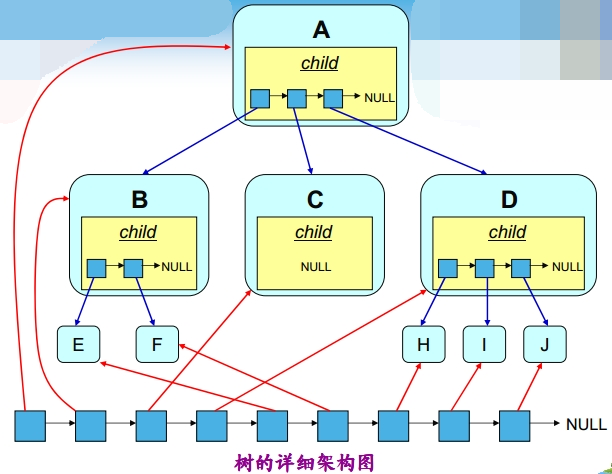
一、树的概念
树是一种典型的非线性结构,是表达有层次特性的图结构的一种方法。
1.1 基本术语
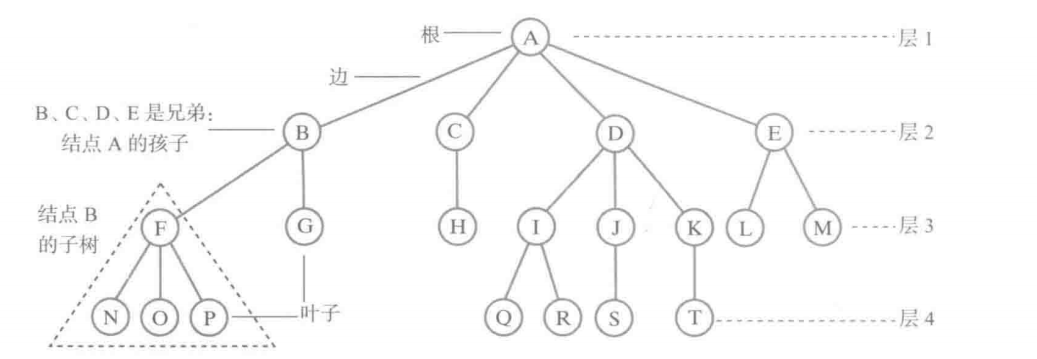
| 术语 | 描述 |
|---|---|
| 空树 | 当n=0 时称为空树。 |
| 根结点 | 根结点是一个没有双亲结点的结点。一棵树最多一个。例如:A |
| 边 | 结点之间的连线 |
| 叶子结点 | 没有孩子结点的结点。例如:N、O、P |
| 兄弟结点 | 同一双亲的孩子结点; 堂兄结点:同一层上结点 |
| 祖先结点 | 从根到该结点的所经分支上的所有结点 |
| 子孙结点 | 以某结点为根的子树中任一结点都称为该结点的子孙 |
| 结点层 | 根结点的层定义为1;根的孩子为第二层结点,依此类推; |
| 树的深度 | 树中最大的结点层 |
| 树的高度 | 跟树的深度一个意思。树中所有结点高度的最大值 |
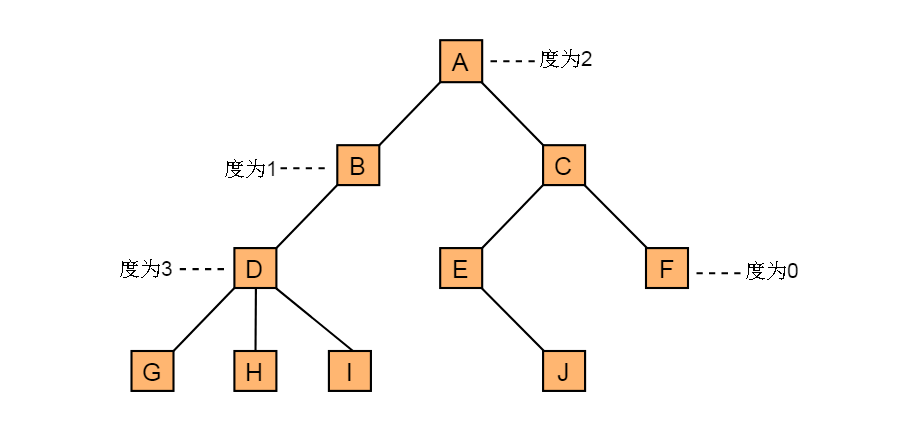
| 结点的度 | 结点子树的个数 |
| 树的度 | 树中最大的结点度。 |
| 分枝结点 | 度不为0的结点; |
| 有序树 | 子树有序的树,如:家族树; |
| 无序树 | 不考虑子树的顺序 |
注意:有写书定义书高和层是从0开始的。如:根结点在0层
- 树的度
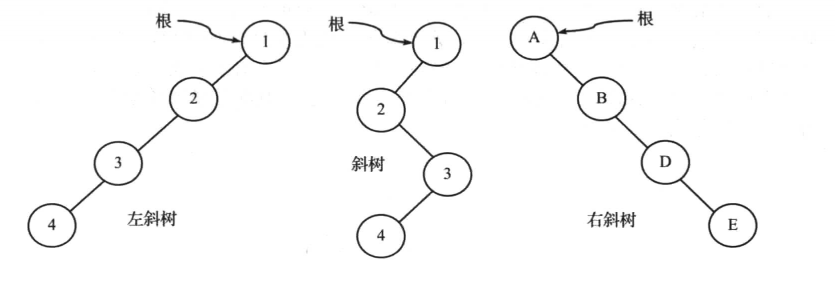
- 如果树除了叶子结点外,其余每一个结点只有一个孩子结点,则这种树称为斜树; 所有的结点都只有左子树的二叉树叫左斜树。所有结点都是只有右子树的二叉树叫右斜树。
1.2 二叉树
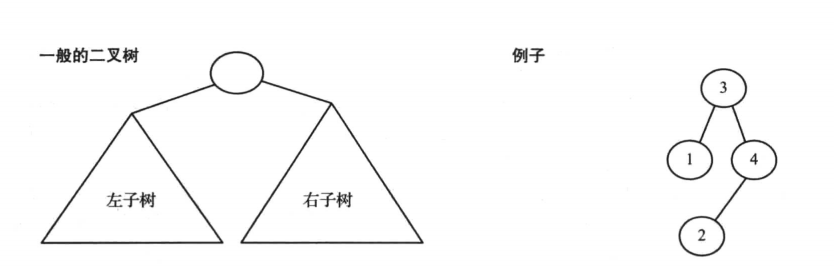
如果一棵树的每个结点有0 、1 后者 2个结点(最多两个孩子结点),那么这棵树称为二叉树。空树也是一棵有效的二叉树。二叉树的子树还是二叉树。实际上可以递归定义二叉树。(因为这个特性,对二叉树的操作常常使用递归算法)
- 满二叉树/满树: 二叉树中的每个结点恰好有两个孩子结点且所有叶子结点都在同一层。
