目录
- 快速定位元组内容
- 对字典进行排序
- json的获取(dumps,dump,loads,load)
- 查找字典中相同的key
- 统计列表中元素的个数
- 字典按输入顺序输出
- 历史记录的存储
- 对有多个分割符的字符串进行分割
- 对文件中的时间格式进行转换
- 字符串的居中,左右对齐
- 列表并行/串行计算
- 字符串判断是否是空格
- 读取系统下文件并判断文件大小
- 对文件进行分类处理
- csv转换为xml文件
- 年龄计算
- 计算任意日期前n天的日期
- 计算日期范围内的所有日期
- 计算n天前同比数据
- 判断指定日期格式
- 正则提取邮箱地址
- 正则提取文档内容并分组
- 隐藏文本中的手机号
- 提取文章最多的几个名词
快速定位元组内容
元组在使用时,其中的每一个值都有其特定的含义,此时我们可以针对其元素设定一个数值常量,即命名的方式,方便我们实现快速检索
法一:
#假定一个元组
student = ('john',4,12,'math',89)
#赋予数值常量
name,clas,age,subject,score=range(5)
#检索元素
student[name]
法二:
这种方法我们需要使用的Python的内置库collections中的namedtuple。该方法可以帮助我们对元组内容进行命名。
collections.namedtuple(
typename, field_names, *, rename=False, defaults=None, module=None)
typename:表示这个子类的名字,类似于Java、Python中的类名;
field_names:一个字符串列表
from collections import namedtuple
stu = namedtuple('Student',['name','clas','age','subject','score'])
s = stu('john',4,12,'math',89)
s.name
对字典进行排序
在对字典进行排序时,首先我们需要根据字典的key还是value进行排序,进而转换为相应的元组形式,使用sorted函数进行排序。sorted默认是按照第一个元素进行升序排序(reverse=False)
#创建一个字典用于测试。对学生的分数进行排序
from random import randint
students = {'stu%s'%i:randint(60,100) for i in range(6)}
转换为元组,提供以下几种方式:
方法一
#列表推导式
s1 = [(v,k) for k,v in students.items()]
sorted(s1,reverse = True)
方法二
或者使用zip函数,转换为元组类型:
sorted(list(zip(students.values(),students.keys())))
指定元素进行排序
使用lambda表达式,可以帮助我们按照需要的值进行排序操作
s2 = [(k,v) for k,v in students.items()]
sorted(s2,key=lambda item:item[1],reverse=True)
生成排名
排名的生成我们需要用到enumerate函数,返回的是当前列表下每个元素的索引和值,进而我们可以对排序后的列表按其索引得出排名。
sort = {}
#指出下标从1开始
for i,(k,v) in enumerate(students,1):sort[i]=(k,v)
json的获取(dumps,dump,loads,load)
import json
data = {'name' : 'zz','age' : 100,
}
# dumps:将python对象编码成Json字符串。
# indent: 每行缩进N个字符
j1 = json.dumps(data,indent=2)
print(f'dumps:值类型为{type(j1)}')# loads:将Json字符串解码成python对象
j2 = json.loads(j1)
print(f'loads:值类型为{type(j2)}')#dump:将python中的对象转化成json储存到文件中
with open('j.json','w') as file:json.dump(data,file)
file.close()#load:将文件中的json的格式转化成python对象提取
with open('j.json','r') as file2:j3 = json.load(file2)
file2.close()
查找字典中相同的key
map():map(function,iterable,…)。第一个参数 function 以参数序列中的每一个元素调用 function 函数,返回包含每次 function 函数返回值的新列表
reduce():reduce(function, iterable[, initializer])。函数会对参数序列中元素进行累积。
函数将一个数据集合(链表,元组等)中的所有数据进行下列操作:用传给 reduce 中的函数 function(有两个参数)先对集合中的第 1、2 个元素进行操作,得到的结果再与第三个数据用 function 函数运算,最后得到一个结果。从from functools import reduce导入使用
from random import randint,sample
from functools import reduce
d1 = {k:randint(1,4) for k in sample('abcdefghi',randint(3,6))}
d2 = {k:randint(1,4) for k in sample('abcdefghi',randint(3,6))}
