Quartz定时任务框架学习
- 什么是Quartz
- Quartz依赖引入
- 使用 Quartz
- Quartz API,Jobs和Triggers
- Job 和 Trigger
- 为什么既有 Job,又有 Trigger 呢?
- Key
- Job与JobDetail介绍
- 为什么设计成JobDetail + Job,不直接使用Job
- JobDataMap
- Job实例
- Job状态与并发
- Job的其它特性
- JobExecutionException
- Quartz中Triggers介绍
- Trigger的公共属性
- 优先级(priority)
- 错过触发(misfire Instructions)
- 日历示例(calendar)
- Simple Trigger
- SimpleTrigger Misfire策略
- CronTrigger
- 构建CronTriggers
- CronTrigger Misfire说明
- 错过触发机制
- TriggerListeners和JobListeners
- 使用自己的Listeners
- 添加对特定job感兴趣的JobListener:
- SchedulerListeners
- Scheduler
- Job Stores
- 为什么需要持久化?
- Quartz初始化表
- 参考文章
什么是Quartz
Quartz是OpenSymphony开源组织在Job scheduling领域又一个开源项目,完全由Java开发,可以用来执行定时任务,类似于java.util.Timer。但是相较于Timer, Quartz增加了很多功能:
- 持久性作业 - 就是保持调度定时的状态;
- 作业管理 - 对调度作业进行有效的管理;
大部分公司都会用到定时任务这个功能。
拿火车票购票来说,当你下单后,后台就会插入一条待支付的task(job),一般是30分钟,超过30min后就会执行这个job,去判断你是否支付,未支付就会取消此次订单;当你支付完成之后,后台拿到支付回调后就会再插入一条待消费的task(job),Job触发日期为火车票上的出发日期,超过这个时间就会执行这个job,判断是否使用等。
在我们实际的项目中,当Job过多的时候,肯定不能人工去操作,这时候就需要一个任务调度框架,帮我们自动去执行这些程序。那么该如何实现这个功能呢?
1.首先我们需要定义实现一个定时功能的接口,我们可以称之为Task(或Job),如定时发送邮件的task(Job),重启机器的task(Job),优惠券到期发送短信提醒的task(Job),实现接口如下:

2.有了任务之后,还需要一个能够实现触发任务去执行的触发器,触发器Trigger最基本的功能是指定Job的执行时间,执行间隔,运行次数等

3.有了Job和Trigger后,怎么样将两者结合起来呢?即怎样指定Trigger去执行指定的Job呢?这时需要一个Schedule,来负责这个功能的实现。

上面三个部分就是Quartz的基本组成部分:
- 调度器:Scheduler
- 任务:JobDetail
- 触发器:Trigger,包括SimpleTrigger和CronTrigger
Quartz依赖引入
<dependency><groupId>org.quartz-scheduler</groupId><artifactId>quartz</artifactId><version>2.3.0</version>
</dependency>
使用 Quartz
在你使用调度器之前,需要借助一些具体的例子去理解它。你可以使用 SchedulerFactory 类来达到程序调度的目的。有一些 Quartz 框架的用户可能会将 Factory 的实例存储在 JND I中,其他人为了便于举例子就直接使用 Factory 的实例。
一旦调度器实例化后,它就能够启动,等待执行和关闭。需要注意的是一旦调度器调用 了shutdown 方法关闭后,如果不重新实例化,它就不会启动了。触发器在调度器未启动时,或是终止状态时,都不会被触发。
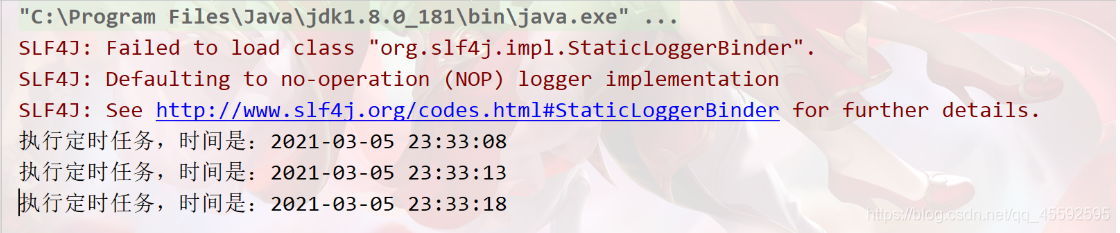
quartz 的简单事例:
package job;import org.quartz.Job;
import org.quartz.JobExecutionContext;
import org.quartz.JobExecutionException;
import org.quartz.SchedulerException;import java.time.LocalDateTime;public class HelloJob implements Job {@Overridepublic void execute(JobExecutionContext context) throws JobExecutionException {Object tv1 = context.getTrigger().getJobDataMap().get("t1");Object tv2 = context.getTrigger().getJobDataMap().get("t2");Object jv1 = context.getJobDetail().getJobDataMap().get("j1");Object jv2 = context.getJobDetail().getJobDataMap().get("j2");Object sv = null;try {sv = context.getScheduler().getContext().get("skey");} catch (SchedulerException e) {e.printStackTrace();}System.out.println(tv1+":"+tv2);System.out.println(jv1+":"+jv2);System.out.println(sv);System.out.println("hello:"+ LocalDateTime.now());}}
import job.HelloJob;
import org.quartz.*;
import org.quartz.impl.StdSchedulerFactory;public class Test {public static void main(String[] args) throws SchedulerException {//创建一个schedulerScheduler scheduler = StdSchedulerFactory.getDefaultScheduler();scheduler.getContext().put("skey", "svalue");//创建一个TriggerTrigger trigger = TriggerBuilder.newTrigger().withIdentity("trigger1", "group1").usingJobData("t1", "tv1").withSchedule(SimpleScheduleBuilder.simpleSchedule().withIntervalInSeconds(3).repeatForever()).build();trigger.getJobDataMap().put("t2", "tv2");//创建一个jobJobDetail job = JobBuilder.newJob(HelloJob.class).usingJobData("j1", "jv1").withIdentity("myjob", "mygroup").build();job.getJobDataMap().put("j2", "jv2");//注册trigger并启动schedulerscheduler.scheduleJob(job,trigger);scheduler.start();}}

