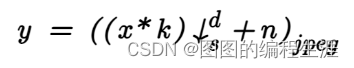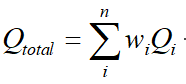目录
题目:
模型建立
题目分析
注意的小问题
计算结果
代码
模型改进和精细预测
写在最后
题目:
假设:
- 病毒正在一个居民总数为N=100,000,
的城市里扩散。在我们研究的时间段内(300天),没有新生儿出生,也没有死亡病例发生
- 所有居民按照其自身年龄,可以划分为:未成年,青壮年和中老年。根据事先统计,未成年占比为Rc=25%,青壮年占比为Ra=55%,中老年占比为Ro=20%。
- 所有居民按照其感染情况,可以划分为:健康者,潜伏者,发病者和康复者
- 病毒传播过程如下:
-
每天健康者接触到潜伏者后,根据其所在的年龄类别(未成年,青壮年和中老年)分别以概率
,
和
变为潜伏者
- 每天健康者接触到发病者后,根据其所在的年龄类别(未成年,青壮年和中老年)分别以概率
,
和
为潜伏者
- 每天所有年龄类型的潜伏者都以概率α变为发病者(α
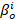 的取值范围在0.01~0.05)
的取值范围在0.01~0.05) - 每天发病者根据其所在的年龄类别(未成年,青壮年和中老年),分别以概率γc, γa和γo变为康复者
- 康复者在所研究的时间段内(300天)不再被感染和感染别人
- 在研究的时间段内(300天),每人每天接触的人数r=10,且所有人两两接触的概率相等
以上就是题目的假设,同时给出前面四十天的数据:如下图所示,一共有四十天的数据
| 发病者 | 康复者 | |||||
| 未成年 | 青壮年 | 中老年 | 未成年 | 青壮年 | 中老年 | |
| 112 | 125 | 305 | 56 | 87 | 73 | |
| 92 | 115 | 302 | 83 | 98 | 87 | |
| 79 | 110 | 309 | 102 | 114 | 106 | |
| 68 | 107 | 316 | 119 | 129 | 122 | |
| 65 | 107 | 332 | 136 | 138 | 134 | |
| 64 | 110 | 353 | 149 | 152 | 152 | |
模型建立
通过题目的分析,可以知道,这个题目要首先建立一个模型,然后根据数据进行估算回原本的参数,通过简单的查询资料,我们可以知道,关于病毒模型,网上很多,包括SI,SEI,SEIR模型等,通过对模型的分析,可以知道,这个题目比较适合SEIR模型,
于是建立SEIR模型:

说明:S,E,I,R 分别表示的是,S:易感人群,也就是健康人群, E:暴露人群,也就是潜伏者,I:患病人群,R:健康人群。
第一个公式的意思:人群当前阶段的数量是上一个阶段的数量
减去上一个阶段
人群中转换为
暴露人群的数量,
第二个公式的意思:人群的当前数量是上一个
的数量加上
阶段转换的人群,减去
转换为
的数量
第三个公式的意思:的数量是上一个阶段
的数量加上
转换为
的数量,然后减去
中康复的数量
第四个公式意思:是数量等于
阶段的数量加上
中康复的数量
注意的小问题:上面列出来的公式,只是children 未成年人的公式,其实每个年龄段都有四个一样的公式,但是都是一样的,只是下标不同,但是值得注意的是三个年龄段中的,
表示的是目前三个年龄阶段中所有的暴露人群和患病人群的总数,并不是三个年龄段各自的暴露人群和患病人群。
说明一下:这里的易感人群转换为暴露人群的公式,是一个近似是公式。他计算的是每个暴露人群碰到的易感人群的数量后转换成暴露人去的个数 + 每个患病人群加上易感人群并转换为暴露人群的数量。这个假设成立的条件是:每个暴露人群碰到一个易感易感人群,易感人群的感染率就增加,每个患病人群碰到易感易感人群,易感人群的感染概率也是增加的。换句话说,对于每个易感人群,他转换的概率是和碰到暴露人群和患病人群的数量有关系的,数量越多,感染的概率就越大。 同时,暴露人群碰到每个人的概率是相同的。患病人群碰到每个人的概率也是相同的。 这个概率不会因为前面碰到的人是什么类型的而改变。当数量很大的时候,应该是近似相等的。如果想更加具体的模型,应该是可以用C(n,m),也就是排列组合来严格计算。但是实际计算发现,N=100000的时候计算机已经计算不过来了。最后还是用了这个模型来计算。
我也曾经尝试过用其他的转换概率模型。比如说假设每个易感人群只要碰到暴露人群并且不接触患病人群,不管是碰到几个暴露人群,那么感染概率都是相同的,也就是,
和
。 每个易感人群只要是碰到患病人群,不管碰到几个患病人群,那么他的感染概率都是
,
或者是