d3 = {k:randint(1,4) for k in sample('abcdefghi',randint(3,6))}
#方法一:
[k for k in d1 if k in d2 and k in d3]
#方法二:
dl = [d1,d2,d3]
r = [k for k in dl[0] if all(map(lambda d:k in d,dl[1:]))]s1 = d1.keys()
s2 = d2.keys()
# print(s1 & s2)#&:取交集
a = reduce(lambda a,b:a&b,map(dict.keys,dl))
print(a)
统计列表中元素的个数
这里推荐使用Counter进行统计计算
from random import randint
data = [randint(0,10) for _ in range(20)]#生成字典
d = dict.fromkeys(data,0)#方法一:迭代统计
for x in data:d[x] += 1
#统计出最多的前三个值
r = sorted([(v,k) for k,v in d.items()],reverse=True)[:3]#方法二:
import heapq
#统计出最多的前三个值
r2 = heapq.nlargest(3,((v,k) for k,v in d.items()))
# print(r2)
#方法三:
from collections import Counter
count = Counter(data)
print(count.most_common(3))字典按输入顺序输出
Python 3.7之前,我们在字典插入数据后,输出数据时会打乱数据,此时我们可以使用collections.OrderedDict来保证我们字典输出有序
from collections import OrderedDict
from random import randint
students = {'stu%s'%i:randint(60,100) for i in range(6)}stu_sort = sorted(list(zip(students.values(),students.keys())),reverse=True)
sort_od = OrderedDict()
for i,item in enumerate(stu_sort,1):sort_od[i] = item
在实现排名后,如果我们想查看第N名的人是谁,除了常规的使用get外,还可以使用以下方式:
from itertools import islice
sort = {}
for i,(k,v) in enumerate(stu_sort,1):sort[v] = idef query_rk(dict,a,b=None):a -= 1if b is None:b = a + 1return list(islice(dict,a,b))print(sort)
print(query_rk(sort,1))
历史记录的存储
在使用一些命令的时候,可以使用collections.deque来帮助我们存储我们使用过的指令
from collections import deque #存入内存q = deque([],5) #创建一个空列表,容量为5,默认无限大
# q.append() #从右端入队
# q.appendleft()#从右端入队
# q.pop()#从右端出队
# q.popleft()#从右端出队
q.append(1)
q.append(2)
q.append(3)
q.append(4)
q.append(5)
# print(q)
q.append(6)
q.append(7)
# print(q)import pickle #存入磁盘活文件
pickle.dump(q,open('save.pkl','wb')) #pkl文件需要二进制写入q2 = pickle.load(open('save.pkl','rb')) #读取文件
print(q2)
对有多个分割符的字符串进行分割
例如下列字符串,我们需要根据不同的字符把它分割开来,可以使用以下几种方式(在有多个分隔符时推荐使用方法三):
ab:cd|efg|hi,jk|mn\tqad:rst,uwc\ttxf
方法一:
我们可以采用传统的str.split方式,对字符串进行分割,不过这种情况,会生成一个多维数组,此时为了方便使用需要把它降维成一维数组。我们可以使用extend或者是sum进行操作。extend会对插入进来的列表进行展开,生成一个一维的列表。例如
t = []
t.extend([1,2])
# print(t)
t.extend([3,4])
# print(t)
t.extend([5,6])
# print(t)
具体实现:
def my_split(s,seps):res = [s]for sep in seps:t = []list(map(lambda s:t.extend(s.split(sep)),res))res = treturn res
使用sum时,需要输入一个空列表:
sum([ss.split('|') for ss in s.split(':')], [])
方法二:
借用reduce操作
from functools import reducer = reduce(lambda l,sep:sum(map(lambda s:s.split(sep),l),[]),',:|\t',[s])
print(r)
my_split2 = lambda s,seps:reduce(lambda l,sep:sum(map(lambda s:s.split(sep),l),[]),',:|\t',[s])
print(my_split2(s, ',:|\t'))
方法三:
使用正则分割。
import re