定时任务每隔三秒执行一次
Quartz API,Jobs和Triggers
Quartz API的关键接口是:
- Scheduler - 与调度程序交互的主要API。
- Job - 你想要调度器执行的任务组件需要实现的接口
- JobDetail - 用于定义作业的实例。
- Trigger(即触发器) - 定义执行给定作业的计划的组件。
- JobBuilder - 用于定义/构建 JobDetail 实例,用于定义作业的实例。
- TriggerBuilder - 用于定义/构建触发器实例。
- Scheduler 的生命期,从 SchedulerFactory 创建它时开始,到 Scheduler 调用shutdown()方法时结束;Scheduler 被创建后,可以增加、删除和列举 Job 和 Trigger,以及执行其它与调度相关的操作(如暂停Trigger)。但是,Scheduler 只有在调用 start() 方法后,才会真正地触发 trigger(即执行job)。
Quartz 提供的“builder”类,可以认为是一种领域特定语言(DSL,Domain Specific Language)
// define the job and tie it to our HelloJob class
JobDetail job = newJob(HelloJob.class).withIdentity("myJob", "group1") // name "myJob", group "group1".build();// Trigger the job to run now, and then every 40 seconds
Trigger trigger = newTrigger().withIdentity("myTrigger", "group1").startNow().withSchedule(simpleSchedule().withIntervalInSeconds(40).repeatForever()) .build();// Tell quartz to schedule the job using our trigger
sched.scheduleJob(job, trigger);
DSL 的静态导入可以通过以下导入语句来实现:
import static org.quartz.JobBuilder.*;
import static org.quartz.SimpleScheduleBuilder.*;
import static org.quartz.CronScheduleBuilder.*;
import static org.quartz.CalendarIntervalScheduleBuilder.*;
import static org.quartz.TriggerBuilder.*;
import static org.quartz.DateBuilder.*;
SchedulerBuilder 接口的各种实现类,可以定义不同类型的调度计划 (schedule);
DateBuilder 类包含很多方法,可以很方便地构造表示不同时间点的 java.util.Date 实例(如定义下一个小时为偶数的时间点,如果当前时间为 9:43:27,则定义的时间为10:00:00)。
Job 和 Trigger
一个 job 就是一个实现了 Job 接口的类,该接口只有一个方法:
public interface Job {public void execute(JobExecutionContext context)throws JobExecutionException;}
- job的一个 trigger 被触发后(稍后会讲到),execute() 方法会被 scheduler 的一个工作线程调用;
- 传递给 execute() 方法的 JobExecutionContext 对象中保存着该 job 运行时的一些信息 ,执行job 的 scheduler 的引用,触发 job 的 trigger 的引用,JobDetail 对象引用,以及一些其它信息。
- JobDetail 对象是在将 job 加入 scheduler 时,由客户端程序(你的程序)创建的。它包含 job的各种属性设置,以及用于存储 job 实例状态信息的 JobDataMap。
- Trigger 用于触发 Job 的执行。当你准备调度一个 job 时,你创建一个 Trigger 的实例,然后设置调度相关的属性。Trigger 也有一个相关联的 JobDataMap,用于给 Job 传递一些触发相关的参数。Quartz 自带了各种不同类型的 Trigger,最常用的主要是 SimpleTrigger 和 CronTrigger。
- SimpleTrigger 主要用于一次性执行的 Job(只在某个特定的时间点执行一次),或者 Job 在特定的时间点执行,重复执行 N 次,每次执行间隔T个时间单位。CronTrigger 在基于日历的调度上非常有用,如“每个星期五的正午”,或者“每月的第十天的上午 10:15”等。
为什么既有 Job,又有 Trigger 呢?
很多任务调度器并不区分 Job 和 Trigger。
有些调度器只是简单地通过一个执行时间和一些 job 标识符来定义一个 Job;
其它的一些调度器将 Quartz 的 Job 和 Trigger 对象合二为一。
将任务的调度和被调度的任务分离,有很多好处,如下:
例如,Job 被创建后,可以保存在 Scheduler 中,与 Trigger 是独立的,同一个 Job可以有多个 Trigger;这种松耦合的另一个好处是,当与 Scheduler 中的 Job 关联的 trigger 都过期时,可以配置 Job 稍后被重新调度,而不用重新定义 Job;还有,可以修改或者替换 Trigger,而不用重新定义与之关联的 Job。
Key
将 Job 和 Trigger 注册到 Scheduler 时,可以为它们设置 key,配置其身份属性。
Job 和 Trigger 的 key(JobKey 和 TriggerKey)可以用于将 Job 和 Trigger 放到不同的分组(group)里,然后基于分组进行操作。
同一个分组下的 Job 或 Trigger 的名称必须唯一,即一个 Job 或 Trigger 的 key 由名称(name)和分组(group)组成
Job与JobDetail介绍
你定义了一个实现Job接口的类,这个类仅仅表明该job需要完成什么类型的任务,除此之外,Quartz还需要知道该Job实例所包含的属性;这将由JobDetail类来完成。
JobDetail实例是通过JobBuilder类创建的,导入该类下的所有静态方法,会让你编码时有DSL的感觉:
import static org.quartz.JobBuilder.*;
让我们先看看Job的特征(nature)以及Job实例的生命期。