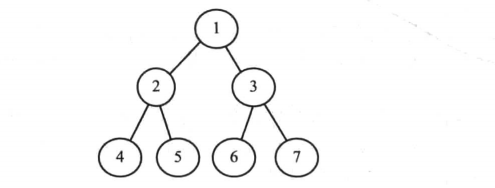
- 完全二叉树/完全树:对一颗具有n个结点的二叉树按层编号,如果编号为i(1<=i<=n) 的结点与同样深度的满二叉树中编号为i的结点在二叉树中位置完全相同,则这棵二叉树称为完全二叉树
倒数第二层是满的,且最后一层的叶子结点从左至右填充
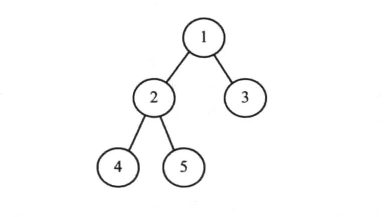
- 平衡二叉树: 如果树中的每个结点的子树的高度差不大于1,则树称为高度平衡的或者平衡的。
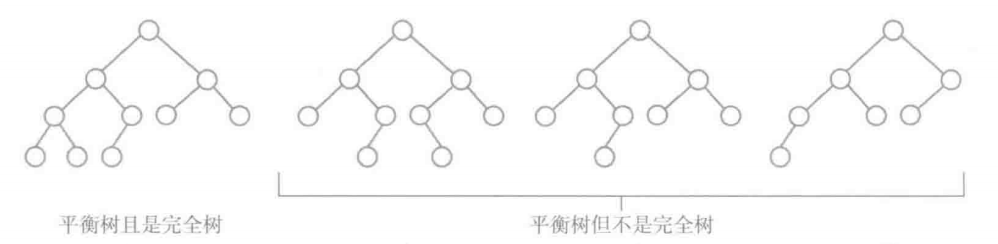
- 完全平衡树: 若二叉树中的每个结点有两棵高度相等的子树,则该树称为完全平衡树。唯一的完全平衡二叉树是满树。
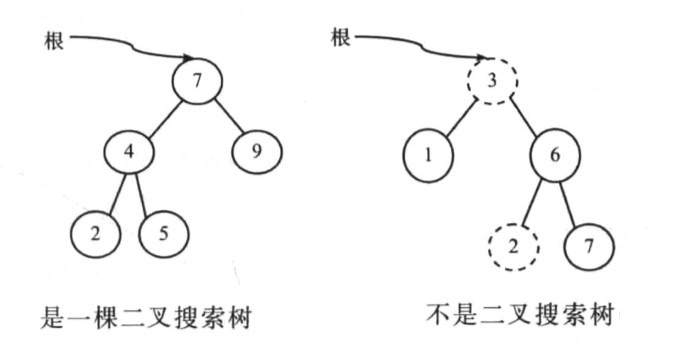
- 二叉搜索树
二叉查找树是一棵二叉树、其结点含有comparable类型的对象,并遵循以下规则:
- 结点中的数据大于结点左子树中的所有数据。
- 结点中的数据小于结点的右子树中的所有数据。
- 左子树和右子树也都必须是二叉查找树
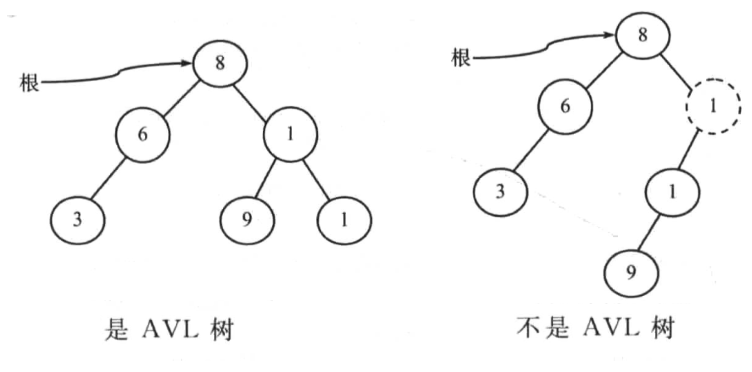
- 平衡二叉查找树(AVL 树)
是平衡树和二叉搜索树的结合
在HB(k)中,如果k=1,那么这样的二叉搜索叫做AVL树。即一棵AVL树是带有平衡条件的二叉搜索树。 左子树和右子树的高度最多不能超过1
- 红黑色
在红黑树中,每个结点关联一个额外的属性:红色或者黑色中的一种颜色。
定义:红黑树是一棵满足以下性质的二叉搜索树:
- 根结点是黑色
- 每个叶子结点是黑色
- 红色结点的孩子结点是黑色
1.3 满树(满二叉树)或完全树(完全二叉树)的高度
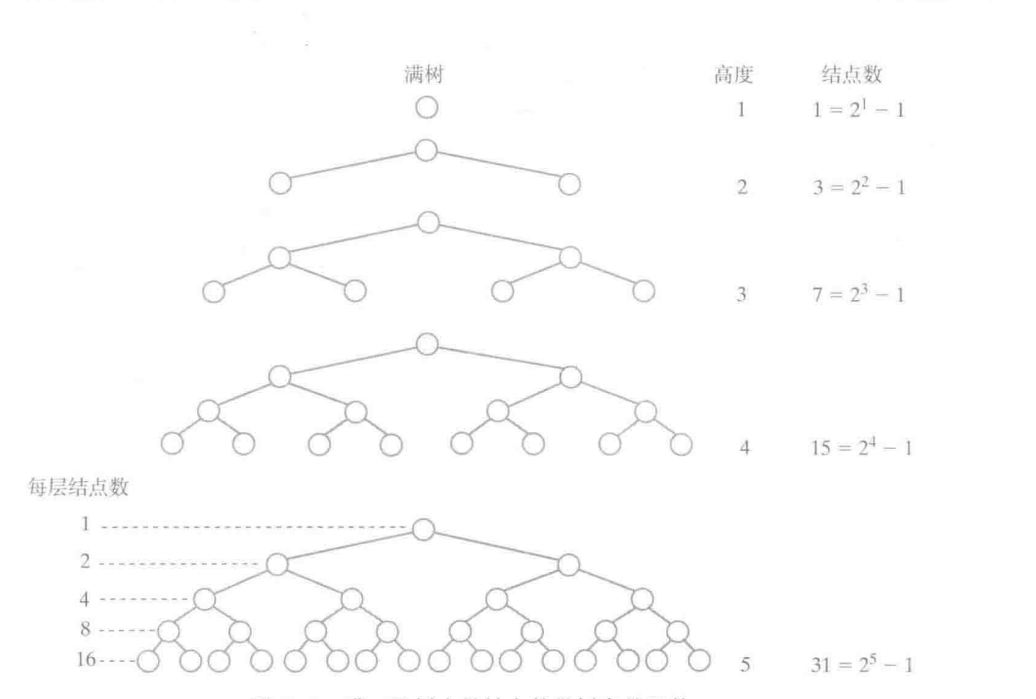 其中h是树的高度,如果满树的结点树为n,则有
其中h是树的高度,如果满树的结点树为n,则有
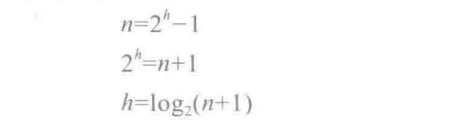