。 也就是说。我认为碰到患病人群后的感染概率要高于碰到暴露人群,并且覆盖了碰到了暴露人群的感染概率。和碰到的数量没有关系。因为,我认为,只要碰到了暴露人群或者是患病人群,易感人群就类似于碰到了病菌了,不管是碰到多少个病菌,转换为携带者的概率都是相同的。而且患病人群的病菌要比携带者更毒一点,所以覆盖了暴露人群的病菌 但是,经过实际的检验。发现基于这个建立的模型,拟合的结果不是那么完美。所以我猜测。对于易感人群,转换为暴露人群的概率和碰到暴露人群和患病者的数量是有关系的。
以上是个人的理解,不知道自己的理解有没有问题。但是查询到网上的模型都是这个。整个模型唯一的近似的地方也就是易感人群转换为暴露人群的地方了。后面的 更加精细的模型也就是算更加准确的转移概率了!当然了,整个模型除了这个地方,其他地方都是很直白的。也没有什么好精细的建模的~~
题目分析
首先,我们可以看看我们目前已经知道什么条件,我们可以知道前面四十天的暴露人群和易感人群的每天的数量,患病人群的每天的数量,康复者的每天的数量。然后,我们分析一下,我们要求的参数,发现可以大致的分成三类
- γc, γa和γo
- α
首先,第一类的参数和其他的参数简直是没有关系。可以直接通过公式计算出来。
也是就是: 这也就可以简单的计算出来了:计算后画个图,如下:

所以可以非常容易的求出了,不管是求平均还是后面的加权求平均,都可以非常容易的计算出来。
第二个参数的求取和第三类的参数求取是关联的,如果知道第二个参数,那么其实根据现在的α 是可以计算出来每个,
,
和
,
和
的。
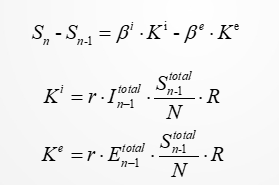
第二个参数的,和其他的参数的关系可以变成如图所示,假设我们知道了 α 那么,对于每个阶段,其实都有一个上面的方程,同时每个阶段的和
是知道的,那么我们可以获取若干个这种类似于二元一次方程的等式,那么我们就可以用最小二乘法类型的方式来计算出
,
,
和
,
和
。
所以我们可以假设一个α ,通过两个时间阶段的值,求出,
,
和
,
和
。然后预测第三个阶段的S+W的值,根据预测的结果来判断α的值预测的是不是正确的。
注意的小问题
(1)首先,我们可以基本上肯定,如果碰上患病人群的感染概率一定是大于碰上潜伏者的感染概率。所以我们在计算的时候,可以加上限制条件 。具体到Matlab公式是怎么样的嘞

我们可以改变第二项的计算是前两项的和,并且限制两个待求的参数都是大于0的,然后重新计算一下第二项系数。
(2) 通过实际的计算可以发现如果直接计算老年人群体里面的易感人群,你会发现,易感人群是波动的,同时在后期,比如33天后,数量居然会回升,如下图所示,下图中蓝色线条和橙色线条是易感人群,红色和蓝色是易感人群的一阶微分的负数。这个回升显然是非常不合理的。这样计算出来的一定是会有负数的。这个地方,我不知道的处理方式是用多阶的线性方程模拟一下,近似于进行了滤波操作,同时,计算
的区间只选择中间的阶段,因为中间的阶段看上要正常很多。应该有其他的处理方式,比如说,剔除掉一阶微分中为符号反常的数据。 我这里只是简单的多阶拟合一下,然后取中间的比较好的数据段。

其他的年龄段的计算还是比较正常的,但是应该也可以shaxuan
计算结果
最终的计算结果和仿真如下图所示,其中α=0.434 。大概率是比较接近的

然后预测后面的人数如下图所示:

代码
代码如下:
clc;
clear all;r = 10;exc = xlsread('Data.xlsx');
Ic = exc(:,1);
Ia = exc(:,2);
Io = exc(:,3);Rc = exc(:,5);
Ra = exc(:,6);
Ro = exc(:,7);TRc=diff(Rc)./Ic(1:39);
gamma_c = mean(TRc(10:39));TRa=diff(Ra)./Ia(1:39);
gamma_a = mean(diff(Ra)./Ia(1:39));TRo=diff(Ro)./Io(1:39);
gamma_o = mean(TRo(10:39));% figure(1);
% plot([1:39],TRc, [1:39],TRa, [1:39],TRo);
% title('三个阶段的gamma');%遍历 a 求最小均方根误差的值
N=100000;
NumberOfDivition=1000;
RMS = zeros(NumberOfDivition,3);
a=0.01:(0.05-0.01)/NumberOfDivition:0.05;
beta_c_list=zeros(NumberOfDivition,2);
beta_a_list=zeros(NumberOfDivition,2);
