring.influx.database}")public String database;
}import lombok.Builder;
import lombok.Data;
import org.influxdb.annotation.Column;
import org.influxdb.annotation.Measurement;
import org.influxdb.annotation.TimeColumn;import java.util.Date;@Builder
@Data
@Measurement(name = "t_log")
public class LogInfo {// Column中的name为measurement中的列名// 此外,需要注意InfluxDB中时间戳均是以UTC时保存,在保存以及提取过程中需要注意时区转换@Column(name = "time")private String time;// 注解中添加tag = true,表示当前字段内容为tag内容@Column(name = "module", tag = true)private String module;@Column(name = "level", tag = true)private String level;@Column(name = "device_id", tag = true)private String deviceId;@Column(name = "msg")private String msg;@TimeColumnprivate Date createTime;
}import com.lean.influxdb.config.InfluxDBConfig;
import org.influxdb.InfluxDB;
import org.influxdb.InfluxDBFactory;
import org.influxdb.dto.BatchPoints;
import org.influxdb.dto.Point;
import org.influxdb.dto.Query;
import org.influxdb.dto.QueryResult;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import org.springframework.util.StringUtils;import javax.annotation.PostConstruct;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.concurrent.TimeUnit;@Service
public class InfluxDBService {@Autowiredprivate InfluxDBConfig influxDBConfig;@PostConstructpublic void initInfluxDb() {this.retentionPolicy = retentionPolicy == null || "".equals(retentionPolicy) ? "autogen" : retentionPolicy;this.influxDB = influxDbBuild();}//保留策略private String retentionPolicy;private InfluxDB influxDB;/*** 连接时序数据库;获得InfluxDB**/private InfluxDB influxDbBuild() {if (influxDB == null) {if(StringUtils.isEmpty(influxDBConfig.userName)){influxDB = InfluxDBFactory.connect(influxDBConfig.url);}else {influxDB = InfluxDBFactory.connect(influxDBConfig.url, influxDBConfig.userName, influxDBConfig.password);}influxDB.setDatabase(influxDBConfig.database);}return influxDB;}/*** 插入*/public void insertPoint(Point point) {influxDbBuild();influxDB.write(point);}/*** 插入** @param measurement 表* @param tags 标签* @param fields 字段*/public void insert(String measurement, Map<String, String> tags, Map<String, Object> fields) {influxDbBuild();Point.Builder builder = Point.measurement(measurement);builder.time(System.currentTimeMillis(), TimeUnit.MILLISECONDS);builder.tag(tags);builder.fields(fields);influxDB.write(influxDBConfig.database, "", builder.build());}/*** @param measurement* @param time* @param tags* @param fields* @return void* @desc 插入, 带时间time*/public void insert(String measurement, long