// define the job and tie it to our HelloJob classJobDetail job = newJob(HelloJob.class).withIdentity("myJob", "group1") // name "myJob", group "group1".build();// Trigger the job to run now, and then every 40 secondsTrigger trigger = newTrigger().withIdentity("myTrigger", "group1").startNow().withSchedule(simpleSchedule().withIntervalInSeconds(40).repeatForever()) .build();// Tell quartz to schedule the job using our triggersched.scheduleJob(job, trigger);
现在考虑这样定义的作业类“HelloJob”:
public class HelloJob implements Job {public HelloJob() {}public void execute(JobExecutionContext context)throws JobExecutionException{System.err.println("Hello! HelloJob is executing.");}}
可以看到,我们传给scheduler一个JobDetail实例,因为我们在创建JobDetail时,将要执行的job的类名传给了JobDetail,所以scheduler就知道了要执行何种类型的job;
每次当scheduler执行job时,在调用其execute(…)方法之前会创建该类的一个新的实例;
执行完毕,对该实例的引用就被丢弃了,实例会被垃圾回收;这种执行策略带来的一个后果是,job必须有一个无参的构造函数(当使用默认的JobFactory时);另一个后果是,在job类中,不应该定义有状态的数据属性,因为在job的多次执行中,这些属性的值不会保留。
那么如何给job实例增加属性或配置呢?如何在job的多次执行中,跟踪job的状态呢?答案就是:JobDataMap,JobDetail对象的一部分。
为什么设计成JobDetail + Job,不直接使用Job
JobDetail绑定指定的Job,每次Scheduler调度执行一个Job的时候,首先会拿到对应的Job,然后创建该Job实例,再去执行Job中的execute()的内容,任务执行结束后,关联的Job对象实例会被释放,且会被JVM GC清除。
为什么设计成JobDetail + Job,不直接使用Job
JobDetail定义的是任务数据,而真正的执行逻辑是在Job中。
这是因为任务是有可能并发执行,如果Scheduler直接使用Job,就会存在对同一个Job实例并发访问的问题。而JobDetail & Job 方式,Sheduler每次执行,都会根据JobDetail创建一个新的Job实例,这样就可以规避并发访问的问题。
JobDataMap
JobDataMap中可以包含不限量的(序列化的)数据对象,在job实例执行的时候,可以使用其中的数据;
JobDataMap是Java Map接口的一个实现,额外增加了一些便于存取基本类型的数据的方法。
将job加入到scheduler之前,在构建JobDetail时,可以将数据放入JobDataMap,如下示例:
// define the job and tie it to our DumbJob classJobDetail job = newJob(DumbJob.class).withIdentity("myJob", "group1") // name "myJob", group "group1".usingJobData("jobSays", "Hello World!").usingJobData("myFloatValue", 3.141f).build();
在job的执行过程中,可以从JobDataMap中取出数据,如下示例:
public class DumbJob implements Job {public DumbJob() {}public void execute(JobExecutionContext context)throws JobExecutionException{JobKey key = context.getJobDetail().getKey();JobDataMap dataMap = context.getJobDetail().getJobDataMap();String jobSays = dataMap.getString("jobSays");float myFloatValue = dataMap.getFloat("myFloatValue");System.err.println("Instance " + key + " of DumbJob says: " + jobSays + ", and val is: " + myFloatValue);}}
如果你使用的是持久化的存储机制(本教程的JobStore部分会讲到),在决定JobDataMap中存放什么数据的时候需要小心,因为JobDataMap中存储的对象都会被序列化,因此很可能会导致类的版本不一致的问题;
Java的标准类型都很安全,如果你已经有了一个类的序列化后的实例,某个时候,别人修改了该类的定义,此时你需要确保对类的修改没有破坏兼容性;
更多细节,参考现实中的序列化问题。另外,你也可以配置JDBC-JobStore和JobDataMap,使得map中仅允许存储基本类型和String类型的数据,这样可以避免后续的序列化问题。
如果你在job类中,为JobDataMap中存储的数据的key增加set方法(如在上面示例中,增加setJobSays(String val)方法),那么Quartz的默认JobFactory实现在job被实例化的时候会自动调用这些set方法,这样你就不需要在execute()方法中显式地从map中取数据了。
在Job执行时,JobExecutionContext中的JobDataMap为我们提供了很多的便利。
它是JobDetail中的JobDataMap和Trigger中JobDataMap的并集,但是如果存在相同的数据,则后者会覆盖前者的值。
下面的示例,在job执行时,从JobExecutionContext中获取合并后的JobDataMap:
public class DumbJob implements Job {public DumbJob() {}public void execute(JobExecutionContext context)throws JobExecutionException{JobKey key = context.getJobDetail().getKey();JobDataMap dataMap = context.getMergedJobDataMap(); // Note the difference from the previous exampleString jobSays = dataMap.getString("jobSays");float myFloatValue = dataMap.getFloat("myFloatValue");ArrayList state = (ArrayList)dataMap.get("myStateData");state.add(new Date());System.err.println("Instance " + key +" of DumbJob says: " + jobSays + ", and val is: " + myFloatValue);}}
