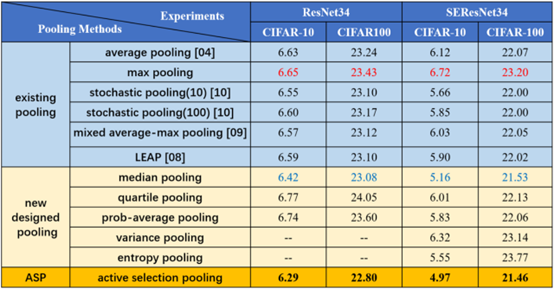
Exposure Fusion Using Boosting Laplacian Pyramid
文章目录
- Exposure Fusion Using Boosting Laplacian Pyramid
- JND Model
- Luminance Adaptation
- Contrast Masking
- Overall JND Model
- A Hybrid Exposure Weight Measurement
- Local Exposure Weight
- Global Exposure Weight
- JND-Based Saliency Weight
- Boosting Laplacian Pyramid
- Boosting guidance
- Boosting Function
- Combining
本文算法结构和《Exposure Fusion》十分接近,比较不同的是在Fusion算法内部塞进了Tone Mapping
JND Model
JND是人眼视觉系统(HVS)中的一个重要概念,简单来说就是图像当中刚好能够引起视觉感知的图像差异(the visibility threshold below which any change cannot be detected by HVS),与之密切相关的理论是Weber-Law、Center-Surround、Contrast Sensitivity Function,总的来说就是模拟对人眼视觉对图像变化的响应,关于JND的简单概述可以参考《Digital Video Image Quality and Perceptual Coding-Chapter 9 :Computational Models for Just-Noticeable Difference》,本文JND模型主要参考论文《Just Noticeable Difference for Images with Decomposition Model for Separating Edge and Textured Regions》。
- Masking effect:我的理解应该是指视觉显著性和视觉容忍性的意思,比如同一噪声被分别叠加到平坦区域、边缘区域、纹理区域,人眼对这一噪声带来的视觉响应是不同的,其中对平坦区域的噪声最为敏感,纹理区域这一噪声带来的视觉变化最小,所以我理解masking effect应该是当前区域对信号变化的容忍度或阈值
人眼视觉系统对图像的背景亮度信息(Luminance Adaptation)和产生局部对比度的细节信息(Contrast Masking)的响应及敏感度是是很不一样的,而细节信息中的边缘信息(Edge Masking)和纹理信息(Texture Masking)也存在感知上的差异,因此,JND模型通常需要从图像中分解出背景亮度信息(LA)、边缘信息(EM)、纹理信息™,算法基本框架如下:

以上JND框架中将原图像 f f f分解为 f = u + v f=u+v f=u+v使用的是全变分,分解之后用其低通滤波结果 u u u表示图像的主要结构信息,由于全变分具有保持图像边缘锐度的性质,此时 u u u当中依旧保有锐利的边缘信息,用Canny算子从 u u u中提取出图像的边缘信息,用 v v v作为图像细节信息。

Luminance Adaptation
L A LA LA即是人眼视觉系统对图像背景亮度信息的响应:
L A ( x , y ) = { 17 × ( 1 − f ( x , y ) / 127 ) + 3 , if f ( x , y ) ≤ 127 3 × ( f ( x , y ) − 127 ) / 128 + 3 , otherwise L A(x, y)=\left\{\begin{array}{ll} 17 \times(1-\sqrt{f(x, y) / 127})+3, & \text { if } f(x, y) \leq 127 \\ 3 \times(f(x, y)-127) / 128+3, & \text { otherwise } \end{array}\right. LA(x,y)={17×(1−f(x,y)/127)+3,3×(f(x,y)−127)/128+3, if f(x,y)≤127 otherwise
其中 f f f为原图的像素值。
Contrast Masking
由于人眼对边缘信息具有一定的预测能力,而对纹理信息的预测能力较差,因此纹理区域的Masking Effect要强于边缘区域的Masking Effect,分别计算边缘区域的Masking Effect E M u EM^{u} EMu、纹理区域的Masking Effect T M v TM^{v} TMv:
E M u ( x , y ) = C s u ( x , y ) . β . W e T M v ( x , y ) = C s v ( x , y ) . β . W t EM^{u}(x,y)=C^{u}_{s}(x,y).\beta.W_{e}\\ TM^{v}(x,y)=C^{v}_{s}(x,y).\beta.W_{t} EMu(x,y)=Csu(x,y).β.WeTMv(x,y)=Csv(x,y).β.Wt