r2 = re.split('[:,|\t]+',s)
在只需要对一个分割符进行操作时不建议使用正则,会降低效率,建议直接使用str.split
对文件中的时间格式进行转换
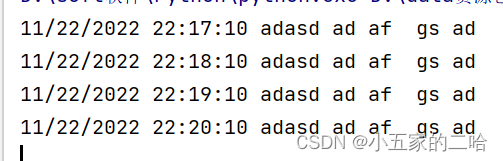
如下列文本,找出其中的时间格式,并转换成11/22/2022 22:17:10形式。
2022-11-22 22:17:10 adasd ad af gs ad
2022-11-22 22:18:10 adasd ad af gs ad
2022-11-22 22:19:10 adasd ad af gs ad
2022-11-22 22:20:10 adasd ad af gs ad
使用正则表达式进行修改
import re
#读取文件
f1 = open('./data.log','r')
f2 = f1.read()
#1.r:避免转义失败
#2.括号():分组,每组组号从1开始
#3.\2/\3/\1:每组的输出位置
print(re.sub(r'(\d{4})-(\d{2})-(\d{2})', r'\2/\3/\1', f2))
字符串的居中,左右对齐
s = 'abc'
#左对齐
print(s.ljust(10))
#右对齐
print(s.rjust(10))
print(s.rjust(10,'*'))
print(s.center(10,'*'))
列表并行/串行计算
并行计算
生成测试数据,分别为语文、数学、英语三门课的成绩,总共20位学生,现在要计算每位学生的成绩之和。
from random import randint
chinese = [randint(60,100) for _ in range(20)]
math = [randint(60,100) for _ in range(20)]
english = [randint(60,100) for _ in range(20)]
我们可以使用zip函数,来汇总每位学生的分数,然后进行计算。
list(zip(chinese,math,english))
#方法一
[sum(s) for s in zip(chinese,math,english)]
#方法二
list(map(sum,zip(chinese,math,english)))
#方法三
list(map(lambda s1,s2,s3:s1+s2+s3,chinese,math,english))
#方法四:当我们不知道需要传几个参数时,可以使用*args
list(map(lambda *args:args,chinese,math,english))
串行计算
需要把多个数组合并为一个
c1 = [randint( 60,100) for _ in range(20)]
c2 = [randint( 60,100) for _ in range(20)]
c3 = [randint( 60,100) for _ in range(20)]
c4 = [randint( 60,100) for _ in range(20)]
from itertools import chain
list(chain(c1,c2,c3,c4))

字符串判断是否是空格
返回布尔值
str.isspace()
读取系统下文件并判断文件大小
import os
for file in os.listdir('.'):#判断是否是文件if os.path.isfile(file):#判断文件大小s = os.path.getsize(file)print(s)
对文件进行分类处理
需要用到os和shutil库。需要用到的方法包括:
os.path.isfile:判断当前路径下的是否是一个文件;
os.path.splitext:对文件按照后缀进行分割,类似于file.split(‘.’,1)。返回一个列表;
os.path.isdir:判断当前路径下的是否是一个文件夹;
os.mkdir:创建指定路径下的文件夹
shutil.move:移动文件到指定路径下
import os
import shutil
def class_file(input_path):for file in os.listdir(input_path):if os.path.isfile(f'{input_path}/{file}'):#对文件按照后缀进行分类,返回一个列表[file_name,suffix]suf = os.path.splitext(file)[1]#去掉后缀前的'.'suf = suf[1:]#判断是否有分类的文件夹,没有则新建if not os.path.isdir(f'{input_path}/{suf}'):os.mkdir(f'{input_path}/{suf}')source_path = f'{input_path}/{file}'output_path = f'{input_path}/{suf}/{file}'#把文件移动各自分类目录下shutil.move(source_path,output_path)
csv转换为xml文件
from xml.etree.ElementTree as et
import csvdef csv_to_xml(csv_path,xml_path):with open(csv_path) as f:reader = csv.reader(f)#获取首行标题header = next(reader)#设置根标签root = et.Element('Data')root.text = '\n\t'`在这里插入代码片`root.tail = '\n'#遍历for row in reader:for tag,text in zip(header,row):e = et.SubElement(root,tag)e.text = texte.tail = '\n\t\t'et.ElementTree(root).write(xml_path,encoding='utf-8')