如果你希望使用JobFactory实现数据的自动“注入”,则示例代码为:
public class DumbJob implements Job {String jobSays;float myFloatValue;ArrayList state;public DumbJob() {}public void execute(JobExecutionContext context)throws JobExecutionException{JobKey key = context.getJobDetail().getKey();JobDataMap dataMap = context.getMergedJobDataMap(); // Note the difference from the previous examplestate.add(new Date());System.err.println("Instance " + key + " of DumbJob says: " + jobSays + ", and val is: " + myFloatValue);}public void setJobSays(String jobSays) {this.jobSays = jobSays;}public void setMyFloatValue(float myFloatValue) {myFloatValue = myFloatValue;}public void setState(ArrayList state) {state = state;}}
你也许发现,整体上看代码更多了,但是execute()方法中的代码更简洁了。而且,虽然代码更多了,但如果你的IDE可以自动生成setter方法,你就不需要写代码调用相应的方法从JobDataMap中获取数据了,所以你实际需要编写的代码更少了。当前,如何选择,由你决定。
Job实例
很多用户对于Job实例到底由什么构成感到很迷惑。我们在这里解释一下,并在接下来的小节介绍job状态和并发。
你可以只创建一个job类,然后创建多个与该job关联的JobDetail实例,每一个实例都有自己的属性集和JobDataMap,最后,将所有的实例都加到scheduler中。
比如,你创建了一个实现Job接口的类“SalesReportJob”。
该job需要一个参数(通过JobdataMap传入),表示负责该销售报告的销售员的名字。
因此,你可以创建该job的多个实例(JobDetail),比如“SalesReportForJoe”、“SalesReportForMike”,将“joe”和“mike”作为JobDataMap的数据传给对应的job实例。
当一个trigger被触发时,与之关联的JobDetail实例会被加载,JobDetail引用的job类通过配置在Scheduler上的JobFactory进行初始化。
默认的JobFactory实现,仅仅是调用job类的newInstance()方法,然后尝试调用JobDataMap中的key的setter方法。你也可以创建自己的JobFactory实现,比如让你的IOC或DI容器可以创建/初始化job实例。
在Quartz的描述语言中,我们将保存后的JobDetail称为“job定义”或者“JobDetail实例”,将一个正在执行的job称为“job实例”或者“job定义的实例”。
当我们使用“job”时,一般指代的是job定义,或者JobDetail;
当我们提到实现Job接口的类时,通常使用“job类”。
Job状态与并发
关于job的状态数据(即JobDataMap)和并发性,还有一些地方需要注意。在job类上可以加入一些注解,这些注解会影响job的状态和并发性。
@DisallowConcurrentExecution: 禁止并发执行多个相同定义的JobDetail, 这个注解是加在Job类上的, 但意思并不是不能同时执行多个Job, 而是不能并发执行同一个Job Definition(由JobDetail定义), 但是可以同时执行多个不同的JobDetail,
@PersistJobDataAfterExecution:将该注解加在job类上,告诉Quartz在成功执行了job类的execute方法后(没有发生任何异常),更新JobDetail中JobDataMap的数据,使得该job(即JobDetail)在下一次执行的时候,JobDataMap中是更新后的数据,而不是更新前的旧数据.
如果你使用了@PersistJobDataAfterExecution注解,我们强烈建议你同时使用@DisallowConcurrentExecution注解,因为当同一个job(JobDetail)的两个实例被并发执行时,由于竞争,JobDataMap中存储的数据很可能是不确定的。
假设 A任务没3秒执行一次,但执行周期为10秒,就会出现多个任务同时在跑的现象,如果只是查询不进行更新操作的话这个问题不大,但是如果有更新操作就会导致数据并发异常
Quartz 调度任务并发问题
Job的其它特性
通过JobDetail对象,可以给job实例配置的其它属性有:
- Durability:如果一个job是非持久的,当没有活跃的trigger与之关联的时候,会被自动地从scheduler中删除。也就是说,非持久的job的生命期是由trigger的存在与否决定的;
- RequestsRecovery:如果一个job是可恢复的,并且在其执行的时候,scheduler发生硬关闭(hard shutdown)(比如运行的进程崩溃了,或者关机了),则当scheduler重新启动的时候,该job会被重新执行。此时,该job的JobExecutionContext.isRecovering() 返回true。
JobExecutionException
最后,是关于Job.execute(…)方法的一些额外细节。
execute方法中仅允许抛出一种类型的异常(包括RuntimeExceptions),即JobExecutionException。
因此,你应该将execute方法中的所有内容都放到一个”try-catch”块中。
你也应该花点时间看看JobExecutionException的文档,因为你的job可以使用该异常告诉scheduler,你希望如何来处理发生的异常。
Quartz中Triggers介绍
Trigger的公共属性
所有类型的trigger都有TriggerKey这个属性,表示trigger的身份;除此之外,trigger还有很多其它的公共属性。这些属性,在构建trigger的时候可以通过TriggerBuilder设置。
trigger的公共属性有:
- jobKey属性:当trigger触发时被执行的job的身份;
- startTime属性:设置trigger第一次触发的时间;该属性的值是java.util.Date类型,表示某个指定的时间点;有些类型的trigger,会在设置的startTime时立即触发,有些类型的trigger,表示其触发是在startTime之后开始生效。比如,现在是1月份,你设置了一个trigger–“在每个月的第5天执行”,然后你将startTime属性设置为4月1号,则该trigger第一次触发会是在几个月以后了(即4月5号)。
- endTime属性:表示trigger失效的时间点。比如,”每月第5天执行”的trigger,如果其endTime是7月1号,则其最后一次执行时间是6月5号。
优先级(priority)
如果你的trigger很多(或者Quartz线程池的工作线程太少),Quartz可能没有足够的资源同时触发所有的trigger;