time, Map<String, String> tags, Map<String, Object> fields) {influxDbBuild();Point.Builder builder = Point.measurement(measurement);builder.time(time, TimeUnit.MILLISECONDS);builder.tag(tags);builder.fields(fields);influxDB.write(influxDBConfig.database, "", builder.build());}/*** 查询** @param command 查询语句* @return*/public QueryResult query(String command) {influxDbBuild();return influxDB.query(new Query(command, influxDBConfig.database));}/*** @param queryResult* @desc 查询结果处理*/public List<Map<String, Object>> queryResultProcess(QueryResult queryResult) {List<Map<String, Object>> mapList = new ArrayList<>();List<QueryResult.Result> resultList = queryResult.getResults();//把查询出的结果集转换成对应的实体对象,聚合成listfor (QueryResult.Result query : resultList) {List<QueryResult.Series> seriesList = query.getSeries();if (seriesList != null && seriesList.size() != 0) {for (QueryResult.Series series : seriesList) {List<String> columns = series.getColumns();String[] keys = columns.toArray(new String[columns.size()]);List<List<Object>> values = series.getValues();if (values != null && values.size() != 0) {for (List<Object> value : values) {Map<String, Object> map = new HashMap(keys.length);for (int i = 0; i < keys.length; i++) {map.put(keys[i], value.get(i));}mapList.add(map);}}}}}return mapList;}/*** @desc InfluxDB 查询 count总条数*/public long countResultProcess(QueryResult queryResult) {long count = 0;List<Map<String, Object>> list = queryResultProcess(queryResult);if (list != null && list.size() != 0) {Map<String, Object> map = list.get(0);double num = (Double) map.get("count");count = new Double(num).longValue();}return count;}/*** 创建数据库* @param dbName 创建数据库* @return*/public void createDB(String dbName) {influxDbBuild();influxDB.createDatabase(dbName);}/*** 批量写入测点* @param batchPoints*/public void batchInsert(BatchPoints batchPoints) {influxDbBuild();influxDB.write(batchPoints);}/*** 批量写入数据** @param database 数据库* @param retentionPolicy 保存策略* @param consistency 一致性* @param records 要保存的数据(调用BatchPoints.lineProtocol()可得到一条record)*/public void batchInsert(final String database, final String retentionPolicy,final InfluxDB.ConsistencyLevel consistency, final List<String> records) {influxDbBuild();influxDB.write(database, retentionPolicy, consistency, records);}/*** @param consistency* @param records* @desc 批量写入数据*/public void batchInsert(final InfluxDB.ConsistencyLevel consistency, final List<String> records) {influxDbBuild();influxDB.write(influxDBConfig.database, "", consistency, records);}}
