这次将介绍如何爬取自己喜欢的小说,以及爬取过程中如何处理具有乱码的网页,以及如何去解码及封装代码
目标网址:http://www.shuquge.com/
爬取书趣阁小说
- 1.分析网页
- (1) 分析网页
- (2) 审查网页代码
- (3) 请求网页内容
- (4) 对网页内容进行解码
- 2.换一个小说进行爬取
- (1)请求内容并解码输出
- (2)提取小说标题
- (3)提取小说内容
- (4)拼接及替换小说内容
- 3.保存内容
- (1)with方法保存爬取内容为txt文件
- (2)绝对路径保存文件到桌面
- (3)加号方法保存文件到桌面
- (4)封装方法保存文件
- (5)使用封装方法爬取并保存第二章
- (6)添加主函数爬取并保存第三章
- 4.取所有章节链接
- (1)分析链接特点
- (2)开始取所有链接
- (3)构造完整链接
- (4)打包所有完整链接并求个数
- (5)将获取章节链接的代码封装
- (6)获取所有章节小说内容
1.分析网页
以爬取书趣阁网站上的小说《傲世九重天》为例
(1) 分析网页
- 打开网站,搜索到该小说如下:
 接下来查看小说第一章的链接为:
接下来查看小说第一章的链接为:
http://www.shuquge.com/txt/55040/8416285.html
 小说第二章的链接为:
小说第二章的链接为:
http://www.shuquge.com/txt/55040/8416286.html
 小说第三章的链接为:
小说第三章的链接为:
http://www.shuquge.com/txt/55040/8416287.html

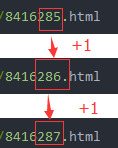
- 对比第一、二、三章的网页链接:
http://www.shuquge.com/txt/55040/8416285.html
http://www.shuquge.com/txt/55040/8416286.html
http://www.shuquge.com/txt/55040/8416287.html
可以发现,第一、二、三章的网页链接只有结尾部分的数字不一样:
(2) 审查网页代码
以小说第一章为例:
- 右击检查网页代码
 点击上图中所说的三个点,就会显示出第一章小说的文本内容:
点击上图中所说的三个点,就会显示出第一章小说的文本内容:

(3) 请求网页内容
- 导入库,开始请求网页返回内容
import requests #导入库
from lxml import etree #导入库
#复制第一章网页地址
target_url="http://www.shuquge.com/txt/55040/8416285.html"
requests.get(url=target_url) #请求第一章网页内容
运行结果:

请求网页内容成功,要注意此处复制的网页链接为第一章所在网页的顶端链接:
因为该网页上我们没有遇到反爬虫程序,所以才可以在没有设置浏览器代理的情况下顺利返回网页信息,如果遇到反爬虫程序,我们就要设置浏览器代理才可以顺利返回网页信息
- 给返回内容赋值并以
.text的文本格式输出
import requests #导入库
from lxml import etree #导入库
#复制第一章网页地址
target_url="http://www.shuquge.com/txt/55040/8416285.html"
response=requests.get(url=target_url) #请求第一章网页内容,并将返回值赋给response
print(response.text) #将response以文本格式输出
运行结果:
 可以发现,我们输出的内容中,小说的文本部分显示的是乱码,而1.(2)审查代码中原网页上显示的文本部分就是小说的文本内容,所以我们接下来要做的就是对请求返回的网页内容
可以发现,我们输出的内容中,小说的文本部分显示的是乱码,而1.(2)审查代码中原网页上显示的文本部分就是小说的文本内容,所以我们接下来要做的就是对请求返回的网页内容response还没输出为文本之前进行解码
(4) 对网页内容进行解码
因为要对请求返回的网页内容response还没输出为文本之前进行解码,即先解码,再输出文本才不是乱码
实质上还是对response进行解码
- 知识拓展:常见编码方式:
utf-8、utf-8-sig、gbk
此处我们将使用一个较为万能的解码方式:
apparent_encoding
使用这个解码方式,它会在不需提示我们需要什么类型的信息的条件下,自动解码出我们所要的信息,但需要注意的是,虽说是万能解码方式,但成功率只有90% - 对第一章小说进行解码
#解码
#对乱码response的内容进行解码,response.encoding为response解码后的名字,.apparent_encoding 为引用万能解码函数
response.encoding=response.apparent_encoding
print(response.text) #将解码后的response的内容response.encoding以文本格式输出
运行结果:
 从解码后的结果来看,乱码部分已经显示为了文字,但通过复制原网页中第一章的小说内容,再利用
从解码后的结果来看,乱码部分已经显示为了文字,但通过复制原网页中第一章的小说内容,再利用Ctrl+f键来到运行结果中查找小说内容,并没有查找到小说内容,此时我们考虑设置浏览器代理
- 设置浏览器代理
查找浏览器代理步骤:
 代码及运行结果:
代码及运行结果:
#添加浏览器代理
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.113 Safari/537.36"
}
运行结果和未添加浏览器代理时一样,通过查找还是没有显示小说文本内容,我们再考虑在设置浏览器代理的位置添加一个防盗链
- 添加防盗链
添加时同样遵循同时设置两个字典时,两个字典中间要用逗号分隔的语法
查找防盗链:
 代码及运行结果:
代码及运行结果:
#添加浏览器代理及防盗链
headers = {"Referer":"http://www.shuquge.com/txt/55040/index.html","User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.113 Safari/537.36"
}
运行结果和未添加防盗链时一样,通过查找还是没有显示小说文本内容,代码无错,就可能是网页本身的问题,所以我们将以同样的代码爬取该网站上的另一个小说
2.换一个小说进行爬取
以书趣阁网站中的另一个小说《天域苍穹》为例
(1)请求内容并解码输出
请求网页为小说《天域苍穹》的第一章
代码及运行结果如下:
#换一个小说后
import requests
url="http://www.shuquge.com/txt/514/363448.html" #天域苍穹第一章链接
response=requests.get(url) #请求第一章网页内容,并将返回值赋给response
response.encoding=response.apparent_encoding #将解码后的response的内容赋值给response.encoding
response.text #将response.encoding以文本格式输出
运行结果:
 请求内容并解码输出《天域苍穹》第一章内容成功,接下来我们将对小说内容进行提取
请求内容并解码输出《天域苍穹》第一章内容成功,接下来我们将对小说内容进行提取
(2)提取小说标题
- 导入库,提取并解析筛取信息
#提取信息
from lxml import etree
#解析筛取信息
etree_html=etree.HTML(response.text)
代码没有报错,提取并解析筛取信息成功
- 提取第一章小说标题
复制第一章小说标题xpath路径
 代码及运行结果如下:
代码及运行结果如下:
#提取信息
from lxml import etree
#解析筛取信息
etree_html=etree.HTML(response.text)
#提取第一章小说标题,/text()不是xpath路径组成部分,意为将内容输出为文本格式
title=etree_html.xpath('//*[@id="wrapper"]/div[4]/div[2]/h1/text()')
print(title)
运行结果:

(3)提取小说内容
仍然使用xpath方式
寻找小说内容所在标签:
选中第一章的所有小说内容,右击检查,会显示出小说内容所在标签,右击copy,再copy xpath即可
 代码及运行结果如下:
代码及运行结果如下:
#提取第一章小说内容
etree_html.xpath('//*[@id="content"]/text()')
可以在将xpath路径加一个/,使查找结果更为准确,可改可不改,即改为
#提取第一章小说内容
etree_html.xpath('//*[@id="content"]//text()')
运行结果:
 此时小说内容为数组,为了方便保存,我们要将它拼接为字符串
此时小说内容为数组,为了方便保存,我们要将它拼接为字符串
(4)拼接及替换小说内容
- 给提取的小说内容赋值,并拼接为字符串
代码及运行结果如下:
#提取第一章小说内容
content=etree_html.xpath('//*[@id="content"]/text()') #现还为数组
"".join(content) #拼接为字符串
运行结果:
 运行结果中,小说内容文本中存在一些多余标签,我们可使用替换功能将其去除
运行结果中,小说内容文本中存在一些多余标签,我们可使用替换功能将其去除
- 替换多余标签
代码及运行结果如下:
"".join(content).replace("\r\r\xa0\xa0\xa0\xa0","") #拼接为字符串,替换多余标签
运行结果:

3.保存内容
(1)with方法保存爬取内容为txt文件
由于我们替换掉的多余标签\r\r\xa0\xa0\xa0\xa0在文本中起到换行的作用,所以保存文件时我们将撤销对它的替换函数
代码及运行结果如下:
#保存文件
#创建文件并打开
with open('.第一章 若得来生重倚剑,屠尽奸邪笑苍天.txt','a',encoding='utf-8')as file: file.write(text) #放进去内容,写入
file.close()#写入后关闭文件
运行结果:

保存内容文件夹及其内容:


(2)绝对路径保存文件到桌面
3.(1)的保存方法中,文件路径为相对路径,而我们可以使用绝对路径将文件直接保存到桌面
- 现在桌面新建一个文件夹,并将其路径复制下来,用于构造绝对路径
 要复制的路径为:
要复制的路径为:C:\Users\ASUS\Desktop\桌面小说 - 使用绝对路径保存文件到桌面
代码及运行结果如下:
#保存文件
#创建文件并打开,r表示原意,\表示转义字符
with open(r'C:\Users\ASUS\Desktop\桌面小说\第一章 若得来生重倚剑,屠尽奸邪笑苍天.txt','a',encoding='utf-8')as file: file.write(text) #放进去内容,写入
file.close()#写入后关闭文件
运行结果:

桌面文件保存情况:

(3)加号方法保存文件到桌面
可以以另一种方式构造保存文件到桌面时的路径,此处为了看出运行效果,可将上一步保存在文件夹桌面小说中的.txt文件先删除
代码及运行结果如下:
#保存文件
#创建文件并打开,r表示原意,\表示转义字符
filePath=r"C:\Users\ASUS\Desktop\桌面小说\\" #将绝对路径前半部分拿出来with open(filePath+title[0]+'.txt','a',encoding='utf-8')as file: file.write(text) #放进去内容,写入
file.close()#写入后关闭文件
运行结果:

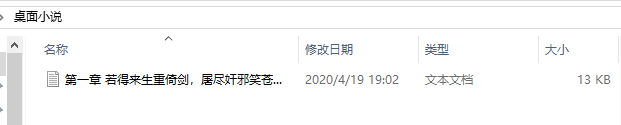
桌面文件保存情况:
- 何时使用相对路径?何时使用绝对路径?
使用相对路径:将文件保存在当前目录中,即打开控制台之前新建的文件夹中
使用绝对路径:保存文件到当前路径之外的地方
具体使用哪一种路径来保存看个人需求来定
(4)封装方法保存文件
所谓封装,就是把能实现某个功能的代码用一个函数封装起来,这样做可以便于我们再想要实现这部分代码的功能时,直接引用它的封装名,而不需要自己再去写一遍代码
- 下面我们将使用封装函数将解析并保存小说内容部分的代码封装起来,并用封装名打开它来实现保存文件内容的目的(仍以保存到桌面为例,需要上一步保存的先删除)
关键语句:
封装函数:def download_text():
调用封装函数时(解封):download_text()
download_text()为自己命名的封装函数名
代码及运行结果如下:
#提取信息
from lxml import etree
def download_text(): #封装到 file.close()#解析筛取信息etree_html=etree.HTML(response.text)#提取第一章小说标题,/text()不是xpath路径组成部分,意为将内容输出为文本格式title=etree_html.xpath('//*[@id="wrapper"]/div[4]/div[2]/h1/text()')print(title)#提取第一章小说内容content=etree_html.xpath('//*[@id="content"]/text()') #现还为数组#"".join(content).replace("\r\r\xa0\xa0\xa0\xa0","") #拼接为字符串,替换多余标签text="".join(content) #拼接为字符串,多余标签\r\n为换行作用#保存文件#创建文件并打开,r表示原意,\表示转义字符filePath=r"C:\Users\ASUS\Desktop\桌面小说\\" #将绝对路径前半部分拿出来with open(filePath+title[0]+'.txt','a',encoding='utf-8')as file: file.write(text) #放进去内容,写入file.close()#写入后关闭文件
download_text()
运行结果:

打开桌面文件夹:
 文件内容:
文件内容:

- 将要爬取得网页链接带入封装方法中
代码及运行结果如下:
#提取信息
from lxml import etree def download_text(url): #封装到 file.close()#请求网页内容并解码 response=requests.get(url) #请求第一章网页内容,并将返回值赋给responseresponse.encoding=response.apparent_encoding #将解码后的response的内容赋值给response.encoding #解析筛取信息etree_html=etree.HTML(response.text)#提取第一章小说标题,/text()不是xpath路径组成部分,意为将内容输出为文本格式title=etree_html.xpath('//*[@id="wrapper"]/div[4]/div[2]/h1/text()')print(title)#提取第一章小说内容content=etree_html.xpath('//*[@id="content"]/text()') #现还为数组#"".join(content).replace("\r\r\xa0\xa0\xa0\xa0","") #拼接为字符串,替换多余标签text="".join(content) #拼接为字符串,多余标签\r\n为换行作用#保存文件#创建文件并打开,r表示原意,\表示转义字符filePath=r"C:\Users\ASUS\Desktop\桌面小说\\" #将绝对路径前半部分拿出来with open(filePath+title[0]+'.txt','a',encoding='utf-8')as file: file.write(text) #放进去内容,写入file.close()#写入后关闭文件
target_url="http://www.shuquge.com/txt/514/363448.html" #天域苍穹第一章链接
download_text(target_url) #打开方法时连着页面的链接
链接的传递过程:
 运行结果和之前保存文件的一样
运行结果和之前保存文件的一样
(5)使用封装方法爬取并保存第二章
使用封装方法爬取并保存第二章,只需要上一步中的target_url改为第二章的链接即可
#天域苍穹第二章链接
target_url="http://www.shuquge.com/txt/514/363449.html"
运行结果如下:
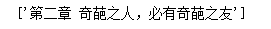
打开桌面文件夹第二章及其内容:


(6)添加主函数爬取并保存第三章
将target_url改为第三章的链接,再在关闭文件的下方写一个mian主函数,同样可以爬取并保存第三章
代码及运行结果如下:
#提取信息
from lxml import etree def download_text(url): #封装到 file.close()#请求网页内容并解码 response=requests.get(url) #请求第三章网页内容,并将返回值赋给responseresponse.encoding=response.apparent_encoding #将解码后的response的内容赋值给response.encoding #解析筛取信息etree_html=etree.HTML(response.text)#提取第一章小说标题,/text()不是xpath路径组成部分,意为将内容输出为文本格式title=etree_html.xpath('//*[@id="wrapper"]/div[4]/div[2]/h1/text()')print(title)#提取第一章小说内容content=etree_html.xpath('//*[@id="content"]/text()') #现还为数组#"".join(content).replace("\r\r\xa0\xa0\xa0\xa0","") #拼接为字符串,替换多余标签text="".join(content) #拼接为字符串,多余标签\r\n为换行作用#保存文件#创建文件并打开,r表示原意,\表示转义字符filePath=r"C:\Users\ASUS\Desktop\桌面小说\\" #将绝对路径前半部分拿出来with open(filePath+title[0]+'.txt','a',encoding='utf-8')as file: file.write(text) #放进去内容,写入file.close()#写入后关闭文件if __name__=='__main__': #添加主函数target_url="http://www.shuquge.com/txt/514/363450.html" #天域苍穹第三章链接download_text(target_url) #打开方法时连着页面的链接
运行结果:

打开桌面文件夹第三章及其内容:


4.取所有章节链接
(1)分析链接特点
打开第一章,右击检查代码,可以发现其网页链接如下:
 所以接下来我们在请求小说首页给我们返回内容时,只要包含有所有章节的这种类型的链接即可,有乱码页不影响
所以接下来我们在请求小说首页给我们返回内容时,只要包含有所有章节的这种类型的链接即可,有乱码页不影响
- 取所有章节链接代码及运行结果如下:
#取所有章节链接
index_url="http://www.shuquge.com/txt/514/index.html" #小说首页链接
index_html=requests.get(index_url).text #在小说首页请求所有链接的内容以文本格式输出
index_html #输出小说首页所有连接的内容
运行结果:
 其中有乱码,但只要我们需要的每一章小说的链接不是乱码即可
其中有乱码,但只要我们需要的每一章小说的链接不是乱码即可
(2)开始取所有链接
分析所有章节的xpath路径:
第一章:
/html/body/div[5]/dl/dd[13]/a
第二章:
/html/body/div[5]/dl/dd[14]/a
第三章:
/html/body/div[5]/dl/dd[15]/a
对比三个链接可以发现,不同的部分有:
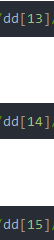
前三章的xpath路径是这样,说明面的章节xpath路径变化规律也是一样的,而我们可以根据这个不同的地方将xpath路径分为前后两段,以此来循环出所有章节的链接
代码及运行结果如下:
#取所有章节链接
index_url="http://www.shuquge.com/txt/514/index.html" #小说首页链接
index_html=requests.get(index_url).text
index_etree=etree.HTML(index_html) #提取内容
#用标签分段取链接
dd=index_etree.xpath('/html/body/div[5]/dl/dd') #写的是所有章节xpath路径写的是的前半部分的相同部分
for item in dd:href=item.xpath('./a/@href') #写的是所有章节xpath路径写的是的后半部分的相同部分,@href意为返回内容为链接print(href)
运行结果:
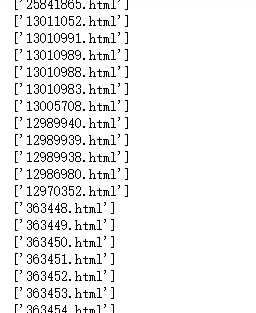
(3)构造完整链接
上一步中我们将章节的链接都拿了出来,但它们不是完整的链接,不可以电机后直接访问到相应章节的小说内容,所以我们将把链接缺失的部分补上
代码及运行结果如下:
#取所有章节链接
index_url="http://www.shuquge.com/txt/514/index.html" #小说首页链接
index_html=requests.get(index_url).text
index_etree=etree.HTML(index_html) #提取内容
#用标签分段取链接
dd=index_etree.xpath('/html/body/div[5]/dl/dd') #写的是所有章节xpath路径写的是的前半部分的相同部分
for item in dd:#构造完整链接href="http://www.shuquge.com/txt/514/"+item.xpath('./a/@href')[0] #写的是所有章节xpath路径写的是的后半部分的相同部分,@href意为返回内容为链接print(href)
运行结果:

(4)打包所有完整链接并求个数
代码及运行结果如下:
#取所有章节链接
index_url="http://www.shuquge.com/txt/514/index.html" #小说首页链接
index_html=requests.get(index_url).text
index_etree=etree.HTML(index_html) #提取内容
#用标签分段取链接
dd=index_etree.xpath('/html/body/div[5]/dl/dd') #写的是所有章节xpath路径写的是的前半部分的相同部分
link_list=[]#打包所有链接
for item in dd:#构造完整链接href="http://www.shuquge.com/txt/514/"+item.xpath('./a/@href')[0] #写的是所有章节xpath路径写的是的后半部分的相同部分,@href意为返回内容为链接link_list.append(href) #每输出一个链接,便追加到 link_list中
print(link_list)
运行结果:

- 求链接的个数,使用
len()函数即可
代码及运行结果如下:
print(len(link_list))
运行结果:
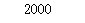
(5)将获取章节链接的代码封装
代码及运行结果如下:
#提取信息
from lxml import etree def download_text(url): #封装到 file.close()#请求网页内容并解码 response=requests.get(url) #请求第三章网页内容,并将返回值赋给responseresponse.encoding=response.apparent_encoding #将解码后的response的内容赋值给response.encoding #解析筛取信息etree_html=etree.HTML(response.text)#提取第一章小说标题,/text()不是xpath路径组成部分,意为将内容输出为文本格式title=etree_html.xpath('//*[@id="wrapper"]/div[4]/div[2]/h1/text()')print(title)#提取第一章小说内容content=etree_html.xpath('//*[@id="content"]/text()') #现还为数组#"".join(content).replace("\r\r\xa0\xa0\xa0\xa0","") #拼接为字符串,替换多余标签text="".join(content) #拼接为字符串,多余标签\r\n为换行作用#保存文件#创建文件并打开,r表示原意,\表示转义字符filePath=r"C:\Users\ASUS\Desktop\桌面小说\\" #将绝对路径前半部分拿出来with open(filePath+title[0]+'.txt','a',encoding='utf-8')as file: file.write(text) #放进去内容,写入file.close()#写入后关闭文件#封装获取所有链接的代码
def get_link(index_url):index_html=requests.get(index_url).textindex_etree=etree.HTML(index_html) #提取内容#用标签分段取链接dd=index_etree.xpath('/html/body/div[5]/dl/dd') #写的是所有章节xpath路径写的是的前半部分的相同部分link_list=[]#打包所有链接for item in dd:#构造完整链接href="http://www.shuquge.com/txt/514/"+item.xpath('./a/@href')[0] #写的是所有章节xpath路径写的是的后半部分的相同部分,@href意为返回内容为链接link_list.append(href) #每输出一个链接,便追加到 link_list中return link_list #返回的东西,我要带走的if __name__=='__main__': #添加主函数index_url="http://www.shuquge.com/txt/514/index.html" #小说首页链接links=get_link(index_url)print(links)
# target_url="http://www.shuquge.com/txt/514/363450.html" #天域苍穹第三章链接
# download_text(target_url) #打开方法时连着页面的链接
运行结果:

(6)获取所有章节小说内容
写一个循环,将所有链接爬取到
改动部分代码为:
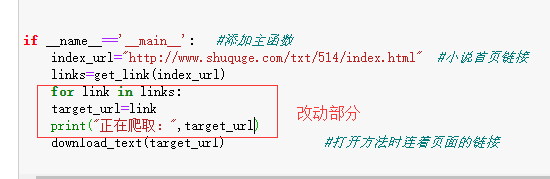 完整运行代码及结果为:
完整运行代码及结果为:
#提取信息
from lxml import etree def download_text(url): #封装到 file.close()#请求网页内容并解码 response=requests.get(url) #请求第三章网页内容,并将返回值赋给responseresponse.encoding=response.apparent_encoding #将解码后的response的内容赋值给response.encoding #解析筛取信息etree_html=etree.HTML(response.text)#提取第一章小说标题,/text()不是xpath路径组成部分,意为将内容输出为文本格式title=etree_html.xpath('//*[@id="wrapper"]/div[4]/div[2]/h1/text()')print(title)#提取第一章小说内容content=etree_html.xpath('//*[@id="content"]/text()') #现还为数组#"".join(content).replace("\r\r\xa0\xa0\xa0\xa0","") #拼接为字符串,替换多余标签text="".join(content) #拼接为字符串,多余标签\r\n为换行作用#保存文件#创建文件并打开,r表示原意,\表示转义字符filePath=r"C:\Users\ASUS\Desktop\桌面小说\\" #将绝对路径前半部分拿出来try:with open(filePath+title[0]+'.txt','a',encoding='utf-8')as file: file.write(text) #放进去内容,写入file.close()#写入后关闭文件except:pass#封装获取所有链接的代码
def get_link(index_url):index_html=requests.get(index_url).textindex_etree=etree.HTML(index_html) #提取内容#用标签分段取链接dd=index_etree.xpath('/html/body/div[5]/dl/dd') #写的是所有章节xpath路径写的是的前半部分的相同部分link_list=[]#打包所有链接for item in dd:#构造完整链接href="http://www.shuquge.com/txt/514/"+item.xpath('./a/@href')[0] #写的是所有章节xpath路径写的是的后半部分的相同部分,@href意为返回内容为链接link_list.append(href) #每输出一个链接,便追加到 link_list中return link_list #返回的东西,我要带走的if __name__=='__main__': #添加主函数index_url="http://www.shuquge.com/txt/514/index.html" #小说首页链接links=get_link(index_url)for link in links:target_url=linkprint("正在爬取:",target_url)download_text(target_url) #打开方法时连着页面的链接
运行结果:
 打开桌面文件夹:
打开桌面文件夹:
 至此,爬取并保存书趣阁小说《天域苍穹》所有章节内容成功结束!
至此,爬取并保存书趣阁小说《天域苍穹》所有章节内容成功结束!










![[C++项目] Boost文档 站内搜索引擎(1): 项目背景介绍、相关技术栈、相关概念介绍...](https://img-blog.csdnimg.cn/img_convert/a0d24a580831ed4856a2c7d8331b55e8.png)