这种情况下,你可能希望控制哪些trigger优先使用Quartz的工作线程,要达到该目的,可以在trigger上设置priority属性。
比如,你有N个trigger需要同时触发,但只有Z个工作线程,优先级最高的Z个trigger会被首先触发。
如果没有为trigger设置优先级,trigger使用默认优先级,值为5;
priority属性的值可以是任意整数,正数、负数都可以。
注意:只有同时触发的trigger之间才会比较优先级。10:59触发的trigger总是在11:00触发的trigger之前执行。
注意:如果trigger是可恢复的,在恢复后再调度时,优先级与原trigger是一样的。
错过触发(misfire Instructions)
trigger还有一个重要的属性misfire;
如果scheduler关闭了,或者Quartz线程池中没有可用的线程来执行job,此时持久性的trigger就会错过(miss)其触发时间,即错过触发(misfire)。
不同类型的trigger,有不同的misfire机制。
它们默认都使用“智能机制(smart policy)”,即根据trigger的类型和配置动态调整行为。
当scheduler启动的时候,查询所有错过触发(misfire)的持久性trigger。
然后根据它们各自的misfire机制更新trigger的信息。
当你在项目中使用Quartz时,你应该对各种类型的trigger的misfire机制都比较熟悉,这些misfire机制在JavaDoc中有说明。
关于misfire机制的细节,会在讲到具体的trigger时作介绍。
日历示例(calendar)
Quartz的Calendar对象(不是java.util.Calendar对象)可以在定义和存储trigger的时候与trigger进行关联。
Calendar用于从trigger的调度计划中排除时间段。
比如,可以创建一个trigger,每个工作日的上午9:30执行,然后增加一个Calendar,排除掉所有的商业节日。
任何实现了Calendar接口的可序列化对象都可以作为Calendar对象,Calendar接口如下:
package org.quartz;public interface Calendar {public boolean isTimeIncluded(long timeStamp);public long getNextIncludedTime(long timeStamp);}
注意到这些方法的参数类型为long。你也许猜到了,他们就是毫秒单位的时间戳。即Calendar排除时间段的单位可以精确到毫秒。你也许对“排除一整天”的Calendar比较感兴趣。
Quartz提供的org.quartz.impl.HolidayCalendar类可以很方便地实现。
Calendar必须先实例化,然后通过addCalendar()方法注册到scheduler。
如果使用HolidayCalendar,实例化后,需要调用addExcludedDate(Date date)方法从调度计划中排除时间段。
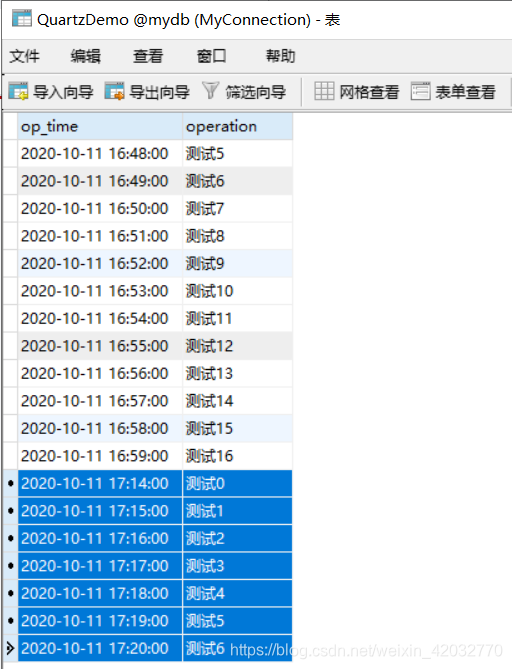
以下示例是将同一个Calendar实例用于多个trigger:
HolidayCalendar cal = new HolidayCalendar();
cal.addExcludedDate( someDate );
cal.addExcludedDate( someOtherDate );sched.addCalendar("myHolidays", cal, false);Trigger t = newTrigger().withIdentity("myTrigger").forJob("myJob").withSchedule(dailyAtHourAndMinute(9, 30)) // execute job daily at 9:30.modifiedByCalendar("myHolidays") // but not on holidays.build();// .. schedule job with triggerTrigger t2 = newTrigger().withIdentity("myTrigger2").forJob("myJob2").withSchedule(dailyAtHourAndMinute(11, 30)) // execute job daily at 11:30.modifiedByCalendar("myHolidays") // but not on holidays.build();// .. schedule job with trigger2
接下来的几个课程将介绍触发器的施工/建造细节。现在,只要认为上面的代码创建了两个触发器,每个触发器都计划每天触发。然而,在日历所排除的期间内发生的任何发射都将被跳过。
Simple Trigger
SimpleTrigger可以满足的调度需求是:在具体的时间点执行一次,或者在具体的时间点执行,并且以指定的间隔重复执行若干次。
比如,你有一个trigger,你可以设置它在2015年1月13日的上午11:23:54准时触发,或者在这个时间点触发,并且每隔2秒触发一次,一共重复5次。
根据描述,你可能已经发现了,SimpleTrigger的属性包括:开始时间、结束时间、重复次数以及重复的间隔。这些属性的含义与你所期望的是一致的,只是关于结束时间有一些地方需要注意。
重复次数,可以是0、正整数,以及常量SimpleTrigger.REPEAT_INDEFINITELY。
重复的间隔,必须是0,或者long型的正数,表示毫秒。
注意,如果重复间隔为0,trigger将会以重复次数并发执行(或者以scheduler可以处理的近似并发数)。
如果你还不熟悉DateBuilder,了解后你会发现使用它可以非常方便地构造基于开始时间(或终止时间)的调度策略。
endTime属性的值会覆盖设置重复次数的属性值;
比如,你可以创建一个trigger,在终止时间之前每隔10秒执行一次,你不需要去计算在开始时间和终止时间之间的重复次数,只需要设置终止时间并将重复次数设置为REPEAT_INDEFINITELY
(当然,你也可以将重复次数设置为一个很大的值,并保证该值比trigger在终止时间之前实际触发的次数要大即可)。
SimpleTrigger实例通过TriggerBuilder设置主要的属性,通过SimpleScheduleBuilder设置与SimpleTrigger相关的属性。要使用这些builder的静态方法,需要静态导入:
import static org.quartz.TriggerBuilder.*;
import static org.quartz.SimpleScheduleBuilder.*;
import static org.quartz.DateBuilder.*:
下面的例子,是基于简单调度(simple schedule)创建的trigger。建议都看一下,因为每个例子都包含一个不同的实现点:
指定时间开始触发,不重复:
SimpleTrigger trigger = (SimpleTrigger) newTrigger() .withIdentity("trigger1", "group1").startAt(myStartTime) // some Date .forJob("job1", "group1") // identify job with name, group strings.build();