import com.lean.influxdb.entity.LogInfo;
import com.lean.influxdb.service.InfluxDBService;
import org.influxdb.dto.Point;
import org.influxdb.dto.QueryResult;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;import java.util.Date;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.concurrent.TimeUnit;@SpringBootTest
class SpringLeanInfluxdbApplicationTests {@Testvoid contextLoads() {}@Autowiredprivate InfluxDBService influxDBService;@Testpublic void test() {LogInfo logInfo = LogInfo.builder().level("1").module("log").deviceId("1").msg("消息").createTime(new Date()).build();Point point = Point.measurementByPOJO(logInfo.getClass()).addFieldsFromPOJO(logInfo).time(System.currentTimeMillis(), TimeUnit.MILLISECONDS).build();influxDBService.insertPoint(point);}@Testpublic void test1() {Integer pageSize = 15;Integer pageNum = 1;// InfluxDB支持分页查询,因此可以设置分页查询条件String pageQuery = " LIMIT " + pageSize + " OFFSET " + ((pageNum - 1) * pageSize);// 此处查询所有内容,如果String queryCmd = "SELECT * FROM student ORDER BY time DESC " + pageQuery;QueryResult queryResult = influxDBService.query(queryCmd);List<Map<String, Object>> maps = influxDBService.queryResultProcess(queryResult);maps.stream().forEach(s->{s.forEach((k,v)->{System.out.printf("k",k);System.out.printf("v",v);});});List<QueryResult.Result> resultList = queryResult.getResults();System.out.println(resultList);}@Testpublic void testSave() {String measurement = "student";Map<String, String> tags = new HashMap<>();tags.put("code", "1");tags.put("studentNums", "1");Map<String, Object> fields = new HashMap<>();fields.put("name", "张三");fields.put("age", "11");influxDBService.insert(measurement, tags, fields);}@Testpublic void testGetdata() {String command = "select * from student";QueryResult queryResult = influxDBService.query(command);List<Map<String, Object>> result = influxDBService.queryResultProcess(queryResult);for (Map map : result) {System.out.println("time:" + map.get("time")+ " code:" + map.get("code")+ " studentNums:" + map.get("studentNums")+ " name:" + map.get("name")+ " age:" + map.get("age"));}}}
五、常用函数
| Aggregations | Selectors | Transformations |
|---|---|---|
| COUNT() | BOTTOM() | CEILING() |
| DISTINCT() | FIRST() | DERIVATIVE() |
| INTEGRAL() | LAST() | DIFFERENCE() |
| MEAN() | MAX() | ELAPSED() |
| MEDIAN() | MIN() | FLOOR() |
| SPREAD() | PERCENTILE() | HISTOGRAM() |
| SUM() | TOP() | MOVING_AVERAGE() |
| NON_NEGATIVE_DERIVATIVE() | ||
| STDDEV() |
更多查看官网:地址
六、存储策略
InfluxDB 每秒可以处理成千上万条数据,要将这些数据全部保存下来会占用大量的存储空间,有时需要自动清理历史数据。