即含有n个结点的满树的高度是 log2(n+1)。含n个结点的完全树的高度是对 log2(n+1)向上取整。
含有n个结点的完全二叉树或满二叉树的高度是对log2(n+1)向上取整
1.4 其他、 二叉树的应用
- 编译器中的表达式
- 用于数据压缩算法中哈弗曼编码树
- 二叉搜索树(查找树)BST
- 优先队列(PQ)
……
1.5 二叉树的结构

为了简单起见,数据设定为整数
//java语言描述
public class BinaryTreeNode {private int data;private BinaryTreeNode leftTree;private BinaryTreeNode rightTree;……
}
1.6 二叉树的操作
- 基本操作
- 插入
- 删除
- 查找
- 遍历
- 辅助操作
- 树大小
- 树高
- 树最大层
- 给定两个或多个节点,找最近公共祖先
……
二 、树的遍历
2.1 二叉树的遍历
为了对树结构进行处理,需要一种机制来遍历树中的结点。在遍历过程中,每个结点只能被处理一次,但可以被访问多次。
- 前序遍历/先序遍历:
在访问根的子树之前访问根。然后访问根的左子树中所有的结点,再访问根的右子树中的所有结点。
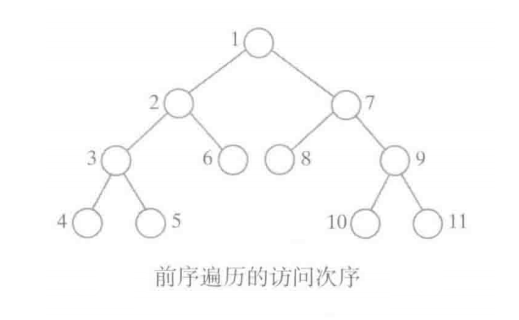
递归方式
public static void preOrder(BinaryTreeNode root) {if(null != root) {System.out.print(root.getData() + " ");preOrder(root.getLeftTree());preOrder(root.getRightTree());}}
非递归方式
为了模拟递归:首先处理当前结点,在遍历左子树之前,把当前结点保留到栈中,当遍历完左子树后,将该元素出栈,然后找打其右子树进行遍历。直到栈为空为止。