指定时间触发,每隔10秒执行一次,重复10次:
trigger = newTrigger().withIdentity("trigger3", "group1").startAt(myTimeToStartFiring) // if a start time is not given (if this line were omitted), "now" is implied.withSchedule(simpleSchedule().withIntervalInSeconds(10).withRepeatCount(10)) // note that 10 repeats will give a total of 11 firings.forJob(myJob) // identify job with handle to its JobDetail itself .build();
5分钟以后开始触发,仅执行一次:
trigger = (SimpleTrigger) newTrigger() .withIdentity("trigger5", "group1").startAt(futureDate(5, IntervalUnit.MINUTE)) // use DateBuilder to create a date in the future.forJob(myJobKey) // identify job with its JobKey.build();
立即触发,每个5分钟执行一次,直到22:00:
trigger = newTrigger().withIdentity("trigger7", "group1").withSchedule(simpleSchedule().withIntervalInMinutes(5).repeatForever()).endAt(dateOf(22, 0, 0)).build();
建立一个触发器,将在下一个小时的整点触发,然后每2小时重复一次:
trigger = newTrigger().withIdentity("trigger8") // because group is not specified, "trigger8" will be in the default group.startAt(evenHourDate(null)) // get the next even-hour (minutes and seconds zero ("00:00")).withSchedule(simpleSchedule().withIntervalInHours(2).repeatForever())// note that in this example, 'forJob(..)' is not called which is valid // if the trigger is passed to the scheduler along with the job .build();scheduler.scheduleJob(trigger, job);
请查阅TriggerBuilder和SimpleScheduleBuilder提供的方法,以便对上述示例中未提到的选项有所了解。
TriggerBuilder(以及Quartz的其它builder)会为那些没有被显式设置的属性选择合理的默认值。
比如:如果你没有调用withIdentity(..)方法,TriggerBuilder会为trigger生成一个随机的名称;
如果没有调用startAt(..)方法,则默认使用当前时间,即trigger立即生效。
SimpleTrigger Misfire策略
SimpleTrigger有几个misfire相关的策略,告诉quartz当misfire发生的时候应该如何处理。
这些策略以常量的形式在SimpleTrigger中定义(JavaDoc中介绍了它们的功能)。这些策略包括:
SimpleTrigger的Misfire策略常量:
MISFIRE_INSTRUCTION_IGNORE_MISFIRE_POLICY
MISFIRE_INSTRUCTION_FIRE_NOW
MISFIRE_INSTRUCTION_RESCHEDULE_NOW_WITH_EXISTING_REPEAT_COUNT
MISFIRE_INSTRUCTION_RESCHEDULE_NOW_WITH_REMAINING_REPEAT_COUNT
MISFIRE_INSTRUCTION_RESCHEDULE_NEXT_WITH_REMAINING_COUNT
MISFIRE_INSTRUCTION_RESCHEDULE_NEXT_WITH_EXISTING_COUNT
回顾一下,所有的trigger都有一个Trigger.MISFIRE_INSTRUCTION_SMART_POLICY策略可以使用,该策略也是所有trigger的默认策略。
如果使用smart policy,SimpleTrigger会根据实例的配置及状态,在所有MISFIRE策略中动态选择一种Misfire策略。
SimpleTrigger.updateAfterMisfire()的JavaDoc中解释了该动态行为的具体细节。
在使用SimpleTrigger构造trigger时,misfire策略作为基本调度(simple schedule)的一部分进行配置(通过SimpleSchedulerBuilder设置):
trigger = newTrigger().withIdentity("trigger7", "group1").withSchedule(simpleSchedule().withIntervalInMinutes(5).repeatForever().withMisfireHandlingInstructionNextWithExistingCount()).build();
CronTrigger
CronTrigger通常比Simple Trigger更有用,如果您需要基于日历的概念而不是按照SimpleTrigger的精确指定间隔进行重新启动的作业启动计划。
使用CronTrigger,您可以指定号时间表,例如“每周五中午”或“每个工作日和上午9:30”,甚至“每周一至周五上午9:00至10点之间每5分钟”和1月份的星期五“。
即使如此,和SimpleT
rigger一样,CronTrigger有一个startTime,它指定何时生效,以及一个(可选的)endTime,用于指定何时停止计划。
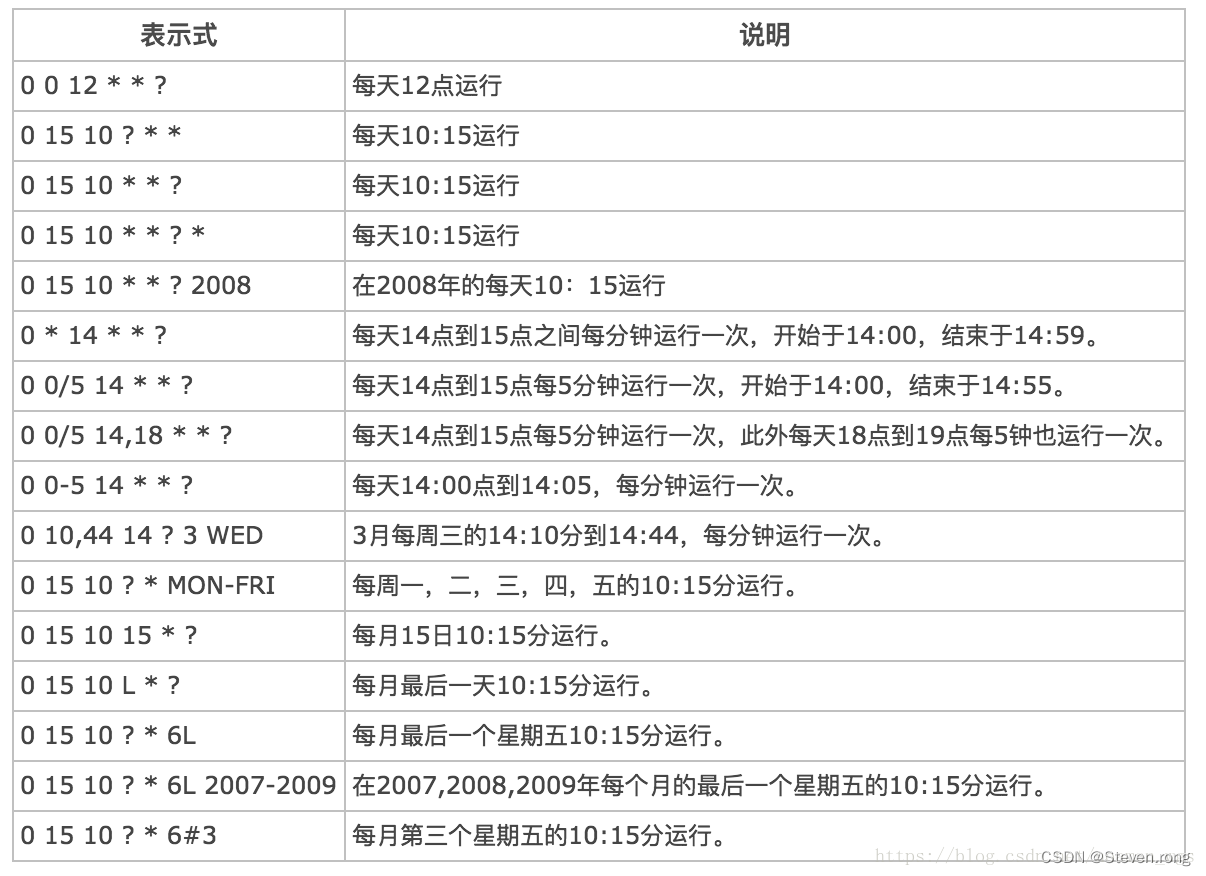
这里不花精力去将cron表达式的语法了,感兴趣可以自己去查
构建CronTriggers
CronTrigger实例使用TriggerBuilder(用于触发器的主要属性)和CronScheduleBuilder(对于CronTrigger特定的属性)构建。要以DSL风格使用这些构建器,请使用静态导入:
import static org.quartz.TriggerBuilder.*;
import static org.quartz.CronScheduleBuilder.*;
import static org.quartz.DateBuilder.*:
建立一个触发器,每隔两分钟,每天上午8点至下午5点之间:
trigger = newTrigger().withIdentity("trigger3", "group1").withSchedule(cronSchedule("0 0/2 8-17 * * ?")).forJob("myJob", "group1").build();
