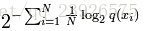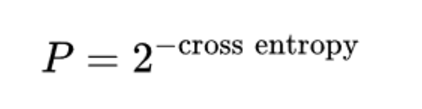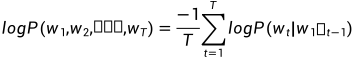本篇内容翻译自Speech and Language Processing. Daniel Jurafsky & James H. Martin.
链接:https://web.stanford.edu/~jurafsky/slp3/
不愧是自然语言处理领域的圣经,读起来流畅自然,以后还是要多读经典。
困惑度(Perplexity, PP)用来评估一个语言模型的好坏。
我们知道语言模型是用来计算一个句子的概率,但实际中,我们不会使用原始的概率作为语言模型的度量。
1. 公式定义
给定测试集 W = w 1 w 2 . . . w N W = w_1w_2...w_N W=w1w2...wN
困惑度定义为测试集的概率的倒数,并用单词数做归一化。

使用链式法则来计算 P ( W ) P(W) P(W):

如果使用bigram模型,公式为:

词序列的条件概率越高,困惑度越低。因此,根据语言模型,最小化困惑相当于最大化测试集概率。
2. 与熵的联系
另一种理解困惑度的方式是,as the weighted average branching factor of a language
怎么理解呢?
The branching factor指的是——一种语言中,任何单词接下来可能跟着出现的单词的数目。
举一个数字识别的例子,假设在训练集与测试集中0-9出现的概率均为1/10。
把10个阿拉伯数字看作一种迷你语言,那么它的困惑度就是10。

但如果假设数字0出现的非常频繁,在一个训练集中,0出现了91词,其它数字各只出现了1次。
现在有这样一个测试集:0 0 0 0 0 3 0 0 0 0
它的困惑度肯定是比10低的,因为大部分时候下一个数字是0
尽管the branching factor仍然是10,但加权求和的结果(困惑度)会更小。
这里就能感觉到困惑度和信息论中的熵概念很相似了,概率平均分布时,熵最大。
困惑度可以理解为,如果每个时间步都根据语言模型计算的概率分布随机挑词,那么平均情况下,挑多少个词才能挑到正确的那个。
接下来回顾一下熵的公式:

如何计算包含序列W ={w0,w1,w2, . . . ,wn}.的熵?
L为一个语言,计算其中所有长度为n的有限的词序列

定义 entropy rate(看作是per-word entropy)为

但是要真正衡量一种语言的熵,需要考虑无限长的序列。

根据香农-麦克米兰- 布雷曼熵定理(Shan-non-McMillan-Breiman theorem)
如果一个语言既平稳又遍历

也就是说,我们可以取一个足够长的序列,而不是对所有可能的序列求和。
香农-麦克米兰- 布雷曼熵定理(Shan-non-McMillan-Breiman theorem)的直觉是,一个足够长的单词序列将包含许多其他较短的序列,并且这些较短的序列中的每一个都将根据它们的概率在较长的序列中重复出现。
尽管自然语言并不是stationary的,我们可以做一些简化假设,取一个非常长的输出样本,计算其average log probability来计算一些随机过程的熵。
接下来介绍交叉熵。
当我们不知道产生一些数据的实际概率分布时,交叉熵是有用的。

m,p为两个不同的概率分布,m is a model of p (i.e., an approximation to p).
根据概率分布p产生序列,但根据m对其概率的对数求和。
对一个平稳遍历过程,根据香农-麦克米兰- 布雷曼熵定理

通过采用足够长的单个序列而不是对所有可能的序列求和,就可以估计p和m的交叉熵。
又,对于任意概率分布m,有

m越精确,则交叉熵 H ( p , m ) H(p,m) H(p,m)就越接近真实熵 H ( p ) H(p) H(p)
因此可以用两者的差值来衡量一个模型有多精确。
在两个模型m1和m2之间,更精确的模型将是交叉熵较低的模型。
上文中,交叉熵被定义为一个词序列长度n趋向无穷的极限。
我们需要依靠一个固定长度(也要足够长)的序列来对交叉熵做一个估计。
在词序列W上,估计模型 M = P ( w i ∣ w i − N + 1 . . . w i − 1 ) M = P(w_i|w_{i-N+1}...w_{i-1}) M=P(wi∣wi−N+1...wi−1)的交叉熵为H(W)

最终定义perplexity of a model P on a sequence of words W 为以2为底,交叉熵估计值H(W)为幂次的值。

3. 进一步说明
使用19979个单词的词汇表,对《华尔街日报》的3800万个单词(包括句子开头的标记),分别训练了三个语言模型,然后计算困惑度。

可以发现,n-gram给我们的关于单词序列的信息越多,困惑度就越低。
困惑度的改善(内在)并不能保证NLP任务(如语音识别或机器翻译)的性能提升(外在)。
然而,因为困惑度通常与这种改进相关,所以它通常被用作对算法的快速检查。
但是,在结束模型的评估之前,模型在困惑度方面的改进应该始终通过对真实任务的端到端评估来确认。