1.查看策略
一个database可以有多个保留策略retention policy,但是只能有一个默认retention policy。
show retention policies on databaseName
2.创建策略
数据库新建都会分配一个默认的保留策略:

- name,保留策略的名称。
- duration,数据保留的持续时长,最小为1h。如果设置为0,数据永久保存(官方默认RP),否则过期清理。它具有各种时间参数,比如:h(小时),w(星期)
- shardGroupDuration,数据存储在shardGroup的时间跨度。shardGroup是influxdb的一个逻辑存储结构,其下包含多个shard。
- replicaN,全称replication,复制因子,它决定在集群中存储多少个数据副本。inflxudb集群中跨N个数据节点复制数据,其中N就是复制因子。复制因子对单个节点实例不起作用,单机版默认是1。
- default,true为默认保留策略。
基本语法:
CREATE RETENTION POLICY <retention_policy_name> ON <database_name> DURATION <duration> REPLICATION <n> [SHARD DURATION <duration>] [DEFAULT]
- retention_policy_name: 策略名。
- database_name: 数据库名(db必须存在)。
- duration: 数据保留时长。
- REPLICATION: 复制因子,单机版设置为1即可。
- SHARD DURATION:设置shardGroupDuration时长,表示每个shard group时间跨度时长。可不填,默认根据RP的duration计算。
- default: true为设置该RP为默认RP。
CREATE RETENTION POLICY "策略名称" ON "表名称" DURATION 30d REPLICATION 1 DEFAULT
3、修改策略
ALTER RETENTION POLICY "策略名称" ON "表名称" DURATION 3w DEFAULT
4. 删除
DROP RETENTION POLICY "策略名称" ON "表名称"
七、目录与文件结构
InfluxDB 的数据存储主要有三个目录。默认情况下是 meta, wal 以及 data 三个目录。
- meta 用于存储数据库的一些元数据,meta 目录下有一个 meta.db 文件。
- wal 目录存放预写日志文件,以 .wal 结尾。
- data 目录存放实际存储的数据文件,以 .tsm 结尾。
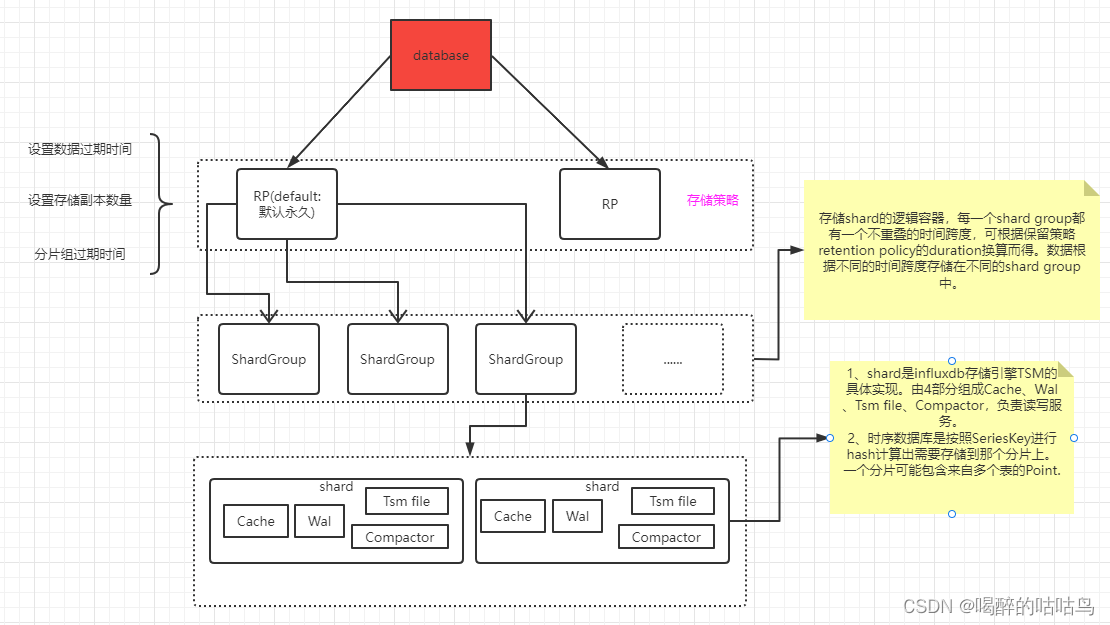
shard:
influxdb存储引擎TSM的具体实现。TSM TREE是专门为influxdb构建的数据存储格式。与现有的B+ tree或LSM tree实现相比,TSM tree具有更好的压缩和更高的读写吞吐量。主要由4部分组成Cache、Wal、Tsm file、Compactor。
shard group:
存储shard的逻辑容器,每一个shard group都有一个不重叠的时间跨度,可根据保留策略retention policy的duration换算而得。数据根据不同的时间跨度存储在不同的shard group中。
cache :
在内存中是一个简单的 map 结构,这里的 key 为 seriesKey + 分隔符 + filedName,目前代码中的分隔符为 #!~#,entry 相当于是一个按照时间排序的存放实际值的数组。
插入数据时,实际上是同时往 cache 与 wal 中写入数据,可以认为 cache 是 wal 文件中的数据在内存中的缓存。当 InfluxDB启动时,会遍历所有的 wal 文件,重新构造 cache,这样即使系统出现故障,也不会导致数据的丢失。
wal:
对数据的修改以日志的形式持久化存储在磁盘上。
内容与内存中的 cache 相同,其作用就是为了持久化数据,当系统崩溃后可以通过 wal 文件恢复还没有写入到 tsm 文件中的数据。
文件中的一条数据,对应的是一个 key(measument + tags + fieldName) 下的所有 value 数据,按照时间排序。
tsm file:
真实存放数据的文件,单个 tsm file 大小最大为 2GB。每隔一段时间,内存中的时序数据就会执行flush操作将数据写入到文件。
compactor:
在后台持续运行,每隔 1 秒会检查一次是否有需要压缩合并的数据。主要进行两种操作,一种是 cache 中的数据大小达到阀值后,进行快照,之后转存到一个新的 tsm 文件中。另外一种就是合并当前的 tsm 文件,将多个小的 tsm 文件合并成一个,使每一个文件尽量达到单个文件的最大大小,减少文件的数量,并且一些数据的删除操作也是在这个时候完成。
数据存储
LSM-Tree VS B-Tree
八、数据备份
两种备份方式:1.db备份 2.元数据备份。元数据备份的备份是整个备份,不能拆分,而db数据的备份,完整的、增量的(从 RFC3339 格式的时间开始),或者针对特定的分片 ID。
1、备份和恢复DB数据
一、DB备份
基本语法:
通过influxd backup -h查看backup有哪些可选参数。
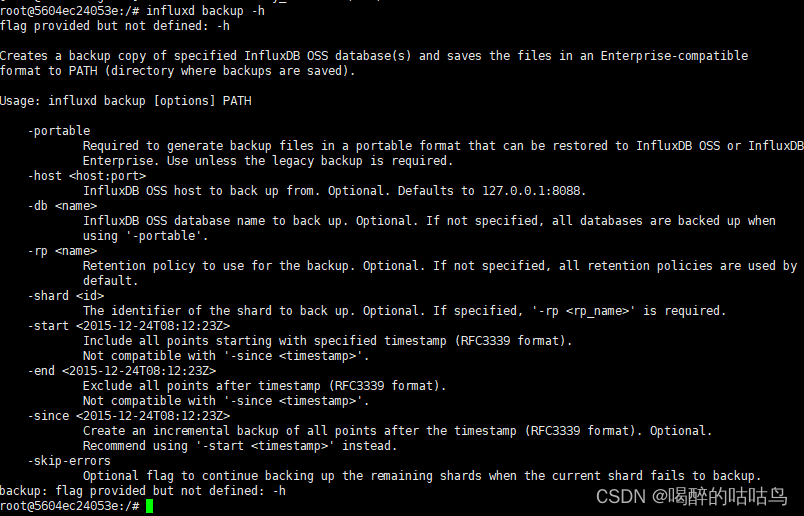
Usage: influxd backup [options] PATH
-portable: 默认
-host <host:port> # 需要备份的influxdb服务机器地址,可选,Defaults to 127.0.0.1:8088.
