一. 概括
图神经网络已经成为深度学习领域最炽手可热的方向之一。本文提出Graph Attention Networks(GATs),将注意力机制应用到图神经网络中,每一层学习节点每个邻居对其生成新特征的贡献度,按照贡献度大小对邻居特征进行聚合,以此生成节点新特征。GATs具有计算复杂度低,适用归纳学习任务的特性。因此,GAT 不仅对于噪音邻居较为鲁棒,注意力机制也赋予了模型一定的可解释性。
二. self-attention
本节详细介绍每一次迭代(每一层)中aggregate模块所使用的Self-Attention机制

2.1 方法
输入:节点i特征 , 邻居特征
输出:邻居j对节点i生成新特征的贡献度
模型:使用一个简单的前馈神经网络去计算 , 共享参数W 通过反向传播学习。

2.2 输入预处理
对,
线性变换,得到W
和W
- W为参数矩阵,将F维的特征线性组合生成F'维特征。
- 线性变换的目的是得到更强大的表达,可以见参考:YJango:深层学习为何要“Deep”
2.3 输入层->隐层
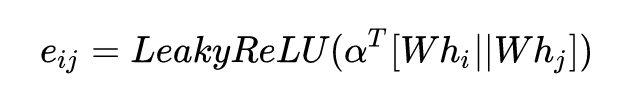
注意力网络可以有很多的设计方式,这里作者将节点 i和j 的表示进行了拼接,再映射为一个标量。需要。
- eij表示邻居j的特征对i的重要性/贡献度。
- ||表示将将i和j拼接起来,作为神经网络的输入(2F'维),注意这里拼接导致eij != eji ,也就是说注意力值 是非对称的.
- a为输入层->隐层的参数,因为隐藏只有一个神经元,故是一个2F'维的向量。
- 激活单元使用Leaky ReLU 进行非线性转换
2.4 隐层->输出层
为了使不同邻居的贡献度可以对比,使用softmax归一化,最终得到邻居j对节点i生成新特征的贡献度 aij
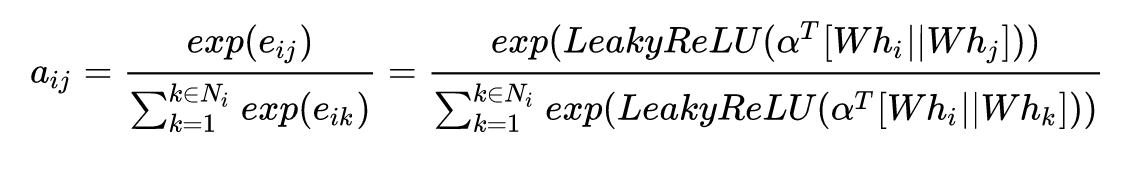
2.5 生成节点新特征
对节点i的邻居特征按贡献度 aij进行加权平均后加一个非线性转换,得到节点i的新特征
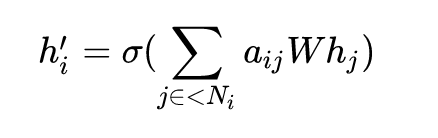
2.6 Transformer Vs GAT
NLP 中大火的 Transformer 和 GAT 本质在做一样的事情。Transformer 利用 self-attention 机制将输入中的每个单词用其上下文的加权来表示,而 GAT 是利用 self-attention 机制将每个节点用其邻居的加权来表示。下面是经典的 Transformer 公式:

上述过程和 GAT 的核心思想非常相似:都是通过探索输入之间的关联性(注意力权重),通过对上下文信息(句子上下文/节点邻居)进行聚合,来获得各个输入(单词/节点)的表示。
Transformer 和 GAT 的主要区别是:
1.在 GAT 中,作者对自注意力进行了简化。每个节点无论是作为中心节点/上下文/聚合输出,都只用一种表示 。也就是说,在 GAT 中 Q=K=V
2.在图上,节点的邻居是一个集合,具有不变性。Transformer 将文本隐式的建图过程中丢失了单词之间的位置关系,这对 NLP 的一些任务是很致命的。为了补偿这种建图损失的位置关系,Transformer 用了额外了的位置编码来描述位置信息
三. Multi-head Attention
因为只计算一次attention,很难捕获邻居所有的特征信息,《Attention is all you need》论文中进一步完善了attention机制,提出了multi-head attention ,其实很简单,就是重复做多次attention计算),如下图所示:

其中, 表示一个可训练的参数向量, 用来学习节点和邻居之间的相对重要性, 也是一个可训练的参数矩阵,用来对输入特征做线性变换,表示向量拼接(concate)。
本文也使用了multi-head attention:学习K个不同的attention,对应参数 ,
然后在生成节点i的新特征时拼接起来

如果在整个图神经网络的最后一层,使用平均替代拼接,得到节点最终的embedding:

四. GAT VS GCN
1. 与GCN的联系与区别
无独有偶,我们可以发现本质上而言:GCN与GAT都是将邻居顶点的特征聚合到中心顶点上(一种aggregate运算),利用graph上的local stationary学习新的顶点特征表达。不同的是GCN利用了拉普拉斯矩阵,GAT利用attention系数。一定程度上而言,GAT会更强,因为顶点特征之间的相关性被更好地融入到模型中。
2. 为什么GAT适用于有向图?
我认为最根本的原因是GAT的运算方式是逐顶点的运算(node-wise),这一点可从公式(1)—公式(3)中很明显地看出。每一次运算都需要循环遍历图上的所有顶点来完成。逐顶点运算意味着,摆脱了拉普利矩阵的束缚,使得有向图问题迎刃而解。
3. 为什么GAT适用于inductive任务?
GAT中重要的学习参数是 W 与 a(·) ,因为上述的逐顶点运算方式,这两个参数仅与顶点特征相关,与图的结构毫无关系。所以测试任务中改变图的结构,对于GAT影响并不大,只需要改变 Ni,重新计算即可。
与此相反的是,GCN是一种全图的计算方式,一次计算就更新全图的节点特征。学习的参数很大程度与图结构相关,这使得GCN在inductive任务上遇到困境。
补充. Message Passing



https://zhuanlan.zhihu.com/p/66812926