其中 C s u 、 C s v C^{u}_{s}、C^{v}_{s} Csu、Csv分别为 u 、 v u、v u、v中空间域内 5 × 5 5×5 5×5的窗口内最大亮度差; W e 、 W t W_{e}、W_{t} We、Wt分别对应边缘区域、纹理区域的Masking Effect响应权重,在 C s C_{s} Cs相同的情况下,纹理区域的响应要高于边缘区域,所有 W e < W t W_{e}<W_{t} We<Wt,一般情况下 W e = 1 、 W t = 3 、 β = 0.117 W_{e}=1、W_{t}=3、\beta=0.117 We=1、Wt=3、β=0.117,最后的Contrast Masking为:
C M ( x , y ) = E M u ( x , y ) + T M v ( x , y ) CM(x,y)=EM^{u}(x,y)+TM^{v}(x,y) CM(x,y)=EMu(x,y)+TMv(x,y)


Overall JND Model
最后将上述的亮度响应和细节响应整合在一起,即为人眼视觉的显著性响应:
J N D = L A + C M − C l c × m i n ( L A , C M ) JND = LA+CM-C^{lc}×min(LA,CM) JND=LA+CM−Clc×min(LA,CM)
其中 C l c × m i n ( L A , C M ) C^{lc}×min(LA,CM) Clc×min(LA,CM)是为了去除 L A 、 C M LA、CM LA、CM将重叠的响应强度,一般取 C l c = 0.3 C^{lc}=0.3 Clc=0.3。
A Hybrid Exposure Weight Measurement
Local Exposure Weight
判断图像序列中的某一点是否曝光合适,为了让序列中过曝、欠曝的区域不参与融合,用以下函数对图像序列中的图像是否曝光合适进行评价:
Q i ( x , y ) = 1 − ∣ 1 a { log I i 1 c ( x , y ) 1 − I i 1 c ( x , y ) − b } ∣ E i ( x , y ) = r g b 2 g r a y ( Q i ( x , y ) ) (1) Q_{i}(x, y)=1- \left | \frac{1}{a}\left\{\log \frac{I_{i}^{\frac{1}{c}}(x, y)}{1-I_{i}^{\frac{1}{c}}(x, y)}-b\right\} \right | \\ E_{i}(x,y)=rgb2gray(Q_{i}(x,y))\tag{1} Qi(x,y)=1−∣∣∣∣∣a1{log1−Iic1(x,y)Iic1(x,y)−b}∣∣∣∣∣Ei(x,y)=rgb2gray(Qi(x,y))(1)
其中 a 、 b 、 c a、b、c a、b、c为曲线控制参数,一般 a = 3.2 、 b = − 1.3 、 c = 0.4 a=3.2、b=-1.3、c=0.4 a=3.2、b=−1.3、c=0.4
Global Exposure Weight
判断图像序列中某一点相对于整个图像序列而言是否曝光合适,具体方法是对《Gradient-directed Composition of Multi-exposure Images》中基于图像梯度方向变化做图像融合的方法的延申。和原方法不同的是,本文使用图像梯度方向变化不是为了检测运动物体,而是为了检测用于融合的像素点是否具有良好的曝光,本文中的方法假设,对于静态场景,在图像序列中曝光良好的相邻帧在同一点的梯度方向应该是比较接近的,且由于图像序列曝光良好,图像的梯度幅度也会比较大,因此,通过计算两梯度向量间的偏差来表示图像序列中任意两帧将的梯度差异性:
S i j ( x , y ) = ∣ ∣ M j ( x , y ) ∣ ∣ × s i n ( M i ( x , y ) , M j ( x , y ) ) (2) S_{ij}(x,y)=||M_{j}(x,y)||×sin(M_{i}(x,y),M_{j}(x,y))\tag{2} Sij(x,y)=∣∣Mj(x,y)∣∣×sin(Mi(x,y),Mj(x,y))(2)
并对 S i j S_{ij} Sij做 9 × 9 9×9 9×9的均值滤波,以平滑噪声的影响。
T i j ( x , y ) = 1 − λ × S i j ( x , y ) (3) T_{ij}(x,y)=1-\lambda×S_{ij}(x,y)\tag{3} Tij(x,y)=1−λ×Sij(x,y)(3)
KaTeX parse error: No such environment: align at position 55: …rray}{c} \begin{̲a̲l̲i̲g̲n̲}̲ T_{i j}(x, y),…
其中 λ = 100 \lambda=100 λ=100为偏差的放大参数,最终用 T i j ′ T^{'}_{ij} Tij′表示任意两帧间的梯度方向相似,最后级联 T i j ′ T^{'}_{ij} Tij′得到全局的曝光权重:
V j ( x , y ) = ∏ i = 1 , i ≠ j N T i j ′ ( x , y ) (5) V_{j}(x, y)=\prod_{i=1, i \neq j}^{N} T_{i j}^{\prime}(x, y)\tag{5} Vj(x,y)=i=1,i=j∏NTij′(x,y)(5)