年龄计算
from datetime import datetime
birthday = '2000-01-01'
#转换为日期格式
birthday_date = datetime.strptime(birthday,'%Y-%m-%d')
#获取当前日期
current_datetime = datetime.now()
#日期相减
minus_datetime = current_datetime - birthday_date
age = round(minus_datetime.days/365)
计算任意日期前n天的日期
from datetime import datetime,timedelta
def get_diff_days(pdate,days):#对输入的日期转换为 日期格式pdate_obj = datetime.strptime(pdate,'%Y-%m-%d')#计算间隔日期time_gap = timedelta(days=days)#计算前n天的日期pdate_result = pdate_obj - time_gapreturn pdate_result.strftime('%Y-%m-%d')
计算日期范围内的所有日期
from datetime import datetime,timedelta
def get_date_range(begin_date,end_date):date_list = []while begin_date <= end_date:date_list.append(begin_date)begin_date_obj = datetime.strptime(begin_date,'%Y-%m-%d')days_timedate = timedelta(days = 1)begin_date = (begin_date_obj + days_timedate).strftime('%Y-%m-%d')return date_list
计算n天前同比数据
from datetime import datetime,timedelta
def get_diff_days(date,days):curr_date = datetime.strptime(date,'%Y-%m-%d')time_delta = timedelta(days=-days)return (curr_date + time_delta).strftime('%Y-%m-%d')def week_rate(data:dict,days):for date,number in data.items():date_diff = get_diff_days(date,days)sale = data.get(date_diff,0)if sale == 0:return (date,0)else:week_diff = round((number - sale)/sale,2)return week_diff
判断指定日期格式
这里以yyyy-mm-dd格式为例:
import re
def date_type(date):#返回是否匹配成功。未匹配上的会返回Nonereturn re.match("\d{4}-\d{2}-\d{2}",date) is not None
正则提取邮箱地址
#从文本中提取邮箱地址
content = """QQ邮箱是:1234567@qq.com163邮箱是:123456@163.cn其他:lds123@dd.net
"""
import repattern = re.compile(r"""
[a-zA-Z0-9_-]+
@
[a-zA-Z0-9]+
\.
[a-zA-Z]{2,4}
""",re.VERBOSE) #VERBOSE:支持多行编写results = pattern.findall(content)
for result in results:print(result)
正则提取文档内容并分组
content = """
小明上街买菜
买了1斤黄瓜花了8元
买了2斤葡萄花了12.4元
买了3斤百次啊花了5.4
"""for line in content.split("\n"):#括号用来分组pattern = r'(\d)斤(.*)花了(\d+(\.\d+)?)元'match = re.search(pattern,line)if match:print(match.groups())
隐藏文本中的手机号
phones = """
小明的手机号是13568893468
"""
pattern = r"(1[3-9])\d{9}"#\1:正则的第一个分组
print(re.sub(pattern, r"\1******", phones))
提取文章最多的几个名词
posseg方法会对中文文本进行分词,并返回其属性。
import pandas as pd
import jieba.posseg as possegdef get_name(txt_path):with open(txt_path,encoding='utf-8') as file:content = file.read()words = []for word,flag in posseg.cut(content):# flag:显示文子的属性,例如:李明 nr,表示名词;喜欢 v,表示动词if flag == 'nr':words.append(word)df = pd.Series(words).value_counts()[:10]return df

![从客户端中检测到有潜在危险的 request.form值[解决方法]](http://blog.unvs.cn/wp-content/uploads/2014/04/request.jpg)