beta_o_list=zeros(NumberOfDivition,2);
for k =1:NumberOfDivitionSEc=20000 - Ic - Rc;SEa=20000 - Ia - Ra;SEo=20000 - Io - Ro;Ec=-diff(SEc)/a(k);Ea=-diff(SEa)/a(k);Eo=-diff(SEo)/a(k);Sc = 25000 - Ic(1:39) - Rc(1:39) - Ec;Sa = 55000 - Ia(1:39) - Ra(1:39) - Ea;So = 20000 - Io(1:39) - Ro(1:39) - Eo;So_old=So;p = polyfit([1:39]' ,So, 4); %p为拟合后的多项式系数So=polyval(p, [1:39]' );S_all =Sc +Sa +So;E_all = Ec + Ea + Eo;I_all = Ic + Ia + Io;R_all =Rc+Ra+Ro;% figure
% plot([1:39]' , So, [1:39]', Eo(1:39), 'linewidth',2);ttc = 10*Sc.*I_all(1:39)./N; ssc = 10*(Sc).*E_all(1:39)./N; xc=[ssc(1:38),ttc(1:38)];tta = 10*Sa.*I_all(1:39)./N; ssa = 10*(Sa).*E_all(1:39)./N; xa=[ssa(1:38),tta(1:38)];tto = 10*So.*I_all(1:39)./N; sso = 10*(So).*E_all(1:39)./N; xo=[sso(1:38),tto(1:38)];Yc = -diff(Sc);Ya = -diff(Sa);Yo = -diff(So);Yo_old=-diff(So_old);
% plot([1:39],So, [1:38], Yo,[1:39],So_old, [1:38], Yo_old,'linewidth',2);
% title('群体:老年人中的易感人群');fun=inline('c(1).*x(:,1)+(c(1)+c(2)).*x(:,2)','c','x');beta_c = lsqcurvefit(fun,[0.01 0.01],xc(10:35,:),Yc(10:35),[0,0],[0.5,0.5]);beta_a = lsqcurvefit(fun,[0.01 0.01],xa(10:35,:),Ya(10:35),[0,0],[0.5,0.5]);beta_o = lsqcurvefit(fun,[0.01 0.01],xo(5:30,:),Yo(5:30),[0,0],[0.5,0.5]);beta_c(2)=beta_c(1)+beta_c(2);beta_a(2)=beta_a(1)+beta_a(2);beta_o(2)=beta_o(1)+beta_o(2);beta_c_list(k,1)=beta_c(1); beta_c_list(k,2)=beta_c(2);beta_a_list(k,1)=beta_a(1); beta_a_list(k,2)=beta_a(2);beta_o_list(k,1)=beta_o(1); beta_o_list(k,2)=beta_o(2);%testY = beta_c(1).*E_all(1:38) + beta_c(2).*I_all(1:38);%plot([1:38],Yc,[1:38], testY)%初值Ic_diff = diff(Ic);Ia_diff = diff(Ia);Io_diff = diff(Io);Ic_ans = Ic(1);Ia_ans = Ia(1);Io_ans = Io(1);Rc_ans = Rc(1);Ra_ans = Ra(1);Ro_ans = Ro(1);Ec_ans = (Ic_diff(1) + gamma_c.*Ic(1))./a(k);Ea_ans = (Ia_diff(1) + gamma_a.*Ia(1))./a(k);Eo_ans = (Io_diff(1) + gamma_o.