JND-Based Saliency Weight
JND是人眼视觉系统(HVS)中的一个重要概念,简单来说就是图像当中刚好能够引起视觉感知的图像差异(the visibility threshold below which any change cannot be detected by HVS),与之密切相关的理论是Weber-Law、Center-Surround、Contrast Sensitivity Function,总的来说就是模拟对人眼视觉对图像变化的响应,关于JND的简单概述可以参考《Digital Video Image Quality and Perceptual Coding-Chapter 9 :Computational Models for Just-Noticeable Difference》。
- 首先计算以当前点为中心的一个 5 × 5 5×5 5×5的窗口内除当前点外的低通滤波 I ˉ ( x , y ) \bar{I}(x,y) Iˉ(x,y),以此作为当前点所在的背景亮度值,随后根据此背景亮度计算亮度响应(Background Luminance Masking):
J i l ( x , y ) = { 17 ( 1 − I ˉ ( x , y ) 127 ) + 3 , if I ˉ ( x , y ) ≤ 127 3 128 ( I ˉ ( x , y ) − 127 ) + 3 , otherwise J_{i}^{l}(x, y)=\left\{\begin{array}{c} 17\left(1-\sqrt{\frac{\bar{I}(x, y)}{127}}\right)+3, \text { if } \bar{I}(x, y) \leq 127 \\ \frac{3}{128}(\bar{I}(x, y)-127)+3, \text { otherwise } \end{array}\right. Jil(x,y)=⎩⎨⎧17(1−127Iˉ(x,y))+3, if Iˉ(x,y)≤1271283(Iˉ(x,y)−127)+3, otherwise
J l ( x , y ) J^{l}(x,y) Jl(x,y)有一点类似与人眼对亮度的感知曲线。
- 随后根据图像梯度计算纹理响应(Texture Masking):
J i t ( x , y ) = max k = 1 , 2 , 3 , 4 { ∣ grad k ( x , y ) ∣ } grad k ( x , y ) = I ( x , y ) ⊗ g k ( x , y ) \begin{array}{c} J_{i}^{t}(x, y)=\max _{k=1,2,3,4}\left\{\left|\operatorname{grad}_{k}(x, y)\right|\right\} \\ \operatorname{grad}_{k}(x, y)=I(x, y) \otimes g_{k}(x, y) \end{array} Jit(x,y)=maxk=1,2,3,4{∣gradk(x,y)∣}gradk(x,y)=I(x,y)⊗gk(x,y)
g 1 = [ 0 0 0 0 0 1 3 8 3 1 0 0 0 0 0 − 1 − 3 − 8 − 3 − 1 0 0 0 0 0 ] , g 2 = [ 0 0 1 0 0 0 8 3 0 0 1 3 0 − 3 − 1 0 0 − 3 8 0 0 0 − 1 0 0 ] g_{1}=\left[\begin{array}{rrrrr} 0 & 0 & 0 & 0 & 0 \\ 1 & 3 & 8 & 3 & 1 \\ 0 & 0 & 0 & 0 & 0 \\ -1 & -3 & -8 & -3 & -1 \\ 0 & 0 & 0 & 0 & 0 \end{array}\right], \quad g_{2}=\left[\begin{array}{rrrrr} 0 & 0 & 1 & 0 & 0 \\ 0 & 8 & 3 & 0 & 0 \\ 1 & 3 & 0 & -3 & -1 \\ 0 & 0 & -3 & 8 & 0 \\ 0 & 0 & -1 & 0 & 0 \end{array}\right] g1=⎣⎢⎢⎢⎢⎡010−10030−30080−80030−30010−10⎦⎥⎥⎥⎥⎤,g2=⎣⎢⎢⎢⎢⎡0010008300130−3−100−38000−100⎦⎥⎥⎥⎥⎤
g 3 = [ 0 0 1 0 0 0 0 3 8 0 − 1 − 3 0 3 1 0 − 8 − 3 0 0 0 0 − 1 0 0 ] , g 4 = [ 0 1 0 − 1 0 0 3 0 − 3 0 0 8 0 − 8 0 0 3 0 − 3 0 0 1 0 − 1 0 ] g_{3}=\left[\begin{array}{rrrrr} 0 & 0 & 1 & 0 & 0 \\ 0 & 0 & 3 & 8 & 0 \\ -1 & -3 & 0 & 3 & 1 \\ 0 & -8 & -3 & 0 & 0 \\ 0 & 0 & -1 & 0 & 0 \end{array}\right], \quad g_{4}=\left[\begin{array}{lllll} 0 & 1 & 0 & -1 & 0 \\ 0 & 3 & 0 & -3 & 0 \\ 0 & 8 & 0 & -8 & 0 \\ 0 & 3 & 0 & -3 & 0 \\ 0 & 1 & 0 & -1 & 0 \end{array}\right] g3=⎣⎢⎢⎢⎢⎡00−10000−3−80130−3−10830000100⎦⎥⎥⎥⎥⎤,g4=⎣⎢⎢⎢⎢⎡000001383100000−1−3−8−3−100000⎦⎥⎥⎥⎥⎤