public static void preOrderNonRecursive(BinaryTreeNode root) {if(null == root) {return;}Stack<BinaryTreeNode> s = new Stack<BinaryTreeNode>(); // FILOwhile (true) {while (null != root) {System.out.print(root.getData() + " ");s.push(root);root = root.getLeftTree();}if(s.isEmpty()) {break;}root = s.pop();root = root.getRightTree();}}
- 中序遍历:
在中序遍历中,根结点的访问在两棵子树的遍历中间完成。
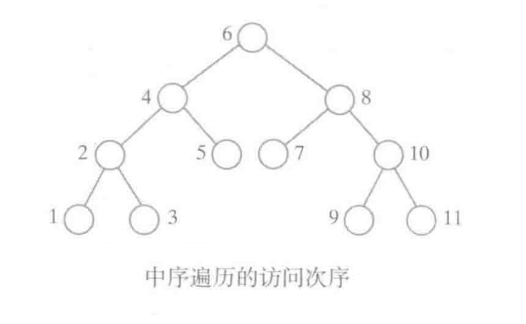
递归方式:
public static void inOrder(BinaryTreeNode root) {if(null != root) {inOrder(root.getLeftTree());System.out.print(root.getData() + " ");inOrder(root.getRightTree());}
}
非递归方式:
非递归中序遍历类似前序遍历。唯一区别是,首先要移动到结点的左子树,完成左子树的遍历后,再将结点出栈进行处理。
public static void inOrderNonRecursive(BinaryTreeNode root) {if(null == root) return;Stack<BinaryTreeNode> stack = new Stack<BinaryTreeNode>();while (true) {while (null != root) {stack.push(root);root = root.getLeftTree();}if(stack.isEmpty()) return;BinaryTreeNode node = stack.pop();System.out.print(node.getData() + " ");root = node.getRightTree();}}
- 后序遍历:
访问二叉树的根的子树中的结点之后访问树的根