*Io(1))./a(k);Sc_ans = 25000 - Ic_ans - Rc_ans - Ec_ans;Sa_ans = 55000 - Ia_ans - Ra_ans - Ea_ans;So_ans = 20000 - Io_ans - Ro_ans - Eo_ans;for i = 2:40Ic_ans(i) = Ic_ans(i-1) + a(k) * Ec_ans(i-1) - gamma_c * Ic_ans(i-1);Ia_ans(i) = Ia_ans(i-1) + a(k) * Ea_ans(i-1) - gamma_a * Ia_ans(i-1);Io_ans(i) = Io_ans(i-1)+ a(k) * Eo_ans(i-1)-gamma_o * Io_ans(i-1);Rc_ans(i) = Rc_ans(i-1) + gamma_c*Ic_ans(i-1);Ra_ans(i) = Ra_ans(i-1) + gamma_a*Ia_ans(i-1);Ro_ans(i) = Ro_ans(i-1) + gamma_o*Io_ans(i-1);Ec_ans(i) = Ec_ans(i-1) + r * Sc_ans(i-1)/100000*( beta_c(1)*(Ec_ans(i-1) + Ea_ans(i-1) + Eo_ans(i-1)) + beta_c(2)*(Ic_ans(i-1)+Ia_ans(i-1)+Io_ans(i-1)) ) - a(k)*Ec_ans(i-1);Ea_ans(i) = Ea_ans(i-1) + r * Sa_ans(i-1)/100000*( beta_a(1)*(Ec_ans(i-1) + Ea_ans(i-1) + Eo_ans(i-1)) + beta_a(2)*(Ic_ans(i-1)+Ia_ans(i-1)+Io_ans(i-1)) ) - a(k)*Ea_ans(i-1);Eo_ans(i) = Eo_ans(i-1) + r * So_ans(i-1)/100000*( beta_o(1)*(Ec_ans(i-1) + Ea_ans(i-1) + Eo_ans(i-1)) + beta_o(2)*(Ic_ans(i-1)+Ia_ans(i-1)+Io_ans(i-1)) ) - a(k)*Eo_ans(i-1);Sc_ans(i) = 25000 - Ic_ans(i) - Rc_ans(i) - Ec_ans(i);Sa_ans(i) = 55000 - Ia_ans(i) - Ra_ans(i) - Ea_ans(i);So_ans(i) = 20000 - Io_ans(i) - Ro_ans(i) - Eo_ans(i);end% figure
% plot([1:40],Ic,[1:40],Ic_ans(1:40));
% title('人群:青年')
% figure
% plot([1:40],Ia,[1:40],Ia_ans(1:40));
% title('人群:成年人')
% figure
% plot([1:40],Io,[1:40],Io_ans(1:40));
% title('人群:老年人')%均方根误差RMS(k,1) = sum(sqrt((Ic_ans-Ic').^2))/40;RMS(k,2) = sum(sqrt((Ia_ans-Ia').^2))/40;RMS(k,3) = sum(sqrt((Io_ans-Io').^2))/40;
end% 找到最小误差点
RMS_mean = (RMS(:,1)+RMS(:,2)+RMS(:,3))/3;
%RMS_mean = RMS(:,1);
k = find(RMS_mean == min(RMS_mean));
for i = 2:300Ic_ans(i) = Ic_ans(i-1) + a(k) * Ec_ans(i-1) - gamma_c * Ic_ans(i-1);Ia_ans(i) = Ia_ans(i-1) + a(k) * Ea_ans(i-1) - gamma_a * Ia_ans(i-1);Io_ans(i) = Io_ans(i-1)+ a(k) * Eo_ans(i-1)-gamma_o * Io_ans(i-1);Rc_ans(i) = Rc_ans(i-1) + gamma_c*Ic_ans(i-1);Ra_ans(i) = Ra_ans(i-1) + gamma_a*Ia_ans(i-1);Ro_ans(i) = Ro_ans(i-1) + gamma_o*Io_ans(i-1);Ec_ans(i) = Ec_ans(i-1) + r * Sc_ans(i-1)/100000*( beta_c_list(k,1)*(Ec_ans(i-1) + Ea_ans(i-1) + Eo_ans(i-1)) + beta_c_list(k,2)*(Ic_ans(i-1)+Ia_ans(i-1)+Io_ans(i-1)) ) - a(k)*Ec_ans(i-1);Ea_ans(i) = Ea_ans(i-1) + r * Sa_ans(i-1)/100000*( beta_a_list(k,1)*(Ec_ans(i-1) + Ea_ans(i-1) + Eo_ans(i-1)) + beta_a_list(k,2)*(Ic_ans(i-1)+Ia_ans(i-1)+Io_ans(i-1)) ) - a(k)*Ea_ans(i-1);Eo_ans(i) = Eo_ans(i-1) + r * So_ans(i-1)/100000*( beta_o_list(k,1)*(Ec_ans(i-1) + Ea_ans(i-1) + Eo_ans(i-1)) + beta_o_list(k,2)*(Ic_ans(i-1)+Ia_ans(i-1)+Io_ans(i-1)) ) - a(k)*Eo_ans(i-1);Sc_ans(i) = 25000 - Ic_ans(i) - Rc_ans(i) - Ec_ans(i);Sa_ans(i) = 55000 - Ia_ans(i) - Ra_ans(i) - Ea_ans(i);So_ans(i) = 20000 - Io_ans(i) - Ro_ans(i) - Eo_ans(i);
endsubplot(2,3,1);
plot([1:40],Ic,[1:40],Ic_ans(1:40));
title('人群:青年')
subplot(2,3,2);
plot([1:40],Ia,[1:40],Ia_ans(1:40));
title('人群:成年人')
subplot(2,3,3);
plot([1:40],Io,[1:40],Io_ans(1:40));
title('人群:老年人')subplot(2,3,4);
plot([1:300],Ic_ans,[1:300],Rc_ans,[1:300],Ec_ans,[1:300],Sc_ans,'linewidth',2);
legend('Infectious people','Recovered people','Exposed people','Susceptible people');
xlabel('天数')
ylabel('人员数量')
title('人群:青年')subplot(2,3,5);
plot([1:300],Ia_ans,[1:300],Ra_ans,[1:300],Ea_ans,[1:300],Sa_ans,'linewidth',2);
legend('Infectious people','Recovered people','Exposed people','Susceptible people');
xlabel('天数')
ylabel('人员数量')
title('人群:成年人')subplot(2,3,6);
plot([1:300],Io_ans,[1:300],Ro_ans,[1:300],Eo_ans,[1:300],So_ans,'linewidth',2);
legend('Infectious people','Recovered people','Exposed people','Susceptible people');
xlabel('天数')
ylabel('人员数量')
title('人群:老年')r=1;
for i = 40:300Ic_ans(i) = Ic_ans(i-1) + a(k) * Ec_ans(i-1) - gamma_c * Ic_ans(i-1);Ia_ans(i) = Ia_ans(i-1) + a(k) * Ea_ans(i-1) - gamma_a * Ia_ans(i-1);Io_ans(i) = Io_ans(i-1)+ a(k) * Eo_ans(i-1)-gamma_o * Io_ans(i-1);Rc_ans(i) = Rc_ans(i-1) + gamma_c*Ic_ans(i-1);Ra_ans(i) = Ra_ans(i-1) + gamma_a*Ia_ans(i-1);Ro_ans(i) = Ro_ans(i-1) + gamma_o*Io_ans(i-1);Ec_ans(i) = Ec_ans(i-1) + r * Sc_ans(i-1)/100000*( beta_c_list(k,1)*(Ec_ans(i-1) + Ea_ans(i-1) + Eo_ans(i-1)) + beta_c_list(k,2)*(Ic_ans(i-1)+Ia_ans(i-1)+Io_ans(i-1)) ) - a(k)*Ec_ans(i-1);Ea_ans(i) = Ea_ans(i-1) + r * Sa_ans(i-1)/100000*( beta_a_list(k,1)*(Ec_ans(i-1) + Ea_ans(i-1) + Eo_ans(i-1)) + beta_a_list(k,2)*(Ic_ans(i-1)+Ia_ans(i-1)+Io_ans(i-1)) ) - a(k)*Ea_ans(i-1);Eo_ans(i) = Eo_ans(i-1) + r * So_ans(i-1)/100000*( beta_o_list(k,1)*(Ec_ans(i-1) + Ea_ans(i-1) + Eo_ans(i-1)) + beta_o_list(k,2)*(Ic_ans(i-1)+Ia_ans(i-1)+Io_ans(i-1)) ) - a(k)*Eo_ans(i-1);Sc_ans(i) = 25000 - Ic_ans(i) - Rc_ans(i) - Ec_ans(i);Sa_ans(i) = 55000 - Ia_ans(i) - Ra_ans(i) - Ea_ans(i);So_ans(i) = 20000 - Io_ans(i) - Ro_ans(i) - Eo_ans(i);
end
subplot(1,3,1);
plot([1:300],Ic_ans,[1:300],Rc_ans,[1:300],Ec_ans,[1:300],Sc_ans,'linewidth',2);
legend('Infectious people','Recovered people','Exposed people','Susceptible people');
xlabel('天数')
ylabel('人员数量')
title('人群:青年')subplot(1,3,2);
plot([1:300],Ia_ans,[1:300],Ra_ans,[1:300],Ea_ans,[1:300],Sa_ans,'linewidth',2);
legend('Infectious people','Recovered people','Exposed people','Susceptible people');
xlabel('天数')
ylabel('人员数量')
title('人群:成年人')subplot(1,3,3);
plot([1:300],Io_ans,[1:300],Ro_ans,[1:300],Eo_ans,[1:300],So_ans,'linewidth',2);
legend('Infectious people','Recovered people','Exposed people','Susceptible people');
xlabel('天数')
ylabel('人员数量')
title('人群:老年')I_ans=Ic_ans+Ia_ans+Io_ans;
R_ans=Rc_ans +Ra_ans+Ro_ans;
S_ans=Sc_ans+Sa_ans+So_ans;figure;
plot([1:300],I_ans,[1:300],Ro_ans,[1:300],R_ans,[1:300],S_ans,'linewidth',2);
legend('Infectious people','Recovered people','Exposed people','Susceptible people');
xlabel('天数')
ylabel('人员数量')
title('人群:总的人群')模型改进和精细预测
整个模型中,易感人群转换为暴露人群的概率和数量应该是可以进一步精细的。比如说用蒙特卡罗方法来模拟N个人群中随机碰撞的情况,然后计算下一个阶段的人群的不同数量情况,例如,可以将某个阶段中N个人群的随机分布,期中的不同年龄阶段的暴露人群和患病人群,易感人群和移出人群都随笔分布,然后计算每个易感人群前后的10个人中的易感人群和患病人群的情况,计算这个人的转换概率,然后遍历一下,计算出新的人群数量的分布。
写在最后
本次的比赛,让我感触良多,对最后的结果也很可惜。但是仔细想想,也没有什么可惜的,自己确实是没有比别人做的更好。自己身上还是有很大的不足,其实一直有意识到自己的不足。但是并没有什么行动,但是这一次,感觉更加深刻, 如果当时可以头脑更加清晰一点,运算过程更加清晰一点,代码更加清晰一点,写的过程更加仔细一点。也许结果会更好一点。
到了这个年龄段,有时候会意识到,自己未来短暂时间的所有可以取得的成绩,都是之前所有努力,所有选择的影响。人应该一直保持进步,一直积极向上。积极改变自己身上的陋习,这个过程可能会比较难,也比较漫长,效果也是非短期可见的。但是,还是要试一试。
慢慢尝试改变自己,人生也还很长,未来可期。做人还是要开心~!