建立一个触发器,将在上午10:42每天发射:
trigger = newTrigger().withIdentity("trigger3", "group1").withSchedule(dailyAtHourAndMinute(10, 42)).forJob(myJobKey).build();
或者:
trigger = newTrigger().withIdentity("trigger3", "group1").withSchedule(cronSchedule("0 42 10 * * ?")).forJob(myJobKey).build();
建立一个触发器,将在星期三上午10:42在TimeZone(系统默认值)之外触发:
trigger = newTrigger().withIdentity("trigger3", "group1").withSchedule(weeklyOnDayAndHourAndMinute(DateBuilder.WEDNESDAY, 10, 42)).forJob(myJobKey).inTimeZone(TimeZone.getTimeZone("America/Los_Angeles")).build();
或者:
trigger = newTrigger().withIdentity("trigger3", "group1").withSchedule(cronSchedule("0 42 10 ? * WED")).inTimeZone(TimeZone.getTimeZone("America/Los_Angeles")).forJob(myJobKey).build();
CronTrigger Misfire说明
以下说明可以用于通知Quartz当CronTrigger发生失火时应该做什么。(本教程“更多关于触发器”部分引入了失火情况)。这些指令定义为CronTrigger本身的常量(包括描述其行为的JavaDoc)。说明包括:
CronTrigger的Misfire指令常数
MISFIRE_INSTRUCTION_IGNORE_MISFIRE_POLICY
MISFIRE_INSTRUCTION_DO_NOTHING
MISFIRE_INSTRUCTION_FIRE_NOW
所有触发器还具有可用的Trigger.MISFIRE_INSTRUCTION_SMART_POLICY指令,并且该指令也是所有触发器类型的默认值。“智能策略”指令由CronTrigger解释为MISFIRE_INSTRUCTION_FIRE_NOW。
CronTrigger.updateAfterMisfire()方法的JavaDoc解释了此行为的确切细节。
在构建CronTriggers时,您可以将misfire指令指定为简单计划的一部分(通过CronSchedulerBuilder):
trigger = newTrigger().withIdentity("trigger3", "group1").withSchedule(cronSchedule("0 0/2 8-17 * * ?")..withMisfireHandlingInstructionFireAndProceed()).forJob("myJob", "group1").build();
错过触发机制
Quartz misfire详解
Quartz-错过触发机制
Quartz的Misfire处理规则 错过任务执行时间的处理机制
TriggerListeners和JobListeners
Listeners是您创建的对象,用于根据调度程序中发生的事件执行操作。您可能猜到,TriggerListeners接收到与触发器(trigger)相关的事件,JobListeners 接收与jobs相关的事件
与触发相关的事件包括:触发器触发,触发失灵,触发完成(触发器关闭)。
org.quartz.TriggerListener接口
public interface TriggerListener {public String getName();
//触发器触发public void triggerFired(Trigger trigger, JobExecutionContext context);public boolean vetoJobExecution(Trigger trigger, JobExecutionContext context);//触发失灵public void triggerMisfired(Trigger trigger);
//触发器完成public void triggerComplete(Trigger trigger, JobExecutionContext context,int triggerInstructionCode);
}
job相关事件包括:job即将执行的通知,以及job完成执行时的通知。
org.quartz.JobListener接口
public interface JobListener {public String getName();public void jobToBeExecuted(JobExecutionContext context);public void jobExecutionVetoed(JobExecutionContext context);public void jobWasExecuted(JobExecutionContext context,JobExecutionException jobException);}
使用自己的Listeners
要创建一个listener,只需创建一个实现org.quartz.TriggerListener或org.quartz.JobListener接口的对象。
然后,listener在运行时会向调度程序注册,并且必须给出一个名称(或者,他们必须通过他们的getName()方法来宣传自己的名字)。
为了方便起见,实现这些接口,您的类也可以扩展JobListenerSupport类或TriggerListenerSupport类,并且只需覆盖您感兴趣的事件。
listener与调度程序的ListenerManager一起注册,并配有描述listener希望接收事件的job触发器的Matcher。
在运行时间内与调度程序一起注册,并且不与jobs和触发器一起存储在JobStore中。这是因为听众通常是与应用程序的集成点。因此,每次运行应用程序时,都需要重新注册该调度程序。
添加对特定job感兴趣的JobListener:
scheduler.getListenerManager().addJobListener(myJobListener,KeyMatcher.jobKeyEquals(new JobKey("myJobName","myJobGroup")));
您可能需要为匹配器和关键类使用静态导入,这将使您定义匹配器更简洁:
import static org.quartz.JobKey.*;
import static org.quartz.impl.matchers.KeyMatcher.*;
import static org.quartz.impl.matchers.GroupMatcher.*;
import static org.quartz.impl.matchers.AndMatcher.*;
import static org.quartz.impl.matchers.OrMatcher.*;
import static org.quartz.impl.matchers.EverythingMatcher.*;
...etc.