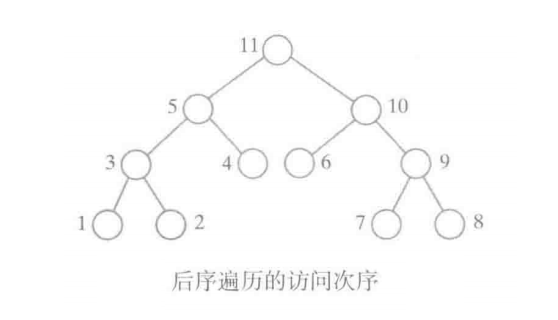
递归方式:
public static void postorder(BinaryTreeNode root) {if(null != root) {postorder(root.getLeftTree());postorder(root.getRightTree());System.out.print(root.getData() + " ");}}
非递归方式:
①:前序、中序遍历中,当元素出栈后就不需要再次访问该结点了,但是后序遍历中,每个结点需要访问两次。
②:当从栈中出栈一个元素时,检查这个元素与栈顶元素的右子树是否相同。如果相同,则说明已经完成了左、右子树的遍历。此时,只需要再将栈顶元素出栈一次病输出该结点数据即可。
public static void postOrderNonRecursive(BinaryTreeNode root) {if(null == root) return;Stack<BinaryTreeNode> stack = new Stack<>();while (true) {if (null != root) {stack.push(root);root = root.getLeftTree();} else {if(stack.isEmpty()) {return;}else {if(null == stack.peek().getRightTree()) {root = stack.pop();System.out.print(root.getData() + " ");if(!stack.isEmpty() && root == stack.peek().getRightTree()) {//左右子树遍历完成System.out.println(stack.peek().getData() + " ");stack.pop();if(stack.isEmpty()) {break;}}root = null;} else {//exists the right subtreeroot = stack.peek().getRightTree();stack.peek().setRightTree(null);}}}}}- 层序遍历:
从根开始,每次访问一层中的结点。在同一层中,从左至右访问。
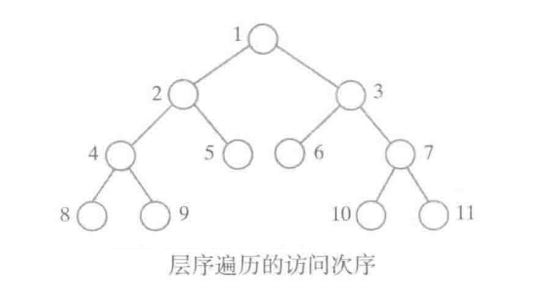
层序遍历需要借助队列来完成
public static void levelOrder(BinaryTreeNode root) {if(null == root) return;Queue<BinaryTreeNode> queue = new ArrayDeque<>();queue.add(root);BinaryTreeNode temp = null;while (!queue.isEmpty()) {temp = queue.poll();//处理当前结点System.out.print(temp.getData() + " ");if(null != temp.getLeftTree()) {queue.add(temp.getLeftTree());}if(null != temp.getRightTree()) {queue.add(temp.getRightTree());}}}
广度优先遍历:层序遍历是广度优先遍历的示例
深度优先遍历:前序遍历是深度优先遍历的示例
2.2一般树的遍历
一般树的遍历有层序、前序和后序、对一般树而言,中序遍历不好定义。
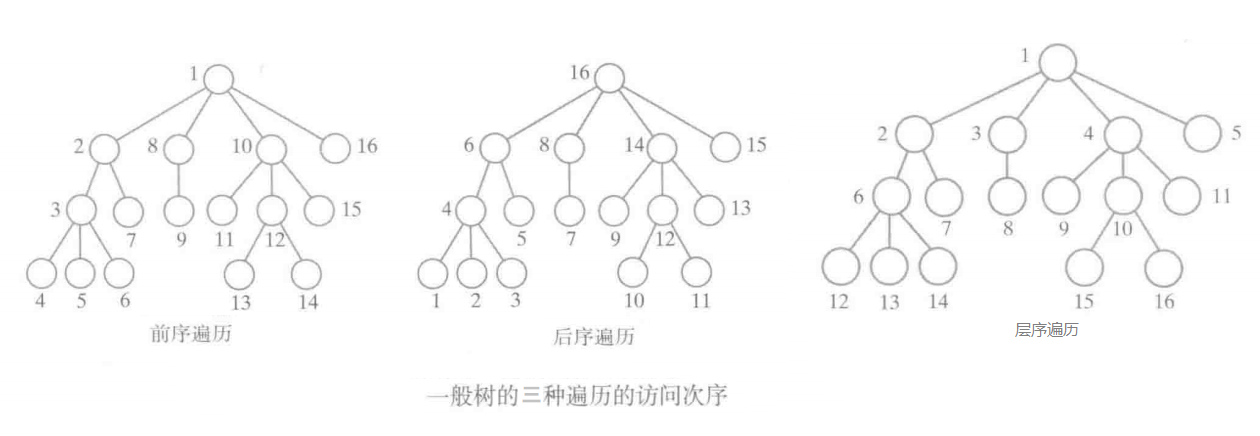
三、树的示例
一些使用树来组织数据的示例。
3.1 表达式树
可以用二叉树来表示其运算符为二元运算符的代数表达式。孩子的次序要与操作树的次序想匹配。这样的二叉树称为表达式树。
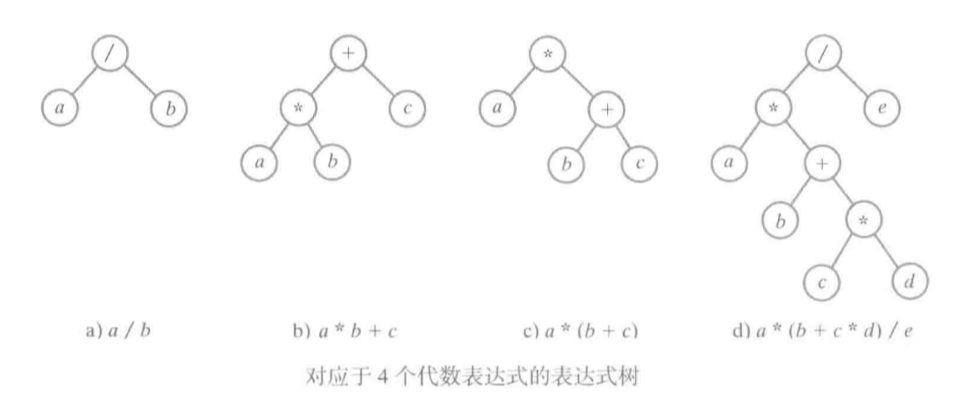 事实上,不需要括号,树也能得到表示中的运算符的次序。代数表达式有不同的写法。正常书写的表达式,即每个二元运算符出现在两个操作数的中间,称为中缀表达式。前缀表达式将每个运算符都放在其两个操作的前面,后缀表达式将每个运算符都放在其两个操作数的后面。