- 最后计算显著性权重:
J i ( x , y ) = J i l ( x , y ) + J i t ( x , y ) − K l , t ( x , y ) min ( J i l ( x , y ) , J i t ( x , y ) ) J_{i}(x, y)=J_{i}^{l}(x, y)+J_{i}^{t}(x, y)-K_{l, t}(x, y) \min \left(J_{i}^{l}(x, y), J_{i}^{t}(x, y)\right) Ji(x,y)=Jil(x,y)+Jit(x,y)−Kl,t(x,y)min(Jil(x,y),Jit(x,y))
Boosting Laplacian Pyramid
首先对多曝光图像序列做高斯金字塔、拉普拉斯金字塔分解,在拉普拉斯金字塔中对图像的基础层(金字塔的最顶层)、细节层(除顶层外的其他层)分别做相应的增强处理。在后续的增强过程中使用前述的Local Exposure Weight和JND-Based Saliency Weight作为增强参数,目的是对视觉显著性区域进行细节增强和调整图像亮度水平,即在金字塔内部的Tone Mapping。
以两帧图像的融合为例,记拉普拉斯金字塔的顶层为 L i B L^{B}_{i} LiB,其他层为 L i , j D L^{D}_{i,j} Li,jD, j j j为细节层的索引。
Boosting guidance
-
用局部曝光权重 E i E_{i} Ei选择做细节增强的区域
KaTeX parse error: No such environment: align at position 48: …rray}{c} \begin{̲a̲l̲i̲g̲n̲}̲ &1, E_{i}(x, y…
其中 σ = 0.01 \sigma=0.01 σ=0.01,用来排除掉图像序列中的过曝、欠曝区域,避免对这部分区域做增强产生Artifacts。 -
有图像显著性权重 J i J_{i} Ji控制图像增强的强度
G i J ( x , y ) = G i E ( x , y ) × J i ( x , y ) G_{i}^{J}(x, y)=G_{i}^{E}(x, y) \times J_{i}(x, y) GiJ(x,y)=GiE(x,y)×Ji(x,y)
Boosting Function
- 对细节层的增强:
D i ( x , y ) = [ L i D ( x , y ) ] α i [ L i D ( x , y ) ] α i + β α i , α i = α 0 G i J ( x , y ) D_{i}(x, y)=\frac{\left[L_{i}^{D}(x, y)\right]^{\alpha_{i}}}{\left[L_{i}^{D}(x, y)\right]^{\alpha_{i}}+\beta^{\alpha_{i}}}, \alpha_{i}=\alpha_{0}^{G_{i}^{J}(x, y)} Di(x,y)=[LiD(x,y)]αi+βαi[LiD(x,y)]αi,αi=α0GiJ(x,y)
本文选择Naka-Rushton equation作为细节层增强函数,,Naka-Rushton equation是Global Tone Mapping的经典函数,可以看出,作者所谓的在金字塔内分别对基础层和亮度层做增强的做法,实际上就是在金字塔内分别对基础层和细节层做Tone Mapping。 - 对基础层的增强:
B i ( x , y ) = [ L i B ( x , y ) ] γ i γ i = γ 0 exp ( 1 n ∑ ( x , y ) n log ( G i J ( x , y ) + ϵ ) ) \begin{array}{c} B_{i}(x, y)=\left[L_{i}^{B}(x, y)\right]^{\gamma_{i}} \\ \gamma_{i}=\gamma_{0} \exp \left(\frac{1}{n} \sum_{(x, y)}^{n} \log \left(G_{i}^{J}(x, y)+\epsilon\right)\right) \end{array} Bi(x,y)=[LiB(x,y)]γiγi=γ0exp(n1∑(x,y)nlog(GiJ(x,y)+ϵ))
Combining
金字塔内分别对增强后的基础层、细节层做融合,最后重建融合后的图像:
R = ∑ i = 1 N = 2 W i 1 D i 1 + ( ∑ i = 1 N = 2 W i 2 D i 2 ) ↑ + ( ∑ i = 1 N = 2 W i 3 B i ) ↑ R=\sum_{i=1}^{N=2} W_{i 1} D_{i 1}+\left(\sum_{i=1}^{N=2} W_{i 2} D_{i 2}\right) \uparrow+\left(\sum_{i=1}^{N=2} W_{i 3} B_{i}\right) \uparrow R=i=1∑N=2Wi1Di1+(i=1∑N=2Wi2Di2)↑+(i=1∑N=2Wi3Bi)↑