-database <name> # 需要备份的db名称,可选,若没有指定,将备份所有数据库
-retention <name> # 备份某个保留策略的数据,未指定,则备份所有rp的数据。
-shard <id> # 需要备份的shard id,可选,若指定了备份shard,必须先选择rp
-start # 起始时间,日期必须采用 RFC3339格式(例如, 2015-12-24T08:12:23Z). 不能和-since一起使用
-end # 结束时间,日期必须采用 RFC3339格式(例如, 2015-12-24T08:12:23Z) 不能和-since一起使用
-since # 备份这个timestamp之后的数据,建议用-start <timestamp>代替
-skip-errors # 可选,当备份shards时,跳过备份失败的shard,继续备份其他shard。
influxd backup -database <mydatabase> <path-to-backup>
mydatabase是您要备份的数据库的名称,以及path-to-backup备份数据应该存储的位置。
注意: Metastore 备份也包含在每个数据库的备份中
案例:
1.备份所有数据库
influxd backup -portable /path/to/backup-directory
2.备份school库的所有数据。
influxd backup -portable -db school ~/tmp/influx_backup/

3.备份school 库昨天的数据。
influxd backup -portable -db school -start 2022-11-14T13:24:52.085243953Z -end 2020-11-15T13:24:52.085243953Z ~/tmp/influx_backup_yesterday/
4.只备份school 的shard=2的数据
influxd backup -portable -db school -shard 2 ~/tmp/influx_backup_2/
5.远程备份(所有数据库)
influxd backup -portable -host 1192.168.56.11:8088 /path/to/backup-directory
二、DB恢复
使用该influxd restore实用程序将时间序列数据和元数据从 InfluxDB 备份还原到 InfluxDB。
influxd restore -h查看restore可选参数:
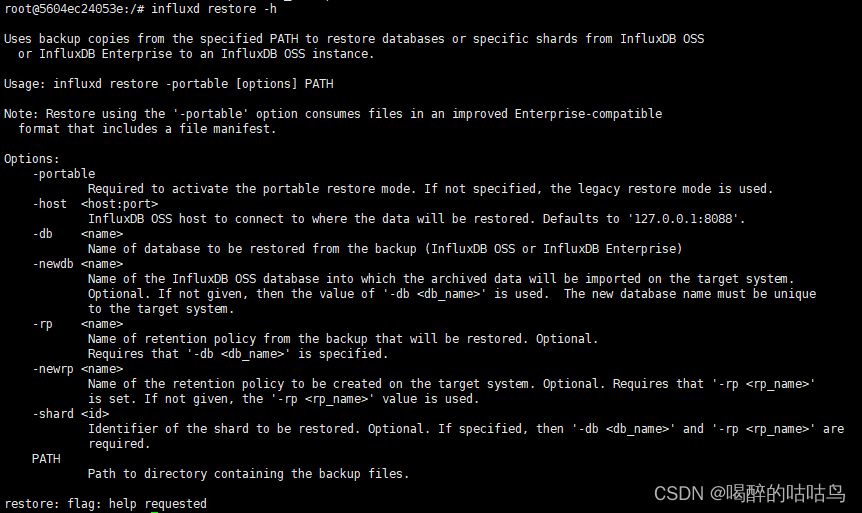
Usage: influxd restore -portable [options] PATH
Note: Restore using the '-portable' option consumes files in an improved Enterprise-compatible
format that includes a file manifest.Options:
-portable
-host <host:port>
-db <name>
从备份数据的哪个库恢复数据
-newdb <name>
数据恢复到新库名称,若没有指定,选择-db <name>的名称。
newdb不存在,恢复时会自动创建
-rp <name>
从备份数据的哪个rp恢复数据,指定了-rp,必须指定-db
-newrp <name>
恢复数据新的rp名称,newrp必须存在。指定了-rp,未指定-newrp则使用-rp
-shard <id>
需要恢复的shard,如果指定了'-db <db_name>' and '-rp <rp_name>',必须-shard<id>
PATH
备份数据文件list
案例:
1.恢复~/tmp/influx_backup/下school库数据到新库new_school。
influxd restore -portable -db school -newdb new_school ~/tmp/influx_backup/
![]()
2.恢复~/tmp/influx_backup/下school库,rp为rp_3数据到新库new_school1。
influxd restore -portable -db school -rp rp_3 -newdb new_school1 ~/tmp/influx_backup/
3.恢复~/tmp/influx_backup/下school库,rp为rp_3,shard为2的数据到新库new_school2,并重命名rp的名称为rp_3days。
influxd restore -portable -db school -rp rp_3 -shard 2 -newdb new_school2 -newrp rp_3days ~/tmp/influx_backup/
注意:

二、备份和恢复元数据
1、备份元数据
influxd backup <path-to-backup>
备份元数据,没有任何其他参数,备份将只转移当前状态的系统元数据到path-to-backup。path-to-backup为备份保存的目录,不存在会自动创建。
influxd backup tmp/mata_backup

2、恢复元数据
基本语法:
influxd restore -metadir <path-to-meta-or-data-directory> <path-to-backup>
参考来源:
influxdb官方英文文档
influxdb中文文档
https://segmentfault.com/a/1190000012385313