这将上面的例子变成这样:
scheduler.getListenerManager().addJobListener(myJobListener, jobKeyEquals(jobKey("myJobName", "myJobGroup")));
添加对特定组的所有job感兴趣的JobListener:
scheduler.getListenerManager().addJobListener(myJobListener, jobGroupEquals("myJobGroup"));
添加对两个特定组的所有job感兴趣的JobListener:
scheduler.getListenerManager().
addJobListener(myJobListener, or(jobGroupEquals("myJobGroup"), jobGroupEquals("yourGroup")));
添加对所有job感兴趣的JobListener:
scheduler.getListenerManager().addJobListener(myJobListener, allJobs());
注册TriggerListeners的工作原理相同。
Quartz的大多数用户并不使用Listeners,但是当应用程序需求创建需要事件通知时不需要Job本身就必须明确地通知应用程序,这些用户就很方便。
SchedulerListeners
SchedulerListeners非常类似于TriggerListeners和JobListeners,除了它们在Scheduler本身中接收到事件的通知 - 不一定与特定触发器(trigger)或job相关的事件。
与计划程序相关的事件包括:添加job/触发器,删除job/触发器,调度程序中的严重错误,关闭调度程序的通知等。
org.quartz.SchedulerListener接口
public interface SchedulerListener {public void jobScheduled(Trigger trigger);public void jobUnscheduled(String triggerName, String triggerGroup);public void triggerFinalized(Trigger trigger);public void triggersPaused(String triggerName, String triggerGroup);public void triggersResumed(String triggerName, String triggerGroup);public void jobsPaused(String jobName, String jobGroup);public void jobsResumed(String jobName, String jobGroup);public void schedulerError(String msg, SchedulerException cause);public void schedulerStarted();public void schedulerInStandbyMode();public void schedulerShutdown();public void schedulingDataCleared();
}
SchedulerListeners注册到调度程序的ListenerManager。SchedulerListeners几乎可以实现任何实现org.quartz.SchedulerListener接口的对象。
添加SchedulerListener:
scheduler.getListenerManager().addSchedulerListener(mySchedListener);
删除SchedulerListener:
scheduler.getListenerManager().removeSchedulerListener(mySchedListener);
Scheduler
scheduler 是quartz的核心所在,所有的任务都是通过scheduler开始。
scheduler是一个接口类,所有的具体实现类都是通过SchedulerFactory工厂类实现,但是SchedulerFactory有两个具体的实现类,如图:

- StdSchedulerFactory:默认值加载是当前工作目录下的”quartz.properties”属性文件。如果加载失败,会去加载org/quartz包下的”quartz.properties”属性文件。一般使用这个实现类就能满足我们的要求。
- DirectSchedulerFactory:这个我也没用过QAQ,听说是为那些想绝对控制 Scheduler 实例是如何生产出的人所
设计的。
Job Stores
Quartz提供两种基本作业存储类型:
- RAMJobStore :RAM也就是内存,默认情况下Quartz会将任务调度存在内存中,这种方式性能是最好的,因为内存的速度是最快的。不好的地方就是数据缺乏持久性,但程序崩溃或者重新发布的时候,所有运行信息都会丢失
- DBC作业存储:存到数据库之后,可以做单点也可以做集群,当任务多了之后,可以统一进行管理。关闭或者重启服务器,运行的信息都不会丢失。缺点就是运行速度快慢取决于连接数据库的快慢。
为什么需要持久化?
- 以后可以做集群。
- 任务可以进行管理,随时停止、暂停、修改任务。
Quartz初始化表
如果需要做持久化的话,数据肯定是要存在数据库的,那么到底存在哪些表呢?
参考文章
Quartz快速入门指南
SpringBoot整合Quartz实现定时任务
定时任务框架Quartz-(一)Quartz入门与Demo搭建
Quartz框架介绍
SpringBoot整合Quartz定时任务(持久化到数据库)
Spring官网文档整合Quarz
SpringBoot2.0整合Quartz定时任务(持久化到数据库,更为简单的方式)
spring和quartz整合实现动态定时任务并持久化到数据库
《SpringBoot2.0 实战》系列-集成Quartz定时任务(持久化到数据库)