附件:
每天的数据:
| 发病者 | 康复者 | |||||
| 未成年 | 青壮年 | 中老年 | 未成年 | 青壮年 | 中老年 | |
| 112 | 125 | 305 | 56 | 87 | 73 | |
| 92 | 115 | 302 | 83 | 98 | 87 | |
| 79 | 110 | 309 | 102 | 114 | 106 | |
| 68 | 107 | 316 | 119 | 129 | 122 | |
| 65 | 107 | 332 | 136 | 138 | 134 | |
| 64 | 110 | 353 | 149 | 152 | 152 | |
| 66 | 119 | 381 | 166 | 167 | 169 | |
| 69 | 129 | 414 | 178 | 181 | 189 | |
| 74 | 145 | 454 | 192 | 196 | 208 | |
| 82 | 162 | 505 | 209 | 212 | 234 | |
| 94 | 182 | 563 | 230 | 232 | 256 | |
| 107 | 209 | 633 | 252 | 251 | 285 | |
| 125 | 242 | 713 | 276 | 277 | 317 | |
| 145 | 276 | 806 | 305 | 304 | 353 | |
| 165 | 319 | 908 | 334 | 338 | 393 | |
| 193 | 370 | 1031 | 373 | 379 | 437 | |
| 217 | 427 | 1165 | 415 | 421 | 489 | |
| 250 | 494 | 1315 | 468 | 472 | 546 | |
| 286 | 567 | 1478 | 524 | 529 | 615 | |
| 326 | 654 | 1665 | 590 | 601 | 686 | |
| 374 | 748 | 1864 | 663 | 678 | 769 | |
| 420 | 853 | 2080 | 748 | 767 | 862 | |
| 477 | 974 | 2314 | 846 | 869 | 969 | |
| 535 | 1104 | 2561 | 954 | 985 | 1084 | |
| 602 | 1249 | 2818 | 1078 | 1116 | 1212 | |
| 671 | 1403 | 3084 | 1212 | 1266 | 1351 | |
| 745 | 1574 | 3360 | 1368 | 1434 | 1504 | |
| 819 | 1762 | 3639 | 1541 | 1623 | 1672 | |
| 903 | 1958 | 3917 | 1725 | 1835 | 1855 | |
| 981 | 2165 | 4189 | 1933 | 2070 | 2049 | |
| 1069 | 2384 | 4455 | 2157 | 2329 | 2261 | |
| 1155 | 2611 | 4708 | 2404 | 2613 | 2481 | |
| 1236 | 2848 | 4948 | 2669 | 2928 | 2719 | |
| 1320 | 3091 | 5173 | 2950 | 3267 | 2967 | |
| 1404 | 3338 | 5376 | 3254 | 3640 | 3225 | |
| 1478 | 3588 | 5562 | 3577 | 4041 | 3490 | |
| 1555 | 3837 | 5727 | 3918 | 4468 | 3770 | |
| 1623 | 4084 | 5876 | 4275 | 4932 | 4054 | |
| 1685 | 4329 | 6002 | 4644 | 5421 | 4351 | |
| 1743 | 4567 | 6105 | 5033 | 5937 | 4651 | |