事实上,不需要括号,树也能得到表示中的运算符的次序。代数表达式有不同的写法。正常书写的表达式,即每个二元运算符出现在两个操作数的中间,称为中缀表达式。前缀表达式将每个运算符都放在其两个操作的前面,后缀表达式将每个运算符都放在其两个操作数的后面。
3.2 二叉查找树 / 二叉搜索树
二叉查找树是一棵二叉树、其结点含有comparable类型的对象,并遵循以下规则:
- 结点中的数据大于结点左子树中的所有数据。
- 结点中的数据小于结点的右子树中的所有数据。
- 左子树和右子树也都必须是二叉查找树

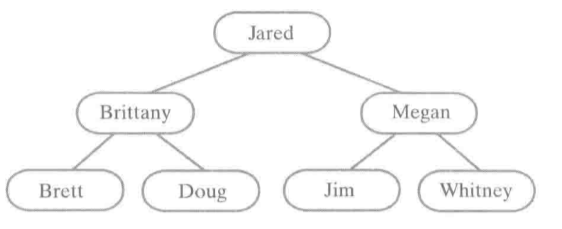
例如:字符串二叉查找树、Jared大于Jared的左子树中的所有名字,但小于Jared的右子树中的所有名字。
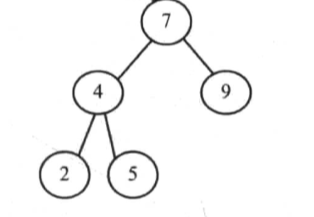
下面是也是一棵二叉查找树
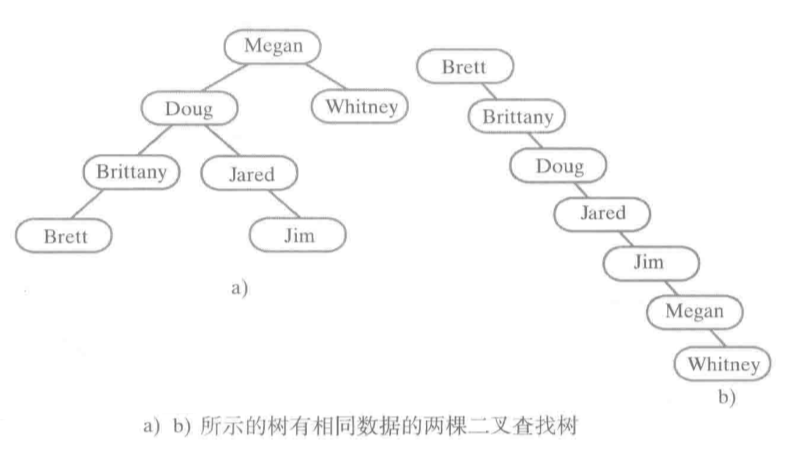
注意: 上面二叉查找树的定义,隐含表明树中的所有项都是不同的。但允许树中有重复的值
二叉查找树的形态是不唯一的。即对同样的一组数据,可以组成几棵不同的二叉查找树。例如:
3.3 堆
堆(heap) 是其结点含有 Comparable对象的一棵完全二叉树,且满足以下条件:每个结点的对象不小于(或不大于)其后代的对象。 在最大堆中,结点中的对象大于或等于其后代的对象。 在最小堆中,关系是小于或等于。
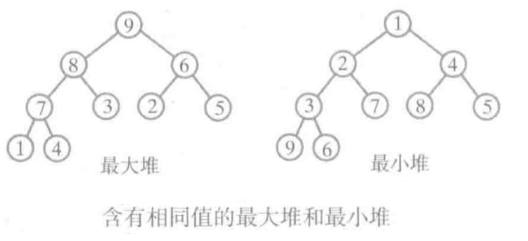 最大/小堆的任何结点的子树仍然是最大/小堆。
最大/小堆的任何结点的子树仍然是最大/小堆。
可以用堆实现优先队列
小结
本篇是对树的一个入门,讲解了树的一些基本概念、并对二叉树的三种遍历做了全面的介绍,给出了java描述。后面讲解了一些其他平衡树的知识,也给出了一些树的示例。
参考
- 《数据结构与算法经典问题解析-Java语言描述》
- 《数据结构与抽象Java语言描述第4版》
- 参考 【https://xiaozhuanlan.com/topic/7189032546】